CentOS7.4环境下的K8S搭建
目录
1、k8s简介... 1
2、基础架构图... 1
2.1、master. 1
2.2、apiserver. 2
2.3、scheduler kubernetes. 2
2.4、Replication Controllers. 2
2.5、minion. 2
2.6、container. 2
2.7、 Pod. 3
2.8、Kube_proxy. 3
2.9、Etcd. 3
2.10、Services. 4
2.11、Labels 标签... 4
2.12、 Deployment. 4
2.13、Kubelet命令... 4
2.14、总结... 5
2.14.1、Kubernetes的架构... 5
2.14.2、Replication controller. 5
2.14.3、service. 5
2.14.4、Kubernetes. 5
2.14.5、pod. 5
3、环境规划... 5
4、环境准备... 6
4.1、配置k8s的yum源(master) 6
4.2、配置yum源(node1和node2)... 9
4.3、主机名规划... 10
4.4、配置/etc/hosts. 10
4.5、配置时间同步... 11
4.5.1、配置chrony服务端(master)... 11
4.5.2、配置chrony客户端(两个node节点都做)... 14
4.6、关闭防火墙... 15
4.7、关闭selinux. 15
5、安装k8s. 16
5.1、安装包... 16
5.1.1、master节点安装包... 16
5.1.2、node节点安装包... 16
5.2、配置etcd服务器... 16
5.2.1、修改配置文件/etc/etcd/etcd.conf 16
5.2.2、配置文件说明... 17
5.2.3、启动etcd服务... 17
5.2.4、检查etcd通讯端口... 17
5.2.5、检查etcd集群成员表... 18
5.2.6、检查etcd集群健康状态... 18
5.3、配置master服务... 18
5.3.1、配置k8s配置文件... 18
5.3.2、config配置文件说明... 19
5.3.3、修改apiserver配置文件... 19
5.3.4、apiserver配置文件说明... 19
5.3.5、配置kube-controller-manager配置文件... 20
5.3.6、配置scheduler配置文件... 20
5.3.7、etcdctl命令使用... 21
5.3.8、设置etcd网络... 24
5.9、配置flanneld服务... 25
5.10、启动master上bube-apiserver服务... 29
5.11、启动master上kube-controller-manager 服务... 30
5.12、启动master上kube-scheduler服务... 30
5.4、配置node1 minion. 31
5.4.1、配置node1上的flanneld. 31
5.4.2、配置node1上master地址... 33
5.4.3、配置node1上的kube-proxy服务... 33
5.4.4、配置node1 kubelet. 34
5.4.5、启动node1上所有服务... 34
5.4.6、查看网卡... 39
5.4.7、查看kube-proxy. 41
5.5、配置node2 minion. 41
5.5.1、拷贝配置文件... 41
5.5.2、微改配置文件... 42
5.5.3、启动node2所有服务... 42
5.5.4、查看node2上所有服务... 42
5.5.5、查看网卡... 47
5.5.6、查看kube-proxy. 49
5.6、查看整个k8s集群状态... 50
5.7、集群服务总结... 50
5.7.1、etcd. 50
5.7.2、master. 51
5.7.3、node1-minion. 52
5.7.4、node2-minion. 53
6、Kubectl工具... 53
6.1、Kubectl概述... 53
6.2、启动相关服务... 53
6.3、获取集群状态... 53
6.4、查看版本... 53
6.5、kubectl常用命令... 54
6.6、kubectl使用举例... 54
6.6.1、上传基础镜像到所有node节点... 54
6.6.2、所有node节点上导入镜像... 55
6.6.3、所有node节点查看镜像... 57
6.6.4、kubectl run语法... 58
6.6.5、启动pod. 58
6.6.6、查看Deployment. 58
6.6.7、查看pod. 59
6.6.8、查看pod详细信息... 59
6.6.9、查看指定的pod详情... 60
6.6.10、pods常见的状态... 62
6.6.11、kubectl删除pod. 63
6.6.12、再创建一个pod. 64
6.6.13、删除deployment. 64
7、Yaml 65
7.1、yaml语法... 65
7.2、Yaml数据结构... 65
7.2.1、数据结构--对象... 65
7.2.2、数组... 66
7.2.3、复合结构... 67
7.2.4、纯量... 67
7.3、应用举例... 68
7.3.1、上传镜像到所有node节点... 68
7.3.2、上传mysql-deployment.yaml到master管理结点... 69
7.3.3、在node1和node2上导入mysql镜像... 69
7.3.4、Mysql-deployment.yaml文件内容... 70
7.3.5、该yaml文件结构... 72
7.3.6、通过yaml文件创建资源... 72
7.3.7、查看创建的pod. 73
7.3.8、查看创建的deployment. 73
7.3.9、查看pod详情... 73
7.3.10、查看service. 74
7.3.11、测试通信... 74
7.3.12、回顾:flannel地址的配置... 75
7.3.13、在node2上查看运行mysql docker实例... 75
7.3.14、简写总结... 76
7.3.15、kubectl describe. 77
7.3.16、Kubectl其他常用命令和参数... 84
8、搭建K8s的web管理界面... 92
8.1、搭建步骤... 93
8.1.1、确认集群环境... 93
8.1.2、上传yaml文件到master. 93
8.1.3、修改apiserver. 94
8.1.4、配置文件说明... 96
8.1.5、service的三种端口... 97
8.1.6、service概述... 99
8.1.7、replicationController. 99
8.1.8、service和replicationController总结... 99
8.1.9、准备k8s相关的镜像... 100
8.1.10、上传yaml文件... 100
8.1.11、创建deployment. 100
8.1.12、创建service. 100
8.1.13、查看deployment. 100
8.1.14、查看service. 100
8.1.15、查看pod. 100
8.1.16、查看指定pod. 100
8.1.17、排错经验... 100
8.2、验证web浏览器访问... 100
8.3、销毁web界面相关应用... 100
8.3.1、删除deployment. 100
8.3.2、删除web对应的service. 100
1、k8s简介
Kubernetes 是Google开源的容器集群管理系统,基于Docker构建一个容器的调度服务,提供资源调度、均衡容灾、服务注册、劢态扩缩容等功能套件。 基于容器的云平台Kubernetes基于docker容器的云平台,简写成: k8s 。 openstack基于kvm虚拟机云平台。
官网:https://kubernetes.io/
2、基础架构图
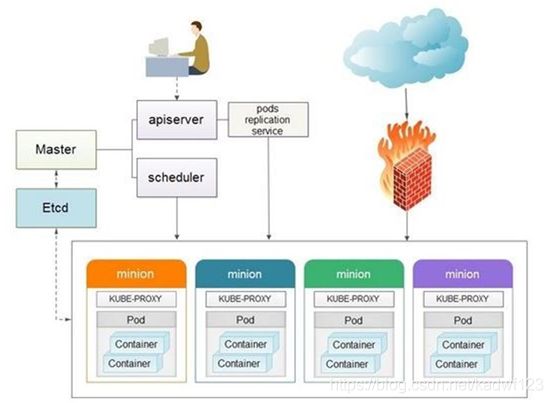
2.1、master
kubernetes管理结点
2.2、apiserver
提供接口服务,用户通过apiserver来管理整个容器集群平台。API Server 负责和 etcd 交互(其他组件不会直接操作 etcd,只有 API Server 这么做),整个 kubernetes 集群的所有的交互都是以 API Server 为核心的。如:
2.2.1、所有对集群迚行的查询和管理都要通过 API 来进行
2.2.2、所有模块之间并不会互相调用
而是通过和 API Server 打交道来完成自己那部分的工作 、API Server 提供的验证和授权保证了整个集群的安全
2.3、scheduler kubernetes
调度服务
2.4、Replication Controllers
复制, 保证pod的高可用
Replication Controller是Kubernetes系统中最有用的功能,实现复制多个Pod副本,往往一个应用需要多个Pod来支撑,并且可以保证其复制的副本数,即使副本所调度分配的宿主机出现异常,通过Replication Controller可以保证在其它宿主机使用同等数量的Pod。Replication Controller可以通过repcon模板来创建多个Pod副本,同样也可以直接复制已存在Pod,需要通过Label selector来关联。
2.5、minion
真正运行容器container的物理机。 kubernets中需要很多minion机器,来提供运算。
minion [ˈmɪniən] 爪牙
2.6、container
容器 ,可以运行服务和程序
2.7、 Pod
在Kubernetes系统中,调度的最小颗粒不是单纯的容器,而是抽象成一个Pod,Pod是一个可以被创建、销毁、调度、管理的最小的部署单元。pod中可以包括一个或一组容器。
pod [pɒd] 豆荚
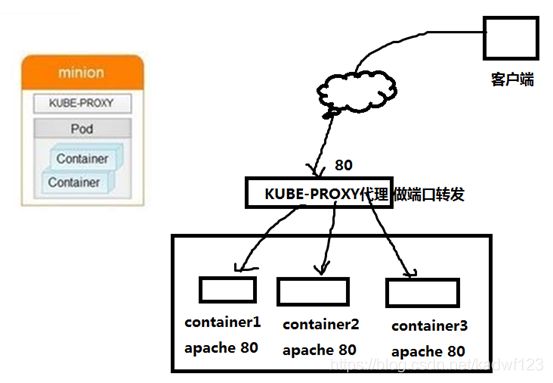
2.8、Kube_proxy
代理做端口转发,相当于LVS-NAT模式中的负载调度器器
Proxy解决了同一宿主机,相同服务端口冲突的问题,还提供了对外服务的能力,Proxy后端使用了随机、轮循负载均衡算法。
2.9、Etcd
etcd存储kubernetes的配置信息,可以理解为是k8s的数据库,存储着k8s容器云平台中所有节点、pods、网络等信息。linux 系统中/etc 目录作用是存储配置文件。 所以etcd (daemon) 是一个存储配置文件的后台服务。
2.10、Services
Services是Kubernetes最外围的单元,通过虚拟一个访问IP及服务端口,可以访问我们定义好的Pod资源,目前的版本是通过iptables的nat转发来实现,转发的目标端口为Kube_proxy生成的随机端口。
2.11、Labels 标签
Labels是用于区分Pod、Service、Replication Controller的key/value键值对,仅使用在Pod、Service、 Replication Controller之间的关系识别,但对这些单元本身进行操作时得使用name标签。
2.12、 Deployment
Deployment [dɪ'plɔ.mənt] 部署
Kubernetes Deployment用于更新Pod和Replica Set(下一代的Replication Controller)的方法,你可以在Deployment对象中只描述你所期望的理想状态(预期的运行状态),Deployment控制器会将现在的实际状态转换成期望的状态。例如,将所有的webapp:v1.0.9升级成webapp:v1.1.0,只需创建一个Deployment,Kubernetes会按照Deployment自动进行升级。通过Deployment可以用来创建新的资源。 Deployment可以帮我们实现无人值守的上线,大大降低我们的上线过程的复杂沟通、操作风险。
2.13、Kubelet命令
Kubelet和Kube-proxy都运行在minion节点上。
Kube-proxy 实现Kubernetes网络相关内容。
Kubelet命令管理Pod、Pod中容器及容器的镜像和卷等信息。

2.14、总结
2.14.1、Kubernetes的架构
由一个master和多个minion组成,master通过api提供服务,接受kubectl的请求来调度管理整个集群。 kubectl: 是k8s平台的一个管理命令。
2.14.2、Replication controller
定义了多个pod或者容器需要运行,如果当前集群中运行的pod或容器达不到配置的数量,replication controller会调度容器在多个minion上运行,保证集群中的pod数量。
2.14.3、service
则定义真实对外提供的服务,一个service会对应后端运行的多个container。
2.14.4、Kubernetes
是个管理平台,minion上的kube-proxy 拥有提供真实服务公网IP。客户端访问kubernetes中提供的服务,是直接访问到kube-proxy上的。
2.14.5、pod
在Kubernetes中pod是一个基本单元,一个pod可以是提供相同功能的多个container,这些容器会被部署在同一个minion上。minion是运行Kubelet中容器的物理机。minion接受master的指令创建pod或者容器。
3、环境规划
| 节点角色 |
IP地址 |
Cpu |
内存 |
OS |
| master |
192.168.2.178 |
2core |
3G |
Centos7.4 |
| etcd |
192.168.2.178 |
2core |
3G |
Centos7.4 |
| Node1 |
192.168.2.179 |
2core |
3G |
Centos7.4 |
| Node2 |
192.168.2.180 |
2core |
3G |
Centos7.4 |
注:正常需要4台机器,如果你内存不够,master和etcd可以运行在同一台机器上。
4、环境准备
4.1、配置k8s的yum源(master)
我们使用的docker-1.12的版本。
把k8s-package.tar.gz上传到master节点上。
[root@master soft]# ll k8s-package.tar.gz
-rw-r--r-- 1 root root 186724113 Dec 18 19:18 k8s-package.tar.gz
[root@master soft]#
[root@master soft]# tar -xzvf k8s-package.tar.gz
[root@master soft]# ls
CentOS-7-x86_64-DVD-1708.iso k8s-package k8s-package.tar.gz
[root@master soft]# cp -R /soft/k8s-package /var/www/html/
[root@master html]# cd /var/www/html/
[root@master html]# ls
centos7.4 k8s-package
新建repo文件配置yum源
[root@master yum.repos.d]# cat /etc/yum.repos.d/k8s-package.repo
[k8s-package]
name=k8s-package
baseurl=http://192.168.2.178/k8s-package
enabled=1
gpgcheck=0
[root@master yum.repos.d]# cat local.repo
[centos7-Server]
name=centos7-Server
baseurl=http://192.168.2.178/centos7.4
enabled=1
gpgcheck=0
[root@master yum.repos.d]#
安装httpd服务(自行配置本地yum源)
yum -y install httpd
启动httpd服务
systemctl start httpd
systemctl enable httpd
创建httpd挂载目录
mkdir /var/www/html/centos7.4
挂载镜像到httpd
[root@master soft]# mount -o loop CentOS-7-x86_64-DVD-1708.iso /var/www/html/centos7.4/
mount: /soft/CentOS-7-x86_64-DVD-1708.iso is already mounted
清除yum源
[root@master html]# yum clean all
Loaded plugins: fastestmirror
Cleaning repos: centos7-Server k8s-package
Cleaning up everything
Maybe you want: rm -rf /var/cache/yum, to also free up space taken by orphaned data from disabled or removed repos
Cleaning up list of fastest mirrors
[root@master html]# yum makecache
Loaded plugins: fastestmirror
centos7-Server | 3.6 kB 00:00:00
k8s-package | 2.9 kB 00:00:00
(1/7): centos7-Server/group_gz | 156 kB 00:00:00
(2/7): centos7-Server/primary_db | 3.1 MB 00:00:00
(3/7): centos7-Server/filelists_db | 3.1 MB 00:00:00
(4/7): centos7-Server/other_db | 1.2 MB 00:00:00
(5/7): k8s-package/filelists_db | 14 kB 00:00:00
(6/7): k8s-package/other_db | 17 kB 00:00:00
(7/7): k8s-package/primary_db | 32 kB 00:00:00
Determining fastest mirrors
Metadata Cache Created
[root@master html]#
4.2、配置yum源(node1和node2)
从master上拷贝repo文件到另外两个节点
[root@master html]# scp /etc/yum.repos.d/local.repo /etc/yum.repos.d/k8s-package.repo 192.168.2.179:/etc/yum.repos.d/
root@192.168.2.179's password:
local.repo 100% 98 39.7KB/s 00:00
k8s-package.repo 100% 93 26.1KB/s 00:00
[root@master html]# scp /etc/yum.repos.d/local.repo /etc/yum.repos.d/k8s-package.repo 192.168.2.180:/etc/yum.repos.d/
root@192.168.2.180's password:
local.repo 100% 98 15.9KB/s 00:00
k8s-package.repo 100% 93 36.0KB/s 00:00
[root@master html]#
在另外两个节点上生成yum缓存
yum clean all
yum makecache
4.3、主机名规划
配置主机名
| IP |
主机名 |
| 192.168.2.178 |
master |
| 192.168.2.179 |
node1 |
| 192.168.2.180 |
node2 |
[root@master html]# cat /etc/hostname
Master
[root@node1 yum.repos.d]# cat /etc/hostname
node1
[root@node2 ~]# cat /etc/hostname
node2
4.4、配置/etc/hosts
配置/etc/hosts
三台机器都加入下面的红色部分
[root@master html]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.2.178 master etcd
192.168.2.179 node1
192.168.2.180 node2
4.5、配置时间同步
4.5.1、配置chrony服务端(master)
