【文献阅读】Label Inference Attacks Against Vertical Federated Learning
【文献阅读】Label Inference Attacks Against Vertical Federated Learning
这篇文章提出了三种针对纵向联邦学习的标签推理攻击:
- 被动标签推理攻击(补全本地模型使之具有推理能力)
- 主动标签推理攻击(主动地增加本地模型在全局的权重)
- 直接标签推理攻击(直接通过梯度符号判断标签)
并利用常见的VFL防御方法对本文提出的攻击手段进行了测试,结果表明本文提出的攻击手段具有良好的表现。
1. 背景
1.1 架构
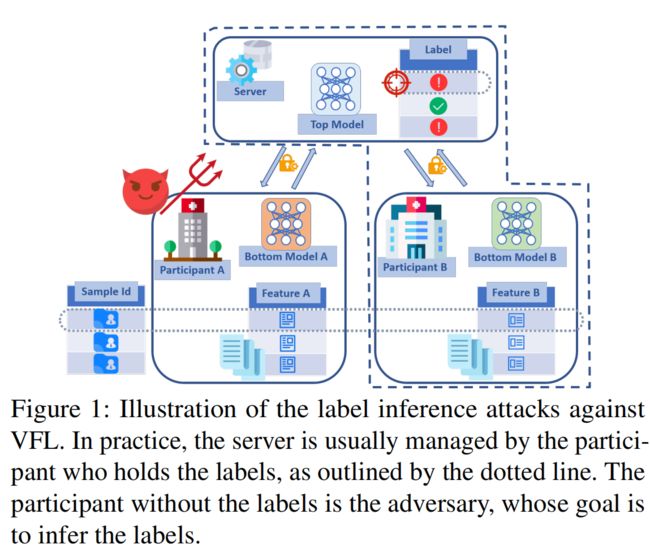
如图所示公司A和公司B的数据库中有部分用户ID重叠,且他们各持有不同的特征。使用纵向联邦学习训练预测模型,其中B为服务器,持有标签、顶部模型和底部模型;A只持有底部模型,并为B提供特征训练顶部模型。
训练流程:A和B根据本地特征进行训练,对应的底部模型生成一个中间结果发送给B->B的顶部模型接收到中间结果后,对结果进行聚合,计算误差,将梯度返回给A和B的底部模型->底部模型根据梯度计算本地参数的更新
1.2 威胁模型
公司A 是curious-but-honest,目的是对推理出B的标签。
在无模型分割的VFL中,由于VFL的特性,A只能控制联邦模型的一部分(A的底部模型),这一部分模型只能接收到来自服务器的一部分梯度,并且没有预测能力
2. 标签推理攻击
2.1 VFL中可能的隐私泄露点
底部模型的泄露
VFL中,在训练阶段和预测阶段,威胁者可以完全掌控其底部模型。底部模型提供一个具有代表性的特征表示以供预测,一个恶意底部模型的表达能力取决于它的训练程度和它与最终预测层的接近程度
梯度的泄露
威胁者可以直接基于接收到的梯度进行标签推理攻击
2.2 Passive Label Inference Attack through Model Completion
目标:威胁者通过完善本地底部模型,使得本地模型具有预测能力
过程:利用少量的带标签的数据,在本地模型之上添加一个分类层,以供标签推理
方法:模型补全 改进半监督学习算法MixMatch算法,添加到底部模型之上,使得底部模型成为完全模型,具有预测能力
MixMatch算法通过对少量标记数据和未标记数据进行数据增广,再分别计算两者的损失,最终的整体损失是两者的加权。【参考:超强半监督学习 MixMatch】
改进的点:去掉了对x和u的数据增广这两行代码,作者的说法是这样做可以使得MixMatch适用于更多的领域,而不仅仅是CV
原MixMatch算法:

本文算法:

2.3 Active Label Inference Attack with the Malicious Local Optimizer
目标:威胁者可以加速他/她的底部模型上的梯度下降,从而在每次迭代中向服务器提交更好的特性。最后,它使得顶层模型更多依赖于自己的底层模型,而不是其他参与者。换句话说,威胁者可以在训练底部模型的时候恶意地扩大学习率
挑战:设置过大的学习率,会使网络参数从最短路径偏离到局部最优路径,并在局部最小点附近震荡。
方法:为了解决这一挑战,设计了一个自适应的恶意局部优化器,它自适应地放大了对手的底部模型中每个参数的梯度。如算法1所示,β是动量参数,G是损失关于底部模型中每个参数的梯度,rθ是自适应梯度缩放因子,vθ是之前迭代中每个比例梯度的指数移动平均值(也成为速度)。
- 接收来自服务器的返回梯度Goutput
- 反向传播计算G
- 根据指数移动平均计算Vθ
- 如果不是首轮迭代的话:
- 计算rθ,γ是超参数(本文中设为1),vlast是上一轮迭代中vθ的值
- rθ根据上下限进行限制,然后对vθ进行缩放
- vlast更新为vθ,θ根据学习率和vθ进行更新
通过使用这种机制,恶意的局部优化器通过自适应缩放因子来放大梯度。为了说明自适应比例因子是如何工作的,处于简化的考虑,我们研究只有一个参数的情况:它只有两个优化方向:增加或减少。如果速度(该参数的速度)与最后一次迭代的速度有一个相反的符号,则认为它是一个振荡信号。相应地,恶意的本地优化器会减少比例因子。这种直觉类似于经典的优化算法Rprop [40]。相反,如果速度的符号在一系列迭代中保持不变,可以推断参数在一个方向上稳定优化。然后,恶意的本地优化器将增加比例因子,以实现更快的优化

