汉字风格迁移篇---W-net:基于深度神经网络的一次任意风格汉字生成
文章目录
- 一、摘要
- 二、提出原因
-
- 已有的一些模型解决方案
-
- 依然存在的限制
- 三、介绍与创新
- 四、模型介绍
-
- 预处理
- w-net结构
- 优化策略和损失函数
- 五、实验
-
- 实验设置
-
- 用zi2zi作为基线
- 具体实现
-
- 1、 W-Net训练期间的超参数设置如下:
- 2、一些细节处理
- 模型评估
-
-
-
- W-net、zi2zi-v1、zi2zi-v2不足与区别
-
-
- 失败案例分析
- 结论与未来工作
-
- 结论
- 未来工作
- 学习集合
- References
一、摘要
由于类别数量巨大,各种笔画和部首的复杂组合,以及自由书写或印刷风格,生成具有多种风格的汉字一直被认为是一项艰巨的任务。
本文介绍了一种有效的、广义的深度框架,即W-Net,用于一次性任意风格汉字生成任务。
具体地,给定具有特定样式(例如,打印字体或手写样式)的单个字符(一次拍摄),所提出的W-Net模型能够学习和生成共享与给定单个字符类似的样式的任意字符。 这种吸引人的财产在文献中很少见到。我们已经将所提出的W-Net框架与许多其他竞争方法进行了比较。实验结果表明,所提出的方法在单次拍摄设置中具有显著的优越性。
二、提出原因
汉语包含数千个不同的类别或10000多个不同的字符,其中3755个字符被定义为一级字符。给定有限数量的汉字或甚至一个具有特定风格的单个字符(例如,个性化手写书法或风格印刷字体),自动模仿具有相同特定风格的许多其他字符是很有趣的。
1、这一主题非常困难,很少研究,因为不同风格的不同汉字的类别数量很大。
2、由于汉字的独特性,这个问题更为棘手,其中每一个汉字都是各种笔画和部首的组合,具有不同的交互结构。
已有的一些模型解决方案
尽管存在这些挑战,但最近有一些与上述发电任务相关的建议。
1、在[13]中,笔画由时间序列表示,书写均匀的粗轨迹。然后将其发送到基于递归神经网络的生成器。
2、在[6]中,基于附加网络实现了用于标准化字符提取的字体特征重构,以辅助一对一图像到图像的翻译框架。在此框架中需要700多张预先选定的训练图像。
3、在Zi2Zi[12]模型中,通过基于固定高斯噪声的分类嵌入(每个样式有超过2000个训练示例),仅用单个模型实现了一对多映射。
依然存在的限制
上述方法存在几个主要限制。
1、这些方法的性能通常严重依赖于具有特定样式的大量样本。在几次或甚至一次生成的情况下,这些方法将无法奏效。
2、这些方法可能无法转变为训练中从未见过的新风格。因此,这些缺点可能导致它们无法实际使用。
三、介绍与创新
1、在本文中,为了在给定具有特定任意风格(在训练中可见或不可见)的单镜头样本时(用一个字生成一堆汉字)生成汉字,我们提出了一种新的深度模型W-Net作为广义风格转换框架。
2、该框架更好地解决了上述缺点,并且可以容易地在实践中使用。
3、特别地,对于一对一图像到图像翻译任务[4],从U-Net框架[9]中固有的,所提出的W-Net使用两个并行的基于卷积的编码器来分别提取样式和内容信息。
4、生成的图像将由基于去卷积的解码器通过使用编码信息来获得。
5、设置捷径连接[9]和多个残差块[2]以处理梯度消失问题,并平衡从两个编码器到解码器的信息。
6、W-Net的培训遵循对抗性的方式。
7、受最近提出的具有梯度惩罚的Wasserstein生成对抗网络(W-GAN)框架[1]的启发,采用了独立的鉴别器1(D)来辅助W-Net(G)学习。
8、作为方法指南,本文仅演示了单镜头任意风格汉字生成,如图1所示。然而,W-Net框架可以扩展到单镜头任意样式图像生成的各种相关主题。
有了这样的建议,与文献中先前的方法相比,可以更容易和有效地完成具有较少样本的数据合成任务。

图1:通过提出的W-Net模型生成的传统字符,其中有一个样本可用(右下角的字符带有红色框)。
四、模型介绍
预处理
表示X是一个汉字数据集,由J个不同的字符组成,总共有I种不同的字体。设xij是X中的一个特定样本,被视为真正的目标。在[3,5]之后,上标i∈ [0,1,2,…,I]表示第I个样式,而下标j∈ [1,2,…,J]表示第J个示例。