我们以master为时间同步服务器,另外两台同步master的时间
配置master
检查chrony包
[root@master html]# rpm -qa |grep chrony
[root@master html]#
安装chrony包
[root@master html]# yum -y install chrony
编辑chrony配置文件
[root@master html]# vi /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
# Record the rate at which the system clock gains/losses time.
driftfile /var/lib/chrony/drift
# Allow the system clock to be stepped in the first three updates
# if its offset is larger than 1 second.
makestep 1.0 3
# Enable kernel synchronization of the real-time clock (RTC).
rtcsync
# Enable hardware timestamping on all interfaces that support it.
#hwtimestamp *
# Increase the minimum number of selectable sources required to adjust
# the system clock.
#minsources 2
# Allow NTP client access from local network.
#allow 192.168.0.0/16
allow 192.168.0.0/16
# Serve time even if not synchronized to a time source.
#local stratum 10
local stratum 8
# Specify file containing keys for NTP authentication.
#keyfile /etc/chrony.keys
# Specify directory for log files.
logdir /var/log/chrony
# Select which information is logged.
#log measurements statistics tracking
飘红的部分是修改/增加的内容。
重启chrony服务
[root@master html]# systemctl restart chronyd
[root@master html]# systemctl enable chronyd
检查123端口监听
[root@master html]# netstat -an |grep 123
udp 0 0 0.0.0.0:123 0.0.0.0:*
unix 2 [ ACC ] STREAM LISTENING 23123 private/verify
4.5.2、配置chrony客户端(两个node节点都做)
检查chrony安装
[root@node1 yum.repos.d]# rpm -qa|grep chrony
[root@node1 yum.repos.d]#
安装chrony
[root@node1 yum.repos.d]# yum -y install chrony
编辑chrony配置文件
[root@node1 yum.repos.d]# vi /etc/chrony.conf
注释掉如下内容:
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
添加下面一行,master的ip地址
server 192.168.2.178 iburst
重启chrony服务
[root@node1 yum.repos.d]# systemctl restart chronyd
[root@node1 yum.repos.d]# systemctl enable chronyd
检查同步
[root@node1 yum.repos.d]# timedatectl
Local time: Sat 2019-12-21 12:19:49 CST
Universal time: Sat 2019-12-21 04:19:49 UTC
RTC time: Sat 2019-12-21 04:19:49
Time zone: Asia/Shanghai (CST, +0800)
NTP enabled: yes
NTP synchronized: yes
RTC in local TZ: no
DST active: n/a
[root@node1 yum.repos.d]# chronyc sources
210 Number of sources = 1
MS Name/IP address Stratum Poll Reach LastRx Last sample
===============================================================================
^* master 8 6 37 8 +562ns[+1331us] +/- 589us
[root@node1 yum.repos.d]#
4.6、关闭防火墙
所有节点都需要执行
[root@master html]# systemctl stop firewalld && systemctl disable firewalld && systemctl status firewalld
4.7、关闭selinux
所有节点都需要关闭selinux
[root@master html]# cat /etc/selinux/config
修改为:
SELINUX=disabled
5、安装k8s
5.1、安装包
5.1.1、master节点安装包
在master节点上安装如下包
[root@master html]# yum install -y kubernetes etcd flannel
注:Flannel为Docker提供一种可配置的虚拟重叠网络。实现跨物理机的容器之间能直接访问
1、Flannel在每一台主机上运行一个 agent。
2、flanneld,负责在提前配置好的地址空间中分配子网租约。Flannel使用etcd来存储网络配置。
3、chrony:主要用于同步容器云平台中所有结点的时间。云平台中结点的时间需要保持一致。
4、kubernetes 中包括了服务端和客户端相关的软件包
5、etcd是etcd服务的软件包
5.1.2、node节点安装包
两个node节点安装如下包
[root@node1 yum.repos.d]# yum install kubernetes flannel -y
#每个minion都要安装一样
5.2、配置etcd服务器
5.2.1、修改配置文件/etc/etcd/etcd.conf
按照规划,etcd服务运行在master节点上
vi /etc/etcd/etcd.conf
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://192.168.2.178:2379"
ETCD_ADVERTISE_CLIENT_URLS="http://192.168.2.178:2379"
5.2.2、配置文件说明
第一行红色的是加的,第二行红色的是改的,需要指定成自己的master的ip。
/etc/etcd/etcd.conf配置文件含意如下:
ETCD_NAME="default"
etcd节点名称,如果etcd集群只有一台etcd,这一项可以注释不用配置,默认名称为default,这个名字后面会用到。这里我们就用默认的。
ETCD_DATA_DIR="/var/lib/etcd/default.etcd"
etcd存储数据的目录,这里我们也是使用默认的。
ETCD_LISTEN_CLIENT_URLS="http://localhost:2379,http://192.168.1.63:2379"
etcd对外服务监听地址,一般默认端口就是2379端口,我们不改,如果为0.0.0.0将会监听所有接口
ETCD_ARGS=""
需要额外添加的参数,可以自己添加,etcd的所有参数可以通过etcd -h查看。
5.2.3、启动etcd服务
[root@master html]# systemctl start etcd
[root@master html]# systemctl enable etcd
5.2.4、检查etcd通讯端口
[root@master html]# netstat -antup | grep 2379
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 982/etcd
tcp 0 0 192.168.2.178:2379 0.0.0.0:* LISTEN 982/etcd
tcp 0 0 192.168.2.178:60368 192.168.2.178:2379 ESTABLISHED 982/etcd
tcp 0 0 127.0.0.1:37860 127.0.0.1:2379 ESTABLISHED 982/etcd
tcp 0 0 127.0.0.1:2379 127.0.0.1:37860 ESTABLISHED 982/etcd
tcp 0 0 192.168.2.178:2379 192.168.2.178:60368 ESTABLISHED 982/etcd
5.2.5、检查etcd集群成员表
[root@master html]# etcdctl member list
8e9e05c52164694d: name=default peerURLs=http://localhost:2380 clientURLs=http://192.168.2.178:2379 isLeader=true
5.2.6、检查etcd集群健康状态
[root@master html]# etcdctl cluster-health
member 8e9e05c52164694d is healthy: got healthy result from http://192.168.2.178:2379
cluster is healthy
到此etcd节点成功。
5.3、配置master服务
5.3.1、配置k8s配置文件
[root@master html]# vi /etc/kubernetes/config
KUBE_MASTER="--master=http://192.168.2.178:8080"
飘红的是改的。
指定master在192.168.2.178 IP上监听端口8080
5.3.2、config配置文件说明
注:/etc/kubernetes/config配置文件含意:
KUBE_LOGTOSTDERR="--logtostderr=true" #表示错误日志记录到文件还是输出到stderr标准错误输出。
KUBE_LOG_LEVEL="--v=0" #日志等级。
KUBE_ALLOW_PRIV="--allow_privileged=false" #是否允讲运行特权容器。false表示丌允讲特权容器
5.3.3、修改apiserver配置文件
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
KUBE_ETCD_SERVERS="--etcd-servers=http://192.168.2.178:2379"
上面飘红的是改的。
下面这行注释掉:
#KUBE_ADMISSION_CONTROL="--admission-control=NamespaceLifecycle,NamespaceExists,LimitRanger,SecurityContextDeny,ServiceAccount,ResourceQuota"
新增为如下内容:
KUBE_ADMISSION_CONTROL="--admission-control=AlwaysAdmit"
5.3.4、apiserver配置文件说明
注:/etc/kubernetes/apiserver配置文件含意:
KUBE_API_ADDRESS="--insecure-bind-address=0.0.0.0"
##监听的接口,如果配置为127.0.0.1则只监听localhost,配置为0.0.0.0会监听所有接口,这里配置为0.0.0.0。
KUBE_ETCD_SERVERS="--etcd-servers=http://192.168.2.178:2379"
#etcd服务地址,前面已经启动了etcd服务
KUBE_SERVICE_ADDRESSES="--service-cluster-ip-range=10.254.0.0/16"
#kubernetes可以分配的ip的范围,kubernetes启动的每一个pod以及serveice都会分配一个ip地址,将从这个范围中分配IP。
KUBE_ADMISSION_CONTROL="--admission-control=AlwaysAdmit"
#不做限制,允讲所有节点可以访问apiserver ,对所有请求开绿灯。
admission [ədˈmɪ.n] 承认;准讲迚入 , Admit [ədˈmɪt] 承认
扩展:
admission-control(准入控制) 概述:admission controller本质上一段代码,在对kubernetes api的请求过程中,顺序为 先经过认证和授权,然后执行准入操作,最后对目标对象迚行操作。
5.3.5、配置kube-controller-manager配置文件
cat /etc/kubernetes/controller-manager
该配置文件默认不需要改,够用。
配置kube-scheduler配置文件
5.3.6、配置scheduler配置文件
[root@master html]# vi /etc/kubernetes/scheduler
KUBE_SCHEDULER_ARGS="--address=0.0.0.0"
#改scheduler监听到的地址为:0.0.0.0,默认是127.0.0.1。
5.3.7、etcdctl命令使用
etcdctl 是操作etcd非关系型数据库的一个命令行客户端,它能提供一些简洁的命令,供用户直接跟 etcd 数据库打交道。
etcdctl 的命令,大体上分为数据库操作和非数据库操作两类。数据库操作主要是围绕对键值和目录的CRUD完整生命周期的管理。 注:CRUD 即 Create, Read, Update, Delete。
etcd在键的组织上采用了层次化的空间结构(类似于文件系统中目录的概念),用户指定的键可以为单独的名字,如 testkey,此时实际上放在根目录 / 下面,也可以为指定目录结构,如 cluster1/node2/testkey,则将创建相应的目录结构。
5.3.7.1、etcdctl数据库操作
5.3.7.1、set
指定某个键的值。
例如:
[root@master html]# etcdctl set mk "shen"
shen
5.3.7.2、get
[root@master html]# etcdctl get mk
shen
[root@master html]#
[root@master html]# etcdctl set /testdir/testkey "hello world"
hello world
[root@master html]# etcdctl get /testdir/testkey
hello world
[root@master html]#
5.3.7.3、update
当键存在时,更新值内容。
[root@master html]# etcdctl update /testdir/testkey aaaa
aaaa
[root@master html]# etcdctl get /testdir/testkey
aaaa
[root@master html]#
5.3.7.4、rm
删除某个键值。
[root@master html]# etcdctl rm mk
PrevNode.Value: shen
[root@master html]# etcdctl rm /testdir/testkey
PrevNode.Value: aaaa
[root@master html]#
5.3.7.5、etcdctl mk和etcdctl set区别
etcdctl mk 如果给定的键不存在,则创建一个新的键值。如果给定的键存在,则报错,无法创建。etcdctl set ,不管给定的键是否存在,都会创建一个新的键值。
[root@master html]# etcdctl mk /testdir/testkey "Hello world"
Hello world
[root@master html]# etcdctl mk /testdir/testkey "bbbb"
Error: 105: Key already exists (/testdir/testkey) [728]
[root@master html]#
5.3.7.6、mkdir
创建一个目录
[root@master html]# etcdctl mkdir testdir1
[root@master html]#
5.3.7.7、ls
列出目录(默认为根目录)下的键或者子目录,默认不显示子目录中内容。
[root@master html]# etcdctl ls
/registry
/testdir1
/testdir
/k8s
[root@master html]#
[root@master html]# etcdctl ls /testdir
/testdir/testkey
[root@master html]#
5.3.7.2、etcdctl非数据库操作
etcdctl member 后面可以加参数list、add、remove 命令。表示列出、添加、删除 etcd 实例到 etcd 集群中。
5.3.7.2.1、list
例如本地启动一个 etcd 服务实例后,可以用如下命令进行查看。
[root@master html]# etcdctl member list
8e9e05c52164694d: name=default peerURLs=http://localhost:2380 clientURLs=http://192.168.2.178:2379 isLeader=true
[root@master html]#
5.3.7.2.2、add
我们这里就一个etcd服务器,add就不做了。
5.3.7.2.3、remove
我们这里就一个etcd服务器,add就不做了。
5.3.8、设置etcd网络
5.3.8.1、创建目录
[root@master html]# etcdctl mkdir /k8s/network
Error: 105: Key already exists (/k8s/network) [729]
[root@master html]#
创建一个目录/ k8s/network用于存储flannel网络信息 。
我这里原来已经创建了,所以报错,没关系,我们需要创建这个目录,后面会用到。
5.3.8.2、设置值
[root@master html]# etcdctl set /k8s/network/config '{"Network": "10.255.0.0/16"}'
给/k8s/network/config 赋一个字符串的值 '{"Network": "10.255.0.0/16"}' ,这个后续会用到。
查看我们设置的值
[root@master html]# etcdctl get /k8s/network/config
{"Network":"10.255.0.0/16"}
注:在启动flannel之前,需要在etcd中添加一条网络配置记录,这个配置将用于flannel分配给每个docker的虚拟IP地址段。用于配置在minion上docker的IP地址.
