CFA: Coupled-hypersphere-based Feature Adaptation for Target-Oriented Anomaly Localization
自学所用
基于耦合超球面的特征适应(CFA),使用适应目标数据集的特征来完成复杂的异常定位。CFA:1.一个可学习的补丁描述符,学习和嵌入面相目标的特征;2.与目标数据集的大小无关的可扩展内存库;CFA采用迁移学习来增加正常特征密度,以便通过补丁描述符和内存库应用于可训练的CNN来区分异常特征。
异常定位的性能取决于内存库的大小;提出的新方法,通过将迁移学习应用到预训练的CNN来产生具有减少偏差的面向目标的特征;定义了一个新的基于软边界回归的损失函数,搜索具有最小半径的超球面,以密集聚类正常特征;提出的损失函数通过利用形成耦合超球面的几个记忆特征来帮助可学习的补丁描述符提取判别特征;减少推理时间,提出一个可扩展的内存库,它不仅缓解了高估异常特征正态性的风险,而且实现了空间复杂性的效率;
贡献:发现了对预训练CNN的偏差特征对异常定位的负面影响,提出了对目标数据集的适应作为解决方案;提出了一种通过度量学习获取判别特征的新方法;
提出了一种基于耦合超球面的特征自适应(CFA),它在目标数据集上执行迁移学习,作为减轻预训练CNN偏差的解决方案;CFA的补丁描述符学习从目标数据集的正常样本中获得的补丁特征,使其在记忆特征周围具有高密度;CFA解决了在使用预训练CNN时,异常特征的正态性被高估的问题。
CFA通过基于具有大数据集的预训练CNN推断mubiao 数据集的样本来获取各种尺度的特征图;

补丁特征:![]() ,H、W代表最大特征图的高度和宽度,D表示采样的特征图的维度总和;F的每个像素位置都有一个预定的感受野,
,H、W代表最大特征图的高度和宽度,D表示采样的特征图的维度总和;F的每个像素位置都有一个预定的感受野, ![]() 可以被认为是像素位置的语义信息。P被输入到补丁描述符
可以被认为是像素位置的语义信息。P被输入到补丁描述符![]() ,
,![]() 是一个具有可学习参数的辅助网络,将Pt
是一个具有可学习参数的辅助网络,将Pt![]() 转换为面向目标的特征
转换为面向目标的特征![]() ,
,![]() 是指通过
是指通过![]() 嵌入的
嵌入的![]() 的维度。
的维度。
仅由正常样本组成的训练集中获取的所有初始面向目标的特征都根据特定的建模过程存储在存储库C中;在训练阶段,CFA基于记忆特征c ∈ C为中心创建的叠加超球进行对比监督,即所谓的耦合超球;CFA将从测试集的任意样本中获得的![]() 与在存储库中搜索的最近邻
与在存储库中搜索的最近邻![]() 进行匹配,并生成表示异常程度的热图;
进行匹配,并生成表示异常程度的热图;
基于耦合超球面的特征自适应:
通过融合基于超球面的损失函数和记忆库来解决预训练CNN的偏差问题,具体流程为:
首先,通过![]() 和C的NN搜索,搜索第k个最近邻
和C的NN搜索,搜索第k个最近邻![]() ,接下来CFA监督
,接下来CFA监督![]() ,使
,使![]() 嵌入到
嵌入到![]() 附近。具体来说,
附近。具体来说,![]() 可以通过监督
可以通过监督![]() 将其嵌入以
将其嵌入以![]() 为中心创建的半径为r的超球面内,从而在正常特征之间形成高度集中;通过在
为中心创建的半径为r的超球面内,从而在正常特征之间形成高度集中;通过在![]() 上加一个惩罚来吸引(1)
上加一个惩罚来吸引(1)![]() :
: ,超参数K是与
,超参数K是与![]() 匹配的最近邻数量,T=h×w是从单个样本中获得的Ps的数量;
匹配的最近邻数量,T=h×w是从单个样本中获得的Ps的数量;![]() 是一个预定义的距离度量,即欧几里得距离;CFA通过优化
是一个预定义的距离度量,即欧几里得距离;CFA通过优化![]() 的参数来实现特征自适应;定义
的参数来实现特征自适应;定义![]() 对
对![]() 进行对比监督,使得以
进行对比监督,使得以![]() 为中心的超球面排斥;
为中心的超球面排斥; ,其中超参数J是用于对比监督的硬负特征的总数,超参数 α 用于控制
,其中超参数J是用于对比监督的硬负特征的总数,超参数 α 用于控制![]() 和
和![]() 之间的平衡
之间的平衡
![]() ,如果与
,如果与![]() 匹配的
匹配的![]() 和
和![]() 之间的距离比r更近,则
之间的距离比r更近,则![]() 基于耦合超球直接监督
基于耦合超球直接监督![]() 。
。
记忆库压缩:
下列算法描述了存储库的压缩过程:

