ResNet50实现kaggle猫狗分类
ResNet50实现kaggle猫狗分类
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
-
- ResNet50实现kaggle猫狗分类
- 前言
- 一、构造ResNet50模型
-
- 1、残差结构
- 2、ResNet50模型基本构成
- 3.实现代码
- 二、实现猫狗图像识别
-
- 1.数据来源
- 2.重构dataset
- 3.图像处理
- 4.载入数据
- 5.训练与验证函数
- 6.将结果生成为csv文件
- 附录 train.py全部代码
前言
Resnet是残差网络(Residual Network)的缩写,该系列网络广泛用于目标分类等领域以及作为计算机视觉任务主干经典神经网络的一部分,典型的网络有resnet50, resnet101等。Resnet网络的证明网络能够向更深(包含更多隐藏层)的方向发展。
论文:Deep Residual Learning for Image Recognition
一、构造ResNet50模型
1、残差结构
Residual net(残差网络)
将靠前若干层的某一层数据输出直接跳过多层引入到后面数据层的输入部分。
意味着后面的特征层的内容会有一部分由其前面的某一层线性贡献。
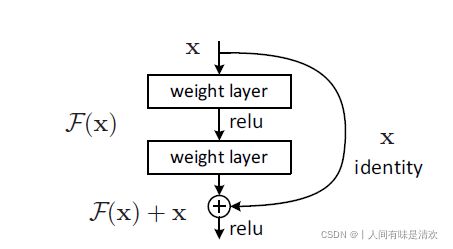
深度残差网络的设计是为了克服由于网络深度加深而产生的学习效率变低与准确率无法有效提升的问题。
为什么网络越深,效果反而可能会越差?
假设该模型完美层数为N,则多余的层继续训练会造成过拟合现象,因此对于额外层数的训练目标是恒等变换,即不对参数做出改变,那么对于这些多余的层,拟合目标为H(x)=x,F(x)–>0。
2、ResNet50模型基本构成
ResNet50有两个基本的块,分别名为Conv Block和Identity Block
Conv Block输入和输出的维度(通道数和size)是不一样的,所以不能连续串联,它的作用是改变网络的维度;
Identity Block输入维度和输出维度(通道数和size)相同,可以串联,用于加深网络的。
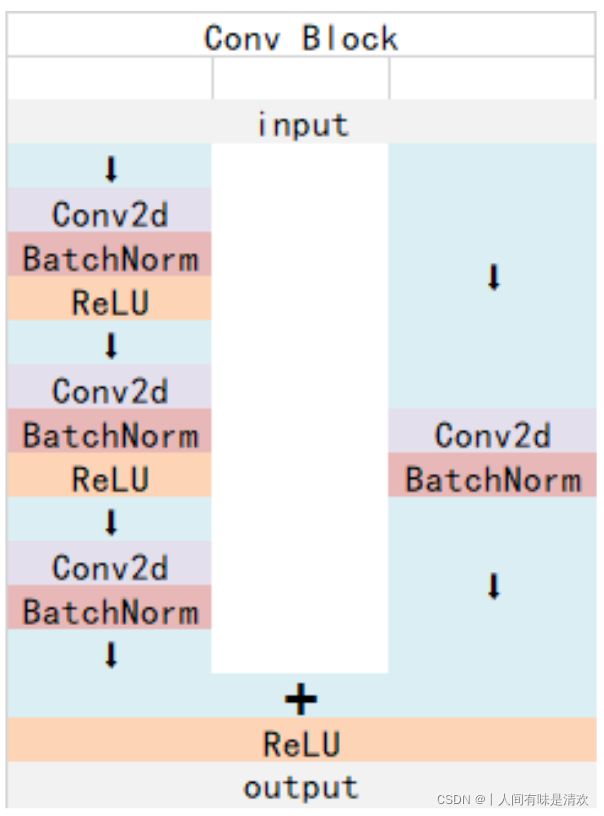
Resnet50的总体模块图如下图所示。

3.实现代码
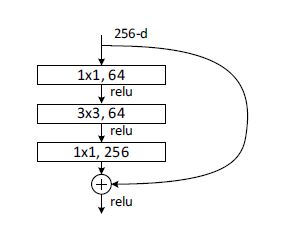
Bottleneck封装下图结构
import torch
import torch.nn as nn
from torch.nn import functional as F
'''
Block的各个plane值:
in_channel:输入block的之前的通道数
mid_channel:在block中间处理的时候的通道数(这个值是输出维度的1/4)
mid_channel * self.extension:输出的维度
downsample:是否下采样,将宽高缩小
'''
class Bottleneck(nn.Module):
# 每个stage中维度拓展的倍数
extension = 4
def __init__(self, in_channel, mid_channel, stride, downsample=None):
super(Bottleneck, self).__init__()
self.downsample = downsample
self.stride = stride
self.conv1 = nn.Conv2d(in_channel, mid_channel, stride=stride, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(mid_channel)
self.conv2 = nn.Conv2d(mid_channel, mid_channel, stride=1, kernel_size=3, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(mid_channel)
self.conv3 = nn.Conv2d(mid_channel, mid_channel * self.extension, stride=1, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(mid_channel * self.extension)
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
# 残差数据
residual = x
# 卷积操作
out = self.relu(self.bn1(self.conv1(x)))
out = self.relu(self.bn2(self.conv2(out)))
out = self.relu(self.bn3(self.conv3(out)))
# 是否直连(如果是Identity block就是直连;如果是Conv Block就需要对参差边进行卷积,改变通道数和size)
if (self.downsample != None):
residual = self.downsample(x)
# 将残差部分和卷积部分相加
out = out + residual
out = self.relu(out)
return out
class Resnet(nn.Module):
def __init__(self, block, layers, num_classes=2):
super(Resnet, self).__init__()
self.in_channel = 64
self.block = block
self.layers = layers
# stem网络层
self.conv1 = nn.Conv2d(in_channels=3, out_channels=self.in_channel, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(self.in_channel)
self.relu = nn.ReLU()
self.maxpool = nn.MaxPool2d(kernel_size=3, padding=1, stride=2)
self.stage2 = self.make_layer(self.block, 64, self.layers[0], stride=1) # 因为在maxpool中stride=2
self.stage3 = self.make_layer(self.block, 128, self.layers[1], stride=2)
self.stage4 = self.make_layer(self.block, 256, self.layers[2], stride=2)
self.stage5 = self.make_layer(self.block, 512, self.layers[3], stride=2)
self.avgpool = nn.AvgPool2d(7)
self.fc = nn.Linear(512 * block.extension, num_classes)
def forward(self, x):