由于flannel将覆盖docker0上的地址,所以flannel服务要先于docker服务启动。如果docker服务已经启动,则先停止docker服务,然后启动flannel,再启动docker。
5.9、配置flanneld服务
5.9.1、flannel启动过程解析
从etcd中获取出/k8s/network/config的值
划分subnet子网,并在etcd中进行注册
将子网信息记录到/run/flannel/subnet.env中
5.9.2、配置flanneld服务
vi /etc/sysconfig/flanneld
FLANNEL_ETCD_ENDPOINTS="http://192.168.2.178:2379"
FLANNEL_ETCD_PREFIX="/k8s/network"
FLANNEL_OPTIONS="--iface=ens33"
分别指定etcd服务端地址,网络路径和通信的物理网卡。
物理网卡可以通过ifconfig -a查看:
[root@master html]# ifconfig -a
ens33: flags=4163
inet 192.168.2.178 netmask 255.255.255.0 broadcast 192.168.2.255
inet6 fe80::60d3:d739:1f01:9258 prefixlen 64 scopeid 0x20
ether 00:0c:29:d8:be:5b txqueuelen 1000 (Ethernet)
RX packets 4618 bytes 421413 (411.5 KiB)
RX errors 0 dropped 2 overruns 0 frame 0
TX packets 13473 bytes 17541537 (16.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
5.9.3、启动flanneld服务
[root@master html]# systemctl start flanneld
[root@master html]# systemctl enable flanneld
Created symlink from /etc/systemd/system/multi-user.target.wants/flanneld.service to /usr/lib/systemd/system/flanneld.service.
Created symlink from /etc/systemd/system/docker.service.requires/flanneld.service to /usr/lib/systemd/system/flanneld.service.
[root@master html]# systemctl status flanneld
● flanneld.service - Flanneld overlay address etcd agent
Loaded: loaded (/usr/lib/systemd/system/flanneld.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 18:35:02 CST; 20s ago
Main PID: 12413 (flanneld)
CGroup: /system.slice/flanneld.service
└─12413 /usr/bin/flanneld -etcd-endpoints=http://192.168.2.178:2379 -etcd-prefix=/k8s/network --iface...
Dec 21 18:35:02 master systemd[1]: Starting Flanneld overlay address etcd agent...
Dec 21 18:35:02 master flanneld-start[12413]: I1221 18:35:02.719599 12413 main.go:132] Installing signal handlers
Dec 21 18:35:02 master flanneld-start[12413]: I1221 18:35:02.720139 12413 manager.go:149] Using interface ....178
Dec 21 18:35:02 master flanneld-start[12413]: I1221 18:35:02.720164 12413 manager.go:166] Defaulting exter...178)
Dec 21 18:35:02 master flanneld-start[12413]: I1221 18:35:02.722622 12413 local_manager.go:179] Picking su...55.0
Dec 21 18:35:02 master flanneld-start[12413]: I1221 18:35:02.741850 12413 manager.go:250] Lease acquired: ...0/24
Dec 21 18:35:02 master flanneld-start[12413]: I1221 18:35:02.742097 12413 network.go:98] Watching for new ...ases
Dec 21 18:35:02 master systemd[1]: Started Flanneld overlay address etcd agent.
Hint: Some lines were ellipsized, use -l to show in full.
[root@master html]#
5.9.4、查看flanneld服务网卡
[root@master html]# ifconfig -a
ens33: flags=4163
inet 192.168.2.178 netmask 255.255.255.0 broadcast 192.168.2.255
inet6 fe80::60d3:d739:1f01:9258 prefixlen 64 scopeid 0x20
ether 00:0c:29:d8:be:5b txqueuelen 1000 (Ethernet)
RX packets 4856 bytes 446523 (436.0 KiB)
RX errors 0 dropped 2 overruns 0 frame 0
TX packets 13605 bytes 17565375 (16.7 MiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel0: flags=4305
inet 10.255.91.0 netmask 255.255.0.0 destination 10.255.91.0
inet6 fe80::cc29:5eca:e542:e3fa prefixlen 64 scopeid 0x20
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3 bytes 144 (144.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
5.9.5、查看子网信息
[root@master html]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.255.0.0/16
FLANNEL_SUBNET=10.255.91.1/24
FLANNEL_MTU=1472
FLANNEL_IPMASQ=false
[root@master html]#
之后将会有一个脚本将subnet.env转写成一个docker的环境变量文件/run/flannel/docker。docker0的地址是由 /run/flannel/subnet.env 的 FLANNEL_SUBNET 参数决定的。
[root@master html]# cat /run/flannel/docker
DOCKER_OPT_BIP="--bip=10.255.91.1/24"
DOCKER_OPT_IPMASQ="--ip-masq=true"
DOCKER_OPT_MTU="--mtu=1472"
DOCKER_NETWORK_OPTIONS=" --bip=10.255.91.1/24 --ip-masq=true --mtu=1472"
[root@master html]#
5.10、启动master上bube-apiserver服务
[root@master html]# systemctl restart kube-apiserver
[root@master html]# systemctl enable kube-apiserver
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-apiserver.service to /usr/lib/systemd/system/kube-apiserver.service.
[root@master html]# systemctl status kube-apiserver
● kube-apiserver.service - Kubernetes API Server
Loaded: loaded (/usr/lib/systemd/system/kube-apiserver.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 18:40:02 CST; 32s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 12495 (kube-apiserver)
CGroup: /system.slice/kube-apiserver.service
└─12495 /usr/bin/kube-apiserver --logtostderr=true --v=0 --etcd-servers=http://192.168.2.178:2379 --i...
5.11、启动master上kube-controller-manager 服务
[root@master html]# systemctl restart kube-controller-manager
[root@master html]# systemctl enable kube-controller-manager
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-controller-manager.service to /usr/lib/systemd/system/kube-controller-manager.service.
[root@master html]# systemctl status kube-controller-manager
● kube-controller-manager.service - Kubernetes Controller Manager
Loaded: loaded (/usr/lib/systemd/system/kube-controller-manager.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 18:41:47 CST; 13s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 12527 (kube-controller)
CGroup: /system.slice/kube-controller-manager.service
└─12527 /usr/bin/kube-controller-manager --logtostderr=true --v=0 --master=http://192.168.2.178:8080
5.12、启动master上kube-scheduler服务
[root@master html]# systemctl restart kube-scheduler
[root@master html]# systemctl enable kube-scheduler
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-scheduler.service to /usr/lib/systemd/system/kube-scheduler.service.
[root@master html]# systemctl status kube-scheduler
● kube-scheduler.service - Kubernetes Scheduler Plugin
Loaded: loaded (/usr/lib/systemd/system/kube-scheduler.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 18:43:09 CST; 13s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 12559 (kube-scheduler)
CGroup: /system.slice/kube-scheduler.service
└─12559 /usr/bin/kube-scheduler --logtostderr=true --v=0 --master=http://192.168.2.178:8080 --address...
至此etcd和master节点成功。
5.4、配置node1 minion
5.4.1、配置node1上的flanneld
5.4.1.1、从master上拷贝flanneld配置文件
我们直接在node1上执行scp命令,从master复制该文件过来
[root@node1 yum.repos.d]# scp 192.168.2.178:/etc/sysconfig/flanneld /etc/sysconfig/flanneld
The authenticity of host '192.168.2.178 (192.168.2.178)' can't be established.
ECDSA key fingerprint is SHA256:Izdvj8GeIvx0CwRk7VfCqwhWtkpLFkmmFNyxXbRwlZQ.
ECDSA key fingerprint is MD5:37:34:aa:ec:34:95:cd:1a:a0:ce:4a:38:d0:f9:87:de.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added '192.168.2.178' (ECDSA) to the list of known hosts.
root@192.168.2.178's password:
flanneld 100% 412 38.3KB/s 00:00
5.4.1.2、在node1上启动flanneld服务
[root@node1 yum.repos.d]# systemctl restart flanneld
[root@node1 yum.repos.d]# systemctl enable flanneld
[root@node1 yum.repos.d]# systemctl status flanneld
● flanneld.service - Flanneld overlay address etcd agent
Loaded: loaded (/usr/lib/systemd/system/flanneld.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:03:05 CST; 35s ago
Main PID: 2398 (flanneld)
CGroup: /system.slice/flanneld.service
└─2398 /usr/bin/flanneld -etcd-endpoints=http://192.168.2.178:2379 -etcd-prefix=/k8s/network --iface=...
Dec 21 19:03:05 node1 systemd[1]: Starting Flanneld overlay address etcd agent...
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.372411 2398 main.go:132] Installing signal handlers
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.372712 2398 manager.go:149] Using interface w...2.179
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.372724 2398 manager.go:166] Defaulting extern....179)
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.376068 2398 local_manager.go:179] Picking sub...255.0
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.382847 2398 manager.go:250] Lease acquired: 1....0/24
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.384297 2398 network.go:98] Watching for new s...eases
Dec 21 19:03:05 node1 flanneld-start[2398]: I1221 19:03:05.392479 2398 network.go:191] Subnet added: 10.....0/24
Dec 21 19:03:05 node1 systemd[1]: Started Flanneld overlay address etcd agent.
Hint: Some lines were ellipsized, use -l to show in full.
5.4.2、配置node1上master地址
[root@node1 yum.repos.d]# vi /etc/kubernetes/config
KUBE_MASTER="--master=http://192.168.2.178:8080"
飘红的是master的地址。
5.4.3、配置node1上的kube-proxy服务
kube-proxy的作用主要是负责service的实现,具体来说,就是实现了内部从pod到service。
[root@node1 yum.repos.d]# grep -v '^#' /etc/kubernetes/proxy
KUBE_PROXY_ARGS=""
[root@node1 yum.repos.d]#
不用修改,默认就是监听所有ip。
注:如果启动服务失败,可以使用tail -f /var/log/messages 动态查看日志。
5.4.4、配置node1 kubelet
Kubelet运行在minion节点上。Kubelet组件管理Pod、Pod中容器及容器的镜像和卷等信息。
[root@node1 yum.repos.d]# vi /etc/kubernetes/kubelet
KUBELET_ADDRESS="--address=0.0.0.0"
#默认只监听127.0.0.1,要改成:0.0.0.0,因为后期要使用kubectl进程连接到kubelet服务上,来查看pod及pod中容器的状态。如果是127就无法进程连接kubelet服务。
KUBELET_HOSTNAME="--hostname-override=node1"
# minion的主机名,设置成和本主机机名一样,便于识别。
KUBELET_API_SERVER="--api-servers=http://192.168.2.178:8080"
#指定apiserver的地址
扩展:第17行的意思:
KUBELET_POD_INFRA_CONTAINER="--pod-infra-container-image=registry.access.redhat.com/rhel7/pod-infrastructure:latest"
KUBELET_POD_INFRA_CONTAINER 指定pod基础容器镜像地址。这个是一个基础容器,每一个Pod启动的时候都会启动一个这样的容器。如果你的本地没有这个镜像,kubelet会连接外网把这个镜像下载下来。最开始的时候是在Google的registry上,因此国内因为GFW都下载不了导致Pod运行不起来。现在每个版本的Kubernetes都把这个镜像地址改成红帽的地址了。你也可以提前传到自己的registry上,然后再用这个参数指定成自己的镜像链接。
注:https://access.redhat.com/containers/ 是红帽的容器下载站点
5.4.5、启动node1上所有服务
[root@node1 yum.repos.d]# systemctl restart flanneld kube-proxy kubelet docker
[root@node1 yum.repos.d]# systemctl enable flanneld kube-proxy kubelet docker
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-proxy.service to /usr/lib/systemd/system/kube-proxy.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
[root@node1 yum.repos.d]# systemctl status flanneld kube-proxy kubelet docker
● flanneld.service - Flanneld overlay address etcd agent
Loaded: loaded (/usr/lib/systemd/system/flanneld.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:16:57 CST; 20s ago
Main PID: 2485 (flanneld)
CGroup: /system.slice/flanneld.service
└─2485 /usr/bin/flanneld -etcd-endpoints=http://192.168.2.178:2379 -etcd-prefix=/k8s/network --iface=ens33
Dec 21 19:16:56 node1 systemd[1]: Starting Flanneld overlay address etcd agent...
Dec 21 19:16:56 node1 flanneld-start[2485]: I1221 19:16:56.894429 2485 main.go:132] Installing signal handlers
Dec 21 19:16:56 node1 flanneld-start[2485]: I1221 19:16:56.896023 2485 manager.go:149] Using interface with name ens....2.179
Dec 21 19:16:56 node1 flanneld-start[2485]: I1221 19:16:56.896048 2485 manager.go:166] Defaulting external address t...2.179)
Dec 21 19:16:57 node1 flanneld-start[2485]: I1221 19:16:57.041167 2485 local_manager.go:134] Found lease (10.255.31....eusing
Dec 21 19:16:57 node1 flanneld-start[2485]: I1221 19:16:57.047416 2485 manager.go:250] Lease acquired: 10.255.31.0/24
Dec 21 19:16:57 node1 flanneld-start[2485]: I1221 19:16:57.052767 2485 network.go:98] Watching for new subnet leases
Dec 21 19:16:57 node1 flanneld-start[2485]: I1221 19:16:57.156192 2485 network.go:191] Subnet added: 10.255.91.0/24
Dec 21 19:16:57 node1 systemd[1]: Started Flanneld overlay address etcd agent.
