PyTorch Cookbook by Eric
1 学习资料
CVHub-cvhuber —— 《PyTorch 常用代码段汇总》
Jack Stark——《[深度学习框架]PyTorch常用代码段》:
- Mixup训练
- 不对偏置项进行权重衰减(weight decay)
- 保存与加载断点
- 模型可解释性,使用captum库
2 Philosophy
2.1 新建tensor时指定设备:device = torchplus.DEVICE
在新建tensor时指定设备可以避免张量在设备之间移动所带来的开销,尤其是从“cpu & RAM”转移到GPU带来的时间消耗;
2.2 使用in-place操作
使用算子进行计算时,尽量使用in-place操作;
2.3 特征图大小(HW)设置为8的倍数
当通道数设置为8的倍数时,会有利于算子库的优化,这里引用NVIDIA/apex#221的表述:
Convolutions:
For cudnn versions 7.2 and ealier, @vaibhav0195 is correct: input channels, output channels, and batch size should be multiples of 8 to use tensor cores. However, this requirement is lifted for cudnn versions 7.3 and later. For cudnn 7.3 and later, you don’t need to worry about making your channels/batch size multiples of 8 to enable Tensor Core use.
NVIDIA在《Train With Mixed Precision :: NVIDIA Deep Learning Performance Documentation | 2.2. Tensor Core Math》中也具体说明了这个特性;
3 张量——torch.Tensor
# 新建一个torch向量
torch.tensor([1,2,3,4])
# 新建一个torch矩阵
torch.tensor([[1,2,3],
[4,5,6],
[7,8,9]])
# 这里都是使用工厂函数torch.tensor新建张量,也可以使用torch.Tensor进行创建,我觉得torch.tensor会更加方便一些,因为可以自动推断张量的类型
# 创建一个全零张量
torch.zeros([2, 3], dtype=torch.float)
# 创建形状相同的全零张量
torch.zeros_like(X)
3.1 张量基本信息
tensor = torch.randn(3,4,5)
# 数据类型
print(tensor.type())
# 张量大小
print(tensor.size())
# 张量形状
x.shape
# NOTE:不用加括号
###########################
# 维度的数量
print(tensor.dim())
# 元素个数
print(tensor.numel())
# 获得当前batch的批次大小
curr_bs = batch_data.size(0)
# 取张量第0维的长度,也就是当前batch的批次大小
3.2 张量类型
浮点数默认类型:FloatTensor
Note
FloatTensor要比DoubleTensor类型速度快;FloatTensor也是torch默认的浮点数张量类型,请参见“PyTorch | default floating point tensor type”。
获得当前运行时的默认浮点数类型:
torch.get_default_dtype()
# 例如:torch.float32
类型转换:
x.to(torch.type)
# 面向对象方式的类型转换
tensor.long()
tensor.float()
# 转换到numpy
tensor.numpy()
# 转换到CUDA
tensor.cuda()
3.3 张量的复制操作
获得不进行反向传播的tensor副本(“类似于.copy()”)
tensor.detach().clone()
3.4 生成与np.ndarray共享内存的张量
# Numpy数据
data = np.array([1, 2, 3])
# 生成共享内存张量
xs = torch.from_numpy(data)
[exp_np_share memory.ipynb]显示了torch.Tensor与np.ndarray共享内存的效果;
关于torch.Tensor跟np.ndarray共享内存的具体表现,可以参考博文《PyTorch中的.Tensor、.tensor、.from_numpy、.as_tensor区别》;
3.5 张量的索引操作
索引运算符:x[bool_mask]
获得单个维度上指定长度的切片视图:x.narrow(dim, start, length)(可以用来实现tf.slice)