# stem部分:conv+bn+relu+maxpool
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
# block
out = self.stage2(out)
out = self.stage3(out)
out = self.stage4(out)
out = self.stage5(out)
# 分类
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
def make_layer(self, block, mid_channel, block_num, stride):
"""
:param block:
:param mid_channel:
:param block_num: 重复次数
:param stride:
:return:
"""
block_list = []
# projection shortcuts are used for increasing dimensions, and other shortcuts are identity
downsample = None
if stride != 1 or self.in_channel != mid_channel * block.extension:
downsample = nn.Sequential(
nn.Conv2d(self.in_channel, mid_channel * block.extension, stride=stride, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel * block.extension)
)
# Conv Block
conv_block = block(self.in_channel, mid_channel, stride=stride, downsample=downsample)
block_list.append(conv_block)
self.in_channel = mid_channel * block.extension
# Identity Block
for i in range(1, block_num):
block_list.append(block(self.in_channel, mid_channel, stride=1))
return nn.Sequential(*block_list)
# 打印网络结构
# resnet = Resnet(Bottleneck, [3, 4, 6, 3])
# print(resnet)
二、实现猫狗图像识别
1.数据来源
https://www.kaggle.com/c/dogs-vs-cats-redux-kernels-edition
2.重构dataset
torch.utils.data.Dataset是一个抽象类,用户想要加载自定义的数据只需要继承这个类,并且覆写其中的两个方法即可:
len:实现len(dataset)返回整个数据集的大小。
getitem:用来获取一些索引的数据,使dataset[i]返回数据集中第i个样本。
不覆写这两个方法会直接返回错误。
代码如下:
class dataset(torch.utils.data.Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
# dataset length
def __len__(self):
self.filelength = len(self.file_list)
return self.filelength
# load an one of images
def __getitem__(self, index):
img_path = self.file_list[index]
img = Image.open(img_path)
img_transformed = self.transform(img)
label = img_path.split('/')[-1].split('\\')[-1].split('.')[0]
if label == 'dog':
label = 1
elif label == 'cat':
label = 0
return img_transformed, label
3.图像处理
torchvision.transforms : 常用的图像预处理方法,提高泛化能力
# Image Augumentation
train_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
val_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
test_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
4.载入数据
# train_data中每个元素为tuple类型,长度为2,tuple第一个元素为torch.Size([3, 224, 224]),第二个元素为int类型,标签
train_data = dataset(train_list, transform=train_transforms)
test_data = dataset(test_list, transform=test_transforms)
val_data = dataset(val_list, transform=test_transforms)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=val_data, batch_size=batch_size, shuffle=True)
5.训练与验证函数
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1) # 返回最大值的下标,如tensor([0, 1, 1, 1, 1, 1])
cur_acc = torch.sum(y == pred) / output.shape[0]
# 反向传播
optimizer.zero_grad() # 初始化梯度
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
train_loss = loss / n
train_acc = current / n
return train_loss, train_acc
# 定义一个验证函数
def val(dataloader, model, loss_fn):
# 将模型转化为验证模型,否则的话,有输入数据,即使不训练,它也会改变权值
model.eval()
loss, current, n = 0.0, 0.0, 0
with torch.no_grad():
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
val_loss = loss / n
val_acc = current / n
return val_loss, val_acc
6.将结果生成为csv文件
def submission(csv_path, test_loader, device, model):
result_list = []
model.eval()
