第15章Stata时间序列分析
目录
15.1时间序列的基本操作
案例延伸
延伸1:清除数据的时间序列格式
延伸2:关于数据处理的一般说明
延伸3:关于时间序列运算的有关说明
15.2单位根检验
1.ADF检验
2.PP检验
案例延伸
15.3协整检验
1.EF-ADF检验
2.迹检验
案例延伸
1.EG-ADF检验方法构建出的协整模型
2.迹检验方法构建出的协整模型
15.4格兰杰因果关系检验
案例延伸
时间序列分析是种动态数据处理的统计方法。该方法基于随机过程理论和数理统计学方法,研究随机数据序列所遵从的统计规律,以此来解决实际问题。时间序列是随时间而变化、具有动态性和随机性的数字序列。在现实生活中,许多统计资料都是按照时间进行观测记录的,因此时间序列分析在实际分析中具有广泛的应用。
时间序列模型不同于一般的经济计量模型, 其不以经济理论为依据,而是依据变量自身的变化规律,利用外推机制描述时间序列的变化。时间序列模型在处理的过程中必须明确考虑时间序的非平稳性。
15.1时间序列的基本操作
在进行时间序列分析前,我们往往需要对数据进行预处理。首先要分析的是该数据是否适合用时间序列分析,这往往需要我们提前对数据进行简单回归,然后再进行时间序列分析的基本操作,包括定义时间序列、绘制时间序列趋势图等。对于个带有日 期变量的数据文件,Stata并不会自动识别并判定出该数据是否是时间序列数据,尤其是数据含有多个日期变量的情形。所以要选取出恰当的日期变量,然后定义时间序列。而绘制时间序列趋势图的意义先不面物的,通过该步操作我们可以迅速看出数据的变化特征,为后续更加精确地判断或者选择合适的模型做好必要准备。
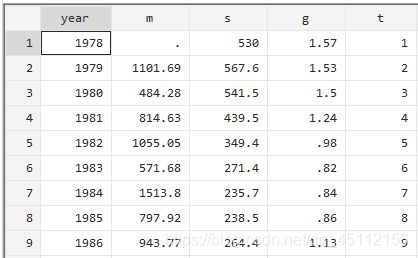
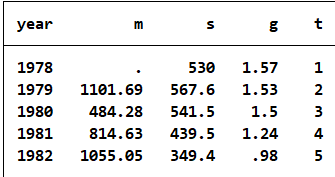
数据(案例15.1)农村家庭联产承包责任制的推行,以及城市化进程的加快,使得我国大批街动力从农村解放出来,向当地乡镇企业和城市转移。农村劳动力的大批转移,有效改善了我明劳动力的整体利用状况,提高了人力资源的市场配置效率,对农村经济乃至整个国民经济的发展都起到了非常大的推动作用。那么影响农村劳动力转移的因素有哪些呢?某课题组对该问题进行了实证研究。该课题组选择的具有代表性的变量和数据如表15.1所示。试将数据整理败Stata数据文件,并进行简要分析。变量分别为年份、城乡人口净转移(万人)、城镇失业规模(万人)、城乡收入差距、制度因素。
regress m s g t #以城乡人口净转移为因变量,不考虑数据时间序列性质,进行简单线性回归
我们可以看出,模型非常显著,但是解释能力就比较差强人意了。各个变量的系数也是非常显著的,模型存在一定的优化空间。基本结论就是城乡人口转移规模(m)随着城乡时机收入差距(g)的扩大而扩大,城镇失业规模 (s)对农村劳动力转移具有阻碍作用 ;制度因素(t)对农村劳动力转移的制约作用逐渐下降。
tsset year #本命令的含义是吧年份作为日期变量对数据进行时间序列定义。twoway(line m year) #绘制时间序列图来描述城乡人口净转移随着时间的变动趋势