● kube-proxy.service - Kubernetes Kube-Proxy Server
Loaded: loaded (/usr/lib/systemd/system/kube-proxy.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:16:56 CST; 20s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 2482 (kube-proxy)
CGroup: /system.slice/kube-proxy.service
└─2482 /usr/bin/kube-proxy --logtostderr=true --v=0 --master=http://192.168.2.178:8080
Dec 21 19:16:57 node1 kube-proxy[2482]: E1221 19:16:57.979426 2482 server.go:421] Can't get Node "node1", assuming i... found
Dec 21 19:16:57 node1 kube-proxy[2482]: I1221 19:16:57.988178 2482 server.go:215] Using iptables Proxier.
Dec 21 19:16:57 node1 kube-proxy[2482]: W1221 19:16:57.991189 2482 server.go:468] Failed to retrieve node info: node... found
Dec 21 19:16:57 node1 kube-proxy[2482]: W1221 19:16:57.991276 2482 proxier.go:248] invalid nodeIP, initialize kube-p...nodeIP
Dec 21 19:16:57 node1 kube-proxy[2482]: W1221 19:16:57.991284 2482 proxier.go:253] clusterCIDR not specified, unable...raffic
Dec 21 19:16:57 node1 kube-proxy[2482]: I1221 19:16:57.991295 2482 server.go:227] Tearing down userspace rules.
Dec 21 19:16:58 node1 kube-proxy[2482]: I1221 19:16:58.159672 2482 conntrack.go:81] Set sysctl 'net/netfilter/nf_con...131072
Dec 21 19:16:58 node1 kube-proxy[2482]: I1221 19:16:58.160025 2482 conntrack.go:66] Setting conntrack hashsize to 32768
Dec 21 19:16:58 node1 kube-proxy[2482]: I1221 19:16:58.167384 2482 conntrack.go:81] Set sysctl 'net/netfilter/nf_con... 86400
Dec 21 19:16:58 node1 kube-proxy[2482]: I1221 19:16:58.167418 2482 conntrack.go:81] Set sysctl 'net/netfilter/nf_con...o 3600
● kubelet.service - Kubernetes Kubelet Server
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:16:59 CST; 17s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 2749 (kubelet)
CGroup: /system.slice/kubelet.service
├─2749 /usr/bin/kubelet --logtostderr=true --v=0 --api-servers=http://192.168.2.178:8080 --address=0.0.0.0 --hostn...
└─2777 journalctl -k -f
Dec 21 19:17:00 node1 kubelet[2749]: W1221 19:17:00.302581 2749 manager.go:247] Registration of the rkt container f...refused
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.302604 2749 factory.go:54] Registering systemd factory
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.302763 2749 factory.go:86] Registering Raw factory
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.302937 2749 manager.go:1106] Started watching for new ooms in manager
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.305309 2749 oomparser.go:185] oomparser using systemd
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.305820 2749 manager.go:288] Starting recovery of all containers
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.402033 2749 manager.go:293] Recovery completed
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.403468 2749 kubelet_node_status.go:227] Setting node annotation.../detach
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.418293 2749 kubelet_node_status.go:74] Attempting to register node node1
Dec 21 19:17:00 node1 kubelet[2749]: I1221 19:17:00.422640 2749 kubelet_node_status.go:77] Successfully registered node node1
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/docker.service.d
└─flannel.conf
Active: active (running) since Sat 2019-12-21 19:16:59 CST; 17s ago
Docs: http://docs.docker.com
Main PID: 2590 (dockerd-current)
CGroup: /system.slice/docker.service
├─2590 /usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtim...
└─2603 /usr/bin/docker-containerd-current -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --shim do...
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.594451020+08:00" level=info msg="devmapper: Succ...-base"
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.631433746+08:00" level=warning msg="Docker could...ystem"
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.651862493+08:00" level=info msg="Graph migration...conds"
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.652393784+08:00" level=info msg="Loading contain...tart."
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.690533063+08:00" level=info msg="Firewalld runni...false"
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.862388053+08:00" level=info msg="Loading contain...done."
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.862480340+08:00" level=info msg="Daemon has comp...ation"
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.862493915+08:00" level=info msg="Docker daemon" ...1.12.6
Dec 21 19:16:59 node1 systemd[1]: Started Docker Application Container Engine.
Dec 21 19:16:59 node1 dockerd-current[2590]: time="2019-12-21T19:16:59.883346725+08:00" level=info msg="API listen on /....sock"
Hint: Some lines were ellipsized, use -l to show in full.
[root@node1 yum.repos.d]#
我们可以看到我们启动了4个服务,有4个running状态,说明服务启动都是ok的。
5.4.6、查看网卡
[root@node1 yum.repos.d]# ifconfig -a
docker0: flags=4099
inet 10.255.31.1 netmask 255.255.255.0 broadcast 0.0.0.0
ether 02:42:c8:81:a9:a3 txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163
inet 192.168.2.179 netmask 255.255.255.0 broadcast 192.168.2.255
inet6 fe80::ab54:d555:c844:3d6b prefixlen 64 scopeid 0x20
ether 00:0c:29:da:c8:bd txqueuelen 1000 (Ethernet)
RX packets 9438 bytes 9035501 (8.6 MiB)
RX errors 0 dropped 3 overruns 0 frame 0
TX packets 2039 bytes 323350 (315.7 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel0: flags=4305
inet 10.255.31.0 netmask 255.255.0.0 destination 10.255.31.0
inet6 fe80::79de:95ca:6514:fbe4 prefixlen 64 scopeid 0x20
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3 bytes 144 (144.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
5.4.7、查看kube-proxy
[root@node1 yum.repos.d]# netstat -antup | grep proxy
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 2482/kube-proxy
tcp 0 0 192.168.2.179:35532 192.168.2.178:8080 ESTABLISHED 2482/kube-proxy
tcp 0 0 192.168.2.179:35534 192.168.2.178:8080 ESTABLISHED 2482/kube-proxy
[root@node1 yum.repos.d]#
到此node1 minion节点成了。
5.5、配置node2 minion
所有的minion配置都是一样,所以我们可以直接拷贝node1的配置文件到node2上即可启动服务。
5.5.1、拷贝配置文件
在node1上执行拷贝:
[root@node1 yum.repos.d]# scp /etc/sysconfig/flanneld 192.168.2.180:/etc/sysconfig/
[root@node1 yum.repos.d]# scp /etc/kubernetes/config 192.168.2.180:/etc/kubernetes/
[root@node1 yum.repos.d]# scp /etc/kubernetes/proxy 192.168.2.180:/etc/kubernetes/
[root@node1 yum.repos.d]# scp /etc/kubernetes/kubelet 192.168.2.180:/etc/kubernetes/
5.5.2、微改配置文件
注意这个地方需要修改:
[root@node2 ~]# vi /etc/kubernetes/kubelet
KUBELET_HOSTNAME="--hostname-override=node2"
这里要改成minion 2的主机名。
5.5.3、启动node2所有服务
[root@node2 ~]# systemctl restart flanneld kube-proxy kubelet docker
[root@node2 ~]# systemctl enable flanneld kube-proxy kubelet docker
Created symlink from /etc/systemd/system/multi-user.target.wants/flanneld.service to /usr/lib/systemd/system/flanneld.service.
Created symlink from /etc/systemd/system/docker.service.requires/flanneld.service to /usr/lib/systemd/system/flanneld.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/kube-proxy.service to /usr/lib/systemd/system/kube-proxy.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/kubelet.service to /usr/lib/systemd/system/kubelet.service.
Created symlink from /etc/systemd/system/multi-user.target.wants/docker.service to /usr/lib/systemd/system/docker.service.
5.5.4、查看node2上所有服务
[root@node2 ~]# systemctl status flanneld kube-proxy kubelet docker
● flanneld.service - Flanneld overlay address etcd agent
Loaded: loaded (/usr/lib/systemd/system/flanneld.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:39:06 CST; 1min 25s ago
Main PID: 2403 (flanneld)
CGroup: /system.slice/flanneld.service
└─2403 /usr/bin/flanneld -etcd-endpoints=http://192.168.2.178:2379 -etcd-prefix=/k8s/network --iface=ens33
Dec 21 19:39:06 node2 systemd[1]: Starting Flanneld overlay address etcd agent...
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.735912 2403 main.go:132] Installing signal handlers
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.738072 2403 manager.go:149] Using interface with name ens....2.180
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.738101 2403 manager.go:166] Defaulting external address t...2.180)
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.786030 2403 local_manager.go:179] Picking subnet in range....255.0
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.805631 2403 manager.go:250] Lease acquired: 10.255.73.0/24
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.813400 2403 network.go:98] Watching for new subnet leases
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.821537 2403 network.go:191] Subnet added: 10.255.91.0/24
Dec 21 19:39:06 node2 flanneld-start[2403]: I1221 19:39:06.821555 2403 network.go:191] Subnet added: 10.255.31.0/24
Dec 21 19:39:06 node2 systemd[1]: Started Flanneld overlay address etcd agent.
● kube-proxy.service - Kubernetes Kube-Proxy Server
Loaded: loaded (/usr/lib/systemd/system/kube-proxy.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:39:06 CST; 1min 26s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 2404 (kube-proxy)
CGroup: /system.slice/kube-proxy.service
└─2404 /usr/bin/kube-proxy --logtostderr=true --v=0 --master=http://192.168.2.178:8080
Dec 21 19:39:07 node2 kube-proxy[2404]: E1221 19:39:07.546923 2404 server.go:421] Can't get Node "node2", assuming i... found
Dec 21 19:39:07 node2 kube-proxy[2404]: I1221 19:39:07.548664 2404 server.go:215] Using iptables Proxier.
Dec 21 19:39:07 node2 kube-proxy[2404]: W1221 19:39:07.550017 2404 server.go:468] Failed to retrieve node info: node... found
Dec 21 19:39:07 node2 kube-proxy[2404]: W1221 19:39:07.550089 2404 proxier.go:248] invalid nodeIP, initialize kube-p...nodeIP
Dec 21 19:39:07 node2 kube-proxy[2404]: W1221 19:39:07.550098 2404 proxier.go:253] clusterCIDR not specified, unable...raffic
Dec 21 19:39:07 node2 kube-proxy[2404]: I1221 19:39:07.550110 2404 server.go:227] Tearing down userspace rules.
Dec 21 19:39:07 node2 kube-proxy[2404]: I1221 19:39:07.689675 2404 conntrack.go:81] Set sysctl 'net/netfilter/nf_con...131072
Dec 21 19:39:07 node2 kube-proxy[2404]: I1221 19:39:07.689901 2404 conntrack.go:66] Setting conntrack hashsize to 32768
Dec 21 19:39:07 node2 kube-proxy[2404]: I1221 19:39:07.689987 2404 conntrack.go:81] Set sysctl 'net/netfilter/nf_con... 86400
Dec 21 19:39:07 node2 kube-proxy[2404]: I1221 19:39:07.689998 2404 conntrack.go:81] Set sysctl 'net/netfilter/nf_con...o 3600
● kubelet.service - Kubernetes Kubelet Server
Loaded: loaded (/usr/lib/systemd/system/kubelet.service; enabled; vendor preset: disabled)
Active: active (running) since Sat 2019-12-21 19:39:09 CST; 1min 23s ago
Docs: https://github.com/GoogleCloudPlatform/kubernetes
Main PID: 2660 (kubelet)
CGroup: /system.slice/kubelet.service
├─2660 /usr/bin/kubelet --logtostderr=true --v=0 --api-servers=http://192.168.2.178:8080 --address=0.0.0.0 --hostn...
└─2688 journalctl -k -f
Dec 21 19:39:09 node2 kubelet[2660]: W1221 19:39:09.890184 2660 manager.go:247] Registration of the rkt container f...refused
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.890230 2660 factory.go:54] Registering systemd factory
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.890446 2660 factory.go:86] Registering Raw factory
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.890648 2660 manager.go:1106] Started watching for new ooms in manager
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.895816 2660 oomparser.go:185] oomparser using systemd
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.896338 2660 manager.go:288] Starting recovery of all containers
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.982917 2660 manager.go:293] Recovery completed
Dec 21 19:39:09 node2 kubelet[2660]: I1221 19:39:09.998995 2660 kubelet_node_status.go:227] Setting node annotation.../detach
Dec 21 19:39:10 node2 kubelet[2660]: I1221 19:39:10.000193 2660 kubelet_node_status.go:74] Attempting to register node node2
Dec 21 19:39:10 node2 kubelet[2660]: I1221 19:39:10.004958 2660 kubelet_node_status.go:77] Successfully registered node node2
● docker.service - Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/docker.service; enabled; vendor preset: disabled)
Drop-In: /usr/lib/systemd/system/docker.service.d
└─flannel.conf
Active: active (running) since Sat 2019-12-21 19:39:09 CST; 1min 23s ago
Docs: http://docs.docker.com
Main PID: 2496 (dockerd-current)
CGroup: /system.slice/docker.service
├─2496 /usr/bin/dockerd-current --add-runtime docker-runc=/usr/libexec/docker/docker-runc-current --default-runtim...
└─2512 /usr/bin/docker-containerd-current -l unix:///var/run/docker/libcontainerd/docker-containerd.sock --shim do...
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.075412800+08:00" level=info msg="devmapper: Succ...-base"
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.111063008+08:00" level=warning msg="Docker could...ystem"
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.129224027+08:00" level=info msg="Graph migration...conds"
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.130233548+08:00" level=info msg="Loading contain...tart."
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.158633597+08:00" level=info msg="Firewalld runni...false"
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.232333949+08:00" level=info msg="Loading contain...done."
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.232422260+08:00" level=info msg="Daemon has comp...ation"
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.232432256+08:00" level=info msg="Docker daemon" ...1.12.6
Dec 21 19:39:09 node2 dockerd-current[2496]: time="2019-12-21T19:39:09.249587277+08:00" level=info msg="API listen on /....sock"
Dec 21 19:39:09 node2 systemd[1]: Started Docker Application Container Engine.
Hint: Some lines were ellipsized, use -l to show in full.
