【论文解读】Recommending Knowledge Concepts on MOOC Platforms with Meta-path-based Representation Learning

推荐
文章目录
- 摘要
- 1 引言
- 2 相关工作
-
- 2.1 MOOC平台上的推荐系统和用户建模
- 2.2 基于HIN的推荐方法
- 3 相关概念
- 4 所提方法
-
- 4.1 训练细节
- 5 实验设置
-
- 5.1 比较方法
- 6 实验结果
- 7 结论和未来工作
摘要
大规模在线开放课程(mooc)为大量用户提供了大规模的在线开放学习,在现代教育中为学生和专业人员发挥着重要作用。为了保持用户对mooc的兴趣,研究并部署了推荐系统来推荐用户可能感兴趣的课程或视频。但是,推荐的课程和视频通常涵盖了广泛的知识概念,并没有考虑到用户对某些特定概念的兴趣和学习需求。本文研究的重点是向用户推荐感兴趣的知识概念,这是一项具有挑战性的任务,因为大量的概念存在,用户概念交互的稀疏性。在本文中,我们提出了一种方法,将MOOC平台(如教师、视频、课程和学校)的信息建模为异构信息网络(HIN),通过HIN中的元路径,使用基于用户-用户和概念-概念关系的图卷积网络来学习用户和概念表示。我们将这些学习到的用户和概念表示纳入一个扩展的矩阵分解框架,以预测每个用户对概念的偏好。我们在一个真实的MOOC数据集上的实验表明,所提出的方法在预测和推荐用户感兴趣的概念方面优于一些基线和最先进的方法。
1 引言
mooc(大规模开放在线课程)是一种免费的在线课程,全世界的人都可以注册。在过去十年里,mooc大受欢迎。截至2018年底,edX1和Coursera2等流行的MOOC平台已经提供了1.14万门课程,用户/学习者达1.01亿人。此前的研究表明,mooc确实具有切实的影响[24,8]。例如,Chen et al.[8]的调查显示,72%的受访者报告了职业福利,61%的受访者报告了教育福利。尽管mooc很受欢迎,但其面临的一个主要挑战是这些课程的整体完成率通常低于10%[19,30]。因此,了解和预测用户的行为和学习需求对于保持用户在MOOC平台上的学习非常重要。
为此,以往的研究主要集中在理解辍学或拖延行为[28,12,38,14]以及推荐用户可能感兴趣的课程、学习路径等内容[16,26,4]。MOOC可以被视为一系列视频,每个视频都与一些知识概念相关联。例如,计算机科学MOOC的一个视频可以涵盖“软件”和“硬件”等多个概念。最近,Gong等人[13]认为课程或视频推荐忽略了用户对特定知识概念的兴趣。例如,不同老师教的数据挖掘课程在微观上可能有很大的不同,用户对“关联规则”等特定概念感兴趣的用户,可能对不同老师从不同角度涵盖这些概念的各种视频片段或学习材料感兴趣。因此,从微观角度理解用户的学习需求,预测用户可能感兴趣的知识概念是很重要的。
在这项工作中,我们专注于预测和推荐在MOOC平台上用户可能感兴趣的知识概念。基于用户和概念之间的交互历史(即,如果用户已经学习了某个概念,那么该用户已经与该概念进行了交互),传统的推荐方法如协同过滤(CF)——基于用户的交互历史或来自相似用户的有趣的条目来推荐相似的条目(概念)——可以被应用。然而,用户项(用户概念)关系的稀疏性限制了基于cf的方法的性能。除了用户和概念,MOOC平台数据通常还包括课程、视频、教师等其他实体以及这些实体之间的关系。
为了解决稀疏性问题,我们将这些实体及其关系建模为一个异构信息网络(HIN)[33],由实体和关系组成,灵感来自于[13],它可以用于通过使用图卷积网络(GCNs)探索间接的用户-用户(概念-概念)关系来学习用户(概念)表示/嵌入。图1说明了这样一个HIN,我们将在第3节详细讨论。例如,我们可以基于HIN中的间接路径推导出一个同构用户图,例如,如果两个用户走了相同的路线,那么两个用户之间就会有边。给定这样一个同构图,传统的GCNs可以应用于该图来学习用户和概念的表示/嵌入与所选路径相关。