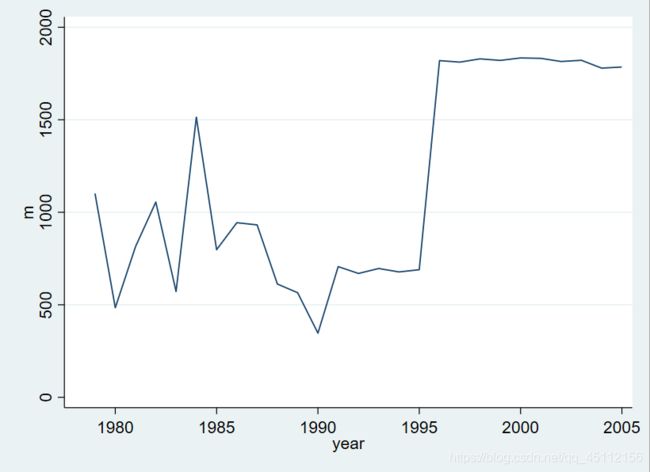
从上图来看变量城乡人口净转移没有明显、稳定的长期变化方向。
twoway(line s year) 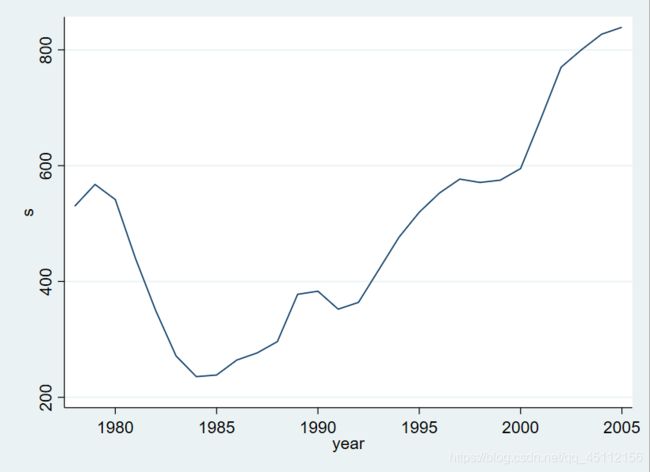 从上图可以 看出变量城镇失业规模 具有明显、稳定的向上增长的趋势。
从上图可以 看出变量城镇失业规模 具有明显、稳定的向上增长的趋势。
twoway(line g year)
twoway(line t year)结果不再过多赘述
twoway(line d.m year) #本命令的含义是绘制时间序列趋势图来描述城乡人口净转移的一阶差分随时间的变动趋势。
twoway(line d.s year)
twoway(line d.g year)
twoway(line d.t year)
从图中可以 看出城乡人口净转移的增量并没有明显、稳定的长期变化方向。其他的不再过多赘述。
案例延伸
延伸1:清除数据的时间序列格式
tsset ,clear延伸2:关于数据处理的一般说明
一般情况下,我们要消除变量的时间序列长期走势后 或者说变量平稳后才能进行回归得到有效结论,所以在绘制变量序列图的时候,如果该变量存在趋势,就应该进行一阶差分后在进行查看。所谓变量的一阶差分指的是对变量的原始数据进行处理,用前面的数据减去后面的数据的出的一个新的时间序列。如果变量的的一阶差分还是存在趋势,那么就应该进行二阶差分进行查看,依次类推,直到数据平稳。所谓的二阶差分指的是在把一阶差分得到的时间序列数据作为原始数据,并进行前项减后项处理后的出新的时间序列。一般情况下买如果数据的低阶差分是平稳的,那么高阶差分也是平稳的。
延伸3:关于时间序列运算的有关说明
在上面的案例中,使用了d.m,d.s等符号来表示m\s的等变量的一阶差分。其实还有很多其简便的运算可以使用。
| stata命令符号 | 时间序列运算含义 |
| L. | 变量滞后一期值 |
| L.2. | 变量滞后二期值 |
| L(1/3). | 变量滞后一期到三期值 |
| F. | 变量向前一期值 |
| F.2 | 变量向前二期值 |
| D. | 变量一阶差分 |
| D2. | 变量二阶差分 |
| S. | 变量季节差分 |
| S2. | 变量的二期季节差分 |
15.2单位根检验
对于一个时间序列数据而言,数据的平稳性对于模型的构建是非常重要的。如果时间序列式不平稳的,可能导致自回归系数的估计值向左偏向于0,使得传统的T检验失效,也有可能会使得两个相互独立的变量出现假相关或者假回归,造成模型的失真。在时间序列数据不平稳的情况下,目前公认的能够有效解决假相关或者假回归,构建出合理模型的方法有两中,一种是先对变量进行差分直到数据平稳,再把得到的数据进行回归的方式:另一种是进行协整检验并构建合理模型的处理方式。那么如何判断数据是否平稳,在商界中提到的绘制时间序列图的方法可以作为初步推测或者辅助检验的一种方式。但一种更精确的检验方式是:如果数据没有单位根我们就认为他是平稳的,这时就需要用到单位根检验。
