Pytorch实战 | P7咖啡豆图片识别(深度学习实践pytorch)
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:Pytorch实战 | 第P7周:咖啡豆识别
- 原作者:K同学啊|接辅导、项目定制
一、我的环境
● 语言环境:Python3.8
● 编译器:pycharm
● 深度学习环境:Pytorch
● 数据来源:链接:https://pan.baidu.com/s/1gUO1eyMYxetvW0JV0r_j2g 提取码:0a2j
二、主要代码实现
1、main.py
# -*- coding: utf-8 -*-
import copy
import matplotlib.pyplot as plt
import torch.utils.data
from torchvision import datasets, transforms
from vgg16 import VGG16
import torch.nn as nn
# 一、数据准备
# 1、数据导入
train_transforms = transforms.Compose({
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
})
test_transforms = transforms.Compose({
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
})
total_data = datasets.ImageFolder('./data/', transform=train_transforms)
class_to_idx = total_data.class_to_idx
print(f'数据分类为:{class_to_idx}')
# 2、数据集划分
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
# 3、数据分批
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size)
for X, y in test_dl:
print('X shape:', X.shape)
print('y shape:', y.shape)
break
# 二、网络构建 vgg16.py vgg16().__init__(), vgg16().forward()
# 三、模型训练
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print('using:', device)
model = VGG16().to(device)
loss_fn = nn.CrossEntropyLoss()
learn_rate = 1e-4 # 初始学习率
lambda1 = lambda epoch: 0.92 ** (epoch // 4)
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=lambda1) # 选定调整方法
epoch_size = 40
train_acc = []
train_loss = []
test_loss = []
test_acc = []
best_model = None
best_acc = 0
for epoch in range(epoch_size):
model.train()
epoch_train_acc, epoch_train_loss = model.train1(model, train_dl, optimizer, loss_fn, device)
scheduler.step()
model.eval()
epoch_test_acc, epoch_test_loss = model.test1(model, test_dl, loss_fn, device)
# 保存最佳模型
if epoch_test_loss > best_acc:
best_acc = epoch_test_acc
best_model = copy.deepcopy(model)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = optimizer.state_dict()['param_groups'][0]['lr']
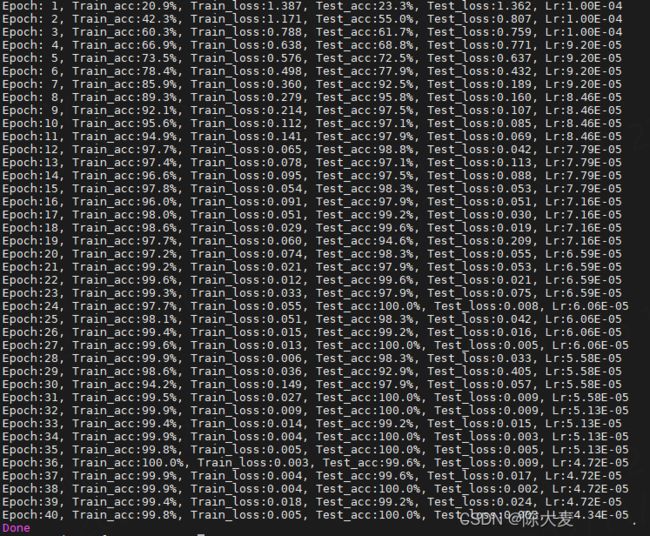
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}')
print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss,
epoch_test_acc * 100, epoch_test_loss, lr))
torch.save(model.state_dict(), './model/model.pth')
print('Done')
# 四、结果评估
epoch_range = range(epoch_size)
plt.figure(figsize=(12, 3))
# 1、训练集和验证集的准确率变化分析
plt.subplot(1, 2, 1)
plt.plot(epoch_range, train_acc, label='Training Accuracy')
plt.plot(epoch_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
# 2、训练集和验证集的损失变化分析
plt.subplot(1, 2, 2)
plt.plot(epoch_range, train_loss, label='Training Loss')
plt.plot(epoch_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.title('Training and Validation Loss')
plt.show()
# 五、测试验证 test.py
2、vgg16.py
# -*- coding: utf-8 -*-
import torch
import torch.nn as nn
from PIL import Image
import matplotlib.pyplot as plt
class VGG16(nn.Module):
def __init__(self):
super(VGG16, self).__init__()
# 卷积块1
self.block1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块2
self.block2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块3
self.block3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块4
self.block4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 卷积块5
self.block5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(),
nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
)
# 全连接网络层,用于分类
self.classifier = nn.Sequential(
nn.Linear(in_features=512 * 7 * 7, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(),
nn.Linear(in_features=4096, out_features=4)
)
def forward(self, x):
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.block4(x)
x = self.block5(x)
x = torch.flatten(x, start_dim=1)
x = self.classifier(x)
return x
def train1(self, model, dataloder, optmizer, loss_fn, device):
train_acc, train_loss = 0, 0
for X, y in dataloder:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optmizer.zero_grad()
loss.backward()
optmizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
size = len(dataloder.dataset)
num_batches = len(dataloder)
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test1(self, model, dataloder, loss_fn, device):
test_acc, test_loss = 0, 0
with torch.no_grad():
for X, y in dataloder:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
test_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss += loss.item()
size = len(dataloder.dataset)
batch_num = len(dataloder)
test_acc /= size
test_loss /= batch_num
return test_acc, test_loss
def predict_one_image(self, img_path, model, transform):
test_img = Image.open(img_path).convert('RGB')
plt.imshow(test_img)
plt.show()
test_img = transform(test_img)
img = test_img.unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
return pred
3、test.py
# -*- coding: utf-8 -*-
import torch
from torchvision import transforms
from vgg16 import VGG16
model = VGG16()
model.load_state_dict(torch.load('./model/model.pth', map_location='cpu'))
transforms = transforms.Compose({
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
})
classes = ['Dark', 'Green', 'Light', 'Medium']
img_path = './data/Medium/medium (100).png'
pred = model.predict_one_image(img_path, model, transforms)
print(f'预测结果为:{classes[pred]}')
三、遇到的主要问题
本周没有遇到什么问题