通过在训练阶段使用恶意的局部优化器,对手可以得到一个训练好的具有更多标签隐藏信息的底部模型。然后,对手可以在被动推理攻击中进行模型完整化,得到最终的标签推理模型。主动标签推理攻击有望提高标签推理的准确性。
2.4 Direct Lable Inference Attack
根据接收到的来自预测层的梯度来推理对应的标签,适用于主流的用于分类的损失函数,如交叉熵损失,带权交叉熵存世,负对数似然损失。本文以交叉熵损失为例:
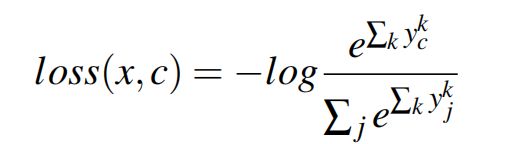
x是一个样本的特征,c是真实标签,yk是输出层的激活后的输出,adv号参与者是威胁者,对应于威胁者的第i个logit的梯度为:
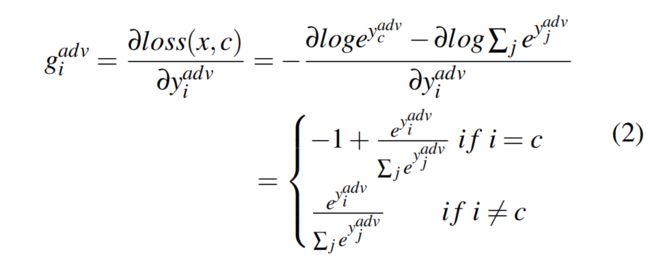
如果i=c的话,gi_adv为负,否则为正,因此gi_adv的符号指出了第i个预测标签是否为真实标签。所以威胁者可以根据服务器发回的梯度推断标签。这样可以获得少量真实标签,然后可以与上文提到的Passive Label Inference Attack相结合
3. 实验
3.1 已知标签数据量对攻击的影响
已知数据越多,攻击表现越好

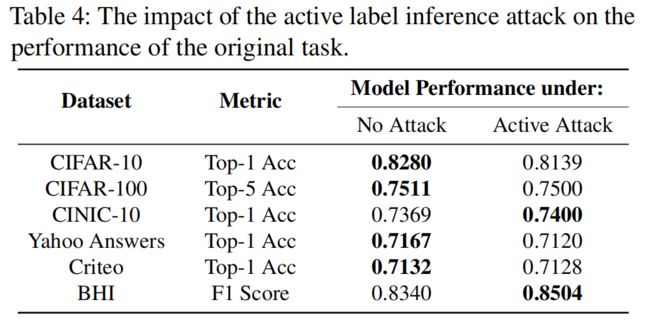
3.2 攻击对模型精度的影响
攻击对模型精度影响不大
3.3 威胁者拥有的特征对精度的影响
威胁者特征越多,训练出的完整模型精度越高

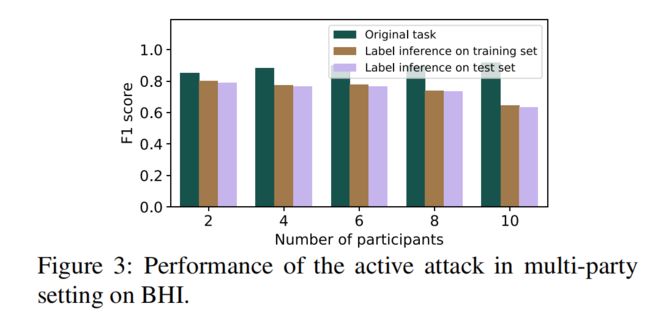
3.4 参与者数量对攻击效果的影响
参与者数量越多,攻击者对顶部模型的权重越小,攻击效果越差
3.5 主动攻击的效果
使用GradCAM进行可视化,图片的左半部分是攻击者的数据,右半部分是其他参与者的数据。可以看出,在经过恶意局部优化器的训练后,整个联邦模型更多地依赖于对手的数据。