数据(案例15.1)m(城乡人口净转移)、s(城镇失业规模)、g(城乡收入差距)、t(制度因素)
单位根检验的方式有很多种,此处我们主要介绍两种 方式,包括ADF检验和PP检验,上一节中我们通过绘制时间序列趋势发现城乡人口净转移、城乡人口净转移的一阶差分、城镇失业规模的一阶差分、城乡收入的一阶差分是没有时间趋势的,而城镇失业规模和城乡收入差距是有时间趋势的。
1.ADF检验
dfuller m,notrend #本命令的含义是使用ADF检验,对面两m进行单位根检验,不包含时间趋势
dfuller s,notrend
dfuller g,notrend
dfuller d.m,notrend #本命令是对边两d.m进行单位根检验不包含时间趋势
dfuller d.s,notrend
dfuller d.g,notrend
dfuller d2.s,notrend
ADF检验的原假设是数据有单位根。从上面的结果中可以看出P值(Mackinnon···)为0.4745,接受了有单位根的假设,这一点也可以通过观察Z(t)值得到。实际Z(t)为-1.617,在1%的置信水平(-3.743)、5%的置信水平(-2.997)、10%的置信水平(-2.629)都无法拒绝原假设,所以城乡人口净转移这一变量数据是存在单位根的,需要对其做一阶差分后再继续进行检验。其他命令的结果解读类似这里不再过多赘述
2.PP检验
pperron m,notrend #使用PP检验对变量m进行单位根检验,不包含时间趋势
pperron s,notrend
pperron g,notrend
pperron d.m,notrend
pperron d.s,notrend
pperron d.g,notrend
pperron d2.s,notrend
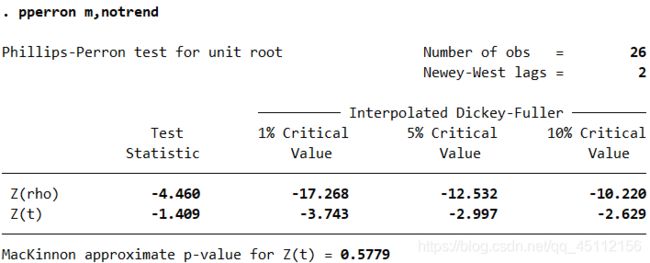
PP检验的原假设是数据有单位根的。从上面的结果也可以看出P值=0.5779,接受了有单位根的原假设,这一点也可以通过观察Z(t)和Z(rho)值得到。实际上Z(t)值为-1.409,在1%的置信水平(-3.743)、5%的置信水平(-2.997)、10%的置信水平(-2.629)都无法拒绝原假设。实际Z(rho)值为-4.460 ,在1%的置信水平(-17.268)、在5%的置信水平(-12.532)、在10%的置信水平(-10.220)都无法拒绝原假设,所以城乡人口净转移这一变量是存在单位根的,需要对其做一阶差分后再继续进行检验。其他解读类似不再过多赘述。
本例中ADF检验和PP检验结果是完全一致的,所以,通过比较可以有把握地认为城乡人口净转移、城乡收入差距两个变量一阶单整的,而城镇失业国模是二阶单整的。
案例延伸
按照前面讲述的解决方法,可以对变量进行相应阶数的差分,然后进行回归,即可避免出现伪回归的情况。
构建如下所示的模型方程:
d.m = a*d.g+b*d2.s+c*t+u
其中a b c 为系数,u为误差扰动项
regress d.m d2.s d.g t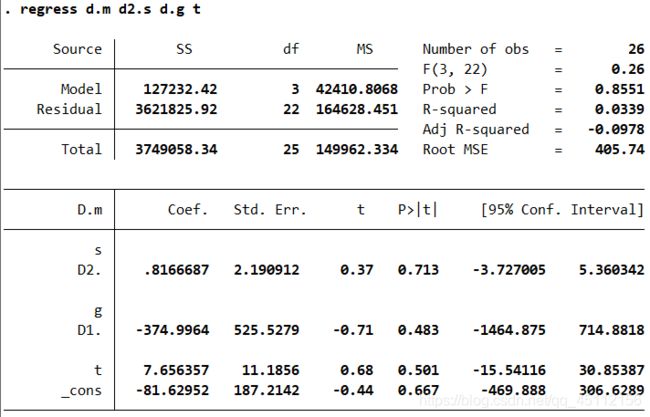