with torch.no_grad(): # network does not update gradient during evaluation
for i, data in enumerate(test_loader):
images, label = data[0].to(device), data[1]
outputs = model(images)
softmax_func = nn.Softmax(dim=1) # dim=1 means the sum of rows is 1
soft_output = softmax_func(outputs) # soft_output is become two probability value
predicted = soft_output[:, 1] # the probability of dog
for j in range(len(predicted)):
result_list.append({
'id': label[j].split('/')[-1].split('\\')[-1].split('.')[0],
'label': predicted[j].item()
})
# convert list to dataframe, and then generate csv format file
columns = result_list[0].keys() # return "id" "label"
result_list = {col: [anno[col] for anno in result_list] for col in columns}
result_df = pd.DataFrame(result_list)
result_df = result_df.sort_values("id")
result_df.to_csv(csv_path, index=None)
附录 train.py全部代码
import glob
import os
import time
import pandas as pd
import torch
from matplotlib import pyplot as plt
from torch import optim, nn
from torch.optim import lr_scheduler
import resnet50
from PIL import Image
from sklearn.model_selection import train_test_split
from torchvision.transforms import transforms
device = 'cuda' if torch.cuda.is_available() else 'cpu'
batch_size = 32
train_dir = 'E:/ResNet_cat&dog/train'
test_dir = 'E:/ResNet_cat&dog/test'
model_path = "E:/ResNet_cat&dog/best_model.pth"
# 获取文件列表
train_list = glob.glob(os.path.join(train_dir, '*.jpg'))
test_list = glob.glob(os.path.join(test_dir, '*.jpg'))
train_list, val_list = train_test_split(train_list, test_size=0.1)
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定义画图函数
def matplot_loss(train_loss, val_loss):
plt.plot(train_loss, label='train_loss')
plt.plot(val_loss, label='val_loss')
plt.legend(loc='best')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.title("训练集、验证集loss值对比图")
plt.show()
def matplot_acc(train_acc, val_acc):
plt.plot(train_acc, label='train_acc')
plt.plot(val_acc, label='val_acc')
plt.legend(loc='best')
plt.ylabel('acc')
plt.xlabel('epoch')
plt.title("训练集、验证集acc值对比图")
plt.show()
# Image Augumentation
train_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
val_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
test_transforms = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
# Load datasets
class dataset(torch.utils.data.Dataset):
def __init__(self, file_list, transform=None):
self.file_list = file_list
self.transform = transform
# dataset length
def __len__(self):
self.filelength = len(self.file_list)
return self.filelength
# load an one of images
def __getitem__(self, index):
img_path = self.file_list[index]
img = Image.open(img_path)
img_transformed = self.transform(img)
label = img_path.split('/')[-1].split('\\')[-1].split('.')[0]
if label == 'dog':
label = 1
elif label == 'cat':
label = 0
return img_transformed, label
# train_data中每个元素为tuple类型,长度为2,tuple第一个元素为torch.Size([3, 224, 224]),第二个元素为int类型,标签
train_data = dataset(train_list, transform=train_transforms)
test_data = dataset(test_list, transform=test_transforms)
val_data = dataset(val_list, transform=test_transforms)
train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(dataset=val_data, batch_size=batch_size, shuffle=True)