具体而言,在训练期间,当i=0时,x0j表示具有标准化样式信息的第j个角色的图像,称为原型内容。同时,xik,k∈ [1,2,…,J]被定义为配备有与xij相同的第i个样式信息的样式参考。请注意,j和k通常不同。在所提出的模型中,假设每个xij与来自原型x0j和从xik学习的第i种写作风格的信息相结合。然后,所提出的W-Net模型将生成生成的目标G(x0j,xik),该目标G通过同时获取x0j和xik而与xij相似。
请注意,生成生成的目标只需要单个样式字符。它被定义为“单镜头任意样式字符生成”任务。具体地说,给定的单个样本(例如,xmp,其中m可以是任意样式,而p可以是任意单个字符。m和p可以分别与[1,2,…,I]和[1,2、…,J]无关)被视为一次性样式参考。在Encr的相关输出(如第2.2节所示,将通过快捷连接或剩余块连接连接到Dec)的条件下,通过提供所需第q个字符的任何内容原型(x0q)来生成G(x0q,xmp),即可轻松完成该任务。在这种设置中,交替q将导致合成不同的字符。同时,所有生成的示例都应该模仿xmp给出的第m个样式信息。同样,q也可以不在[1,2,…,J]中。
w-net结构
图2说明了所提出的W-Net模型的基本结构。它由内容原型编码器(Encp,蓝色部分)、样式参考编码器(Encr,绿色部分)和解码器(Dec,红色部分)组成。
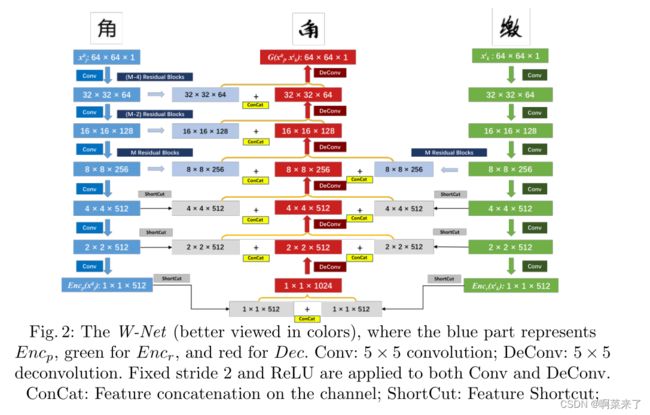
图2:W-Net(更好地用颜色查看),其中蓝色部分表示Encp,绿色表示Encr,红色表示 解码器 Conv: 5 × 5 卷积;DeConv:5×5反褶积。固定步幅2和ReLU应用于Conv和DeConv。ConCat:通道上的特征连接;ShortCut: Feature Shortcut;
1 、Encp和Encr被构造为卷积层序列,其中实现了具有固定步长2和ReLU函数的5×5滤波器。通过此设置,64×64原型图像x0j和参考图像xkj将被映射到1×512特征向量中,分别表示为Encp(x0j)和Encr(xkj)。
2、与U-Net框架[9]中的解码器相同,解码器dec被设计为与Encp和Encr明智连接的反进化进程层。它产生一个生成的图像,其大小与两个编码器的所有输入图像一致。具体而言,对于解码器和两个编码器之间的高级特征,通过简单的特征快捷方式实现连接。对于Encp的较低层,应用一系列残余块2[2]并将其连接到Dec。块的数量由超级参数M控制。
3、相反,由于写作风格是一种高级深度特征,Encr和Dec之间只有一个剩余的块连接(具有M个块),同时省略了低级特征连接。
优化策略和损失函数
所提出的W-Net基于被视为生成器G的Wasserstein生成对抗网络(W-GAN)框架进行对抗性训练。
1、具体而言,它采用内容原型和样式参考,然后将生成的目标返回为接近xij的G(x0j,xik)=Dec(Encp(x0j),Encr(xik))。G通过利用对抗网络D以及如下定义的若干优化损失来优化。
2、训练策略:W-Net的学习遵循对抗性训练策略。在每个学习迭代中,有两个独立的过程,分别包括G训练和D训练。训练G和D以分别优化方程(1)和方程(2)。
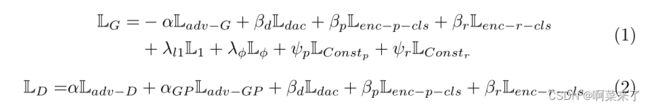
3、 对抗性损失: G优化Ladv−G=D(x0j,G(x0j、xik),xik)而D最小化Ladv−D=D(x0j,xij,xik)− D(x0j,G(x0j、xik),xik)。请注意,梯度惩罚设置为Ladv−糖蛋白=||∇bxD(x0j,bx,xik)− 1||2[1],其中bx沿xij和G(x0j,xik)之间的线均匀插值。
4、鉴别器辅助分类器的类别丢失:
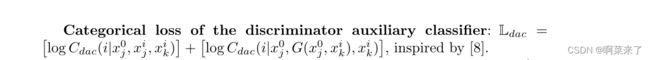
5、重建损失包括像素级差和高级特征变化 φ(.)表示特定的深度特征。这里使用了用多种字符样式训练的VGG-16网络[10]。在该优化中,共有五个卷积特征,包括φ1−2, φ2−2, φ3−3, φ4−3, φ5−涉及3个。