从上述分析结果中可以看到,结果与本章开始在数据无处理状态下进行的“伪回归”的结果是不同的。可以看出共有26个样本参与了分析,这是因为进行差分会减少观测样本。模型的F值(3.22)=0.26,P值(Prob>F) =0.8551, 说明模型整体上是不显著的,本章开始得出的结果其实是一种真真正正的“伪回归”。模型的可决系数(R-squared)为0.0339, 模型修正的可决系数(Adj R-squared)为-0.0978, 说明模型几乎没有什么解释能力。
模型的回归方程是:
dm-0.8166687* d2.s-374.9964*dl.g+7.656357*t+-81.62952
变量d2.s的系数标准误是2.190912, t值为0.37, P值为0.713,系数是非常不显著的,95%的置信区间为[-3.727005,5.360342]。变量dl.g的系数标准误是525.5279, t值为-0.71, P值为0.483,系数也是非常显著的,95%的置信区间为[-1464.875, 714.8818]。变量t的系数标准误是11.1856, t值为0.68,P值为0.501, 系数也是非常显著的,95%的置信区间为[-15.54116 ,30.85387]。常数项的系数标准误是187.2142, t值为-0.44, P值为0.667,系数也是非常显著的,95%的置信区间为[-469.888, 306.6289]。
从上面的分析可以看出,本模型得到的基本结论是城乡人口转移规模(m)随着城乡实际收入差距(g)的扩大而扩大;城镇失业规模(s)对农村劳动力转移具有阻碍作用:制度因素(t)对农村劳动力转移的制约作用逐渐下降,这一点与伪回归得出的结果是一致的。
15.3协整检验
上一节中,我们提到对于一个时间序列数据而言,数据的平稳性对于模型的构建是非常重要的。在时间序列不平稳的状况下,构建出合力模型的另外一种方法就是进行协整检验并构建合理模型。协整的思想就是把存在一阶单整的变量放在一起进行分析,通过这些变量进行线性组合,从而消除他们的随机趋势,得到其长期联动趋势。
本节沿用上节的案例,试通过EG-ADF检验、迹检验等两种协整检验的方式来判断相关变量包括城市人口净转移、城镇失业规模、城乡收入差距比等变量是否存在长期协整关系。
在前面两节中,通过绘制时间序列趋势图发现城乡人口净转移、城乡人口净转移的一阶差分、城镇失业规模的一阶差分、城乡收入差距的一阶差分是没有时间趋势的,而城镇失业国模和城乡收入差距是有时间趋势的。通过单位根检验发现城乡人口净转移、城乡收入差距两个变量是一阶单整的,而城镇失业 规模变量是二阶单整的。这些结论将会在后续的操作命令中被用到。
1.EF-ADF检验
EF-ADF检验过程是:首先把城乡人口净转移作为因变量,把城镇失业规模的一阶差分、城乡收入差距作为自变量,用普通最小二乘估计发进行估计得到残差序列,然后对残差序列进行ADF检验,观测其是否为平稳序列,如果残差序列事平稳的,那么变量之间的长期协整关系就存在,如果残差是不平稳的那么,变脸之间的长期协整关系就不存在。