3.5.1 .gather():根据索引张量index选取对应值
使用要点:
- index的
dim()等于原tensor的dim() - index的值仅替换原tensor中对应dim的下标值
- 最终输出为替换下标后在原tensor中的值
这里以获取类别分数为例进行说明,
x = torch.tensor([[1,2],[3,4]], device = 'cuda')
indx = torch.tensor([[0],[1]], device = 'cuda')
# indx = torch.tensor([0,1], device = 'cuda')
# 就会报错
x.gather(dim=1,index = indx)
Note:.gather()函数要求索引index与输入input维度保持一样,所以这里的index的维度是(bs, 1),这里的1 表示每个batch里面选择一个值;在这里,也就是最高的置信度。
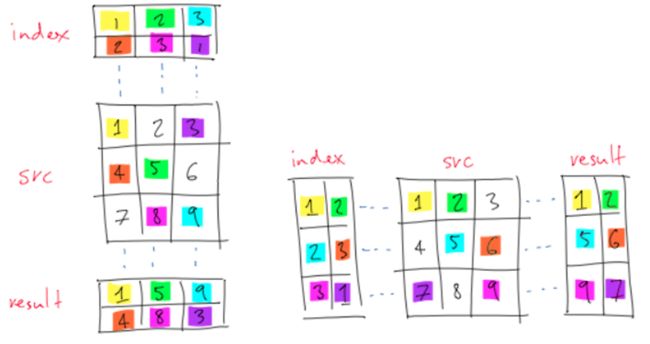
这里可以看看博文《pytorch中的gather()函数》的示意图,比较形象化可以帮助我们理解.gather()函数的效果,
实现tf.slice的等价操作:x[index]
PyTorch中没有提供跟tf.slice类似的函数,一个等价的操作是:
# tf.slice(x, begin=[a1, a2, a3, a4], size=[l1, l2, l3, l4]) ->
x[a1:a1+l1, a2:a2+l2, a3:a3+l3, a4:a4+l4]
也可以用x.narrow(dim, start, length)来实现类似的操作;
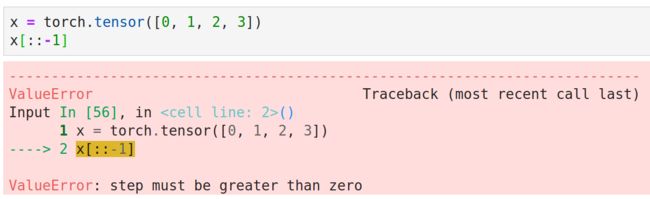
torch.Tensor[index]不支持负数步长
torch.Tensor是不支持一般的负数步长操作的,
可以用...符号表示张量中其它维度

a = torch.rand(2,3,4,5)
b = a[0, ...]
c = a[0, ..., 3]
可广播的掩码选择函数——torch.masked_select():
x.masked_select(mask)和x[mask]速度基本相同。
支持广播操作(tensor[mask]不支持)
tensor.masked_select()支持广播操作,例如:如果有形状是(A,B,C,D)的张量,而mask是(A,1,1,D),tensor.masked_select()同样可以实现掩码选择操作,而tensor[mask]无法实现。
返回的张量不与原始张量共享内存空间
实现了“深拷贝”的操作,保证了“函数式数据安全”。
3.5 张量的维度操作
torch.Tensor.contiguous()
这里引用ShellCollector的解释,我感觉说的挺好理解的:
一种可能的解释是: 有些tensor并不是占用一整块内存,而是由不同的数据块组成,而tensor的view()操作依赖于内存是整块的,这时只需要执行contiguous()这个函数,把tensor变成在内存中连续分布的形式。 判断是否contiguous用torch.Tensor.is_contiguous()函数。
不过这个操作我觉得已经被“弃用”了,因为使用它的原因是:对于某些内存非连续的Tensor变量,如果使用.view()操作,会出现“RuntimeError: input is not contiguous”的错误,这时我们就需要使用.contiguous()函数来生成一个深拷贝的副本,再进行.view()操作;
但是,在0.4版本后的Pytorch中,增加了torch.Tensor.reshape(),这与numpy.reshape()的功能类似。它大致相当于torch.Tensor.contiguous().view()
所以,我们以后尽量选择使用.reshape()操作;
展平张量
t.flatten()
# Examples:
# 将cls_score张量从维度2开始展开,即:保持维度0和维度1
cls_score.flatten(2) # start_dim=2
使用einops进行维度变换
使用einops实现不同形式维度变换的示例代码,请参考《Einops tutorial, part 1: basics》;
使用einops来简化PyTorch代码,请参考《Writing a better code with pytorch and einops》;
# 维度合并
rearrange(ims, 'b h w c -> (b h) w c')
增加batch维度
tensor.unsqueeze_(0)
# 这里使用的是unsqueeze操作的in-place版本
显式指定数字变换维度
对于通过显式的指定数字来变换张量的维度,这里推荐使用t.shape()函数,这是因为t.shape()会自动地判断是否可以返回张量的视图,从而能提升torch张量的效率(避免不必要的张量数据复制操作),
a = torch.arange(4.)
