[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows
CSWin Transformer:基于交叉十字形窗口的视觉Transformer框架
- Abstract
- Section I Introduction
- Section II Related Work
- Section III Method
-
- Part 1 Overall Architecture
- Part 2 Cross-Shaped Window Self-Attention
- Section IV Experiments
-
- Part 1 ImageNet-1K Classification
- Part 2 COCO Detection
- Part 3 ADE20K Semantic Segmentation
- Part 4 Ablation Study
- Section V Conclusion
Paper
Code
Abstract
本文提出的CSWin Transformer是一种高效的通用视觉Transformer框架。Transformer的挑战之一就是其SA计算复杂度,一定程度上限制了Transformer中每个token的交互。为了解决这一问题,本文提出Cross-Shaped Window自注意力机制,可以并行计算水平方向和垂直方向的SA,这里需要将输入切分成等宽的条纹。
本文对切分的宽度做了细致的分析,从而实现较好的精度-计算量的权衡。
此外本文还引入了局部增强的位置编码方法(LePE),比现有的位置编码方法可以更好的利用局部位置信息。LePE可以接受任意分辨率的输入,并且可以迁移到下游任务。
基于以上设计,CSWinTransformer在各种任务中达到了十分可观的性能,在没有额外训练的ImageNet-1K上达到了85.4%的最高精度,目标检测COCO数据集上达到了46.4AP,在ADE20K分割任务上达到了51.7mIoU;如果在InageNet-21K上预训练后精度会进一步提升。
Section I Introduction
Vision Transformer
基于Transformer的模型近期在诸多视觉任务中超过了CNN的性能,通过MHSA机制ViT可以有效的建模长程依赖关系,非常适合处理高分辨率输入迁移到下游任务中;但是SA的计算复杂度一定程度上限制了Transformer的应用。
为了提升Transformer的计算效率,一种经典的方法是限制每一个token的注意力范围,将全局的注意力限制在一定窗口范围内;为了建立窗口之间的联系,有学者提出使用移窗的方式来交换附近窗口之间的信息;但是感受野扩大的仍然比较满,需要堆叠较多的block才能实现全局的注意力。但是一个足够大的感受野范围对最终性能是至关重要的,尤其是对于下游任务,如目标检测、分割。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第1张图片](http://img.e-com-net.com/image/info8/a51f126287304bec9e9ea820dde8edfa.jpg)
因此需要在保证较低计算成本的同时尽可能提升感受范围。
本文提出了CSWin自注意力机制,Fig 1展示了与SA的区别。CSWin中会在水平和垂直方向分别计算注意力,这需要将输入特征分成等宽的条纹,条纹宽度是窗口的重要参数,窗口的形状是十字形的,宽度决定了计算成本以及建模能力。
并且本文还会根据网络的深度来调整条纹的宽度:在浅层次宽度较小,深层次宽度较大;因为宽度越宽允许远程元素之间建立连接,这样可以在增加少部分计算成本的前提上提升网络容量。本文提供了细致的分析,讨论条纹的宽度是如何影响模型建模能力和计算成本的。
值得注意的是,基于CSWin SA,可以将多头注意力也切分成并行的组然后不同的组进行不同的SA运算,这种并行策略并没有增加计算成本,但是却扩大了每一个Transformer block的注意力区域。这与Fig 1右侧其他SA的计算方式有根本性的区别,并且消融实验的结果表示本文的注意力对一般视觉任务更有效。
在CSWin SA的基础上,本文采用层次化设计搭建了CSWin Transformer,为了进一步增强Transformer模型的建模能力,还使用了局部增强的位置编码(LePE),对下游任务更为 友好。与以往的位置编码相比,会在每个block内使用LePE,并且还会作用在注意力结果上,这样使得CSWin Transformer更有效。
CSWin Transformer作为一种视觉Transformer的基准网络,在图像分类、目标检测、语义分割任务中均取得了优异的性能。
Section II Related Work
Vision Transformer
近年来卷积神经网络已经是计算机视觉任务的主流框架,但是近期ViT等基于Transformer的网络框架也展现出惊人的效果;因此诸多工作致力于研究设计更好的Transformer框架用于视觉任务。这些工作都遵循Transformer的层次化设计,但采用了不同的SA机制。分层设计的优点是可以有效利用多尺度特征,然后逐步减少token数目可以降低计算复杂福。本文通过引入十字形窗口和LePE提出了一种新的层次化Transformer网络。
Efficient Self-Attention
在NLP领域已经设计了多种高效注意力机制来提升Transformer处理长序列的效率;由于视觉任务中图像的分辨率往往很高,因此设计高效的注意力机制也是至关重要的。但是目前许多工作依旧采用原始的全注意力机制,计算复杂度是输入分辨率的平方项;为了降低计算复杂度,Swin Transformer等提出使用移窗MSA将注意力局限在窗口之内同时允许窗口之间的交互;Vision Transformer中另一种 有效的是轴向注意力,会沿着水平轴或垂直轴依次应用局部窗口来实现全局注意力,但是这种按顺序和窗口的大小限制了网络的学习能力。
Positional Encoding