regress m d.s g #对变量进行最小二乘回归分析
predict e , resid #得到上一步回归的残差
twoway(line e year) #绘制残差序列的时间趋势
dfuller e, notrend nocon lags(1) regress #对残差序列进行ADF检验,观测其是否为平稳序列,其中不包括时间趋势,不包括常数项、滞后1期
上图是ADF检验结果。ADF原假设是数据有单位根,从图中我们可以看出Z(t)的实际值是-2.273在置信度1%(-2.660)和5%(-1.950) 之间,所以应该拒绝原假设,因此残差序列是不存在单位根的,或者说残差序列是平稳的。
综上所述,城乡人口净转移、城镇失业规模、城乡收入三个变量值存在协整关系,根据上面分析结果可以构建出相应的模型来描述这种协整关系。关于这一点我们将在案例部分进行详细说明。
2.迹检验
迹检验的过程是:首先要根据信息准测确定变量的滞后阶数,即模型中变量的个数。信息准测的概念是针对变量的个数,学者们认为只有适当变量的个数才是合理的,如果变量太少,就会遗漏很多信息,导致模型不足以解释因变量,如果变量太多,就会导致信息重叠,同样导致建模失真。目前国际上工人的比较合理的信息准测有很多种,所以研究者在选取滞后阶数时要适当加入自己的判断。在确定滞后阶数后,我们要确定协整秩,协整秩代表着协整关系个数。变量之间往往会存在多个长期均衡关系,所以协整秩并不必然等于1。在确定协整秩后,我们就可以构建相应的模型,并写出协整方程了。
varsoc m d.s g #本命令旨在根据信息准则确定变量的滞后阶数
上图给出了根据信息准测确定变量滞后阶数分析结果。最左列的lag表示滞后阶数,LL、LR表示的是统计量,df表示的是自由度,P值表示的是对应滞后阶数下模型的显著性,FPE、AIC、HQIC、SBIC代表的是四种信息准测,其中值越小越好,月应该选用这一点也可以通过观察“*”来验证,带“*”号说明在本信息准则下的最优滞后阶数。最下面两行文字说明的是模型中的外生变量和内生变量,本例中外生变量包括m、D.s、g,内生变量包括—常数项。
综上所述,可以看出选取滞后阶数为1或者4是比较合适的。但是为了模型中的变量更多一些,更有说服力,我们选择滞后阶数为4.
vecrank m d.s g,lags(4) #本命令旨在确定协秩
vec m d.s g,lags(4) rank(1) #本命令旨在估计协整模型 上图展示的是根据前面确定的滞后阶数确定协整秩的结果。分析本结果的最直接的方式就是找到带有“*”号的迹统计量,本例中最优值为14.5747,对应的协整秩为1,说明本例中城乡人口净转移、城镇失业规模、城乡收入差距三个变量存在一个协整关系。
上图展示的是根据前面确定的滞后阶数确定协整秩的结果。分析本结果的最直接的方式就是找到带有“*”号的迹统计量,本例中最优值为14.5747,对应的协整秩为1,说明本例中城乡人口净转移、城镇失业规模、城乡收入差距三个变量存在一个协整关系。
至此协整检验完毕,我们可以发现两种检验方法得到的结论是一直的,对于迹检验而言,同样可以构建出相应的模型来描述这种长期协整关系。这一点也放到本书案例延伸部分。