[root@node2 ~]#
5.5.5、查看网卡
[root@node2 ~]# ifconfig -a
docker0: flags=4099
inet 10.255.73.1 netmask 255.255.255.0 broadcast 0.0.0.0
ether 02:42:48:7f:f8:3c txqueuelen 0 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
ens33: flags=4163
inet 192.168.2.180 netmask 255.255.255.0 broadcast 192.168.2.255
inet6 fe80::950e:ef22:9f8d:fed6 prefixlen 64 scopeid 0x20
ether 00:0c:29:4e:26:64 txqueuelen 1000 (Ethernet)
RX packets 8491 bytes 8987676 (8.5 MiB)
RX errors 0 dropped 3 overruns 0 frame 0
TX packets 1363 bytes 263495 (257.3 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
flannel0: flags=4305
inet 10.255.73.0 netmask 255.255.0.0 destination 10.255.73.0
inet6 fe80::e105:ef44:47f9:b20d prefixlen 64 scopeid 0x20
unspec 00-00-00-00-00-00-00-00-00-00-00-00-00-00-00-00 txqueuelen 500 (UNSPEC)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 3 bytes 144 (144.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
注:flannel0是flanneld服务启动的。
上面的docker0网卡的值是根据以下来的
[root@node2 ~]# cat /run/flannel/
docker subnet.env
[root@node2 ~]# cat /run/flannel/subnet.env
FLANNEL_NETWORK=10.255.0.0/16
FLANNEL_SUBNET=10.255.73.1/24
FLANNEL_MTU=1472
FLANNEL_IPMASQ=false
[root@node2 ~]#
5.5.6、查看kube-proxy
[root@node2 ~]# netstat -antup | grep proxy
tcp 0 0 127.0.0.1:10249 0.0.0.0:* LISTEN 2404/kube-proxy
tcp 0 0 192.168.2.180:58772 192.168.2.178:8080 ESTABLISHED 2404/kube-proxy
tcp 0 0 192.168.2.180:58770 192.168.2.178:8080 ESTABLISHED 2404/kube-proxy
[root@node2 ~]#
Kubeproxy监听端口号是10249。Kubeproxy和master的8080进行通信。
[root@node2 ~]# netstat -antup | grep 8080
tcp 0 0 192.168.2.180:58772 192.168.2.178:8080 ESTABLISHED 2404/kube-proxy
tcp 0 0 192.168.2.180:58770 192.168.2.178:8080 ESTABLISHED 2404/kube-proxy
tcp 0 0 192.168.2.180:58792 192.168.2.178:8080 ESTABLISHED 2660/kubelet
tcp 0 0 192.168.2.180:58784 192.168.2.178:8080 ESTABLISHED 2660/kubelet
tcp 0 0 192.168.2.180:58786 192.168.2.178:8080 ESTABLISHED 2660/kubelet
tcp 0 0 192.168.2.180:58782 192.168.2.178:8080 ESTABLISHED 2660/kubelet
查看kubelete服务连接是否建立,此处我们发现已经建立。
5.6、查看整个k8s集群状态
[root@master html]# kubectl get nodes
NAME STATUS AGE
node1 Ready 32m
node2 Ready 10m
[root@master html]#
至此说明运行正常。
至此,整个k8s集群搭建完毕。
5.7、集群服务总结
在本实验中kubernetes 4个结点一共需要启动13个服务,开6个端口号。
详情如下:
5.7.1、etcd
一共1个服务 ,通讯使用2379端口
启动服务
[root@xuegod63 ~]#systemctl restart etcd
[root@master html]# netstat -antup | grep etcd
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN 982/etcd
tcp 0 0 192.168.2.178:2379 0.0.0.0:* LISTEN 982/etcd
tcp 0 0 127.0.0.1:2380 0.0.0.0:* LISTEN 982/etcd
5.7.2、master
一共4个服务,通讯使用8080端口
[root@xuegod63 ~]# systemctl restart kube-apiserver kube-controller-manager kube-scheduler flanneld
[root@master html]# netstat -antup | grep kube-apiserve
tcp6 0 0 :::6443 :::* LISTEN 12495/kube-apiserve
tcp6 0 0 :::8080 :::* LISTEN 12495/kube-apiserve
[root@master ~]# netstat -antup | grep kube-controll
tcp6 0 0 :::10252 :::* LISTEN 12527/kube-controll
[root@master ~]# netstat -antup | grep kube-schedule
tcp6 0 0 :::10251 :::* LISTEN 12559/kube-schedule
[root@master ~]# netstat -antup | grep flanneld
tcp 0 0 192.168.2.178:60480 192.168.2.178:2379 ESTABLISHED 12413/flanneld
tcp 0 0 192.168.2.178:60482 192.168.2.178:2379 ESTABLISHED 12413/flanneld
udp 0 0 192.168.2.178:8285 0.0.0.0:* 12413/flanneld
5.7.3、node1-minion
一共4个服务
kubeproxy 监控听端口号是 10249 ,kubelet 监听端口10248、10250、10255三个端口
[root@node1 ~]# systemctl restart flanneld kube-proxy kubelet docker
[root@node1 yum.repos.d]# netstat -autup | grep kube-proxy
tcp 0 0 localhost:10249 0.0.0.0:* LISTEN 2482/kube-proxy
tcp 0 0 node1:35532 master:webcache ESTABLISHED 2482/kube-proxy
tcp 0 0 node1:35534 master:webcache ESTABLISHED 2482/kube-proxy
[root@node1 yum.repos.d]# netstat -autup | grep kubelet
tcp 0 0 localhost:10248 0.0.0.0:* LISTEN 2749/kubelet
tcp 0 0 node1:35546 master:webcache ESTABLISHED 2749/kubelet
tcp 0 0 node1:35544 master:webcache ESTABLISHED 2749/kubelet
tcp 0 0 node1:35550 master:webcache ESTABLISHED 2749/kubelet
tcp 0 0 node1:35542 master:webcache ESTABLISHED 2749/kubelet
tcp6 0 0 [::]:10255 [::]:* LISTEN 2749/kubelet
tcp6 0 0 [::]:4194 [::]:* LISTEN 2749/kubelet
tcp6 0 0 [::]:10250 [::]:* LISTEN 2749/kubelet
5.7.4、node2-minion
一共4个服务
[root@node2 ~]# systemctl restart flanneld kube-proxy kubelet docker
6、Kubectl工具
管理kubernetes容器平台
6.1、Kubectl概述
kubectl是一个用于操作kubernetes集群的命令行接口,通过利用kubectl的各种命令可以实现各种功能。
6.2、启动相关服务
systemctl restart kube-apiserver kube-controller-manager kube-scheduler flanneld
6.3、获取集群状态
[root@master html]# kubectl get nodes
NAME STATUS AGE
node1 Ready 3h
node2 Ready 2h
6.4、查看版本
[root@master html]# kubectl version
Client Version: version.Info{Major:"1", Minor:"5", GitVersion:"v1.5.2", GitCommit:"269f928217957e7126dc87e6adfa82242bfe5b1e", GitTreeState:"clean", BuildDate:"2017-07-03T15:31:10Z", GoVersion:"go1.7.4", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"5", GitVersion:"v1.5.2", GitCommit:"269f928217957e7126dc87e6adfa82242bfe5b1e", GitTreeState:"clean", BuildDate:"2017-07-03T15:31:10Z", GoVersion:"go1.7.4", Compiler:"gc", Platform:"linux/amd64"}
6.5、kubectl常用命令
kubectl创建和删除一个pod相关操作
| 命令 |
说明 |
| run |
在集群上运行一个pod |
| create |
使用文件或者标准输入的方式创建一个pod |
| delete |
使用文件或者标准输入以及资源名称或者标签选择器来删除某个pod |
6.6、kubectl使用举例
在集群上运行一个镜像
6.6.1、上传基础镜像到所有node节点
上传docker.io-nginx.tar和pod-infrastructure.tar两个文件到node1和node2
[root@node1 ~]# pwd
/root
[root@node1 ~]# ll
total 323096
-rw-------. 1 root root 1294 Dec 18 19:58 anaconda-ks.cfg
-rw-r--r-- 1 root root 112218624 Dec 18 19:28 docker.io-nginx.tar
-rw-r--r-- 1 root root 218623488 Dec 18 19:28 pod-infrastructure.tar
[root@node1 ~]#
传到node2
[root@node1 ~]# scp docker.io-nginx.tar 192.168.2.180:/root/
[root@node1 ~]# scp pod-infrastructure.tar 192.168.2.180:/root/
如果node1和node2服务器上没有docker.io-nginx.tar和pod-infrastructure.tar镜像,后期使用时会自动在dockerhub上下载此镜像,这样比较慢,所以我们提前上传到服务器上。 其中,pod-infrastructure.tar是pod的基础镜像,使用docker-io-nginx的镜像时,也是需要依赖于此镜像的。
6.6.2、所有node节点上导入镜像
在node1和node2上导入镜像
node1:
[root@node1 ~]# pwd
/root
[root@node1 ~]# docker load -i docker.io-nginx.tar
cec7521cdf36: Loading layer [==================================================>] 58.44 MB/58.44 MB
350d50e58b6c: Loading layer [==================================================>] 53.76 MB/53.76 MB
63c39cd4a775: Loading layer [==================================================>] 3.584 kB/3.584 kB
Loaded image: docker.io/nginx:latest
[root@node1 ~]# docker load -i pod-infrastructure.tar
f1f88d1c363a: Loading layer [==================================================>] 205.9 MB/205.9 MB
bb4f52dd78f6: Loading layer [==================================================>] 10.24 kB/10.24 kB
c82569247c35: Loading layer [==================================================>] 12.73 MB/12.73 MB
Loaded image: registry.access.redhat.com/rhel7/pod-infrastructure:latest
[root@node1 ~]#
node2:
[root@node2 ~]# ls
anaconda-ks.cfg docker.io-nginx.tar pod-infrastructure.tar
[root@node2 ~]# pwd
/root
[root@node2 ~]# docker load -i docker.io-nginx.tar
cec7521cdf36: Loading layer [==================================================>] 58.44 MB/58.44 MB
350d50e58b6c: Loading layer [==================================================>] 53.76 MB/53.76 MB
63c39cd4a775: Loading layer [==================================================>] 3.584 kB/3.584 kB
Loaded image: docker.io/nginx:latest
[root@node2 ~]# docker load -i pod-infrastructure.tar
f1f88d1c363a: Loading layer [==================================================>] 205.9 MB/205.9 MB
bb4f52dd78f6: Loading layer [==================================================>] 10.24 kB/10.24 kB
c82569247c35: Loading layer [==================================================>] 12.73 MB/12.73 MB
Loaded image: registry.access.redhat.com/rhel7/pod-infrastructure:latest
[root@node2 ~]#
6.6.3、所有node节点查看镜像
在两个node节点上导完镜像后可以查看一下镜像
[root@node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/nginx latest 9e7424e5dbae 2 years ago 108.5 MB
registry.access.redhat.com/rhel7/pod-infrastructure latest 1158bd68df6d 2 years ago 208.6 MB
可以看到node1上有刚才导入的两个镜像。
[root@node2 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/nginx latest 231d40e811cd 4 weeks ago 126.3 MB
registry.access.redhat.com/rhel7/pod-infrastructure latest 1158bd68df6d 2 years ago 208.6 MB
[root@node2 ~]#
同样node2上也有两个刚才导入的镜像。后面我们创建pod时就直接使用这两个镜像即可。
6.6.4、kubectl run语法
kubectl run和docker run一样,kubectl run能将一个pod运行起来。
语法:
kubectl run NAME --image=image [--env="key=value"] [--port=port] [--replicas=replicas]
6.6.5、启动pod
[root@master html]# kubectl run nginx --image=docker.io/nginx --replicas=1 --port=9000
deployment "nginx" created
注:使用docker.io/nginx镜像 ,--port=暴露容器端口9000 ,设置副本数1
注: 如果docker.io/nginx镜像没有,那么node1和node2会自动在dockerhub上下载。也可以改成自己的私有仓库地址:--image=192.168.2.178:5000/nginx:1.12
[root@node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/nginx latest 9e7424e5dbae 2 years ago 108.5 MB
registry.access.redhat.com/rhel7/pod-infrastructure latest 1158bd68df6d 2 years ago 208.6 MB
[root@node1 ~]#
kubectl run之后,kubernetes创建了一个deployment
6.6.6、查看Deployment
[root@master html]# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 0 1m
[root@master html]# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
nginx 1 1 1 1 38m
[root@master html]#
查看生成的pod,kubernetes将容器运行在pod中以方便实施卷和网络共享等管理
6.6.7、查看pod
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-mg1sg 0/1 ContainerCreating 0 2m
[root@master html]#
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-mg1sg 1/1 Running 0 39m
[root@master html]#
当首次创建pod的时候,这个状态从ContainerCreating变成Running在我的虚机上花了很长时间,估计十几分钟以上是有的。
6.6.8、查看pod详细信息
[root@master html]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
nginx-2187705812-mg1sg 1/1 Running 0 55m 10.255.73.2 node2
这样可以看到这个pod具体运行在哪个节点上,本例中可以看到是运行在node2上。
此时,我们可以在master节点上ping这个pod的id10.255.73.2,是可以ping通的。
[root@master html]# ping 10.255.73.2
PING 10.255.73.2 (10.255.73.2) 56(84) bytes of data.
64 bytes from 10.255.73.2: icmp_seq=1 ttl=61 time=0.795 ms
64 bytes from 10.255.73.2: icmp_seq=2 ttl=61 time=0.946 ms
^C
--- 10.255.73.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.795/0.870/0.946/0.081 ms
6.6.9、查看指定的pod详情
可以使用如下的命令查看具体的pod的详情
[root@master html]# kubectl describe pod nginx-2187705812-mg1sg
Name: nginx-2187705812-mg1sg
Namespace: default
Node: node2/192.168.2.180
Start Time: Sat, 21 Dec 2019 22:58:59 +0800
Labels: pod-template-hash=2187705812
run=nginx
Status: Running
IP: 10.255.73.2
Controllers: ReplicaSet/nginx-2187705812
Containers:
nginx:
Container ID: docker://e511702ff41c7b41141dac923ee5a56a8b3b460565544853cbf93668848e5638
Image: docker.io/nginx
Image ID: docker-pullable://docker.io/nginx@sha256:50cf965a6e08ec5784009d0fccb380fc479826b6e0e65684d9879170a9df8566
Port: 9000/TCP
State: Running
Started: Sat, 21 Dec 2019 23:14:09 +0800
Ready: True
Restart Count: 0
Volume Mounts:
Environment Variables:
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
No volumes.