由于SA是排列不变的忽略了标记的位置信息,因此Transformer广泛使用positional emcoding来重新添加位置信息,包括绝对位置编码、相对位置编码和条件位置编码。
APE和RPE通常表示为一系列正弦函数或可学习参数,一般针对特定的分辨率,对不同的分辨率很不友好;
CPE则将特征作为输入可以得到任意分辨率的位置编码,然后再将生成的位置编码添加到输入上,一同输入SA模块。
本文的LePE与CPE比较相似,但是会把位置编码作为一个并行的模块添加到SA操作中,会对每个模块投影后的值进行操作。这样将位置编码与自注意力计算解耦,可以获得更强的局部归纳偏置。
Section III Method
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第2张图片](http://img.e-com-net.com/image/info8/cd5edbc13d6c465cac6d0e80fec45925.jpg)
Part 1 Overall Architecture
Fig 2展示了CSWin的网络架构。对于HxWx3的输入,首先采用步长卷积切patch进行patch embedding,window_size = 4;
整个网络包括4个阶段,这样可以获得多尺度的特征表述;相邻两个stage之间使用3x3的步长卷积来减少token数目,通道为数也会加倍。
因此第i个阶段的token数目为:
![]()
每一个阶段的CSWin Transformer Block的结构如右图所示,与原始MHSA有2点区别:
(1)将SA替换为本文的Cross-Shaped Window SA;
(2)使用LePE来增强局部归纳偏置信息,作为与SA并行的一个模块。
Part 2 Cross-Shaped Window Self-Attention
虽然SA可以有效建模远程上下文,但是其计算复杂度与特征大小的平方成正比,因此输入较高分辨率的特征图的计算成本十分高昂。Swin Transformer将SA的计算局限在窗口内来提升计算效率,但是需要堆叠更多的块来获得全局感受野。本文则提出十字交叉的窗口注意力。
Horizontal and Vertical Stripes
根据MHSA的定义,输入的特征首先会映射到K个头,然后每个头在自己子空间内进行SA计算。
对于水平方向的SA,X被均匀划分为等宽的互补重叠的水平条纹[X1,…,Xm],每条包含sw*W个token,sw表示条纹的宽度,通过调节SW来权衡学习能力和计算复杂度。
水平的SA计算为:
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第3张图片](http://img.e-com-net.com/image/info8/c3058c3a328a428590de8e2897340e25.jpg)
每条的输出会级联在一起。
我们可以将K个注意力头等分,K/2用于水平SA,K/2用于垂直SA的计算,最终的注意力输出表示为二者的级联:

即将多头注意力分成并行的group,不同的group采用不同的SA计算方式、换言之通过分组来扩大每个token的注意力范围。而原始的SA是对不同的头进行相同的注意力计算,实验结果表明本文的这种分组计算方法性能更好。
计算复杂度分析
对于高分辨率的输入,H,W一般会远远大于通道数C
对于低分辨率(later atage)HW则会小于C
因此可以在早期stage使用较小sw在后期stage使用较大sw,这样通过调整sw可以灵活调整每个token的注意力区域。
![]()
同时还要注意sw应该能被输入尺寸整除,因此本文默认设置为1,2,7,7
Locally-Enhanced Positional Encoding
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第4张图片](http://img.e-com-net.com/image/info8/5bc3c91d3b5b412fa5f953183ed50774.jpg)
LePE是在每个Transformer block内部增加的位置信息,但与RPE不同的地方在于RPE是在attention计算时加入的位置信息,LePE则是更加直接,将位置信息加在线性映射后的value上。参见下式:

但是也要考虑到如果计算E的所有连接需要的计算成本也很大,因此本文假设:对于特定的输入,最重要的信息来自于该特定位置的附近。
因此本文提出局部增强的位置编码(LePE),结合深度可分离卷积来作用V于alue。这样LePE可以接受任意分辨率的输入。
![]()
## Part 3 CSWin Transformer Block
因此CSWin Transformer Block的计算可以表达为:
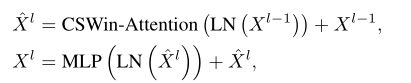
## Part 4 结构变体
Table 1展示了不同规模的CSWin网络,不同的通道数目、不同的注意力头数以及每个stage中的bokck数目组成了Tiny,Small,Base,Large四种规模的网络。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第5张图片](http://img.e-com-net.com/image/info8/90764a1f7f3c49b6b8e957d7b18cbcc4.jpg)
Section IV Experiments
本文在ImageNet-1K图像分类,COCO目标检测,ADE20K语义分割任务上测试了CSWin Transformer的性能。
Part 1 ImageNet-1K Classification
输入224x224
AdamW优化器
training epoch = 300
Table 2是与目前SOTA模型的精度对比,计算量分别是:
tINY模型(约4.3GFLOPs);SMALL模型(约6.8GFLOPs)和Base模型(约15GFLOPs).