6、编码器的恒定损耗:两个编码器也采用恒定损耗[11]。它们由LConsp=||Encp(x0j)−Encp(G(x0j,xik))||2 和 LConstr=||Encr(xik)− Encr(G(x0j,xik))||2。分别用于Encp和Encr
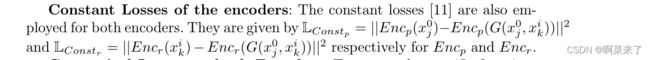
7、两个编码器上的类别损失:为了确保两个编码器的特定功能,我们强制它们提取的内容和样式特征分别配备相同类型的相应通用性。通过添加完全连接来实现类别分类任务,这导致两个编码器都学习自己的代表性特征,同时避免了过度拟合。θp和θr分别用于表示编码器的两个输出特征向量的完全连接和softmax函数,而分类记为Cencp和Cencr。上述两种分类的交叉熵损失以Lenc−p−cls=[ log Cencp(j |θp(Encp(x0j))]和Lenc−p−cls=[ log Cencr(i|θr(Encr(xik))] 分别地请注意,i和j表示特定的样式和字符标签。

五、实验
一系列实验来验证所提出的W-Net网络的有效性。对打印字体和手写字体进行评估。还参考了几个相关的基线进行比较。
实验设置
数据集来源: 标准中文印刷字体数据库中专门选择了80种字体。其中50个,每个包含3755个一级简体中文字符,参与了训练集。
CASIA-HWDB-1.1(用于简化的孤立字符)和CASIA-HHDB-2.1(用于简体草书字符)[7]的脱机版本都是手写数据集。选择50位作家(编号1101至1150)书写的字符作为训练集,共产生249066个样本(平均每个作家4980个样本)。
对于这两组,测试数据的选择是出于不同的评估目的。HeiTi(黑体字体)被用作两组字体的原型字体,如图3(a)所示。

图3:生成的不可见打印和手写样式数据的几个示例。
(a) 。输入内容原型;
(b) -(e):第一行:生成的字符;第二行:对应的样式参考(基本真实字符)。
基线模型包括Zi2Zi[12]框架的两个升级版本,该框架经过了修改,用于少数镜头的新样式合成任务。
用zi2zi作为基线
Zi2Zi[12]框架的两个升级版本:
1、利用微调策略(记为Zi2Zi-V1),其中风格信息被假设为由基于固定高斯噪声的分类嵌入表示的多个已知风格的线性组合;
2、(Zi2Zi-V2)通过引入6个作者的最终softmax输出来丢弃分类嵌入,该输出是由于过度长度而被抑制的预训练VGG-16网络(嵌入器网络),与第2.3节中使用的网络相同。这些基线的所有其他网络架构和训练设置都是相同的[12]。
来自两个数据库的字符由64×64灰度图像表示,然后进行二值化。
需要特别注意的一点是,所提出的W-Net和Zi2Zi-V2都遵循一次性设置,在评估过程中仅引用单个样式示例(xmp)。
然而,Zi2Zi-V1采用了最少的(32个参考)方案,以获得有效的微调性能。
具体实现
1、 W-Net训练期间的超参数设置如下:
残差块数为M=5;相关惩罚为:α=3,αGP=10,βd=1,βp=βr=0.2,λl1=50,λφ=75,ψp=3,ψr=5。
2、一些细节处理
2.1 实现了具有β1=0.5和β2=0.999的Adam优化器,而初始学习率被设置为0.0005,并且在每个训练周期之后呈指数衰减。
2.2 D(鉴别器)的架构遵循Zi2Zi框架[12]与W-GAN框架的设置。
2.3 为了加快和稳定训练进度,将批处理归一化应用于G网络的多个层,而将层归一化应用于D。
2.4 还将丢弃技巧应用于G和D,以提高泛化性能。重量衰减也用于避免过度拟合问题。
2.5 拟议的W-Net框架和其他基线是用Tensorflow(r1.5)实现的。
模型评估
通过在本节中为内容x0q和样式xmp设置p=q来验证W-Net模型。
因此,引用正好是实际目标(xmp=xmq)。对于每个求值,如前所述,只使用单个样式引用(xmp,图3(b)-(e)中第二行的字符)。
如果所提出的W-Net能够重建参考图像xmp中所提取的风格信息,则所生成的图像被视为遵循单镜头参考的风格趋势。
