scikit-learn(GBDT GradientBoostingClassifier)源码解析
损失函数(目标函数)
【概述】共支持五个类别六个种类的的损失函数,分别是:
'ls': LeastSquaresError
'lad': LeastAbsoluteError
'huber': HuberLossFunction
'quantile': QuantileLossFunction
'deviance': None,如果二分类:BinomialDeviance,多分类:MultinomialDeviance
'exponential': ExponentialLoss,
'''判断损失函数手否支持'''
if (self.loss not in self._SUPPORTED_LOSS
or self.loss not in LOSS_FUNCTIONS):
raise ValueError("Loss '{0:s}' not supported. ".format(self.loss))
'''所支持的loss函数实现'''
LOSS_FUNCTIONS = {'ls': LeastSquaresError,
'lad': LeastAbsoluteError,
'huber': HuberLossFunction,
'quantile': QuantileLossFunction,
'deviance': None, # for both, multinomial and binomial
'exponential': ExponentialLoss,
}
''''''
if self.loss == 'deviance':
loss_class = (MultinomialDeviance
if len(self.classes_) > 2
else BinomialDeviance)
【LeastSquaresError】
pythons实现版本支持传入样本权重,默认情况下按照权重全为1的方式计算。有权重和无权重loss计算方式如下:
【无权重loss计算方式】

【有权重计算方式】:带权最小二乘
![\frac{1}{N}\sum_{i=1}^{N} sample\_weight*[y-f(x)]^{2}](http://img.e-com-net.com/image/info8/6e27b47a9bb2478c85261612951df4ee.gif)
负梯度公式:y-f(x)
class LeastSquaresError(RegressionLossFunction):
"""Loss function for least squares (LS) estimation.
Terminal regions need not to be updated for least squares. """
def init_estimator(self):
return MeanEstimator()
def __call__(self, y, pred, sample_weight=None):
if sample_weight is None:
return np.mean((y - pred.ravel()) ** 2.0)
else:
return (1.0 / sample_weight.sum() *
np.sum(sample_weight * ((y - pred.ravel()) ** 2.0)))
def negative_gradient(self, y, pred, **kargs):
return y - pred.ravel()
def update_terminal_regions(self, tree, X, y, residual, y_pred,
sample_weight, sample_mask,
learning_rate=1.0, k=0):
"""Least squares does not need to update terminal regions.
But it has to update the predictions.
"""
# update predictions
y_pred[:, k] += learning_rate * tree.predict(X).ravel()
def _update_terminal_region(self, tree, terminal_regions, leaf, X, y,
residual, pred, sample_weight):
pass
LeastAbsoluteError(最小绝对值误差)
【loss计算方式】同样支持权重和非权重
【不带权最小绝对值】

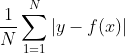
【带权最小绝对值】

【负梯度】
如果误差大于0 取值1 ,如果误差小于0 取值-1
class LeastAbsoluteError(RegressionLossFunction):
"""Loss function for least absolute deviation (LAD) regression. """
def init_estimator(self):
return QuantileEstimator(alpha=0.5)
def __call__(self, y, pred, sample_weight=None):
if sample_weight is None:
return np.abs(y - pred.ravel()).mean()
else:
return (1.0 / sample_weight.sum() *
np.sum(sample_weight * np.abs(y - pred.ravel())))
def negative_gradient(self, y, pred, **kargs):
"""1.0 if y - pred > 0.0 else -1.0"""
pred = pred.ravel()
return 2.0 * (y - pred > 0.0) - 1.0
def _update_terminal_region(self, tree, terminal_regions, leaf, X, y,
residual, pred, sample_weight):
"""LAD updates terminal regions to median estimates. """
terminal_region = np.where(terminal_regions == leaf)[0]
sample_weight = sample_weight.take(terminal_region, axis=0)
diff = y.take(terminal_region, axis=0) - pred.take(terminal_region, axis=0)
tree.value[leaf, 0, 0] = _weighted_percentile(diff, sample_weight, percentile=50)
【HuberLossFunction】
class HuberLossFunction(RegressionLossFunction):
def __init__(self, n_classes, alpha=0.9):
super(HuberLossFunction, self).__init__(n_classes)
self.alpha = alpha
self.gamma = None
def init_estimator(self):
return QuantileEstimator(alpha=0.5)
def __call__(self, y, pred, sample_weight=None):
pred = pred.ravel()
diff = y - pred
gamma = self.gamma
if gamma is None:
if sample_weight is None:
gamma = stats.scoreatpercentile(np.abs(diff), self.alpha * 100)
else:
gamma = _weighted_percentile(np.abs(diff), sample_weight, self.alpha * 100)
gamma_mask = np.abs(diff) <= gamma
if sample_weight is None:
sq_loss = np.sum(0.5 * diff[gamma_mask] ** 2.0)
lin_loss = np.sum(gamma * (np.abs(diff[~gamma_mask]) - gamma / 2.0))
loss = (sq_loss + lin_loss) / y.shape[0]
else:
sq_loss = np.sum(0.5 * sample_weight[gamma_mask] * diff[gamma_mask] ** 2.0)
lin_loss = np.sum(gamma * sample_weight[~gamma_mask] *
(np.abs(diff[~gamma_mask]) - gamma / 2.0))
loss = (sq_loss + lin_loss) / sample_weight.sum()
return loss
def negative_gradient(self, y, pred, sample_weight=None, **kargs):
pred = pred.ravel()
diff = y - pred
if sample_weight is None:
gamma = stats.scoreatpercentile(np.abs(diff), self.alpha * 100)
else:
gamma = _weighted_percentile(np.abs(diff), sample_weight, self.alpha * 100)
gamma_mask = np.abs(diff) <= gamma
residual = np.zeros((y.shape[0],), dtype=np.float64)
residual[gamma_mask] = diff[gamma_mask]
residual[~gamma_mask] = gamma * np.sign(diff[~gamma_mask])
self.gamma = gamma
return residual
def _update_terminal_region(self, tree, terminal_regions, leaf, X, y,
residual, pred, sample_weight):
terminal_region = np.where(terminal_regions == leaf)[0]
sample_weight = sample_weight.take(terminal_region, axis=0)
gamma = self.gamma
diff = (y.take(terminal_region, axis=0)
- pred.take(terminal_region, axis=0))
median = _weighted_percentile(diff, sample_weight, percentile=50)
diff_minus_median = diff - median
tree.value[leaf, 0] = median + np.mean(
np.sign(diff_minus_median) *
np.minimum(np.abs(diff_minus_median), gamma))