下图的上半部分说明了为目标数据集的每个样本更新记忆特征的过程

评分函数:
使用![]() 定义异常分数
定义异常分数![]()
使用softmin来衡量最近的c与另一个c的接近程度,并将其定义为确定性,通过将![]() 与
与![]() 的确定性相乘,解决了正态性被低估的问题:
的确定性相乘,解决了正态性被低估的问题: ;为了输出与输入样本相同分辨率的异常评分图,对异常评分图A进行插值,并采用σ=4的高斯平滑作为后处理;
;为了输出与输入样本相同分辨率的异常评分图,对异常评分图A进行插值,并采用σ=4的高斯平滑作为后处理;
实验:
为了验证所提方法的鲁棒性,给出了随机旋转和裁剪MVTec AD数据集的Rd-MVTec AD数据集的性能。I-AUROC(异常检测)、P-AUROC(异常定位),P-AUPRO(区域重叠曲线),用于所有实验的CNN都经过ImageNet预训练,为了在预训练的CNN上获得多尺度特征,我们从中间层提取对应的{C2,C3,C4}的特征映射。每个提取的特征图的空间分辨率分别为输入样本的1/4、1/8、1/16,优化器采用adamw和amsgrad,学习率为0.003,权重衰减0.0005,batch-size为4,epochs为30,CFA的超参数α为0.00001,β为0.1,作为每个补丁特征的最近邻居数,K和J均为3。
定量结果:
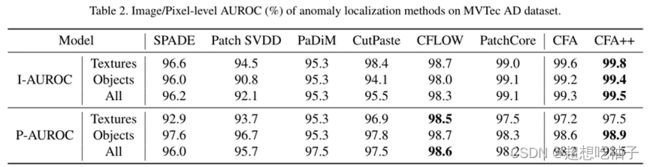
CFA++指的是使用裁剪图像和仅使用调整大小的样本时对结果进行集成的情况;

消融实验:
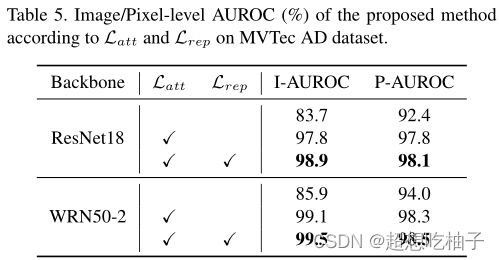 表5显示了特征适应对异常定位的影响
表5显示了特征适应对异常定位的影响

定性结果:
图 3 显示了根据特征适应和评分函数对每个样本的补丁特征的异常评分。这里,红色表示异常分数,虚线圆圈表示异常特征区域,三角形表示记忆特征。当在适应之前使用偏向于大数据集的特征时,正常特征的正态性被低估并且具有与异常特征相似的分数(第二列)。很难区分这两个特征,因为边界在分数方面是模棱两可的。这会导致无法精确区分异常特征的负面影响。
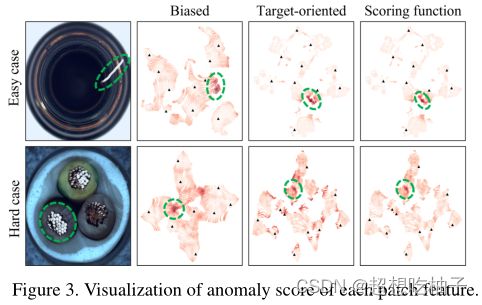
另一方面,当使用特征适应后的面向目标的特征时,它们是很好的聚类。因此,简单情况的正常特征和异常特征得到了清晰的区分(见图3第三列)。然而,单靠聚类无法对困难情况的不确定异常特征进行精确评分。所提出的评分函数通过考虑确定性来确定异常值,因此即使是硬例的异常特征也能被精确区分出来,如图3的最后一列所示。