文献阅读笔记整理--ConvNext:A ConvNet for the 2020s
文献阅读时间:2022年11月1日
论文名称:A ConvNet for the 2020s
论文下载链接:https://arxiv.org/abs/2201.03545
论文对应源码链接:https://github.com/facebookresearch/ConvNeXt
一、前言
以ResNet-50结构为基础,按照Swin-Transformer的设计思想来改进ResNet-50,实现新的准确率,并进一步探索它的可扩展性。
二、ResNet-50
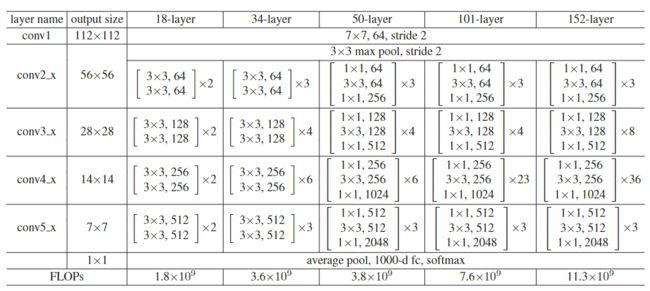
图来自深度残差学习
1、什么是ResNet-50
由48层卷积、1层maxpooling、1层avgpooling构成,卷积的每个block比例为3:4:6:3。
三、相关设计
1、Training Techniques
除了网络结构的设计,训练技巧也会影响最后的效果。
本文在训练技巧模块,以ResNet-50和ResNet-200为baseline-model,来进行训练技巧的设计:
(1)Epochs设计
由90改变至300。
(2)引入Adam W Optimize
借鉴Vision Transformer ,使用其Adam W Optimize,是一个带有权重正则化的优化器。
其中优化器参数为:
预训练学习率为4e-3,weight_decay=0.05,batchsize=4096;
微调学习率为5e-5,weigth_decay=1e-8,batchsize=512,layer-wise lr decay。
weigth_decay:权重衰减。L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化;
learning rate:学习率;
learning rate_decay:学习率衰减。
(3)Data augmentation技巧的引入
比如Mixup、Cutmix、RandAugment、Random Erasing and Regularization schemes including Stochastic Depth and Label Smoothing。
效果:在测试集上,由原本的76.1上升到78.8。此处使用随机种子,求平均得到。
得出结论:利用现在的优化方法,重新训练ResNet-50,准确率有所提高,即后续工作继续使用该超参数。
启示:在处理复杂任务时,先在小数据集/小模型上找到一个最优的训练策略,找到后一直使用该策略,然后使用导大数据集/大模型中;
2、Macro Design
宏观设计
(1)Changing Stage compute ratio
block的比例改变:借鉴Swin Transformer的【1:1:3:1】,由【3,4,6,3】改变至【3,3,9,3】;
效果:在测试集上,由原本的78.8上升到79.4。此处使用随机种子,求平均得到。
(2)Changing stem to “patchify”
底层卷积改变:借鉴vision Transformer的patch思想,将底层的卷积替换成4x4 stride=4的卷积,使特征图变为若干patch;//由于之前7x7 stride=2的底层卷积,移动时会出现交叠,故进行改变;
效果:在测试集上,由原本的79.4上升到79.5。此处使用随机种子,求平均得到。
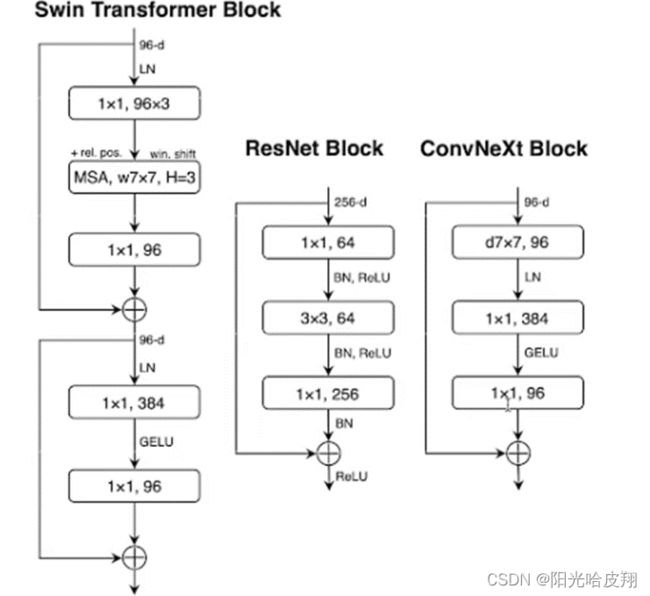
(3)ResBext-ify
引入depth-wise conv:为深度可分离卷积,减少计算量。借鉴self-attention的加权求和思想。并将channels从64提升到96;// 深度可分离卷机可将将通道数目划分为若干group。此时,将group数目设置为与输入通道数目相同。
效果:在测试集上,由原本的79.5上升到80.5。此处使用随机种子,求平均得到。
(4)Inverted Bottleneck
引入bottle-neck结构:借鉴Transformer的feed-forward设计思想,即通道数目先放大,再压缩。将channels设置为96、384、96,并增大kernel size至7x7。
效果:在测试集上,由原本的80.5上升到80.6。此处使用随机种子,求平均得到。
至此,在ImageNet-1k的准确率从78.8%提升到80.6%;
2、Micro Design
微观设计
(1)Replacing ReLu with GELU and Substituting BN with LN
激活函数替换:由RELU替换为GELU,将BN(批归一化)替换成LN(层归一化)。
效果:在测试集上,由原本的78.8上升到79.4。此处使用随机种子,求平均得到。
(2)Fewer activation functions and Normalization layers
激活函数即归一化层改变:引入更少的激活函数和归一化层。
效果:在测试集上,由原本的78.8上升到79.4。此处使用随机种子,求平均得到。
(3)Separate downsampling layers.
下采样层改变:借鉴Swin Transformer的patch merging设计思想。采用2x2 stride=2的卷积进行下采样,并在底层、下采样之前和最后的平均池化之后加入LN层,使训练更加稳定。
效果:在测试集上,由原本的78.8上升到79.4。此处使用随机种子,求平均得到。
至此,在ImageNet-1k的准确率从80.6%提升到82.0%;相比同量级的swin Transformer的81.6%有所提高。
下图为模型比较结果:

笔记部分内容整理自b站UP主:deep_thoughts