QoS Class: BestEffort
Tolerations:
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
41m 41m 1 {default-scheduler } Normal Scheduled Successfully assigned nginx-2187705812-mg1sg to node2
41m 41m 1 {kubelet node2} spec.containers{nginx} Normal Pulling pulling image "docker.io/nginx"
41m 25m 2 {kubelet node2} Warning MissingClusterDNS kubelet does not have ClusterDNS IP configured and cannot create Pod using "ClusterFirst" policy. Falling back to DNSDefault policy.
25m 25m 1 {kubelet node2} spec.containers{nginx} Normal Pulled Successfully pulled image "docker.io/nginx"
25m 25m 1 {kubelet node2} spec.containers{nginx} Normal Created Created container with docker id e511702ff41c; Security:[seccomp=unconfined]
25m 25m 1 {kubelet node2} spec.containers{nginx} Normal Started Started container with docker id e511702ff41c
6.6.10、pods常见的状态
1、ContainerCreating #容器创建中
2、ImagePullBackOff #从后端把镜像拉取到本地
注:如果这里pod没有正常运行,都是因为docker hub没有连接上,导致镜像没有下载成功,这时,可以在node节点上把相关镜像手动上传一下或把docker源换成阿里云的。
3、terminating ['tɜ:mɪneɪtɪŋ #终止 。当删除pod时的状态
4、Running 正常运行状态
6.6.11、kubectl删除pod
使用kubectl delete删除创建的对象
删除pod
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-mg1sg 1/1 Running 0 1h
[root@master html]# kubectl delete pod nginx-2187705812-mg1sg
pod "nginx-2187705812-mg1sg" deleted
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-4tmkx 0/1 ContainerCreating 0 4s
[root@master html]#
这里很奇怪,我们删除这个镜像后,平台会自动构建一个新的镜像,来代替我们刚刚删除的那个镜像。这是正是replicas为1的作用,平台会一直保证有一个副本在运行。 过了大概十几分钟又起来一个pod。
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-4tmkx 1/1 Running 0 17m
在这个地方我们在起一个pod
6.6.12、再创建一个pod
[root@master html]# kubectl run nginx01 --image=docker.io/nginx --replicas=1 --port=9009
deployment "nginx01" created
注意:镜像可以用一样的,但是pod的名字和端口不能重复了。
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-4tmkx 1/1 Running 0 21m
nginx01-3827941023-h4vql 1/1 Running 0 1m
[root@master html]#
可以看到之前构建的两个pod都是running状态了。
6.6.13、删除deployment
直接删除pod触发了replicas的确保机制,所以我需要直接删除deployment。也就是说删除pod并不能真的删除pod,如果想完全删除pod,我们可以删除deployment。
[root@master html]# kubectl delete deployment nginx01
deployment "nginx01" deleted
[root@master html]#
我们直接删除刚才新建的nginx01的pod。
[root@master html]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-2187705812-4tmkx 1/1 Running 0 25m
[root@master html]#
检查发现目前只有一个pod了,就是我们之前建的名为nginx的pod了。
7、Yaml
7.1、yaml语法
yaml语法的基本语法规则如下:
1、大小写敏感
2、使用缩进表示层级关系
3、缩进时不允许使用Tab键,只允许使用空格。
4、缩进的空格数目不重要,叧要相同层级的元素左侧对齐即可
5、# 表示注释,从这个字符一直到行尾,都会被解析器忽略。
6、在yaml里面,连续的项目(如:数组元素、集合元素)通过减号“-”来表示,map结构里面的键值对(key/value)用冒号“:”来分割。
7.2、Yaml数据结构
对象:键值对的集合,又称为映射(mapping)/ 哈希(hashes) / 字典(dictionary)
数组:一组按次序排列的值,又称为序列(sequence) / 列表(list)
纯量(scalars):单个的、不可再分的值
7.2.1、数据结构--对象
对象的一组键值对,使用冒号结构表示。
例1:animal代表 pets # pet [pet] 宠物
animal: pets
Yaml 也允许另一种写法,将所有键值对写成一个行内对象。
例2:hash对象中包括 name和foo
hash:
name: Steve
foo: bar
或
hash: { name: Steve, foo: bar }
7.2.2、数组
一组连词线开头的行,构成一个数组。
- Cat
- Dog
- Goldfish
转为 JavaScript 如下。
[ 'Cat', 'Dog', 'Goldfish' ]
数据结构的子成员是一个数组,则可以在该项下面缩进一个空格。数组中还有数组。
-
- Cat
- Dog
- Goldfish
转为 JavaScript 如下。
[ [ 'Cat', 'Dog', 'Goldfish' ] ]
数组也可以采用行内表示法。
animal: [Cat, Dog]
转为 JavaScript 如下。
{ animal: [ 'Cat', 'Dog' ] }
7.2.3、复合结构
对象和数组可以结合使用,形成复合结构。
例:编写一个包括BAT基本信息的bat.yaml配置文件
[root@master ~]# vim bat.yaml #写入以下内容
bat:
website:
baidu: http://www.baidu.com
qq: http://www.qq.com
ali:
- http://www.taobao.com
- http://www.tmall.com
ceo:
yanhongli: 李彦宏
huatengma: 马化腾
yunma: 马云
注:格式如下
对象 : 对象: 对象:键值 对象: - 数组 - 数组
7.2.4、纯量
纯量是最基本的、不可再分的值。如:字符串、布尔值、整数、浮点数、Null、时间、日期
例:数值直接以字面量的形式表示。
number: 12.30
7.3、应用举例
kubectl create加载yaml文件生成deployment
使用kubectl run在设定很复杂的需求时,需要非常长的一条语句,也很容易出错,也没法保存。所以更多场景下会使用yaml或者json文件。
生成mysql-deployment.yaml 文件
上传mysql服务器镜像docker.io-mysql-mysql-server.tar 到node1和node2上
7.3.1、上传镜像到所有node节点
[root@node1 ~]# ls
anaconda-ks.cfg docker.io-mysql-mysql-server.tar docker.io-nginx.tar pod-infrastructure.tar
[root@node1 ~]# pwd
/root
scp到node2
[root@node1 ~]# scp docker.io-mysql-mysql-server.tar node2:/root/
[root@node2 ~]# pwd
/root
[root@node2 ~]# ls
anaconda-ks.cfg docker.io-mysql-mysql-server.tar docker.io-nginx.tar pod-infrastructure.tar
[root@node2 ~]#
7.3.2、上传mysql-deployment.yaml到master管理结点
[root@master ~]# pwd
/root
[root@master ~]# ls
anaconda-ks.cfg bat.yaml mysql-deployment.yaml
[root@master ~]#
7.3.3、在node1和node2上导入mysql镜像
[root@node1 ~]# pwd
/root
[root@node1 ~]# ls
anaconda-ks.cfg docker.io-mysql-mysql-server.tar docker.io-nginx.tar pod-infrastructure.tar
[root@node1 ~]# docker load -i docker.io-mysql-mysql-server.tar
0302be4b1718: Loading layer [==================================================>] 124.3 MB/124.3 MB
f9deff9cb67e: Loading layer [==================================================>] 128.7 MB/128.7 MB
c4c921f94c30: Loading layer [==================================================>] 9.216 kB/9.216 kB
0c39b2c234c8: Loading layer [==================================================>] 3.072 kB/3.072 kB
Loaded image: docker.io/mysql/mysql-server:latest
[root@node1 ~]#
[root@node2 ~]# pwd
/root
[root@node2 ~]# ls
anaconda-ks.cfg docker.io-mysql-mysql-server.tar docker.io-nginx.tar pod-infrastructure.tar
[root@node2 ~]# docker load -i docker.io-mysql-mysql-server.tar
0302be4b1718: Loading layer [==================================================>] 124.3 MB/124.3 MB
f9deff9cb67e: Loading layer [==================================================>] 128.7 MB/128.7 MB
c4c921f94c30: Loading layer [==================================================>] 9.216 kB/9.216 kB
0c39b2c234c8: Loading layer [==================================================>] 3.072 kB/3.072 kB
Loaded image: docker.io/mysql/mysql-server:latest
7.3.4、Mysql-deployment.yaml文件内容
kind: Deployment
#使用deployment创建一个pod资源,旧k8s版本可以使用kind: ReplicationController来创建pod
apiVersion: extensions/v1beta1
metadata:
name: mysql
#deployment的名称,全局唯一
spec:
replicas: 1
#Pod副本期待数量,1表示叧运行一个pod,里面一个容器
template:
#根据此模板创建Pod的副本(实例)
metadata:
labels:
#符合目标的Pod拥有此标签。默认和name的值一样
name: mysql
#定义Pod的名字是mysql
spec:
containers:
# Pod中容器的定义部分
- name: mysql
#容器的名称
image: docker.io/mysql/mysql-server
#容器对应的Docker Image镜像
imagePullPolicy: IfNotPresent
#默认值为:imagePullPolicy: Always一直从外网下载镜像,不用使用本地的。
#其他镜像下载策略参数说明:
#IfNotPresent :如果本地存在镜像就优先使用本地镜像。这样可以直接使用本地镜像,加快启动速度。Present [ˈpreznt] 目前;现在
#Never:直接不再去拉取镜像了,使用本地的;如果本地不存在就报异常了。
ports:
- containerPort: 3306
#容器暴露的端口号
protocol: TCP
env:
#注入到容器的环境变量
- name: MYSQL_ROOT_PASSWORD
#设置mysql root的密码
value: "hello123"
7.3.5、该yaml文件结构
注: mysql-deployment.yaml 文件结构:
Deployment的定义
pod的定义
容器的定义
7.3.6、通过yaml文件创建资源
使用mysql-deployment.yaml创建和删除mysql资源
[root@master ~]# kubectl create -f mysql-deployment.yaml
deployment "mysql" created
[root@master ~]#
注:当一个目录下,有多个yaml文件的时候,使用kubectl create -f 目录 的方式一下全部创建
[root@master tmp]# kubectl create -f yamls/
deployment "mysql" created
deployment " mysql 1" created
使用get参数查看pod详细信息
7.3.7、查看创建的pod
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 1m
nginx-2187705812-4tmkx 1/1 Running 0 20h
[root@master ~]#
7.3.8、查看创建的deployment
[root@master ~]# kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
mysql 1 1 1 1 2m
nginx 1 1 1 1 21h
7.3.9、查看pod详情
[root@master ~]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
mysql-2261771434-x62bx 1/1 Running 0 3m 10.255.73.2 node2
nginx-2187705812-4tmkx 1/1 Running 0 20h 10.255.31.2 node1
加上-o wide参数可以查看更详细的信息,比如看到此pod在哪个node上运行,此pod的集群IP是多少也被一并显示了
注:10.255.73.2这个IP地址是flannel 中定义的网段中的一个IP地址。 pod通过这个IP和master进行通信
7.3.10、查看service
[root@master ~]# kubectl get service
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes 10.254.0.1
我们当前没有创建过服务,只有一个默认的kubernetes的服务。所以我们当前访问不了mysql服务。
7.3.11、测试通信
#可以ping通
[root@master ~]# ping 10.255.73.2
PING 10.255.73.2 (10.255.73.2) 56(84) bytes of data.
64 bytes from 10.255.73.2: icmp_seq=1 ttl=61 time=0.522 ms
64 bytes from 10.255.73.2: icmp_seq=2 ttl=61 time=3.05 ms
^C
--- 10.255.73.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.522/1.790/3.058/1.268 ms
[root@master ~]# ping 10.255.73.1
PING 10.255.73.1 (10.255.73.1) 56(84) bytes of data.
64 bytes from 10.255.73.1: icmp_seq=1 ttl=62 time=0.587 ms
64 bytes from 10.255.73.1: icmp_seq=2 ttl=62 time=2.02 ms
^C
--- 10.255.73.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.587/1.308/2.029/0.721 ms
[root@master ~]#
#ping node2上的docker0的地址,也可以通的。
总结: master,node2,pod,docker,container 它们之间通信都是使用flannel分配的地址。也就是通过flannel隧道把物理上分开的主机和容器,连接在一个局域网中了。
7.3.12、回顾:flannel地址的配置
该部分内容无需在做,因为我们前面已经做过了。
7.3.12.1、设置etcd网络
[root@xuegod63 ~]# etcdctl mkdir /k8s/network #创建一个目录/ k8s/network用于存储flannel网络信息
7.3.12.2、获取网络值
master:
etcdctl set /k8s/network/config '{"Network": "10.255.0.0/16"}'
#给/k8s/network/config 赋一个字符串的值 '{"Network": "10.255.0.0/16"}'
在这里配置的。最终是存储etcd中的
7.3.13、在node2上查看运行mysql docker实例
[root@node2 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
2fe9d8e43131 docker.io/mysql/mysql-server "/entrypoint.sh mysql" 19 minutes ago Up 19 minutes (healthy) k8s_mysql.31ec27ee_mysql-2261771434-x62bx_default_fdd4f3fb-24b6-11ea-ade8-000c29d8be5b_6872c9d5
57f3831e25ec registry.access.redhat.com/rhel7/pod-infrastructure:latest "/usr/bin/pod" 19 minutes ago Up 19 minutes k8s_POD.1d520ba5_mysql-2261771434-x62bx_default_fdd4f3fb-24b6-11ea-ade8-000c29d8be5b_964c94c5
[root@node2 ~]#
发现有两个docker实例在运行,底下那个是pod的基础服务镜像,要运行mysql,必须要先把pod-infrastructure镜像运行起来。
7.3.14、简写总结
get命令能够确认的信息类别:
deployments (缩写 deploy)
events (缩写 ev)
namespaces (缩写 ns)
nodes (缩写 no)
pods (缩写 po)
replicasets (缩写 rs)
replicationcontrollers (缩写 rc)
services (缩写 svc)
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 24m
nginx-2187705812-4tmkx 1/1 Running 0 20h
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 24m
nginx-2187705812-4tmkx 1/1 Running 0 20h
[root@master ~]# kubectl get po
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 24m
nginx-2187705812-4tmkx 1/1 Running 0 20h
[root@master ~]#
可以发现后面可以简写。
7.3.15、kubectl describe
使用describe查看k8s中详细信息
describe [dɪˈskraɪb] 描述
语法: kubectl describe pod pod名字
语法: kubectl describe node node名字
语法: kubectl describe deployment deployment 名字
使用describe查看pod的详细描述信息
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 26m
nginx-2187705812-4tmkx 1/1 Running 0 20h
7.3.15.1、查看pod
[root@master ~]# kubectl describe pod mysql-2261771434-x62bx
Name: mysql-2261771434-x62bx
Namespace: default
Node: node2/192.168.2.180
Start Time: Sun, 22 Dec 2019 20:31:34 +0800
Labels: name=mysql
pod-template-hash=2261771434
Status: Running
IP: 10.255.73.2
Controllers: ReplicaSet/mysql-2261771434
Containers:
mysql:
Container ID: docker://2fe9d8e43131fc0b315fca6a9f72e34b2207c85fe1eca508ae6c6600dbf2f274
Image: docker.io/mysql/mysql-server
Image ID: docker://sha256:a3ee341faefb76c6c4c6f2a4c37c513466f5aae891ca2f3cb70fd305b822f8de
Port: 3306/TCP
State: Running
Started: Sun, 22 Dec 2019 20:31:35 +0800
Ready: True
Restart Count: 0
Volume Mounts:
Environment Variables:
MYSQL_ROOT_PASSWORD: hello123
Conditions:
Type Status
Initialized True
Ready True
PodScheduled True
No volumes.
