Python的自然语言处理,情感分析
Python的自然语言处理,情感分析
- 一.Jieba实现词性标注
- 二.基于TextRank算法的关键词提取
- 三.python情感分析库:TextBlob
-
- TextBlob是一个自然语言处理的python库。他为常见的自然语言处理任务提拱了一个简单的API,例如单词标注、名词短语提取、情感分析、分类、翻译等
-
- 中文情感分析
一.Jieba实现词性标注
要实现词性分析,首先要对句子中的词进行分割,jieba的cut()方法可以实现这个功能
安装方法pip install jieba
示例:
import jieba
str="你是一个大sb"
seg_list=jieba.cut(str,cut_all=True)
print('Full Mode:','/'.join(seg_list))
输出结果:
Full Mode: 你/是/一个/大/sb
下面使用Jieba的词性标注库posseg实现词的分割与标注
import jieba
import jieba.analyse
import jieba.posseg
str_new='希望明天没有疫情'
sentence_seged=jieba.posseg.cut(str_new)
outstr=''
for x in sentence_seged:
outstr=outstr+f'{x.word}/{x.flag}'
print(outstr)
希望/v明天/t没有/v疫情/n
常见的一些符号及词性的对应关系如下:
| 词性 | 符号 | 词性 | 符号 | 词性 | 符号 | 词性 | 符号 |
|---|---|---|---|---|---|---|---|
| 形容词 | a(adjective) | 成语 | i(idiom) | 机构团体 | nt | 助词 | u |
| 连词 | c(conjunction) | 数词 | m(numeral) | 其他专有名词 | nz | 动词 | v(verb) |
| 副词 | d(adverb) | 名词 | n(noun) | 介词 | p(preposition) | 名动词 | vn(verb noun) |
| 叹词 | e(interjection) | 人名 | nr | 代词 | r(pronoun)不会是replace吧 | 标点符号 | w(punctuation) |
| 方位词 | f | 地名 | ns | 时间 | t(time) | 未知词语 | un(unknown) |
二.基于TextRank算法的关键词提取
TextRank算法是一种用于文本的基于图的排序算法,通过把文本分割成若干组单元(句子),构建节点连接图,用句子之间的相似度作为边的权重,通过循环迭代计算句子的TextRank值,最后抽取排名高的句子组合成文本摘要>
示例代码如下:
import jieba
import jieba.analyse as ja
# 从水星记里找了一个热门评论
text=':信使号水星探测器,于2004年8月3日发射,2011年3月18日进入水星轨道,是首颗围绕水星运行的探测器,在水星轨道已经运行了4年,目前由于燃料耗尽,于北京时间15年4月30日下午3:26坠落于水星表面,结束自己的生命。'
tags=ja.textrank(text,withWeight=True)
for x,w in tags:
print('%s %s'%(x,w))
输出结果:
水星 1.0 探测器 0.5166625412425594 轨道 0.4538922882513052 耗尽 0.4298220982290774 北京 0.42527734798076083 运行 0.3746428156622363 结束 0.3290651106861785 围绕 0.3024157219332433 表面 0.2970649626092998 燃料 0.29244185681944723 时间 0.29244185681944723 坠落 0.1959439923374903 进入 0.17605880871430668 信使 0.17171768567210033 生命 0.13970514641417064
三.python情感分析库:TextBlob
TextBlob是一个自然语言处理的python库。他为常见的自然语言处理任务提拱了一个简单的API,例如单词标注、名词短语提取、情感分析、分类、翻译等
TextBlob的安装命令如下:(在终端运行)
pip install -U textblob
python -m textblob.download_corpora
另外我们还需要从nltk下载语料库,语法,受过训练的模型等等,下载方法如下:(在编译器下载)
pip install nltk
nltk.download()
示例代码:
import nltk