案例延伸
按照前面的方法,可以对变量进行相应的阶数的差分,然后进行回归,即可避免出现伪回归的情况。
1.EG-ADF检验方法构建出的协整模型
假定m为因变量(真实情况需要进行格兰杰因果关系检验,将在下节说明),则构建如下所示的方程模型:
d.m=a*d.g+b*d2.s+c*ecm(t-1)+u
其中,a、b、c为系数,ecm为误差修正项,u为误差扰动项。
ecm误差修正项的模型方程为:
m=a*g+b*d.s+ecm(t-1)
a、b为系数。实质上,ecm是该模型方程的误差扰动项,或者说以m为因变量,以g、d.s为自变量进行最小二乘回归估计后的残差。
在上面EF-ADF检验部分,得到ecm模型方程为:
m=-1.229304*d1.s+793.4284*g-14.01591
该该方程反应的是变量长期均衡关系
regress d.m d2.s d.g l.e2.迹检验方法构建出的协整模型
从上面的分析可以看出,变量间短期关系是非常不显著的,几乎没什么关系。但是变量的长期均衡关系却很显著。下面利用另一种更加精确的迹检验方法构建出的协整模型来详细研究变量间的这种长期均衡关系。
vec m d.s g ,lag(4) rank(1)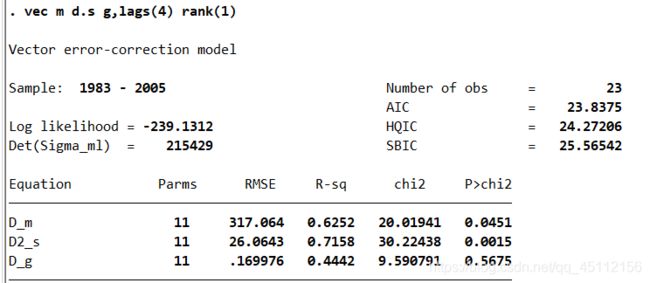
上图说明的是分别把城乡人口净转移的一阶差分、城镇失业规模的二阶差分、城乡收入差距的一阶差分作为因变量时的模型方程总数。通过观察上图可以知道城乡人口净转移、城镇失业规模、城乡收入差距3个变量张子健的协整关系可以通过3个方程来说明。此次值得强调的时,协整关系表示的仅仅是变量之间的某种长期联动关系,跟因果毫无关联。如果要探究变量之间的因果关系,换言之,就是确定让谁来做因变量的问题,就需要用到格兰杰因果关系检验。
本例中(实质上所有的协整关系都是一样的),3个方程的样本情况(sample:193-2005 obs = 25)、信息准则情况(AIC、HQIC、SBIC)等都是相同的。当爸城乡人口的一阶差分作为因变量时,模型的可决系数时0.6252,卡方值时20.01941.后面的解读类似。

上图展示的时城乡人口净转移变量的一阶差分作为因便是的方程模型具体情况,这个分析时与回归分析时一样的,不再过多赘述。
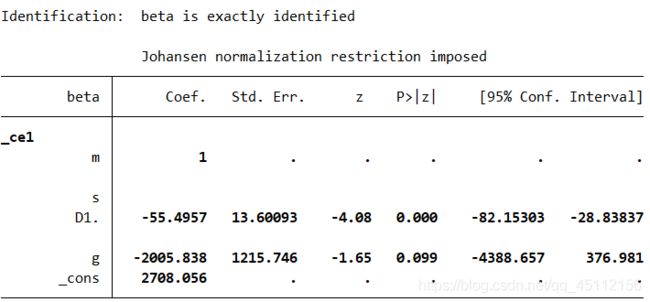 上图可以看出协整方程的具体模型:
上图可以看出协整方程的具体模型:
m-55.4957*d1.s-2005.838*g+2708.056=0
如果把m作为因变量,对上面的等式进行变形,结果就是:
m= -2708.056+55.4957d1.s+2005.838g
可以发现m与s、g都是正向变动关系。着表示含义是从长期来看,城乡人口净转移、城镇失业规模、城乡收入差距3个变量都是正向联动的。这个结论与对变量进行相应阶数差分后进行回归分析得到的结论不同,这个结论说明从长期来看,城镇失业规模和城镇人口净转移是正向变动的。这也是可以理解的,因为城乡人口净转移越多,城镇失业规模就可能越大,而城镇失业规模越大,很可能意味着城镇创造就业机会越多,从而导致城乡人口净转移越大。
