NNDL 实验六 卷积神经网络(5)使用预训练resnet18实现CIFAR-10分类
文章目录
-
- 5.5 实践:基于ResNet18网络完成图像分类任务
-
- 5.5.1 数据处理
-
- 5.5.1.1 数据集介绍
- 5.5.1.2 数据读取
- 5.1.1.3 构造Dataset类
- 5.5.2 模型构建
-
- 什么是“**预训练模型**”?什么是“迁移学习”?(必做)
- 比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
- 5.5.3 模型训练
- 5.5.4 模型评价
- 5.5.5 模型预测
- 思考题
-
- 1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)
- 2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
- 总结
- 参考:
5.5 实践:基于ResNet18网络完成图像分类任务
图像分类(Image Classification)
计算机视觉中的一个基础任务,将图像的语义将不同图像划分到不同类别。
很多任务可以转换为图像分类任务。
比如人脸检测就是判断一个区域内是否有人脸,可以看作一个二分类的图像分类任务。
- 数据集:CIFAR-10数据集,
- 网络:ResNet18模型,
- 损失函数:交叉熵损失,
- 优化器:Adam优化器,Adam优化器的介绍参考NNDL第7.2.4.3节。
- 评价指标:准确率。
5.5.1 数据处理
5.5.1.1 数据集介绍
CIFAR-10数据集包含了10种不同的类别、共60,000张图像,其中每个类别的图像都是6000张,图像大小均为32×32像素。CIFAR-10数据集的示例如上图所示。
5.5.1.2 数据读取
在本实验中,将原始训练集拆分成了train_set、dev_set两个部分,分别包括40 000条和10 000条样本。将data_batch_1到data_batch_4作为训练集,data_batch_5作为验证集,test_batch作为测试集。
最终的数据集构成为:
- 训练集:40 000条样本。
- 验证集:10 000条样本。
- 测试集:10 000条样本。
读取一个batch数据的代码如下所示:
import os
import pickle
import numpy as np
def load_cifar10_batch(folder_path, batch_id=1, mode='train'):
if mode == 'test':
file_path = os.path.join(folder_path, 'test_batch')
else:
file_path = os.path.join(folder_path, 'data_batch_'+str(batch_id))
#加载数据集文件
with open(file_path, 'rb') as batch_file:
batch = pickle.load(batch_file, encoding = 'latin1')
imgs = batch['data'].reshape((len(batch['data']),3,32,32)) / 255.
labels = batch['labels']
return np.array(imgs, dtype='float32'), np.array(labels)
imgs_batch, labels_batch = load_cifar10_batch(folder_path=r'C:\Users\320\PycharmProjects\pythonProject1\cifar-10-batches-py',
batch_id=1, mode='train')
查看数据的维度:
#打印一下每个batch中X和y的维度
print ("batch of imgs shape: ",imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
运行结果:
batch of imgs shape: (10000, 3, 32, 32) batch of labels shape: (10000,)
观察其中一张样本图像和对应标签:
# 打印一下每个batch中X和y的维度
print("batch of imgs shape: ", imgs_batch.shape, "batch of labels shape: ", labels_batch.shape)
import matplotlib.pyplot as plt
image, label = imgs_batch[2], labels_batch[2]
print("The label in the picture is {}".format(label))
plt.figure(figsize=(2, 2))
plt.imshow(image.transpose(1, 2, 0))
plt.savefig('cnn.pdf')
运行结果:

The label in the picture is 9
5.1.1.3 构造Dataset类
class CIFAR10Dataset(Dataset):
def __init__(self, folder_path='./cifar10/cifar-10-batches-py', mode='train'):
if mode == 'train':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=1, mode='train')
for i in range(2, 5):
imgs_batch, labels_batch = load_cifar10_batch(folder_path=folder_path, batch_id=i, mode='train')
self.imgs, self.labels = np.concatenate([self.imgs, imgs_batch]), np.concatenate(
[self.labels, labels_batch])
elif mode == 'dev':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, batch_id=5, mode='dev')
elif mode == 'test':
self.imgs, self.labels = load_cifar10_batch(folder_path=folder_path, mode='test')
self.transform = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
def __getitem__(self, idx):
img, label = self.imgs[idx], self.labels[idx]
img = img.transpose(1, 2, 0)
img = self.transform(img)
return img, label
def __len__(self):
return len(self.imgs)
train_dataset = CIFAR10Dataset(folder_path='./cifar10/cifar-10-batches-py', mode='train')
dev_dataset = CIFAR10Dataset(folder_path='./cifar10/cifar-10-batches-py', mode='dev')
test_dataset = CIFAR10Dataset(folder_path='./cifar10/cifar-10-batches-py', mode='test')
5.5.2 模型构建
使用高层API中的Resnet18进行图像分类实验。
from torchvision.models import resnet18
resnet18_model = resnet18()
什么是“预训练模型”?什么是“迁移学习”?(必做)
预训练模型:
-
预训练模型就是已经用数据集训练好了的模型。
-
现在我们常用的预训练模型就是他人用常用模型,比如VGG16/19,Resnet等模型,并用大型数据集来做训练集,比如Imagenet, COCO等训练好的模型参数
-
正常情况下,我们常用的VGG16/19等网络已经是他人调试好的优秀网络,我们无需再修改其网络结构。
为什么我们要做预训练模型?
- 首先,预训练模型是一种迁移学习的应用,利用几乎无限的文本,学习输入句子的每一个成员的上下文相关的表示,它隐式地学习到了通用的语法语义知识。
- 第二,它可以将从开放领域学到的知识迁移到下游任务,以改善低资源任务,对低资源语言处理也非常有利。
- 第三,预训练模型在几乎所有 NLP 任务中都取得了目前最佳的成果。
- 最后,这个预训练模型+微调机制具备很好的可扩展性,在支持一个新任务时,只需要利用该任务的标注数据进行微调即可,一般工程师就可以实现。
预训练模型发展趋势
- 模型越来越大,
- 预训练方法也在不断增加,
- 还有从语言、多语言到多模态不断演进。
什么是迁移学习
迁移学习的定义:
迁移学习,是指利用数据、任务、或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
迁移学习,顾名思义,就是要进行迁移。放到人工智能和机器学习的学科里,迁移学习是一种学习的思想和模式。
首先机器学习是人工智能的一大类重要方法,也是目前发展最迅速、效果最显著的方法。机器学习解决的是让机器自主地从数据中获取知识,从而应用于新的问题中。迁移学习作为机器学习的一个重要分支,侧重于将已经学习过的知识迁移应用于新的问题中。
迁移学习的核心问题是,找到新问题和原问题之间的相似性,才可顺利地实现知识的迁移。
比较“使用预训练模型”和“不使用预训练模型”的效果。(必做)
resnet = models.resnet18(pretrained=True)
resnet = models.resnet18(pretrained=False)
使用预训练的运行结果:
[Evaluate] best accuracy performence has been updated: 0.79750 --> 0.79820
[Train] epoch: 4/5, step: 2625/3125, loss: 0.44100
[Evaluate] dev score: 0.79320, dev loss: 0.66294
[Train] epoch: 4/5, step: 2640/3125, loss: 0.50751
[Evaluate] dev score: 0.78610, dev loss: 0.67606
[Train] epoch: 4/5, step: 2655/3125, loss: 0.31529
[Evaluate] dev score: 0.79570, dev loss: 0.65889
[Train] epoch: 4/5, step: 2670/3125, loss: 0.46521
[Evaluate] dev score: 0.78810, dev loss: 0.68342
[Train] epoch: 4/5, step: 2685/3125, loss: 0.37717
[Evaluate] dev score: 0.78900, dev loss: 0.67783
[Train] epoch: 4/5, step: 2700/3125, loss: 0.31043
[Evaluate] dev score: 0.79180, dev loss: 0.66016
[Train] epoch: 4/5, step: 2715/3125, loss: 0.38367
[Evaluate] dev score: 0.79180, dev loss: 0.66531
[Train] epoch: 4/5, step: 2730/3125, loss: 0.52862
[Evaluate] dev score: 0.79340, dev loss: 0.66304
[Train] epoch: 4/5, step: 2745/3125, loss: 0.28240
[Evaluate] dev score: 0.79260, dev loss: 0.66879
[Train] epoch: 4/5, step: 2760/3125, loss: 0.14882
[Evaluate] dev score: 0.79580, dev loss: 0.66182
[Train] epoch: 4/5, step: 2775/3125, loss: 0.30550
[Evaluate] dev score: 0.78820, dev loss: 0.69171
[Train] epoch: 4/5, step: 2790/3125, loss: 0.44015
[Evaluate] dev score: 0.79200, dev loss: 0.67065
[Train] epoch: 4/5, step: 2805/3125, loss: 0.41613
[Evaluate] dev score: 0.79580, dev loss: 0.66872
[Train] epoch: 4/5, step: 2820/3125, loss: 0.59139
[Evaluate] dev score: 0.79230, dev loss: 0.68105
[Train] epoch: 4/5, step: 2835/3125, loss: 0.29377
[Evaluate] dev score: 0.79520, dev loss: 0.65866
[Train] epoch: 4/5, step: 2850/3125, loss: 0.29034
[Evaluate] dev score: 0.79260, dev loss: 0.65478
[Train] epoch: 4/5, step: 2865/3125, loss: 0.41271
[Evaluate] dev score: 0.78830, dev loss: 0.65999
[Train] epoch: 4/5, step: 2880/3125, loss: 0.37167
[Evaluate] dev score: 0.79460, dev loss: 0.64716
[Train] epoch: 4/5, step: 2895/3125, loss: 0.53052
[Evaluate] dev score: 0.79230, dev loss: 0.64815
[Train] epoch: 4/5, step: 2910/3125, loss: 0.21881
[Evaluate] dev score: 0.79280, dev loss: 0.65201
[Train] epoch: 4/5, step: 2925/3125, loss: 0.26600
[Evaluate] dev score: 0.79170, dev loss: 0.64918
[Train] epoch: 4/5, step: 2940/3125, loss: 0.28689
[Evaluate] dev score: 0.79080, dev loss: 0.65444
[Train] epoch: 4/5, step: 2955/3125, loss: 0.20815
[Evaluate] dev score: 0.79260, dev loss: 0.66230
[Train] epoch: 4/5, step: 2970/3125, loss: 0.48740
[Evaluate] dev score: 0.79650, dev loss: 0.66977
[Train] epoch: 4/5, step: 2985/3125, loss: 0.18930
[Evaluate] dev score: 0.79520, dev loss: 0.65486