基于所选择的不同间接路径,我们可以推导出不同的用户(概念)表示,这些关于不同路径的用户(概念)表示可以被聚合,例如,使用这些表示的平均值。我们提出并研究了不同的注意机制,以基于不同路径导出聚合的用户(概念)表示,而不是简单的平均聚合。使用注意力机制背后的直觉是,不同路径对每个用户的重要性可能不同。之后,这些学习到的用户和概念表征可以用来预测概念的推荐偏好得分。我们在这项工作中的贡献如下:(1)我们提出了一个端到端框架4,用于预测和推荐第4节中用户感兴趣的知识概念;(2)我们研究了**从不同元路径聚合信息的两种注意机制(**定义可以在第3节中找到),以派生用户表征和概念表征。然后,我们将这些表示结合到我们的扩展矩阵分解框架中,以预测一个概念相对于用户的偏好得分;(3)最后,我们根据完善的评估指标,用几个基线和最先进的方法来评估我们的方法,并在第6节中展示我们提出的方法的有效性。
2 相关工作
2.1 MOOC平台上的推荐系统和用户建模
自2013年以来,MOOC平台上对于课程、视频、学习路径等不同方面的推荐系统的兴趣越来越大[16,26,3,43,9,23]。例如,[3]的作者提出了YouEDU,它是一个对MOOC论坛帖子进行分类并推荐教学视频片段的管道,可能有助于解决在这些帖子中发现的混淆。在[21]中,作者表明,在项目管理MOOC环境下,同行推荐可以显著提高用户的参与度。Dai等人[9]提出通过分析课程内容来推荐MOOC平台的个性化学习路径。Khalid等人[18]对mooc背景下不同推荐系统的最新进展进行了全面的调查。最近,研究人员开始在mooc环境下对用户兴趣进行建模,而用户建模在社交媒体[42]等其他领域也得到了广泛的研究。例如,Li et al.[22]通过对课程推荐的调查或问卷调查来研究获取用户兴趣的影响。在[2]中,作者提出了利用用户兴趣建模来推荐课程的LeCoRe,以及利用类似用户来促进企业环境中的同伴学习。Gong等[13]认为课程推荐忽略了用户对特定知识概念的兴趣,从微观角度研究用户的在线学习兴趣,推荐知识概念可以更好地捕捉用户的兴趣,提供选择用户感兴趣的学习资源的灵活性。在这项工作中,我们还关注微观视角的知识概念推荐。
2.2 基于HIN的推荐方法
早期HIN推荐方法的基本思想是利用基于路径的用户和条目之间的语义相关性,例如,利用基于元路径的相似性进行推荐[40,32,41]。例如,Shi等人[32]提出了基于通过不同元路径测量的相似用户的产品评级预测。随着图表示学习的进步,[31]的作者提出使用基于随机游动元路径信息的预训练的用户和项目嵌入,并将这些预训练的嵌入作为特征纳入到扩展的矩阵分解框架中。与我们最相似的作品是Gong et al.[13],这是最早在异构视角下推荐MOOC平台知识概念的工作之一。作者表明,他们提出的方法优于其他基于cf的基线以及metapath2vec[11],后者通过测量两个节点之间的相似性,使用给定HIN的已知节点表示来进行知识概念推荐。我们的工作在几个方面与[13]不同。首先,我们将每个用户的互动概念定义为隐性反馈,[13]将点击量定义为评分,将问题定义为评分预测,用于推荐评分最高的未知概念。其次,我们考察了不同的注意机制,包括矩阵分解中融入用户(物品)潜在特征的注意机制。第三,估计概念偏好得分的预测层(Eq. 6)与使用用户(物品)表示作为特征进行最终预测的[13]不同。
3 相关概念
在这项工作中,我们考虑了预测和推荐用户可能感兴趣的概念的任务,基于他们的学习历史,包括一组学习过的概念和他们的上下文信息,如课程,视频,等。我们研究中的MOOC数据可以用HIN来表示。HIN由用户、概念、视频、课程、学校和教师等六类实体组成。此外,还有一组描述这些实体之间关系的链接。在HIN定义的基础上,使用网络模式的概念来描述网络[31]的元结构。
4 所提方法
元路径选择