QoS Class: BestEffort
Tolerations:
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
26m 26m 1 {default-scheduler } Normal Scheduled Successfully assigned mysql-2261771434-x62bx to node2
26m 26m 2 {kubelet node2} Warning MissingClusterDNS kubelet does not have ClusterDNS IP configured and cannot create Pod using "ClusterFirst" policy. Falling back to DNSDefault policy.
26m 26m 1 {kubelet node2} spec.containers{mysql} Normal Pulled Container image "docker.io/mysql/mysql-server" already present on machine
26m 26m 1 {kubelet node2} spec.containers{mysql} Normal Created Created container with docker id 2fe9d8e43131; Security:[seccomp=unconfined]
26m 26m 1 {kubelet node2} spec.containers{mysql} Normal Started Started container with docker id 2fe9d8e43131
[root@master ~]#
通过这个可以查看创建pod时报的错误及告警信息,可以看到以下告警:
26m 26m 2 {kubelet node2} Warning MissingClusterDNS kubelet does not have ClusterDNS IP configured and cannot create Pod using "ClusterFirst" policy. Falling back to DNSDefault policy.
7.3.15.2、查看node
使用describe查看node的详细描述信息
[root@master ~]# kubectl describe node node2
Name: node2
Role:
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/hostname=node2
Taints:
CreationTimestamp: Sat, 21 Dec 2019 19:39:10 +0800
Phase:
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
OutOfDisk False Sun, 22 Dec 2019 21:04:30 +0800 Sat, 21 Dec 2019 19:39:10 +0800 KubeletHasSufficientDisk kubelet has sufficient disk space available
MemoryPressure False Sun, 22 Dec 2019 21:04:30 +0800 Sat, 21 Dec 2019 19:39:10 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sun, 22 Dec 2019 21:04:30 +0800 Sat, 21 Dec 2019 19:39:10 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
Ready True Sun, 22 Dec 2019 21:04:30 +0800 Sat, 21 Dec 2019 19:39:20 +0800 KubeletReady kubelet is posting ready status
Addresses: 192.168.2.180,192.168.2.180,node2
Capacity:
alpha.kubernetes.io/nvidia-gpu: 0
cpu: 2
memory: 2855652Ki
pods: 110
Allocatable:
alpha.kubernetes.io/nvidia-gpu: 0
cpu: 2
memory: 2855652Ki
pods: 110
System Info:
Machine ID: c32dec1481dc4cf9b03963bf6e599d20
System UUID: 4CBF4D56-41E3-C9F6-C1F6-F697A64E2664
Boot ID: 2dc7b509-d86d-4cdd-83c6-a9212b209eaa
Kernel Version: 3.10.0-693.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://1.12.6
Kubelet Version: v1.5.2
Kube-Proxy Version: v1.5.2
ExternalID: node2
Non-terminated Pods: (1 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits
--------- ---- ------------ ---------- --------------- -------------
default mysql-2261771434-x62bx 0 (0%) 0 (0%) 0 (0%) 0 (0%)
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.
CPU Requests CPU Limits Memory Requests Memory Limits
------------ ---------- --------------- -------------
0 (0%) 0 (0%) 0 (0%) 0 (0%)
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
33m 33m 2 {kubelet node2} Warning MissingClusterDNS kubelet does not have ClusterDNS IP configured and cannot create Pod using "ClusterFirst" policy. pod: "mysql-2261771434-x62bx_default(fdd4f3fb-24b6-11ea-ade8-000c29d8be5b)". Falling back to DNSDefault policy.
[root@master ~]#
7.3.15.3、查看deployment
使用describe查看deployment的详细描述信息
[root@master ~]# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
mysql 1 1 1 1 36m
nginx 1 1 1 1 22h
[root@master ~]# kubectl describe deploy mysql
Name: mysql
Namespace: default
CreationTimestamp: Sun, 22 Dec 2019 20:31:34 +0800
Labels: name=mysql
Selector: name=mysql
Replicas: 1 updated | 1 total | 1 available | 0 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 1 max unavailable, 1 max surge
Conditions:
Type Status Reason
---- ------ ------
Available True MinimumReplicasAvailable
OldReplicaSets:
NewReplicaSet: mysql-2261771434 (1/1 replicas created)
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37m 37m 1 {deployment-controller } Normal ScalingReplicaSet Scaled up replica set mysql-2261771434 to 1
[root@master ~]#
7.3.16、Kubectl其他常用命令和参数
命令 说明
logs 取得pod中容器的log信息
exec 在pod中执行一条命令
cp 从容器拷出或向容器拷入文件
attach Attach到一个运行中的容器上,实时查看容器消息
7.3.16.1、生成测试容器资源
实验环境:先生成一个mysql资源:
kubectl create -f /root /mysql-deployment.yaml
#这个命令在之前前已经生成了。这里就不用执行了。
7.3.16.2、kubectl logs
类似于docker logs,使用kubectl logs能够取出pod中镜像的log,也是故障排除时候的重要信息
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 44m
nginx-2187705812-4tmkx 1/1 Running 0 21h
[root@master ~]# kubectl logs mysql-2261771434-x62bx
[Entrypoint] MySQL Docker Image 5.7.20-1.1.2
[Entrypoint] Initializing database
[Entrypoint] Database initialized
Warning: Unable to load '/usr/share/zoneinfo/iso3166.tab' as time zone. Skipping it.
Warning: Unable to load '/usr/share/zoneinfo/zone.tab' as time zone. Skipping it.
Warning: Unable to load '/usr/share/zoneinfo/zone1970.tab' as time zone. Skipping it.
[Entrypoint] ignoring /docker-entrypoint-initdb.d/*
[Entrypoint] Server shut down
[Entrypoint] MySQL init process done. Ready for start up.
[Entrypoint] Starting MySQL 5.7.20-1.1.2
[root@master ~]#
7.3.16.3、kubectl exec
exec命令用于到pod中执行一条命令,到mysql的镜像中执行cat /etc/my.cnf命令
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 46m
nginx-2187705812-4tmkx 1/1 Running 0 21h
[root@master ~]# kubectl exec mysql-2261771434-x62bx cat /etc/my.cnf
# For advice on how to change settings please see
# http://dev.mysql.com/doc/refman/5.7/en/server-configuration-defaults.html
[mysqld]
#
# Remove leading # and set to the amount of RAM for the most important data
# cache in MySQL. Start at 70% of total RAM for dedicated server, else 10%.
# innodb_buffer_pool_size = 128M
#
# Remove leading # to turn on a very important data integrity option: logging
# changes to the binary log between backups.
# log_bin
#
# Remove leading # to set options mainly useful for reporting servers.
# The server defaults are faster for transactions and fast SELECTs.
# Adjust sizes as needed, experiment to find the optimal values.
# join_buffer_size = 128M
# sort_buffer_size = 2M
# read_rnd_buffer_size = 2M
skip-host-cache
skip-name-resolve
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
secure-file-priv=/var/lib/mysql-files
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
log-error=/var/log/mysqld.log
pid-file=/var/run/mysqld/mysqld.pid
[root@master ~]#
成功获取到了docker里面的mysql配置文件信息。
7.3.16.4、进入容器
也可以直接进入到容器中,执行相关命令
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 47m
nginx-2187705812-4tmkx 1/1 Running 0 21h
[root@master ~]# kubectl exec -it mysql-2261771434-x62bx bash
bash-4.2#
7.3.16.5、kubectl cp
7.3.16.5.1、从容器中拷出
用于从容器中拷出hosts文件到物理机的/tmp下
[root@master ~]# kubectl get pod
NAME READY STATUS RESTARTS AGE
mysql-2261771434-x62bx 1/1 Running 0 47m
nginx-2187705812-4tmkx 1/1 Running 0 21h
[root@master ~]# kubectl cp mysql-2261771434-x62bx:/etc/hosts /tmp/hosts
error: unexpected EOF
我们查看下kubectl cp的使用说明:
[root@master ~]# kubectl cp --help
Copy files and directories to and from containers.
Examples:
# !!!Important Note!!!
# Requires that the 'tar' binary is present in your container
# image. If 'tar' is not present, 'kubectl cp' will fail.
#发现想要使用kubectl cp你的容器实例中必须有tar库。
#如果镜像中tar命令不存在,那么kubectl cp将拷贝失败。
那么我们就在在mysql pod中安装tar命吧
[root@master ~]# kubectl exec -it mysql-2261771434-x62bx bash
bash-4.2# yum install tar -y
Loaded plugins: ovl
ol7_UEKR4 | 2.5 kB 00:00:00
ol7_latest | 2.7 kB 00:00:00
Package 2:tar-1.26-35.el7.x86_64 already installed and latest version
Nothing to do
bash-4.2# exit
exit
[root@master ~]#
注意:这个安装tar是使用的在线yum源,需要容器能联网,而且一步狂慢,我执行了好久(大于3小时)才执行完。
此时我们在尝试拷贝
[root@master ~]# ll /tmp/hosts
ls: cannot access /tmp/hosts: No such file or directory
[root@master ~]# kubectl cp mysql-2261771434-x62bx:/etc/hosts /tmp/hosts
tar: Removing leading `/' from member names
[root@master ~]# ls /tmp/hosts
/tmp/hosts
7.3.16.5.2、从宿主机拷到容器
从虚机拷贝到容器docker中
进入容器:
[root@master ~]# kubectl exec -it mysql-2261771434-x62bx bash
检查该文件在容器中是否存在
bash-4.2# ls /tmp/hosts
ls: cannot access /tmp/hosts: No such file or directory
bash-4.2# exit
Exit
拷贝该文件到容器
[root@master ~]# kubectl cp /tmp/hosts mysql-2261771434-x62bx:/tmp/hosts
进入容器
[root@master ~]# kubectl exec -it mysql-2261771434-x62bx bash
再次检查该文件是否存在
bash-4.2# ls /tmp/hosts
/tmp/hosts
检查文件内容
bash-4.2# cat /tmp/hosts
# Kubernetes-managed hosts file.
127.0.0.1 localhost
::1 localhost ip6-localhost ip6-loopback
fe00::0 ip6-localnet
fe00::0 ip6-mcastprefix
fe00::1 ip6-allnodes
fe00::2 ip6-allrouters
10.255.73.2 mysql-2261771434-x62bx
bash-4.2#
kubectl attach
kubectl attach用于取得pod中容器的实时信息,可以持续不断实时的取出消息。像tail -f /var/log/messages 动态查看日志的作用。
kubectl logs是一次取出所有消息,像cat /etc/passwd
attach [ə.tæʃ] 贴上 附上
[root@master ~]# kubectl attach mysql-2261771434-x62bx
If you don't see a command prompt, try pressing enter.
[Entrypoint] MySQL Docker Image 5.7.20-1.1.2
Warning: Unable to load '/usr/share/zoneinfo/iso3166.tab' as time zone. Skipping it.
[Entrypoint] Initializing database
[Entrypoint] Database initialized
[Entrypoint] ignoring /docker-entrypoint-initdb.d/*
Warning: Unable to load '/usr/share/zoneinfo/zone.tab' as time zone. Skipping it.
Warning: Unable to load '/usr/share/zoneinfo/zone1970.tab' as time zone. Skipping it.
[Entrypoint] Server shut down
[Entrypoint] MySQL init process done. Ready for start up.