[Train] epoch: 4/5, step: 3000/3125, loss: 0.48037
[Evaluate] dev score: 0.79350, dev loss: 0.66097
[Train] epoch: 4/5, step: 3015/3125, loss: 0.36582
[Evaluate] dev score: 0.79320, dev loss: 0.65317
[Train] epoch: 4/5, step: 3030/3125, loss: 0.28759
[Evaluate] dev score: 0.78800, dev loss: 0.68003
[Train] epoch: 4/5, step: 3045/3125, loss: 0.35838
[Evaluate] dev score: 0.79580, dev loss: 0.65306
[Train] epoch: 4/5, step: 3060/3125, loss: 0.33888
[Evaluate] dev score: 0.79010, dev loss: 0.66805
[Train] epoch: 4/5, step: 3075/3125, loss: 0.43376
[Evaluate] dev score: 0.79490, dev loss: 0.64777
[Train] epoch: 4/5, step: 3090/3125, loss: 0.37124
[Evaluate] dev score: 0.79340, dev loss: 0.66019
[Train] epoch: 4/5, step: 3105/3125, loss: 0.16443
[Evaluate] dev score: 0.79090, dev loss: 0.67627
[Train] epoch: 4/5, step: 3120/3125, loss: 0.38564
[Evaluate] dev score: 0.79400, dev loss: 0.64625
[Evaluate] dev score: 0.79640, dev loss: 0.64426
[Train] Training done!
不使用预训练运行结果:
[Evaluate] dev score: 0.60980, dev loss: 1.16757
[Train] epoch: 4/5, step: 3000/3125, loss: 0.85107
[Evaluate] dev score: 0.61390, dev loss: 1.16987
[Train] epoch: 4/5, step: 3015/3125, loss: 0.66345
[Evaluate] dev score: 0.59570, dev loss: 1.22045
[Train] epoch: 4/5, step: 3030/3125, loss: 0.77317
[Evaluate] dev score: 0.60470, dev loss: 1.19635
[Train] epoch: 4/5, step: 3045/3125, loss: 0.91572
[Evaluate] dev score: 0.60900, dev loss: 1.17674
[Train] epoch: 4/5, step: 3060/3125, loss: 1.05468
[Evaluate] dev score: 0.60780, dev loss: 1.17694
[Train] epoch: 4/5, step: 3075/3125, loss: 0.93902
[Evaluate] dev score: 0.59870, dev loss: 1.19800
[Train] epoch: 4/5, step: 3090/3125, loss: 0.92894
[Evaluate] dev score: 0.60660, dev loss: 1.17440
[Train] epoch: 4/5, step: 3105/3125, loss: 0.83346
[Evaluate] dev score: 0.60950, dev loss: 1.17812
[Train] epoch: 4/5, step: 3120/3125, loss: 1.06426
[Evaluate] dev score: 0.61770, dev loss: 1.14914
[Evaluate] best accuracy performence has been updated: 0.61420 --> 0.61770
[Evaluate] dev score: 0.61830, dev loss: 1.15176
[Evaluate] best accuracy performence has been updated: 0.61770 --> 0.61830
对比使用预训练模型和不使用预训练模型,我们发现
- 使用预训练模型收敛速度更快,更稳定
- 使用预训练模型的准确率更高
5.5.3 模型训练
建议选用cuda进行训练,如果没有就是用cpu:
import torch.nn.functional as F
import torch.optim as opt
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(device)
lr = 0.001
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
dev_loader = DataLoader(dev_dataset, batch_size=batch_size)
test_loader = DataLoader(test_dataset, batch_size=batch_size)
model = resnet18_model
model.to(device)
optimizer = opt.SGD(model.parameters(), lr=lr, momentum=0.9)
loss_fn = F.cross_entropy
metric = Accuracy()
runner = RunnerV3(model, optimizer, loss_fn, metric)
log_steps = 3000
eval_steps = 3000
runner.train(train_loader, dev_loader, num_epochs=30, log_steps=log_steps,
eval_steps=eval_steps, save_path="best_model.pdparams")
运行结果:
[Evaluate] dev score: 0.60980, dev loss: 1.16757
[Train] epoch: 4/5, step: 3000/3125, loss: 0.85107
[Evaluate] dev score: 0.61390, dev loss: 1.16987
[Train] epoch: 4/5, step: 3015/3125, loss: 0.66345
[Evaluate] dev score: 0.59570, dev loss: 1.22045
[Train] epoch: 4/5, step: 3030/3125, loss: 0.77317
[Evaluate] dev score: 0.60470, dev loss: 1.19635
[Train] epoch: 4/5, step: 3045/3125, loss: 0.91572
[Evaluate] dev score: 0.60900, dev loss: 1.17674
[Train] epoch: 4/5, step: 3060/3125, loss: 1.05468
[Evaluate] dev score: 0.60780, dev loss: 1.17694
[Train] epoch: 4/5, step: 3075/3125, loss: 0.93902
[Evaluate] dev score: 0.59870, dev loss: 1.19800
[Train] epoch: 4/5, step: 3090/3125, loss: 0.92894
[Evaluate] dev score: 0.60660, dev loss: 1.17440
[Train] epoch: 4/5, step: 3105/3125, loss: 0.83346
[Evaluate] dev score: 0.60950, dev loss: 1.17812
[Train] epoch: 4/5, step: 3120/3125, loss: 1.06426
[Evaluate] dev score: 0.61770, dev loss: 1.14914
[Evaluate] best accuracy performence has been updated: 0.61420 --> 0.61770
[Evaluate] dev score: 0.61830, dev loss: 1.15176
[Evaluate] best accuracy performence has been updated: 0.61770 --> 0.61830
5.5.4 模型评价
# 加载最优模型
runner.load_model('best_model.pdparams')
# 模型评价
score, loss = runner.evaluate(iter(test_loader))
print("[Test] accuracy/loss: {:.4f}/{:.4f}".format(score, loss))
运行结果:
[Test] accuracy/loss: 0.6055/1.1625
5.5.5 模型预测
#获取测试集中的一个batch的数据
X, label = next(iter(test_loader))
X = X.cpu()
logits = runner.predict(X)
#多分类,使用softmax计算预测概率
pred = F.softmax(logits)
#获取概率最大的类别
pred_class = torch.argmax(pred[2]).numpy()
print(label[2].numpy())
label = label[2].numpy()
#输出真实类别与预测类别
print("The true category is {} and the predicted category is {}".format(label, pred_class))
#可视化图片
plt.figure(figsize=(2, 2))
imgs, labels = load_cifar10_batch(folder_path='./cifar10/cifar-10-batches-py', mode='test')
plt.imshow(imgs[2].transpose(1,2,0))
plt.savefig('cnn-test-vis.pdf')
运行结果:

The true categary is 8 and the predicted categary is 8
思考题
1.阅读《Deep Residual Learning for Image Recognition》,了解5种深度的ResNet(18,34,50,101和152),并简单谈谈自己的看法。(选做)

上面一共提出了5种深度的resnet,分别是18,34,50,101和152,首先看表最左侧,我们发现所有的网络都分成5部分,分别是:conv1,conv2_x,conv3_x,conv4_x,conv5_x.
拿101-layer那列,我们先看看101-layer是不是真的是101层网络,首先有个输入7x7x64的卷积,然后经过3 + 4 + 23 + 3 = 33个building block,每个block为3层,所以有33 x 3 = 99层,最后有个fc层(用于分类),所以1 + 99 + 1 = 101层,确实有101层网络;
101层网络仅仅指卷积或者全连接层,而激活层或者Pooling层并没有计算在内.
仔细观察图,可以得出以下2个结论:
从50-layer之后,conv2——conv5都是采取三层块结构以减小计算量和参数数量
说明50-layer以后开始采用BottleBlock
从50-layer之后,层数的加深仅仅体现在conv4_x这一层中,也就是output size为14×14的图像
2.用自己的话简单评价:LeNet、AlexNet、VGG、GoogLeNet、ResNet(选做)
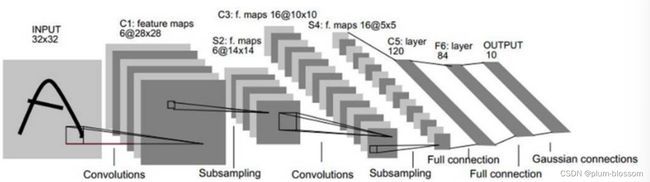
Le-Net
Lenet也称Lenet-5,共5个隐藏层(不考虑磁化层),网络结构为:

AlexNet
Alexnet模型由5个卷积层和3个池化Pooling 层 ,其中还有3个全连接层构成。AlexNet 跟 LeNet 结构类似,但使用了更多的卷积层和更大的参数空间来拟合大规模数据集 ImageNet。它是浅层神经网络和深度神经网络的分界线。
下图为AlexNet网络结构:

特点:
- 首次利用GPU进行网络加速训练。
- 在每个卷机后面添加了Relu激活函数,而不是传统的Sigmoid激活函数以及Tanh激活函数,解决了Sigmoid的梯度消失问题,使收敛更快。
- 使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合(也使用数据增强防止过拟合)
- 添加了归一化LRN(Local Response Normalization,局部响应归一化)层,使准确率更高。
- 重叠最大池化(overlapping max pooling),即池化范围 z 与步长 s 存在关系 z>s 避免平均池化(average pooling)的平均效应。
VGGNet
VGG 的结构与 AlexNet 类似,区别是深度更深,但形式上更加简单。VGG由5层卷积层、3层全连接层、1层softmax输出层构成,层与层之间使用maxpool(最大化池)分开,所有隐藏层的激活单元都采用ReLU函数。

VGG网络特点:
(1)结构简洁
(2) 小卷积核
(3)小池化核
(5)层数更深

GoogLeNet
GoogLeNet获得了6.7%的top-5分类错误率。这已经非常接近人类的表现水平。数据表明,经过培训后的人能够在ILSVRC上做到5.1%的top-5分类错误率。GoogLeNet的整体结构:3个卷积层,9个Inception子模块,以及softmax层。其中,每个Inception子模块包含了2个特殊的卷积层。所以,GoogLeNet一共有22层网络。

ResNet
ResNet是一种残差网络,咱们可以把它理解为一个子网络,这个子网络经过堆叠可以构成一个很深的网络。咱们可以先简单看一下ResNet的结构

总结
使用思维导图全面总结CNN(必做)

参考:
NNDL 实验5(上) - HBU_DAVID - 博客园 (cnblogs.com)
NNDL 实验5(下) - HBU_DAVID - 博客园 (cnblogs.com)