正如在第3节中讨论的,元路径提供了通过这些路径派生实体-实体关系的能力。与之前的研究[13,31]类似,我们通过不同的元路径考虑用户-用户和概念-概念关系。为了在我们的实验中与[31]进行公平的比较,我们在我们的研究中使用了与[31]相同的元路径集。表1总结了我们工作中使用的6个元路径,其中4个用于用户,2个用于概念。对于每个元路径,都可以提取一个关于用户(概念)的同构图,如图2所示为其对应的邻接矩阵。可以想象,如果两个用户(概念)可以通过该元路径连接,邻接矩阵A中的每个条目都等于1,否则等于0。之后,我们可以使用gcn学习每个元路径的用户(概念)表示。
图卷积网络GCN
GCNs通过检查相邻节点来学习图的节点表示。在这项工作中,我们采用以下分层传播规则来学习关于元路径的用户(概念)表示/嵌入。
4.1 训练细节
为了克服过拟合问题,我们进一步利用最后一个交互概念为每个用户构建验证集,并将每个已知概念与99个未知概念随机配对。我们运行500个观察收敛的时间点,并监控验证集上的评估指标(参见第5节)的性能。最后,我们根据MRR(平均倒数秩)在验证集上选择性能最好的模型,MRR(平均倒数秩)是衡量一个基础真值概念在对应的100个概念集中排名如何的评估指标之一。基于对特定度量的偏好,任何其他评估度量都可以用于选择性能最好的模型
5 实验设置
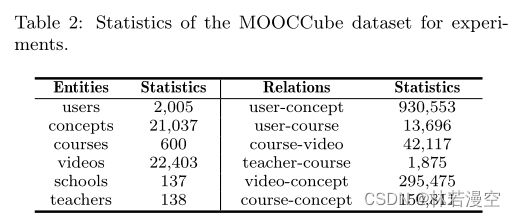
我们使用来自XuetangX平台的MOOCCube数据集[39]进行实验。MOOCCube数据集是规模最大、全面的MOOC数据集之一,提供了2017年至2019年MOOC平台上用户活动的丰富信息。每个课程或视频在数据集中都有一组涵盖的知识概念。在本工作中,我们使用201701-01至2019-10-31的用户活动进行培训,使用2019-11-01至2019-12-31的用户活动进行测试。我们限制那些在培训和测试阶段都学习过概念,并且在测试阶段至少有一个新概念(在培训阶段没有出现)的用户。总体而言,该数据集包含2005个用户21,037个概念、600门课程、22,403个视频、137所学校、138名教师以及这些实体之间的关系。用户和概念之间总共有930,553个交互,其中训练集中有858,072个交互,测试集中有72,481个交互。数据集的总体统计数据如表2所示。
5.1 比较方法
为了更好地理解和研究在第4节中介绍的两种注意机制的每个组成部分的贡献和表现,我们首先比较我们的方法的几个变体。MOOCIRa1表示我们使用注意机制的方法,使用公式3只考虑不同的元路径。MOOCIRa2指的是我们利用注意机制结合用户潜在特征(概念)的方法,使用Eq. 4。MOOCIRa-是我们的方法的一个变种,没有任何注意,即,不同的元路径被平等对待,从这些路径学习的表示是平均的。MOOCIRmf-指的是Eq. 6中没有用于预测的矩阵分解部分的变量,它只使用基于元路径的用户和概念表示来预测一个概念的偏好得分。
接下来,我们将MOOCIR与以下基线和最先进的方法进行比较,以评估为用户推荐知识概念的性能。TopPop是一种简单的基线方法,它根据概念的流行程度对其进行排名。在这里,一个概念的受欢迎程度可以通过学习该概念的用户数量来衡量。MFBPR[29]是一种矩阵分解方法,它优化了推荐任务的两两排名损失,作为我们的方法,但没有基于元路径的表示学习。即去掉了Eq. 6中基于用户(概念)表示的第二个分量。FISM[17]是一种项目到项目的协同过滤方法,它基于所有交互概念的平均嵌入和目标概念的嵌入提供推荐。NAIS[15]也是一种项目到项目的协同过滤方法,但它具有注意力机制,能够区分用户档案中哪些历史项目对预测更重要。我们对NAIS和FISM5都使用作者的实现。metapath2vec[11]。Metapath2vec是一种基于元路径的表示学习模型,它利用基于元路径的随机漫步来构建节点的异构邻域,然后利用异构跳过图模型来学习节点嵌入。我们在实验中使用了metapath2vec的starargraph[10]实现,其中metapath2vec的参数设置与[11]相同,只是将随机游走的数量设置为500而不是10006。ACKRec[13]还将MOOC数据集建模为HIN,并从表1中的同一组元路径中提取用户(概念)表示。但是,ACKRec将此问题视为评分预测任务,用户对一个概念的评分是用户与该概念之间的交互次数。此外,它利用用户和概念表示作为特征,同时扩展矩阵分解框架。我们使用作者的实现7进行实验。MFBPR和那些MOOCIR变体是使用Tensorflow[1]实现的。所有实验都在英特尔®酷睿™ i5-8365U处理器笔记本电脑上运行,16GB内存,MOOCIR变体的训练时间不到两天。