torch.reshape(a, (2, 2))
# tensor([[ 0., 1.],
# [ 2., 3.]])
变换张量维度(by einops)
y = rearrange(x, "b c h w -> b h w c")
改变张量维度(by each-dim)
tensor.reshape(w,h,c,n)
改变张量维度顺序(by dim-id)
tensor.permute(0,3,2,1)
维度复制repeat()
可以使用repeat()函数实现张量的维度复制
x = torch.tensor([[1,2,3],
[4,5,6],
[7,8,9]])
x = einops.repeat(x, 'c h w -> (2 c) h w')
x = x.repeat(2,1,1)
x
# tensor([[[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]],
# [[1, 2, 3],
# [4, 5, 6],
# [7, 8, 9]]])
3.5.1 使用命名张量(names)变换维度
在初始化张量是可以对它的维度进行命名,并通过维度名来进行相应的操作;
示例如下:

3.6 保存张量(Serialization)
x = torch.tensor([0, 1, 2])
torch.save(x, 'tensor.pt')
x1 = torch.load('tensor.pt', map_location=torchplus.DEVICE)
3.7 生成随机数
# [0,1)均匀分布中生成随机小数
torch.rand(10) # 长度为10向量
# (-infty, +infty)正态分布中生成随机数
torch.randn(10) # 长度为10向量
生成随机整数张量
指定范围生成随机整数张量
torch.randint(10, (bs,)) # 生成[0,10)之内size=(bs,1)的整数张量
Tensor.random_:按照Tensor的形状生成随机整数张量。
torch.empty(3).random_(2)
# 生成长度为3范围{0,1}的随机整数张量
3.7 张量比较
比较两个张量的size(形状)是否相同
a.size() == b.size()
两个张量是否相等(shape & elements)
a.equal(b)
浮点数张量是否足够接近
a.allclose(b)
3.8 张量合并
Conditional tensors with torch.where
当我们想要根据条件合并两个张量时,如果为True,则从第一个张量取值,如果为False,则从第二个张量中取值;
请参考代码
torch.where(mask, x, y)
3.10 张量运算
小数取整
# 近邻取整
x.round()
幂运算
x**2
# 使用**符号表示按元素的幂运算
逻辑运算
# 与, 或, 非, 异或
b1&b2, b1|b2, ~b, b1^b2
矩阵乘法@
X @ W
# 使用@符号表示矩阵乘法运算
# 仅以最后的两个维度实现矩阵乘法,多的维度不会生效
# 可以用于Attention机制中实现qk的乘法运算
3.8 统计计算
计算Tensor的mean&std
torch.std_mean(t)
统计列表中自然数出现的个数
tensor.bincount()
.bincount()会统计所有自然数出现的个数,其长度为最大的自然数+1;
Tensor常见函数说明
torch.Tensor.permute()
用来调整张量的维度的顺序;
4 Function
4.1 Advanced Indexing无法与sigmoid_()无法联合使用
测试代码:
import torch
a = torch.tensor([[0.0000, float('inf'), 1.1314],
[1.4110, 1.6292, 1.8083]])
print(a)
mask = a.isinf()
print(a[mask].sigmoid_()) # a[mask] -> Advanced Indexing
# In-Place Assignments
print(a)
>>>
tensor([[0.0000, inf, 1.1314],
[1.4110, 1.6292, 1.8083]])
tensor([1.])