15.4格兰杰因果关系检验
协整关系表示的仅仅是变量之间的某种长期联动关系,跟因果关系是毫不相关的,如果想要探究变量之间的因果关系,就需要用到格兰杰因果关系检验。格兰杰因果关系检验的基本思想是如果变量A是变量B的因,同时变量B不是变量A的因,那么A变量的滞后值就可以帮助B变量预测未来值,同时B变量的滞后值却不能帮助预测变量A的未来值。这种思想反映到操作层面就是如果A变量是B变量的因,那么以A变量为因变量、以A变量的滞后值以及B变量的滞后值作为自变量进行最小二乘回归,则B变量的滞后值的系数显著。另外需要强调3点:一是格兰杰因果关系检验并非真正意义的因果关系,表明的仅仅是数据上的一种动态相关关系,如果要准确界定变量的因果关系,需要相应的实践经验作为支撑,而是格兰杰因果关系检验的各个变量要求是同阶单整的,三是存在协整关系的变量间至少有一种格兰杰因果关系。
regress m l.m dl.s #本命令旨在以m为因变量,以l.m dl.s 为自变量,进行最小二乘回归分析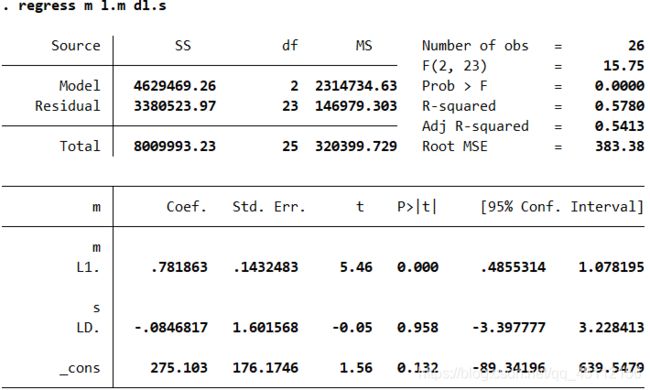 我们可以看到,dl.s的系数是非常不显著的,这点我们可以从上下图的系数显著性看出。其他的分析不再过多赘述。所以我们可以比较有把握的得出结论,城镇失业规模不是城乡人口净转移的格兰杰因。
我们可以看到,dl.s的系数是非常不显著的,这点我们可以从上下图的系数显著性看出。其他的分析不再过多赘述。所以我们可以比较有把握的得出结论,城镇失业规模不是城乡人口净转移的格兰杰因。
test dl.s=0 #本命令旨在检验变量系数的显著性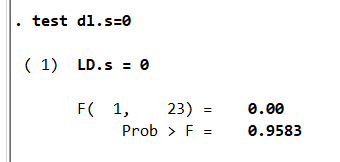
regress d.s dl.s l.m
test l.m = 0
regress m l.m l.g
test l.g=0regress g l.g l.m
test l.m=0regress g l.g dl.s
test dl.s=0regress d.s dl.s l.g
test l.g=0上述代码解读类似这里不再过多赘述,自行分析格兰杰因果,这代码完全是按照基础概念来写的。上述代码观察完之后我们可以发现只有城镇失业规模是城乡收入差距的格兰杰因,其他变量之间均不存在格兰杰因果关系。当然,正如前面讲到的,格兰杰因果关系并不是真正的因果关系,变量是指的因果关系依靠有关理论或者实践经验的判断。格兰杰因果关系反应的仅仅是一种预测的效果,起到一种辅助作用,所以本例的格兰杰因果检验虽然没有得到预想的结果,但并不意味着模型的失败。
案例延伸
在前面的格兰杰因果关系检验过程中,我们使用的被假设为格兰杰的自变量的滞后期均为1期,其实我们可以多试几期。例如,在检验城乡收入差距是否是城镇失业规模的格兰杰因的时候可以把滞后期拓展为5期。
regress d.s dl.s l.g l2.g l3.g l4.g l5.g
test l.g=0
test l2.g=0
test l3.g=0
test l4.g=0
test l5.g=0