[Entrypoint] Starting MySQL 5.7.20-1.1.2
^C
[root@master ~]
#注: 到现在,所创建nginx和mysql都只是deployment设备硬件资源,并没有对应service服务,所以现在还不能直接在外网进行访问nginx和mysql服务。
8、搭建K8s的web管理界面
部署k8s Dashboard web界面
创建dashboard-deployment.yaml deployment配置文件
创建dashboard-service.yaml service配置文件
准备kubernetes相关的镜像
启动dashboard的deployment和service
排错经验分享
查看kubernetes dashboard web界面
销毁web界面相关应用
在kubernetes上面的集群上搭建基于redis和docker的留言簿案例
创建Redis master deployment配置文件
创建redis master service配置文件
创建redis slave deployment配置文件
创建slave service配置文件
创建frontend guestbook deployment配置文件
创建frontend guestbook service配置文件
查看外部网络访问guestbook
8.1、搭建步骤
准备deployment和service 配置文件-》导入相关镜像-》启动deployment和service
8.1.1、确认集群环境
[root@master ~]# kubectl get node
NAME STATUS AGE
node1 Ready 2d
node2 Ready 2d
[root@master ~]#
8.1.2、上传yaml文件到master
在master上上传dashboard-deployment.yaml和dashboard-service.yaml到/root/目录
[root@master ~]# ls
anaconda-ks.cfg bat.yaml dashboard-deployment.yaml dashboard-service.yaml mysql-deployment.yaml
[root@master ~]#
8.1.3、修改apiserver
需要把apiserver改成自己的master地址
[root@master ~]# vi dashboard-deployment.yaml
args:
- --apiserver-host=http://192.168.2.178:8080
[root@master ~]# cat dashboard-deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
# Keep the name in sync with image version and
# gce/coreos/kube-manifests/addons/dashboard counterparts
name: kubernetes-dashboard-latest
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: kubernetes-dashboard
version: latest
kubernetes.io/cluster-service: "true"
spec:
containers:
- name: kubernetes-dashboard
image: docker.io/bestwu/kubernetes-dashboard-amd64:v1.6.3
imagePullPolicy: IfNotPresent
resources:
# keep request = limit to keep this container in guaranteed class
limits:
cpu: 100m
memory: 50Mi
requests:
cpu: 100m
memory: 50Mi
ports:
- containerPort: 9090
args:
- --apiserver-host=http://192.168.2.178:8080
# - --apiserver-host=http://192.168.2.178:8080
livenessProbe:
httpGet:
path: /
port: 9090
initialDelaySeconds: 30
timeoutSeconds: 30
[root@master ~]# cat dashboard-service.yaml
apiVersion: v1
kind: Service
metadata:
name: kubernetes-dashboard
namespace: kube-system
labels:
k8s-app: kubernetes-dashboard
kubernetes.io/cluster-service: "true"
spec:
selector:
k8s-app: kubernetes-dashboard
ports:
- port: 80
targetPort: 9090
[root@master ~]#
8.1.4、配置文件说明
image: docker.io/bestwu/kubernetes-dashboard-amd64:v1.6.3
8.1.4.1、关于deployment文件说明
#这里修改成可以找到的镜像源。/bestwu/kubernetes-dashboard-amd64 这个是一个中文的web界面镜像。
limits: #关于pod使用的cpu和内存硬件资源做限制 。
args:
- --apiserver-host=http://192.168.2.178:8080
#使用该deployment文件时,这里写成自己的apiserver服务器地址和端口。
8.1.4.2、关于service文件说明
name: kubernetes-dashboard
#这里要和上面的deployment中定义一样
namespace: kube-system
#这里要和上面的deployment中定义一样
8.1.5、service的三种端口
8.1.5.1、port
service暴露在cluster ip上的端口,port 是提供给集群内部客户访问service的入口。
8.1.5.2、nodePort
nodePort是k8s提供给集群外部客户访问service入口的一种方式。
8.1.5.3、targetPort
targetPort是pod中容器实例上的端口,从port和nodePort上到来的数据最终经过kube-proxy流入到后端pod的targetPort上迚入容器。
8.1.5.4、图示说明
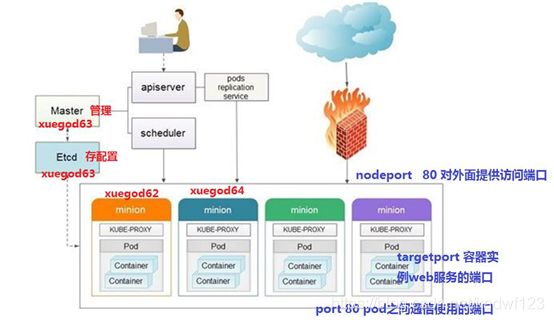
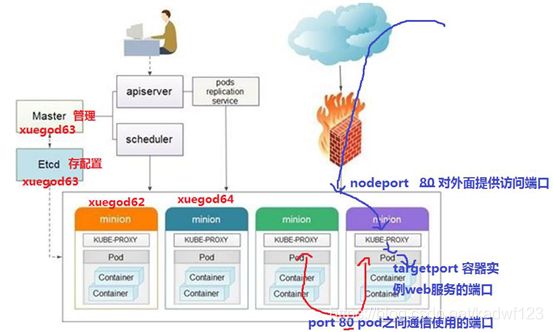
8.1.5.5、port、nodePort总结
port和nodePort都是service的端口,前者暴露给集群内客户访问服务,后者暴露给集群外客户访问服务。从这两个端口到来的数据都需要经过反向代理kube-proxy流入后端pod的targetPod,从而到达pod上的容器内。
8.1.6、service概述
service是pod的路由代理抽象,用于解决pod之间的服务发现问题。因为pod的运行状态可动态变化(比如切换机器了、缩容过程中被终止了等),所以访问端不能以写死IP的方式去访问该pod提供的服务。service的引入旨在保证pod的动态变化对访问端透明,访问端只需要知道service的地址,由service来提供代理。
8.1.7、replicationController
是pod的复制抽象,用于解决pod的扩容缩容问题。通常,分布式应用为了性能或高可用性的考虑,需要复制多份资源,并且根据负载情况动态伸缩。通过replicationController,我们可以指定一个应用需要几份复制,Kubernetes将为每份复制创建一个pod,并且保证实际运行pod数量总是与该复制数量相等(例如,当前某个pod宕机时,自动创建新的pod来替换)。
8.1.8、service和replicationController总结
service和replicationController只是建立在pod之上的抽象,最终是要作用于pod的,那么它们如何跟pod联系起来呢?这就要引入label的概念:label其实很好理解,就是为pod加上可用于搜索或关联的一组key/value标签,而service和replicationController正是通过label来与pod关联的。如下图所示,有三个pod都有label为"app=backend",创建service和replicationController时可以指定同样的label:"app=backend",再通过label selector机制,就将它们与这三个pod关联起来了。例如,当有其他frontend pod访问该service时,自动会转发到其中的一个backend pod。
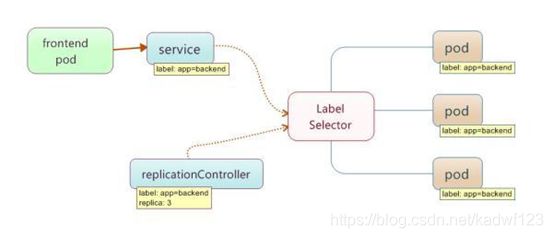
8.1.9、准备k8s相关的镜像
在官方的dashboard-deployment.yaml中定义了dashboard所用的镜像:gcr.io/google_containers/kubernetes-dashboard-amd64:v1.5.1,启动k8s的pod还需要一个额外的镜像:registry.access.redhat.com/rhel7/pod-infrastructure:latest,这两个镜像在国内下载比较慢。可以使用docker自带的源先下载下来:
8.1.9.1、本地上传镜像
本地上传镜像到node1和node2上
node1和nod2都要导入以下2个镜像:
本地上传镜像到node1和node2上
[root@node1 ~]# mkdir /root/k8s
[root@node2 ~]# mkdir /root/k8s
上传镜像文件到node1和node2
[root@node1 k8s]# pwd
/root/k8s
[root@node1 k8s]# ls
docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar
[root@node1 k8s]#
[root@node1 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/nginx latest 231d40e811cd 4 weeks ago 126.3 MB
docker.io/mysql/mysql-server latest a3ee341faefb 2 years ago 245.7 MB
registry.access.redhat.com/rhel7/pod-infrastructure latest 1158bd68df6d 2 years ago 208.6 MB
node1上执行导入镜像操作
[root@node1 k8s]# docker load -i docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar
8fc4262856aa: Loading layer [==================================================>] 139.3 MB/139.3 MB
Loaded image: docker.io/bestwu/kubernetes-dashboard-amd64:v1.6.3
[root@node1 k8s]#
检查node1上面的镜像
[root@node1 k8s]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
docker.io/nginx latest 231d40e811cd 4 weeks ago 126.3 MB
docker.io/mysql/mysql-server latest a3ee341faefb 2 years ago 245.7 MB
registry.access.redhat.com/rhel7/pod-infrastructure latest 1158bd68df6d 2 years ago 208.6 MB
docker.io/bestwu/kubernetes-dashboard-amd64 v1.6.3 691a82db1ecd 2 years ago 139 MB
[root@node1 k8s]#
pod-infrastructure镜像是之前已经导入的。
将docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar文件传到node2
[root@node1 k8s]# scp docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar node2:/root/k8s/
root@node2's password:
docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar 100% 133MB 66.6MB/s 00:01
[root@node1 k8s]#
在node2上导入镜像
[root@node2 k8s]# pwd
/root/k8s
[root@node2 k8s]# ls
docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar
[root@node2 k8s]# docker load -i docker.io-bestwu-kubernetes-dashboard-amd64-zh.tar
8fc4262856aa: Loading layer [==================================================>] 139.3 MB/139.3 MB
Loaded image: docker.io/bestwu/kubernetes-dashboard-amd64:v1.6.3
[root@node2 k8s]#
8.1.9.2、在线pull镜像
docker pull registry.access.redhat.com/rhel7/pod-infrastructure:latest
可以直接在node节点上下载该镜像,这是红帽的官方docker镜像下载站点,可以直接访问。
gcr.io这个网址在国内,没有办法访问,我使用docker.io中的镜像:
[root@xuegod62 ~]# docker search kubernetes-dashboard-amd
[root@xuegod62 ~]# docker pull docker.io/mritd/kubernetes-dashboard-amd64
这种方式我执行失败了,不太好用。
8.1.10、上传yaml文件
在master上
[root@master ~]# mkdir /etc/kubernetes/yaml
[root@master ~]# cd /etc/kubernetes/yaml
[root@master yaml]#
将所有的yaml配置文件都上传到master的这个/etc/kubernetes/yaml目录
[root@master yaml]# ls
dashboard-deployment.yaml frontend-deployment.yaml redis-master-deployment.yaml redis-slave-deployment.yaml
dashboard-service.yaml frontend-service.yaml redis-master-service.yaml redis-slave-service.yaml
[root@master yaml]#
飘红的是需要上传的yaml文件。
8.1.11、创建deployment
[root@master yaml]# kubectl create -f /etc/kubernetes/yaml/dashboard-deployment.yaml
deployment "kubernetes-dashboard-latest" created
[root@master yaml]#
8.1.12、创建service
[root@master yaml]# kubectl create -f /etc/kubernetes/yaml/dashboard-service.yaml
service "kubernetes-dashboard" created
[root@master yaml]#
到此,dashboard搭建完成。
8.1.13、查看deployment
[root@master yaml]# kubectl get deployment --all-namespaces
NAMESPACE NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
default mysql 1 1 1 1 1d
default nginx 1 1 1 1 1d
kube-system kubernetes-dashboard-latest 1 1 1 1 1m
[root@master yaml]#
desired [dɪ'zaɪəd] 希望,渴望的 ; CURRENT 现在 ; UP-TO-DATE最新的 ; available可用
注: 因为我们定义了namespace,所以这需要加上--all-namespaces才可以显示出来,默认只显示namespaces=default的deployment。
8.1.14、查看service
[root@master yaml]# kubectl get svc --all-namespaces
NAMESPACE NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
default kubernetes 10.254.0.1
kube-system kubernetes-dashboard 10.254.209.198
[root@master yaml]#
8.1.15、查看pod
[root@master yaml]# kubectl get pod -o wide --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
default mysql-2261771434-x62bx 1/1 Running 0 1d 10.255.73.2 node2
default nginx-2187705812-4tmkx 1/1 Running 0 1d 10.255.31.2 node1
kube-system kubernetes-dashboard-latest-810449173-zhc37 1/1 Running 0 3m 10.255.73.3 node2
[root@master yaml]#
8.1.16、查看指定pod
[root@master yaml]# kubectl get pod -n kube-system -o wide
NAME READY STATUS RESTARTS AGE IP NODE
kubernetes-dashboard-latest-810449173-zhc37 1/1 Running 0 4m 10.255.73.3 node2
[root@master yaml]#
8.1.17、排错经验
8.1.17.1、kubelet 监听端口未改
[root@master kubernetes]# kubectl get pod -o wide --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
kube-system kubernetes-dashboard-latest-2351462241-slg41 0/1 CrashLoopBackOff 5 5m 10.255.9.5 node1
查看报错信息:
#kubectl logs -f kubernetes-dashboard-latest-810449173-zhc37 -n kube-system #显示
Error from server:
Get https://node1:10250/containerLogs/kube-system/kubernetes-dashboard-latest-2351462241-slg41/kubernetes-dashboard?follow=true: dial tcp 192.168.2.179:10250: getsockopt: connection refused
注:
解决:
[root@node1 ~]# grep -v '^#' /etc/kubernetes/kubelet
改:KUBELET_ADDRESS="--address=127.0.0.1"
为:KUBELET_ADDRESS="--address=0.0.0.0"
[root@node1 ~]#systemctl restart kubelet.service
在node2上也同样执行以上命令。
[root@node2 ~]# grep -v '^#' /etc/kubernetes/kubelet
改:KUBELET_ADDRESS="--address=127.0.0.1"
为:KUBELET_ADDRESS="--address=0.0.0.0"
[root@node2 ~]#systemctl restart kubelet.service
8.1.17.2、防火墙未关
[root@master ~]# kubectl logs kubernetes-dashboard-latest-2661119796-64km9 -n kube-system
Error from server: Get
https://node2:10250/containerLogs/kube-system/kubernetes-dashboard-latest-2661119796-64km9/kubernetes-dashboard: dial tcp 192.168.2.179:10250: getsockopt: no route to host
解决:
[root@node2 ~]# iptables -F #清空防火墙
[root@node2 ~]# systemctl stop firewalld
[root@node2 ~]# systemctl disable firewalld
清空防火墙后,再查看日志:
[root@master ~]# kubectl logs kubernetes-dashboard-latest-810449173-zhc37 -n kube-system
Starting HTTP server on port 9090
Creating API server client for http://192.168.2.178:8080
Successful initial request to the apiserver, version: v1.5.2
Creating in-cluster Heapster client
弹出以上界面说明我们配置成功。
8.2、验证web浏览器访问
http://192.168.2.178:8080/ui
到这里可以对虚机做一个快照,方便后面的实验。
8.3、销毁web界面相关应用
8.3.1、删除deployment
[root@master yaml]# kubectl get deploy
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
mysql 1 1 1 1 1d
nginx 1 1 1 1 1d
[root@master yaml]# kubectl get deployment --namespace=kube-system
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
kubernetes-dashboard-latest 1 1 1 1 15m
[root@master yaml]#
注意一定要加namespace,不然获取到的就是default空间的deployment。
删除web对应的deployment
[root@master yaml]# kubectl delete deployment kubernetes-dashboard-latest --namespace=kube-system
8.3.2、删除web对应的service
[root@master yaml]# kubectl get svc --namespace=kube-system
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes-dashboard 10.254.209.198
[root@master yaml]#
[root@master yaml]# kubectl delete svc kubernetes-dashboard --namespace=kube-system