tensor([[0.0000, inf, 1.1314],
[1.4110, 1.6292, 1.8083]])
可以看到sigmoid_()并没有在a中生效,也就是说 mask-indexing 无法跟 In-Place-Assignments 联合使用,Torch开发者在issue#80945中也对这个现象进行了说明;
4.2 自定义算子
自定义反向传播算子:torch.autograd.Function
请参考《TorchDoc | When to use torch.autograd》
在以下应用场景中,需要自定义算子:
- 使不可导算子实现反向传播运算
某些自带算子例如argmax,是不可导的,则可以自定义不可导运算的反向传播过程。
关于使用Function的教程,请参考《三分钟教你如何PyTorch自定义反向传播》
这里我们来学习以下文档中给出的示例代码:
# I.新建算子类继承torch.autograd.Function
class Exp(Function):
# II.实现前向运算函数
@staticmethod
def forward(ctx, i):
result = i.exp()
ctx.save_for_backward(result)
# ctx: 上下文对象(类型未知),负责从forward()向backward()传递数据,
# 保存的数据会被保存在saved_tensors元组中;
# 此处仅能保存tensor类型变量,对于其它类型变量(如int等),
# 可直接赋予ctx作为成员变量,也可以达到存储效果
return result
# III.实现反向运算函数
@staticmethod
def backward(ctx, grad_output):
result, = ctx.saved_tensors # 取出forward中保存的result张量
return grad_output * result
# 使用示例:
x = torch.tensor([1.], requires_grad=True)
# 需要设置tensor的requires_grad属性为True,才会进行梯度反传
# 使用apply方法调用自定义算子
ret = Exp.apply(x)
print(ret)
# tensor([2.7183], grad_fn=)
ret.backward() # 反传梯度
print(x.grad) # tensor([2.7183])
自定义C++算子:通过算子融合追求更高的计算性能
官方文档:《Custom C++ and CUDA Extensions — PyTorch Tutorials documentation》
多个算子API组合得到的运算逻辑会引入一定的Python交互与算子调度开销,如果想要追求更高的性能,可以使用单个C++自定义算子实现多个原PyTorch算子的功能,从而提高性能;
关于使用C++定义深度学习算子的教程,请参考《百度AI Studio课程 - 飞桨自定义算子实现和使用》
5 Module
5.1 基本模块
展平层: flatten
使用torch.flatten()或者nn.Flatten();
滑动平均
self.running_mean += momentum*(current - self.running_mean)
# 这样会比下面的写法节省两个需要写作的参数
# self.running_mean = (1 - momentum)*self.running_mean + momentum*current
使用Reduce('b c h w -> b c', 'mean')代替AvgPool2d操作
具体可以参考[einops.rocks/pytorch-examples | Simplifying ResNet];
5.2 自定义更新参数和注册固定参数
查看模块参数:nn.Module.state_dict
示例如下:
# jupyter-lab
import torch.nn as nn
m = nn.BatchNorm2d(3)
list(m.state_dict().keys())
>>> ['weight', 'bias', 'running_mean', 'running_var', 'num_batches_tracked']
自定义更新参数
# 定义Parameter
self.a = nn.Parameter(torch.randn(1, 2))
# 此时参数的requires_grad自动为true
# 新建参数后,此参数也会自动注册到当前模块的parameters()中去
注册固定参数(模块状态信息,不参加梯度更新)
典型的用例就是BN的running_mean参数,(“For example, BatchNorm’s running_mean is not a parameter, but is part of the module’s state”),示例代码如下:
self.register_buffer('running_mean', torch.zeros(n))
# 引用变量
print(self.running_mean)
5.3 Layers容器
ModuleList:torch中用来归纳layers的列表,用法类似于list。
5.4 Hook机制
PyTorch提供了以下四种hook函数:
