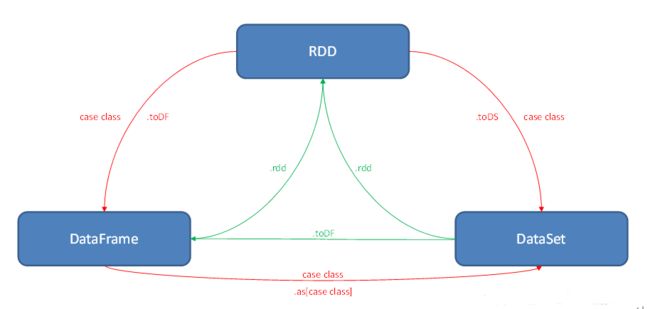
Spark之创建Rdd、DataFrame、Dataset
一、RDD
1.1 通过本地集合创建RDD
val seq1 = Seq(1001,"liming",24,95)
val seq2 = Seq(1,2,3)
//可以不指定分区数
val rdd1: RDD[Any] = sc.parallelize(seq1,2)
println(rdd1.collect().mkString(","))
val rdd2: RDD[Int] = sc.makeRDD(Seq(1,2,3,4),2)
//也可以使用Array、List
val rdd3 = sc.parallelize(List(1, 2, 3, 4))
val rdd4 = sc.parallelize(Array(1, 2, 3, 4))
rdd3.take(10).foreach(println)
1.2 通过外部数据创建RDD
//外部数据(文件)创建RDD
val rdd1 = sc.textFile("file_path")
//1、textFile传入的是一个路径
//2、分区是由HDFS中的block决定的
1.3 通过RDD衍生新的RDD
//RDD衍生RDD
val rdd1 = sc.parallelize(Seq("zhangsan","lisi","wangwu"))
//通过RDD执行算子操作会产生RDD
val rdd2 = rdd1.map(item => (item, 1))
二、DataFrame
1.1 通过Seq生成
val df = spark.createDataFrame(Seq(
("ming", 20, 15552211521L),
("hong", 19, 13287994007L),
("zhi", 21, 15552211523L)
)).toDF("name", "age", "phone")
df.show()
1.2 通过读取外部结构化数据
1.2.1 读取Json文件生成
json文件内容:
{"name":"ming","age":20,"phone":15552211521}
{"name":"hong", "age":19,"phone":13287994007}
{"name":"zhi", "age":21,"phone":15552211523}代码:
val dfJson = spark.read.format("json").load("/Users/hadoop/sparkLearn/data/student.json")
dfJson.show()1.2.2 读取csv文件生成
csv文件:
name,age,phone
ming,20,15552211521
hong,19,13287994007
zhi,21,15552211523代码:
val dfCsv = spark.read.format("csv").option("header", true).load("/Users/hadoop/sparkLearn/data/students.csv")
dfCsv.show()1.2.3 读取parquet文件
val dfparquet = spark.read.parquet("/Users/hadoop/sparkLearn/data/students.parquet")1.3 通过jdbc创建
//读取数据库(mysql)
val options = new util.HashMap[String,String]()
options.put("url", "jdbc:mysql://localhost:3306/spark")
options.put("driver","com.mysql.jdbc.Driver")
options.put("user","root")
options.put("password","hollysys")
options.put("dbtable","user")
spark.read.format("jdbc").options(options).load().show()1.4 动态创建schema
1.4.1 ArrayList + Schema
val schema = StructType(List(
StructField("name", StringType, true),
StructField("age", IntegerType, true),
StructField("phone", LongType, true)
))
val dataList = new util.ArrayList[Row]()
dataList.add(Row("ming",20,15552211521L))
dataList.add(Row("hong",19,13287994007L))
dataList.add(Row("zhi",21,15552211523L))
spark.createDataFrame(dataList,schema).show()1.4.2 RDD + Schema
文件内容:
54655326,44039606001410150001,2020-11-28 20:51:04,2020-11-28 20:51:04,2020-11-28 18:45:16,61,http://190.176.35.157/photos/sensord
oor_face/20201128/6c33fe6e2215e74997a57a11916ece43/614374_1.jpg,szgj_img/20201128-ac8a6897-000a580ae00068-07f7ca68-00003eb0
54655326,44039606001410150001,2020-11-28 20:51:04,2020-11-28 20:51:04,2020-11-28 18:45:16,61,http://190.176.35.157/photos/sensord
oor_face/20201128/6c33fe6e2215e74997a57a11916ece43/614374_1.jpg,szgj_img/20201128-ac8a6897-000a580ae00068-07f7ca68-00003eb0
54655327,44039603011410050002,2020-11-28 20:51:04,2020-11-28 20:51:04,2020-11-28 19:37:49,272,http://190.176.35.157/photos/sensor
door_face/20201128/0ff9f28494461eafca57e569d62493f7/9578502_0.jpg,szgj_img/20201128-a96baad0-000a580ae01a5d-0885e0e0-000022b0 //从原始RDD中创建一个包含Row的RDD
val FacialProfileRDD: RDD[Row] = linesRDD.map(line => {
val strs: Array[String] = line.split(",")
Row(strs(0), strs(1), strs(2), strs(3), strs(4), strs(5), strs(6), strs(7))
})
//创建由StructType表示的模式,该模式与上述步骤中创建的RDD中的行结构相匹配
val structType: StructType = StructType(
StructField("aid", StringType, true) ::
StructField("gbNO", StringType, true) ::
StructField("create_time", StringType, true) ::
StructField("update_time", StringType, true) ::
StructField("acquisition_time", StringType, true) ::
StructField("recordId", StringType, true) ::
StructField("bigcaptureFaceUrl", StringType, true) ::