3.6 主动与被动攻击的对比
使用主动攻击,对不同标签的分类效果更好

4. 防御
FL常见的防御手段:
- 梯度加噪
- 梯度压缩:只分享一部分梯度
- 隐私保护的深度学习:包括三种防御策略:差异隐私、梯度压缩和随机选择
- 离散SGD
4.1 针对主动和被动标签推理防御效果分析
总结:四种方法都不能在抵御攻击的同时保证原有的精度
-
梯度加噪
小范围内的噪声并不能降低标签泄漏的风险。大规模噪声可以成功地减轻标签推理攻击,但代价是显著降低了联邦模型在原始任务上的性能
-
梯度压缩
梯度压缩可以成功地减轻标签推理攻击,但代价是显著降低了联邦模型在原始任务上的性能
-
隐私保护的深度学习
在所有三个数据集上,通过将超参数θu设置为0.25或更低的深度学习,可以减轻标签推理攻击。然而,联邦模型在原始任务上的性能下降也很显著,这与在HFL上报告的结果不同。VFL对从服务器到参与者的共享梯度上的修改更为敏感。这就解释了为什么保护隐私的深度学习可能是HFL的一个很好的防御,但不适合VFL。
-
离散SGD
在三个数据集上,随着超参数N的减小(梯度变得更加离散),攻击性能和联邦模型对原始任务的性能都显著下降,这表明离散sgd不能有效地抵御主动标签推理攻击。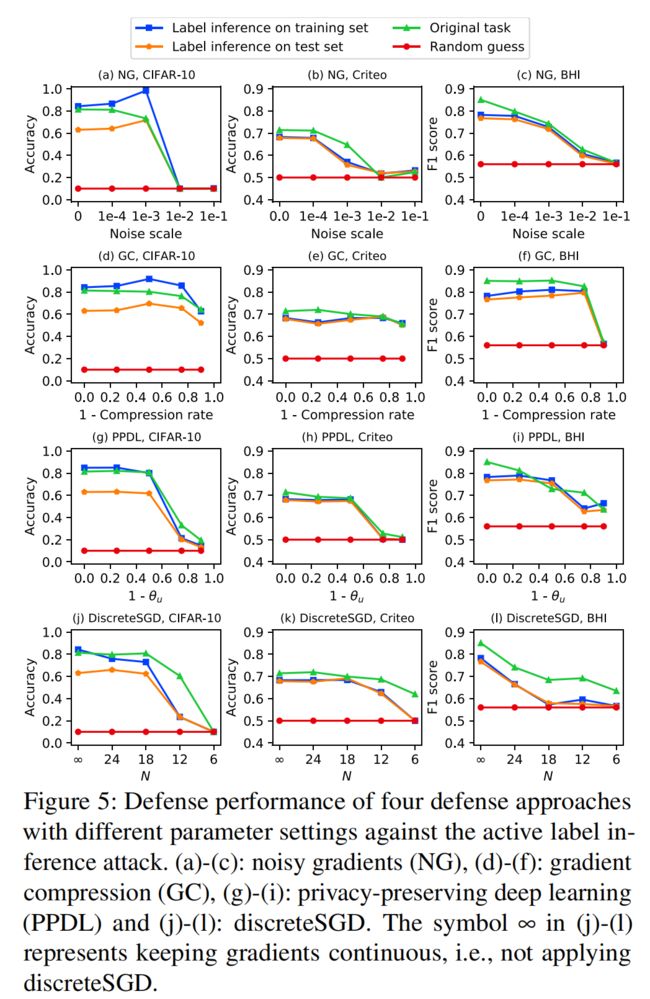
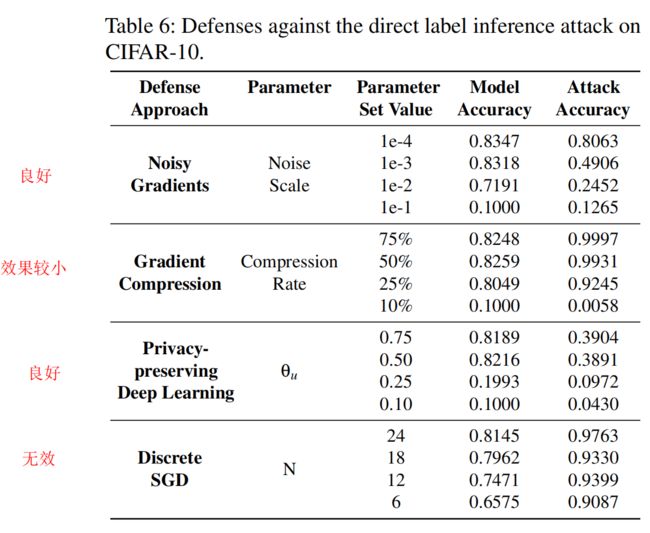
4.2 针对直接标签推理攻击防御效果分析
评估了四种主流的防御方法,实验结果表明,这些防御方法虽然有效地减轻直接标签推理攻击,但对被动标签推理攻击和主动标签推理攻击无效