model = resnet50.Resnet(resnet50.Bottleneck, [3, 4, 6, 3]).to(device)
# optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9, weight_decay=0.0005)
criterion = nn.CrossEntropyLoss()
lr_scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5)
# 迭代epoch
model.load_state_dict(torch.load(model_path))
# 定义训练函数
def train(dataloader, model, loss_fn, optimizer):
loss, current, n = 0.0, 0.0, 0
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1) # 返回最大值的下标,如tensor([0, 1, 1, 1, 1, 1])
cur_acc = torch.sum(y == pred) / output.shape[0]
# 反向传播
optimizer.zero_grad() # 初始化梯度
cur_loss.backward()
optimizer.step()
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
train_loss = loss / n
train_acc = current / n
return train_loss, train_acc
# 定义一个验证函数
def val(dataloader, model, loss_fn):
# 将模型转化为验证模型,否则的话,有输入数据,即使不训练,它也会改变权值
model.eval()
loss, current, n = 0.0, 0.0, 0
with torch.no_grad():
for batch, (x, y) in enumerate(dataloader):
image, y = x.to(device), y.to(device)
output = model(image)
cur_loss = loss_fn(output, y)
_, pred = torch.max(output, axis=1)
cur_acc = torch.sum(y == pred) / output.shape[0]
loss += cur_loss.item()
current += cur_acc.item()
n = n + 1
val_loss = loss / n
val_acc = current / n
return val_loss, val_acc
def submission(csv_path, test_loader, device, model):
result_list = []
model.eval()
with torch.no_grad(): # network does not update gradient during evaluation
for i, data in enumerate(test_loader):
images, label = data[0].to(device), data[1]
outputs = model(images)
softmax_func = nn.Softmax(dim=1) # dim=1 means the sum of rows is 1
soft_output = softmax_func(outputs) # soft_output is become two probability value
predicted = soft_output[:, 1] # the probability of dog
for j in range(len(predicted)):
result_list.append({
'id': label[j].split('/')[-1].split('\\')[-1].split('.')[0],
'label': predicted[j].item()
})
# convert list to dataframe, and then generate csv format file
columns = result_list[0].keys() # return "id" "label"
result_list = {col: [anno[col] for anno in result_list] for col in columns}
result_df = pd.DataFrame(result_list)
result_df = result_df.sort_values("id")
result_df.to_csv(csv_path, index=None)
# 开始训练
loss_train = []
acc_train = []
loss_val = []
acc_val = []
epoch = 5
min_acc = 0
for t in range(epoch):
lr_scheduler.step()
start = time.time()
train_loss, train_acc = train(train_loader, model, criterion, optimizer)
val_loss, val_acc = val(val_loader, model, criterion)
end = time.time()
print(f"第{t + 36}次epoch训练时间:{end - start}s")
print('Epoch : {}, train_accuracy : {}, train_loss : {}'.format(t + 1, train_acc, train_loss))
print('Epoch : {}, val_accuracy : {}, val_loss : {}'.format(t + 1, val_acc, val_loss))
loss_train.append(train_loss)
acc_train.append(train_acc)
loss_val.append(val_loss)
acc_val.append(val_acc)
# 保存最好的模型权重
if val_acc > min_acc:
min_acc = val_acc
print(f"save best model, 第{t + 1}轮")
torch.save(model.state_dict(), 'best_model.pth')
matplot_loss(loss_train, loss_val)
matplot_acc(acc_train, acc_val)
csv_path = './submission.csv'
model = resnet50.Resnet(resnet50.Bottleneck, [3, 4, 6, 3]).to(device)
model.load_state_dict(torch.load(model_path))
submission(csv_path, test_loader, device, model)