StructField("smallcaptureFaceUrl", StringType, true) ::
Nil
)
//DataFrame = RDD + Schema
//通过SparkSession提供的createDataFrame方法,将模式应用到Row的RDD中
val FacialProfileDF: DataFrame = spark.createDataFrame(FacialProfileRDD, structType)1.5 通过样例类case class 创建
文件内容同1.4.2
创建样例类:
package com.sibat.applications.part0
//样例类facialprofile:"aid","gbNo","create_time","update_time","acquisition_time","recordId","bigcaptureFaceUrl","smallcaptureFaceUrl"
case class FacialProfile(aid:String, gbNO:String, create_time:String, update_time:String, acquisition_time:String, recordId:String, bigcaptureFaceUrl:String, smallcaptureFaceUrl:String)组装:
//profile泛型是FacialProfile ,FacialProfile既有数据,又有字段
//数据 + Scheme
val FacialProfileRDD: RDD[FacialProfile] = linesRDD.map(line => {
val column: Array[String] = line.split(",")
FacialProfile(column(0), column(1), column(2), column(3),column(4), column(5), column(6), column(7))
})
//将RDD转成DF 需要导入隐式转换
//该隐式转换在SparkSession中
import spark.implicits._
val FacialProfileDF: DataFrame = FacialProfileRDD.toDF()三、DataSet
3.1 什么是DataSet
DataSet是分布式的数据集合,Dataset提供了强类型支持,也是在RDD的每行数据加了类型约束。DataSet是在Spark1.6中添加的新的接口。它集中了RDD的优点(强类型和可以用强大lambda函数)以及使用了Spark SQL优化的执行引擎。DataSet可以通过JVM的对象进行构建,可以用函数式的转换(map/flatmap/filter)进行多种操作。
3.2 DataSet操作API地址:
http://spark.apache.org/docs/2.2.0/api/scala/index.html#org.apache.spark.sql.Dataset
3.3 通过spark.createDataset通过集合进行创建dataSet
val ds1 = spark.createDataset(1 to 10)3.4 从已经存在的rdd当中构建dataSet
val ds2 = spark.createDataset(sc.textFile("file:///export/servers/person.txt"))3.5 通过样例类配合创建DataSet
spark-shell中一次输入多行操作
:paste后Enter进入,退出时进入没有输入的行Ctrl D结束
case class Person(name:String,age:Int)
val personDataList = List(Person("zhangsan",18),Person("lisi",28))
val personDS = personDataList.toDS
personDS.show
3.6 通过DataFrame转化生成
案例一:
使用as[类型]转换为DataSet
case class Person(name:String,age:Long)
val jsonDF = spark.read.json("file:///export/servers/spark-2.2.0-bin-2.6.0-cdh5.14.0/examples/src/main/resources/people.json")
val jsonDS = jsonDF.as[Person]
jsonDS.show案例二:
创建Dataframe
scala>val df= spark.createDataFrame(Seq(
("Tom",20,15552211521L),
("Jack",19,13287994007L),
("Tony",21,15552211523L),
("Tom",20,15552211521L),
("David",22,15552211523L),
("Alex",25,15552211523L)
)) toDF("name","age","phone")
df: org.apache.spark.sql.DataFrame= [name: string, age: int ...1 more field]查看
scala> df.show()
+-----+---+-----------+
| name|age| phone|
+-----+---+-----------+
| Tom|20|15552211521|
| Jack|19|13287994007|
| Tony|21|15552211523|
| Tom|20|15552211521|
|David|22|15552211523|
| Alex|25|15552211523|
+-----+---+-----------+创建样例类
scala>import spark.implicits._
import spark.implicits._
scala>case class Person(name: String, age: String, phone: String)
definedclass Person转成DataSet
scala>val person= df.as[Person]
person: org.apache.spark.sql.Dataset[Person]= [name: string, age: int ...1 more field]
scala> person.show
+-----+---+-----------+
| name|age| phone|
+-----+---+-----------+
| Tom|20|15552211521|
| Jack|19|13287994007|
| Tony|21|15552211523|
| Tom|20|15552211521|
|David|22|15552211523|
| Alex|25|15552211523|
+-----+---+-----------+DataSet的基本操作
去重(所有字段都相同)
scala> person.distinct().show()
+-----+---+-----------+
| name|age| phone|
+-----+---+-----------+
|David|22|15552211523|
| Alex|25|15552211523|
| Tom|20|15552211521|
| Tony|21|15552211523|
| Jack|19|13287994007|
+-----+---+-----------+去重(某一字段相同)
scala> person.dropDuplicates("phone").show()
+----+---+-----------+
|name|age| phone|
+----+---+-----------+
|Jack|19|13287994007|
| Tom|20|15552211521|
|Tony|21|15552211523|
+----+---+-----------+四、RDD,DataFrame,DataSet互相转化