| Hook | description |
|---|---|
| register_load_state_dict_post_hook | Post hook to be run after module’s load_state_dict is called |
| register_forward_pre_hook | Forward pre-hook before forward() |
| register_forward_hook | Forward hook after forward() |
| register_full_backward_hook | Backward hook after backward() |
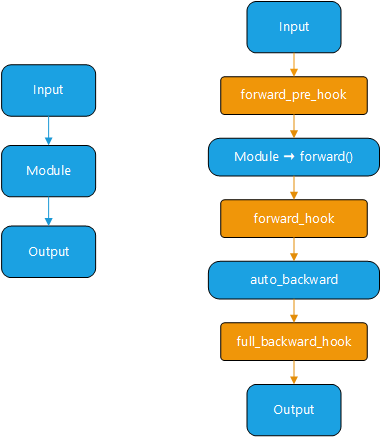
Torch代码位点示意图:
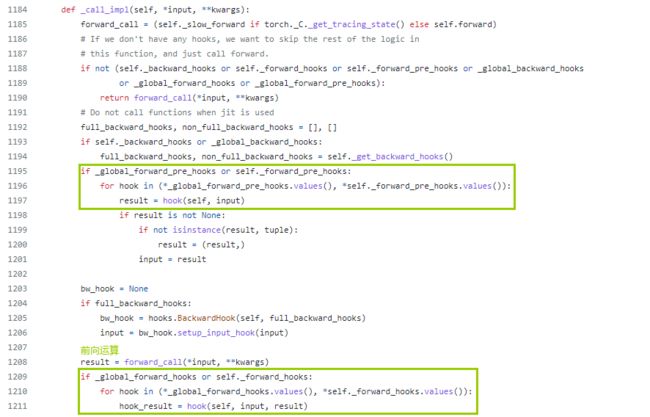
5.5 高级用法
使用torch.chunk()实现等同维度输出
请参考原文《13 FEATURES OF PYTORCH THAT YOU SHOULD KNOW – 8. Linear layer + chunking trick (torch.chunk)》
示例代码如下:
d = 1024
batch = torch.rand((8, d))
layers = nn.Linear(d, 128, bias=False), nn.Linear(d, 128, bias=False), nn.Linear(d, 128, bias=False)
one_layer = nn.Linear(d, 128 * 3, bias=False)
%%timeit
o1 = layers[0](batch)
o2 = layers[1](batch)
o3 = layers[2](batch)
289 µs ± 30.8 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
%%timeit
o1, o2, o3 = torch.chunk(one_layer(batch), 3, dim=1)
# 202 µs ± 8.09 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
Module常见函数说明
torch.nn.Module.register_full_backward_hook(hook)
反向传播的hook函数,可以用来:
- 可以查看当前层参数的梯度;
- 可以用来设置当前层的customized学习率,示例代码请参考DCNv2–self.m_conv.register_backward_hook(self._set_lr)
6 Model
5.1 打印网络结构
print(net)
5.2 切换模型模式:train() | eval()
train() | eval()的工作原理主要是设置对标志参数self.training进行切换:

7 缓存清理
del torch_resource
gc.collect()
torch.cuda.empty_cache()
8 数据载入
8.1 使用dali进行数据载入
torch |
dali |
|---|---|
DataLoader |
DALIGenericIterator |
9 优化更新
9.1 优化器——torch.optim.Optimizer
load_state_dict():加载状态字典
state_dict():返回优化器状态
["state"]:优化器状态的字典
["param_groups "]:所有参数组优化超参的列表
add_param_group(param_group): 加入自定义参数组
增加自定义的一组参数,可以定制 lr,momentum, weight_decay等超参数,在finetune中常用。
7.2 梯度裁减
nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=20, norm_type=2)
7.2 对bias参数单独设置学习率
请参考《PyTorch中对bias参数单独设置学习率》
7.3 学习率调整
使用optimizer.param_groups直接改变参数学习率
for param_group in optimizer.param_groups:
param_group['lr'] = lr
print('Updating learning rate to {}'.format(lr))
上述相关代码可以参考《深度学习pytorch训练代码模板(个人习惯) | adjust lr》
Torch内置学习率规划器:torch.optim.lr_scheduler
学习率调整策略:
# Assuming optimizer uses lr = 0.05 for all groups
# lr = 0.05 if epoch < 30
# lr = 0.005 if 30 <= epoch < 80
# lr = 0.0005 if epoch >= 80
scheduler = MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(100):
train(...)