图3举例说明了训练期间合成不可见风格的比较结果。
可以观察到,通过保持风格一致性,W-Net模型以适当的性能学习并将打印和手写类型的风格转移到原型。

图4:所见样式的生成字符的几个示例。
(a) ,(c)和(e)是打印字体;
(b) 、(d)和(f)是手写体。
在每个图中,第一行:地面真实字符(带蓝色框)和单镜头样式参考(带红色框);
第二:W-Net生成的字符;第三排:Zi2Zi-V1性能;第四排:Zi2Zi-V2性能。
W-Net的有效性通过生成具有替代样式的常用汉字(简体和繁体)来测试。
在此设置中,xmp是随机选择的具有第m个样式信息的单镜头角色,以模拟真实的应用场景,而q是指要生成的所需内容原型。通常,p 6=q。
图4和图5分别列出了WNet生成的图像的几个示例,以及训练期间可见和不可见风格的两个基线。
特别是,在培训过程中,只有简化的汉字可以使用,如这两幅插图中每个子图的左四列所示。在其他剩余栏目中,这些传统图像的两个相关数据库中都没有地面真相数据。

图5:生成的几种不可见样式的字符示例。
(a) ,(c)和(e)是打印字体;
(b) 、(d)和(f)是手写体。在每个图中,第一行:地面真实字符(带蓝色框)和单镜头样式参考(带红色框);第二:W-Net生成的字符;第三排:Zi2Zi-V1性能;第四排:Zi2Zi-V2性能。
当在训练期间生成具有特定可见样式的字符时,从图4中可以直观地观察到,即使给定单镜头样式参考,W-Net生成的字体看起来与相应的真实目标非常相似。
W-net、zi2zi-v1、zi2zi-v2不足与区别
不同的是,在少数镜头设置下,Zi2Zi-V1仍然会产生模糊的图像,而Zi2Zi-V2似乎会合成具有平均风格的人物。
所提出的W-Net通过产生具有所需内容和一致风格的角色而优于其他人,只有一个镜头风格参考可用。
同时,当使用一次性样式参考构建不可见样式时,通过所提出的方案仍然可以从图5中获得可接受的世代。虽然生成的样本与前面的示例中的样本不够相似,但仍然可以清楚地观察到明显的风格倾向。相比之下,Zi2Zi-V1未能生成高质量的图像,因为过度拟合问题,即使为微调提供了32个参考。同时,Zi2Zi-V2无法生成可区分的样式,因为它只能从嵌入器网络(VGG-16)提供的原始基础学习样式。
失败案例分析
1、当所提出的模型离原型字体太远时,它有时无法捕获样式信息。
例如,由于输入内容都是孤立的字符,一些草书书写可能在生成过程中起到负面作用。图6中给出了一些失败生成的字符,其中第二行列出了相应的一次性样式引用。
在提出的W-Net中,每个目标都被视为从参考到原型的非线性风格转换。
2、然而,当样式与内容字体差异太大时,模型无法学习这种复杂的映射关系。 在这种极端情况下,本文中提供的单一原型字体可能是不合适的选择。在这种情况下,学习其他映射可能是一个好主意,这些映射可以将原始原型转换为合适的潜在特征,以便更好地处理真实场景中的自由写作风格。

图6:不满意的生成示例。在每个图中:第一行:生成的字符;第二行:对应的样式参考(基本真实字符)
结论与未来工作
结论
1、介绍了一种新的通用框架W-Net,以实现一次任意风格汉字生成任务。
2、具体而言,所提出的模型由两个编码器和一个解码器组成,具有多个分层连接,基于W-GAN方案进行对抗性训练。
3、它能够通过将学习到的风格信息从单个引用传输到输入内容原型来合成任意的风格特征。
4、大量的实验证明了所提出的W-Net模型在一次拍摄设置中的合理性和有效性。
未来工作
未来将研究对图像重建更合适的映射架构的扩展,以捕捉足够复杂和自由的写作风格。同时,实际应用不仅局限于字符生成领域,而且还局限于其他相关的任意风格图像生成任务。
学习集合

References
- Gulrajani, I., Ahmed, F., Arjovsky, M., Dumoulin, V., Courville, A.C.: Improved
training of wasserstein gans pp. 5769–5779 (2017) - He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks.