# nltk.download('punkt')
from textblob import TextBlob
texts=["i am happy",'i am very happy']
for text in texts:
blob=TextBlob(text)
emotion=blob.sentiment
print(emotion)
Sentiment(polarity=0.8, subjectivity=1.0) Sentiment(polarity=1.0, subjectivity=1.0)
情感极性(polarity)为0.8,1,主观性(subjectivity)都为1.情感极性的变化范围为[-1,1],-1代表完全负面(消极),1代表完全正面(积极),subjictivity的范围为[0,1],0表示客观,1表示主观,越接近0则越客观
中文情感分析
使用TextBlob进行中文情感分析,需要安装Snownpl库,安装命令为: pip install snownlp
SnowNLP情感分析也是基于情感词典实现的,其简单的将文本分为两类,积极和消极,返回值为情绪的概率,越接近1为积极,接近0为消极。其原理参考zhiyong_will大神和邓旭东老师的文章,也强烈推荐大家学习。地址:
情感分析——深入snownlp原理和实践
自然语言处理库之snowNLP
这个安装时间有点长,建议使用清华源安装
示例代码:
这里爬了50条玫瑰少年歌曲的评论:好多都是为高彦发生的,必须字词

from snownlp import SnowNLP
text = open('1.txt', mode="r", encoding='utf-8').read()
y = []
s = SnowNLP(text)
sentence = s.sentences
for sentence_1 in s.sentences:
print(sentence_1)
s1 = SnowNLP(sentence_1[0])
score = s1.sentiments
y.append(score)
[0.7150301700493692, 0.483455882352941, 0.5702479338842974, 0.8888888888888888, 0.7150301700493692, 0.782178217821782, 0.7150301700493692, 0.5, 0.5262327818078083, 0.49411764705882355, 0.5262327818078083, 0.5262327818078083, 0.5262327818078083, 0.5262327818078083, 0.5262327818078083, 0.7150301700493692, 0.4285714285714284, 0.5459317585301836, 0.5262327818078083, 0.6582579723940979, 0.8333333333333333, 0.8888888888888888, 0.7150301700493692, 0.625, 0.7150301700493692, 0.5262327818078083, 0.782178217821782, 0.7150301700493692, 0.483455882352941, 0.8888888888888888, 0.6582579723940979, 0.6904761904761904, 0.8333333333333333, 0.764705882352941, 0.6603773584905661, 0.8888888888888888, 0.3693910911319984, 0.8888888888888888, 0.8333333333333333, 0.5662650602409638, 0.5702515177797052, 0.5492584745762712, 0.5, 0.5262327818078083, 0.8888888888888888, 0.5]
这里画了图:
import matplotlib.pyplot as plt
import numpy as np
# 生成数据并绘图
x = np.arange(0, 46, 1)
# 绘制图形,同时修改参数
plt.plot(x, y, marker='*', color='m', markersize=10)
# 设置x轴的刻度
plt.xlim(0, 50)
plt.ylim(0, 1)
# 输出图形
plt.grid()
plt.show()
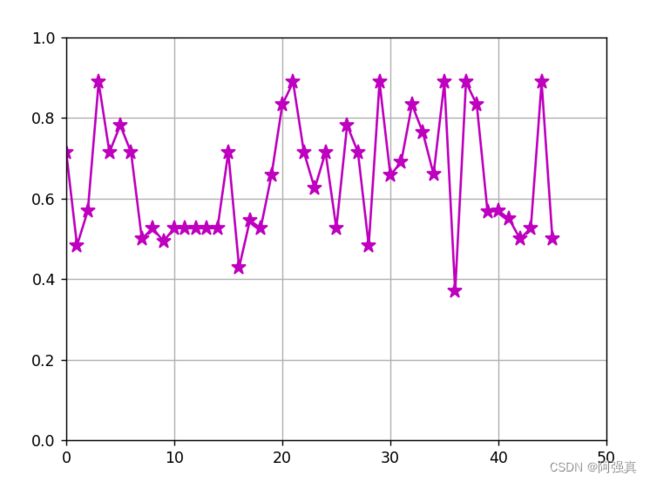
可以看出网友们的态度还有是很积极的
参考文章:[Pyhon疫情大数据分析] 四.微博话题抓取及新冠肺炎疫情文本挖掘和情感分析 - 代码天地 (codetd.com)