可以看到远远超过了Vision Transformer,证明了CSWin强大的学习能力。
与CNN模型相比,也比EfficientNet效果接近甚至超过了;如果在ImageNet-21K上预训练后性能会进一步提升,参见Table 3。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第6张图片](http://img.e-com-net.com/image/info8/84aff68189a44d5c8d287d2271994691.jpg)
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第7张图片](http://img.e-com-net.com/image/info8/89eeae23b194435587dedfca5f091f8f.jpg)
Part 2 COCO Detection
CSWin Transformer与Mask R-CNN,级联Mask R-CNN对比做目标检测的结果,对比结果参见Table 4,可以看到CSWin超过Transformer同类。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第8张图片](http://img.e-com-net.com/image/info8/89b54517e1fc4dab881334efcf8d7994.jpg)
Part 3 ADE20K Semantic Segmentation
语义分割backbone选用的是FPN和Upernet网络,Table 6是语义分割的比较结果。可以看到不同规模的CSWin均超过目前的SOTA,具体来说,CSWin-T、CSWin-S、CSWin-B实现了+6.7、+4.0、+3.9与Swin 框架相比,以及比Upernet分别高+4.8、+2.4、+2.7 mIoU。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第9张图片](http://img.e-com-net.com/image/info8/f73811f3b19f4a9896647ef38e8f78a6.jpg)
Part 4 Ablation Study
为了评估每部分的作用还进行了消融实验。
主要评估sw对网络深度、网络性能的影响以及MHSA的分组设计对性能的影响。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第10张图片](http://img.e-com-net.com/image/info8/66a092839719437796d968f02c6d8ad7.jpg)
Table 7展示了消融实验的结果,可以看到sw对扩大注意力范围十分重要,sw =1时精度会显著下降;如果不对head分组也会导致性能有一定下降。
从Table 7最后两行可以看到“先深再浅”网络会比“先浅再深”的网络性能更好,为了验证这一点本文还这几了一个比较浅、宽的网络变体,性能确实变差了。
最后一行则显示使用重叠token embedding的必要性。
![[Transformer]CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows_第11张图片](http://img.e-com-net.com/image/info8/3e7bc0e79bca4c46b25e4a8cef4a394e.jpg)
Attention Mechanism
CSWin是本文的核心模块,可以在节省计算的同时实现较强的建模能力。为了验证这一点本文将CSWin与现有的一些SA进行了对比,分别是滑窗SA,移窗SA,空间分离SA和轴向SA。基于的网络是前一节的浅宽设计网络。
Table 8a展示了对比结果,可以看到CSWin的性能比目前其他SA机制都要好;尤其是轴向注意力,虽然可以通过两个模块就捕获全局注意力,但是迁移到下游任务上效果却不是很好,因为它每个block中注意力范围都很小,相当于sw=1的情况。
Positional Encoding Comparison
Table 8(b)则展示了不同位置编码方案的对比结果。
可以看到位置编码通过引入局部归纳偏执带来心梗提升,虽然RPE在不同分辨率的分类任务上取得了较好的性能,但是本文的LePE性能更好。
Section V Conclusion
本文提出的CSWin Transformer核心是十字形的SA,通过将多头注意力分成水平组和垂直组分别进行SA计算,可以有效扩大每个token的注意力范围;另一方面本文还分析了条纹宽度(sw)对网络容量和计算复杂度的影响。
本文还将LePE这种位置编码方案引入设计中,可以迁移到下游任务。
大量实验结果证明了本文CSWin的高效和有效性。在分类、分割、目标检测任务上均达到了SOTA。
期待未来CSWin可以应用到更多任务中。