In: European Conference on Computer Vision. pp. 630–645. Springer (2016) - Huang, K., Jiang, H., Zhang, X.Y.: Field support vector machines. IEEE Transac-
tions on Emerging Topics in Computational Intelligence 1(6), 454–463 (2017) - Isola, P., Zhu, J.Y., Zhou, T., Efros, A.A.: Image-to-image translation with condi-
tional adversarial networks. arXiv preprint (2017) - Jiang, H., Huang, K., Zhang, R.: Field support vector regression. In: International
Conference on Neural Information Processing. pp. 699–708. Springer (2017) - Jiang, Y., Lian, Z., Tang, Y., Xiao, J.: Dcfont: an end-to-end deep chinese font
generation system. In: SIGGRAPH Asia 2017 Technical Briefs. p. 22. ACM (2017) - Liu, C.L., Yin, F., Wang, D.H., Wang, Q.F.: Casia online and offline chinese hand-
writing databases pp. 37–41 (2011) - Odena, A., Olah, C., Shlens, J.: Conditional image synthesis with auxiliary classifier
gans. arXiv preprint arXiv:1610.09585 (2016) - Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedi-
cal image segmentation. In: International Conference on Medical image computing
and computer-assisted intervention. pp. 234–241. Springer (2015) - Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale
image recognition. arXiv preprint arXiv:1409.1556 (2014) - Taigman, Y., Polyak, A., Wolf, L.: Unsupervised cross-domain image generation.
arXiv preprint arXiv:1611.02200 (2016) - Tian, Y.: zi2zi: Master chinese calligraphy with conditional adversarial networks.
https://github.com/kaonashi-tyc/zi2zi/ (2017) - Zhang, X.Y., Yin, F., Zhang, Y.M., Liu, C.L., Bengio, Y.: Drawing and recognizing
chinese characters with recurrent neural network. IEEE transactions on pattern
analysis and machine intelligence (2017)