6 实验结果
表3总结了使用MOOCIR变体的结果。从表中我们可以看到,mooocirmf使用了基于HIN元路径学习的用户和概念表示,但没有矩阵分解组件,与其他变体相比,它提供了更糟糕的性能。结果表明,推广矩阵分解对于MOOCIR是必要的。
接下来,我们比较MOOCIRa-和具有注意力机制的变体(即MOOCIRa1和MOOCIRa2)。我们观察到MOOCIRa1和MOOCIRa2在所有评估指标上都优于MOOCIRa,这表明使用注意力确实可以提高性能,而且不同的元路径对衍生用户(概念)表示具有不同的重要性。这也可以通过调查MOOCIR中不同元路径的学习注意力权重来进一步验证。例如,图3显示了100个随机选择使用MOOCIR的用户学习到的注意力权重的热图。图中x轴表示100个用户,y轴表示第4节表1中4种不同用户元路径的关注权重。从图中我们可以看出,第一个元路径(user→concept−1−→user)的权重总体上高于其他元路径。此外,我们观察到不同用户的注意权重不同,这表明每个元路径的重要性对不同的用户是不同的。
最后,通过比较两种不同的注意机制,我们观察到,与更简单的注意机制(Eq. 3)相比,融合用户和概念潜在特征的注意机制(Eq. 4)并没有提高性能,这与我们的假设不同。相反,我们观察到,对于与有限数量的概念进行交互的用户来说,MOOCIRa2在HR@10和HR@20方面的表现明显比MOOCIRa1差。表4显示了概念小于150、350和550的三组用户的性能。从图中我们可以看到,在第一批353名用户中,MOOCIRa1的表现明显优于MOOCIRa2。研究结果表明,将用户潜在特征(概念)的信息融合到注意机制中是一项重要的任务,未来还需要进一步研究其他方法。
表5展示了mooocira1的性能以及比较方法。我们首先观察到所有其他方法都优于TopPop, TopPop是一个推荐流行概念的基线方法。例如,MOOCIRa1和ACKRec的MRR分别比TopPop提高了45.8%和43.1%。在表5中比较的所有方法中,MOOCIRa1的性能最好,其次是ACKRec、MFBPR和metapath2vec。ACKRec在nDCG和MRR方面表现最好,MFBPR在or HR方面表现最好。MOOCIRa1在MRR(+1.9%)、nDCG@5(+3.1%)、nDCG@10(+4.5%)、+nDCG@20(4.8%)方面明显优于ACKRec (α < 0.01)。与MFBPR相比,当k = 5,10,20时,MOOCIRa1使HR得分分别提高6.7%、9.2%和9.4% (α < 0.01)。两种分项CF方法(FISM和NAIS)的性能不如MFBPR和ACKRec。一种可能的解释可能是由于数据集的稀疏性,这使得基于每个条目的交互用户来导出条目之间的相似性具有挑战性,并限制了性能。
这些结果表明,与基线和最先进的方法相比,所提出的方法MOOCIRa1在top-k概念推荐的评估指标方面可以取得具有竞争力的性能。
7 结论和未来工作
在这篇文章中,我们提出MOOCIR来预测和推荐在MOOC平台上用户可能感兴趣的概念。第6节中对MOOCIR变体的比较表明,使用从不同元路径学习到的用户和概念表示来扩展矩阵分解,并使用注意力来派生这些表示,在获得更好的性能方面发挥了至关重要的作用。此外,与其他基线和最新的方法相比,MOOCIRa1可以显著提高概念的预测和推荐性能。通过比较两种引入的注意机制(式3和式4),我们发现在将用户和概念的潜在特征融合到注意机制中时,需要一种更全面的方法,这将在不久的将来进行研究。