Jigsaw: A Data Storage and Query Processing Engine for Irregular Table Partitioning论文阅读
目录
- Jigsaw: A Data Storage and Query Processing Engine for Irregular Table Partitioning
- 现有问题
-
- 水平分区
- 垂直分区
- 混合分区
- 不规则分区
- 原文算法展示
- 算法举例
Jigsaw: A Data Storage and Query Processing Engine for Irregular Table Partitioning
数据库的分区不一定非得是矩形的,不规则分区有时也会有更好的效果。
现有问题

给出一组SQL语句 Q 1 , Q 2 , Q 3 Q_{1}, Q_{2}, Q_{3} Q1,Q2,Q3

当数据按照上图随机存储时查询效果如图,不同颜色深度表示不同的查询聚焦的数据:当执行 Q 1 Q_{1} Q1时遍历 a 1 a_{1} a1,发现对应 t 1 , t 2 , t 4 t_{1}, t_{2}, t_{4} t1,t2,t4,所以 t 6 t_{6} t6并未涉及,故无色;其余同理。
水平分区
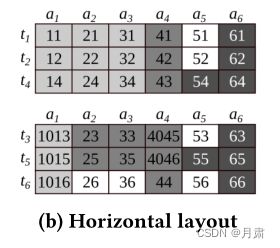
上图为水平划分方法,此时表按照 a 1 a_{1} a1升序排列,可以看到对于 Q 1 , Q 2 Q_{1}, Q_{2} Q1,Q2而言,该分区形式确实省去了一个块的读取,但是 Q 3 Q_{3} Q3仍然要读取全部的块;最重要的是,以 Q 1 Q_{1} Q1为例,查询只涉及 a 1 , a 2 , a 3 a_{1}, a_{2}, a_{3} a1,a2,a3,但是却多读取了 a 4 , a 5 , a 6 a_{4}, a_{5}, a_{6} a4,a5,a6。
垂直分区
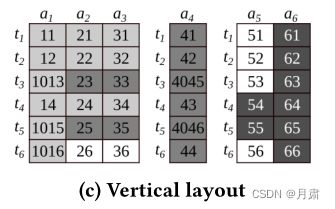
垂直分区的问题和水平分区相似:对于查询 Q 1 Q_{1} Q1而言,多读取了 t 3 , t 5 , t 6 t_{3}, t_{5}, t_{6} t3,t5,t6;对于 Q 2 Q_{2} Q2而言,需要读取两个块。
混合分区

混合分区解决了水平和垂直分区的查询读取数据冗余的问题,但是,混合分区将分区划分得太小了,如果需要调取的表很大的话,读取分区将会成为巨大IO开销的来源。
不规则分区

不规则分区解决了多块读取和冗余行数据读取,相比之下又比混合分区分出的块要少,相比之下增加的IO也较少。同时注意到,为了方便不规则分区,数据的排列顺序也要稍微改动一下。
原文算法展示


一开始将整张表作为segment置于active中,之后循环如下操作
- 取active中第一个segment,用partitionSegment(s)函数划分为子segment,并获取划分评价;
- 如果评价大于0,那么将子segment置于active尾部;否则,置于froze中;
- 如果active为空,则停止循环
之后循环如下操作
- 取froze的第一个segment
- 如果这个segment大于MAX_SIZE,就按照 h o r i z o n t a l ( s , a , s . m a x a + s . m i n a 2 ) horizontal(s, a, \frac{s.max_{a}+s.min_{a}}{2}) horizontal(s,a,2s.maxa+s.mina)的标准划分出子segment,并加入froze尾部;
- 如果这个segment小于MIN_SIZE,就将froze中与其具有相同查询的segment相合并,直到合并后的segment大于MIN_SIZE,将最终segment作为partition;
- 其他情况下直接将segment作为partition;
- 若froze为空则停止循环;
在这里需要注意 M A X _ S I Z E ≥ 2 M I N _ S I Z E MAX\_SIZE\ge2MIN\_SIZE MAX_SIZE≥2MIN_SIZE,否则可能会使程序陷入死循环。