validate(...)
scheduler.step()
优化器链式更新
请参考《[深度学习框架]PyTorch常用代码段 | 优化器链式更新》
9 Troubleshooting
9.1 出现错误“AssertionError: Torch not compiled with CUDA enabled”
这是因为没有下载CUDA版本的PyTorch,重新在官网选择CUDA版本PyTorch安装即可;
这里可以使用
conda list torch
查看当前安装torch的编译版本,示例结果如图所示

这里编译版本“cuda112py310h51fe464_200”包含“cuda”,则表示是使用CUDA编译的版本;
10 调试分析
10.1 检查张量信息
# 判断张量是否包含nan
tensor.isnan().any()
# 模拟张量中出现inf
torch.tensor([1, float('inf'), 2, float('-inf'), float('nan')])
关于“训练中出现loss为nan”的调试笔记,请参考“《深度学习笔记》——在训练过程中出现nan的调试笔记”
8.2 检查模块信息
显示module的“所有的”参数及其names
module.named_parameters()
显示模块每一层输出张量的尺寸
from torchinfo import summary
model = ConvNet()
batch_size = 16
summary(model, input_size=(batch_size, 1, 28, 28))
8.3 设置卷积层权重
module = nn.Conv2d(in_channels=image.shape[1], out_channels=filter.shape[0], kernel_size=filter.shape[2], stride=1,padding='same', bias=False)
module.weight.data[:] = filter
8.4 模型结构可视化
关于可视化的更多内容,请参见《Visualization(可视化)的学习笔记》
TensorBoard
关于在PyTorch中使用TensorBoard,请参考《PyTorch | Docs | torch.utils.tensorboard》
with SummaryWriter(path) as w:
w.add_graph(net, images)
8.5 打印当前学习率
scheduler.get_lr()
8.6 查看GPU状态
Torch.cuda.max_memory_allocated():返回显存占用峰值
使用torch.cuda.max_memory_allocated()可以获得当前运行时显存占用的峰值;
10 性能分析
统计模型MACs: ptflops
可以使用ptflops来统计模块的MACs数,来估计此模块的计算复杂度;
测量代码段运行时间:torch.cuda.Event(enable_timing=True)
关于测量 torch-CUDA代码的运行时间,请参考《CUDA semantics — PyTorch documentation | Asynchronous execution》
统计各部分代码耗时
with torch.autograd.profiler.profile(enabled=True, use_cuda=False) as profile:
...
print(profile)
# 或者在命令行运行
python -m torch.utils.bottleneck main.py
Torch分析工具
使用Torch自带的工具进行性能分析请参考《【PyTorch】使用Torch自带的工具进行性能分析》
NVIDIA工具: DLProf
DLProf是英伟达官方提供的可对Torch进行性能分析的工具,也是PyProf 的继任者;
Python分析工具:cProfile
关于使用cProfile对.py脚本进行性能分析,请参考博文《PyTorch消除训练瓶颈 提速技巧(by pprp)| 2. 如何测试训练过程的瓶颈》
11 性能优化
请参考《【PyTorch】性能优化的学习笔记》
12 参数统计
请参考《PyTorch中统计模块参数的学习笔记》
13 数据集载入
13.1 关于使用num_workers并行读取数据时出现内存占用过大的问题
我们在使用DataLoader读取数据时,会出现内存占用过高的问题,Torch官方在文档里面也明确指出了这个现象:“WARNING: After several iterations, the loader worker processes will consume the same amount of CPU memory as the parent process for all Python objects in the parent process which are accessed from the worker processes.”
14 序列化和读取
请参考《PyTorch数据保存和读取的学习笔记》