对于每个segment,我们都可以按照其所涉及的query来划分为三个部分:查询条件部分 ( S σ ) (S_{\sigma}) (Sσ),结果投影部分 ( S π ) (S_{\pi}) (Sπ)和未涉及到的部分remain ( S r ) (S_{r}) (Sr)。在这里我们认为所有数据为均匀分布的,所以 S π S_{\pi} Sπ按照比例进行遍历划分为 S π 1 , S π 2 S_{\pi_{1}}, S_{\pi_{2}} Sπ1,Sπ2。
由于上述的query和划分方式有很多种,因此也就有许多组 ( S σ , S π 1 , S π 2 , S r ) (S_{\sigma}, S_{\pi_1}, S_{\pi_2}, S_{r}) (Sσ,Sπ1,Sπ2,Sr),我们选取在cost()函数中最小的一组,返回划分出的子segment和评价。

按照给出的比例划分子segment。
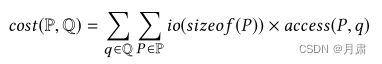
评价标准为读取io越小越好。
算法举例
| a1 | a2 | a3 | a4 | a5 | a6 | |
|---|---|---|---|---|---|---|
| t1 | 11 | 21 | 31 | 41 | 51 | 61 |
| t2 | 12 | 22 | 32 | 42 | 52 | 62 |
| t3 | 1013 | 23 | 33 | 4045 | 53 | 63 |
| t4 | 14 | 24 | 34 | 43 | 54 | 64 |
| t5 | 1015 | 25 | 35 | 4046 | 55 | 65 |
| t6 | 1016 | 26 | 36 | 44 | 56 | 66 |
| 查询语句 | |
|---|---|
| Q1 | SELECT a2, a3 FROM T WHERE a1 ≤ \le ≤ 100 |
| Q2 | SELECT a2, a3 FROM T WHERE a4 ≥ \ge ≥ 4000 |
| Q3 | SELECT a5 FROM T WHERE 64 ≤ \le ≤ a6 ≤ \le ≤ 65 |
假设MIN_SIZE=7,MAX_SIZE=14
一开始整个表作为segment,根据Q1的 S σ , S π , S r S_{\sigma}, S_{\pi}, S_{r} Sσ,Sπ,Sr的方法划分如图

中间橙色部分为 S π S_{\pi} Sπ,对其进行划分。在这里省略最大值最小值的选取,划分结果为
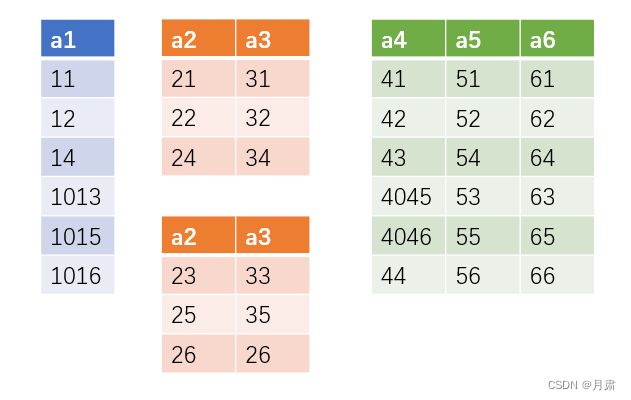
计算cost为6+6+18+6+18=54
同理对Q2如此操作,获得

cost=18+12+6+4+18=58
同理,Q3如图
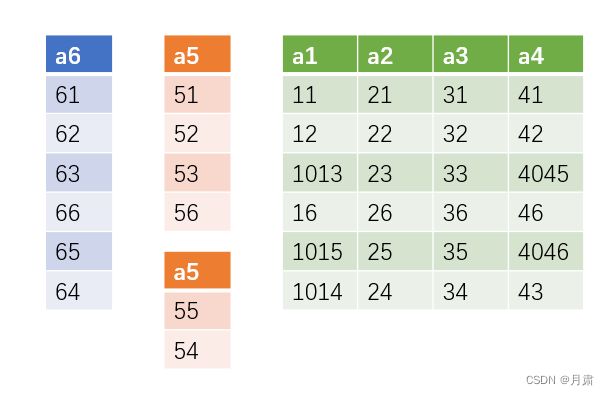
cost=6+2+24+24=56
因此在这里采用Q1的划分方案。
再次重复上述步骤,直至active为空,此时划分为

进入froze,这里没有大于MAX_SIZE的部分,故一直处于合并状态。
对a1列来说,其与a2,a3蓝色部分具有相同query,所以合并,此时大于MIN_SIZE,作为一个partition;
同理,灰色a2,a3与黄色a4有相同query,合并并作为partition;
绿色a6和蓝色a5具有相同query,合并并作为partition;
剩余部分不具有相同的query,但为了结束程序,将其合并并作为partition;
froze空,跳出程序,结束,最终划分如图
