Python 使用 twitter API 获取twitter用户信息
Python 使用 twitter API 获取twitter用户信息
1. 概述
twitter作为国外极其大众化的社交平台,具有大量的海外用户,平台流动数据量极大,是国外人群生活数据的重要来源之一。twitter网站上的用户信息具有很大的研究价值和意义。
但是作为行业领先平台之一,twitter的网站设计水平较高,具有较强的反爬虫侦测手段,获取twitter数据最好的方法是使用其提供的twitter开发者API,通过API来结合Python爬虫获取用户数据是较为现实可靠的获取手段。

该文所使用的技术性手段不多,爬虫的使用较为基础,重点在于获取并合理使用twitter开发者API。
2. 工具准备:
1. Twitter开发者API接口:
Twitter给开发者提供了合理获取其数据的手段,即申请twitter开发者权限:
具体获取方法参见该博客:https://www.jianshu.com/p/cfb741dd52dd
注意事项:
- 申请开发者账号最好不要将所在地选择为中国。
- 提交申请时需要挂,所在地最好和所在地一致。
- 开发者账号申请具有一定的随机性。
2. Python环境及基础爬虫第三方库
3. 目标观察和数据获取思路:
1. 获取目标:
本文的获取目标是twitter平台上的极客用户数据。
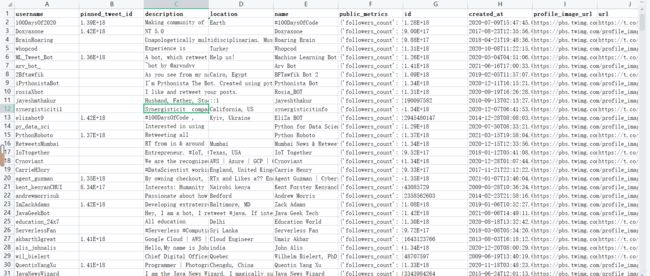
2. twitter API情况:
twitter的开发者API提供了多种查询用户信息、搜索推文的不同途径,具体参见其官方文档:
我们主要使用了推文搜索API和用户查询API。
3. 数据获取思路:
由于twitter的用户并没有按照特定领域或关键词进行分组,我们无法通过直接查询用户的方法来一步获取极客相关的twitter用户信息,因此我们采用间接的两步获取方法,首先使用推文搜索API,对找出的五十个极客相关关键词分别进行推文搜索,获取这些推文的作者信息——由于这些关键词都是专业性较强的行业用语,因此这些作者有很大可能是极客用户。由于此种获取到的用户数较少,我们进一步对上述获取到的用户进行关注者查询,查询以上结果中关注者较多较为知名的用户的所有关注者,并获取其关注者信息——根据行业集中原则,著名极客用户的关注者也是极客用户的可能性较大。

通过此种方法,我们可以获取到超过十万条极客用户数据。
4. 具体获取方法及代码:
首先我们需要根据自己申请得到的开发者令牌来构造header。
我们所需要的信息是开发者账号中给出的BEARER_TOKEN令牌信息。
实现一个函数,将令牌信息和user-agent信息写入请求头之中:
def bearer_oauth(r):
"""
Method required by bearer token authentication.
"""
r.headers["Authorization"] = f"your token"
r.headers["User-Agent"] = "Mozilla/5.0"
return r
然后我们根据自己的目标数据构造请求参数字典:
query_params = {'query': 'Python',#搜索关键词
'tweet.fields': 'author_id',
'expansions':'author_id',
'max_results': '100',#一页显示的最大结果数
'user.fields': 'created_at,entities,description,id,location,name,pinned_tweet_id,profile_image_url,protected,public_metrics,url,username,verified,withheld'#显示的信息,可定制
}
注意:上文的参数可以根据自己的目标数据定制,每一个参数的具体作用请参阅官方文档
然后我们使用requests库来获取搜索结果的用户数据。
url = "https://api.twitter.com/2/tweets/search/recent" #搜索API网址
query_params_two = query_params.copy()#使用翻页请求时的请求头参数
id_haved_lst = []#存储已获取过的用户id
user_info_lst = []#存储爬取结果
key_word_num = 0#正在爬取第几个关键词的搜索结果
next = False#是否翻页
while key_word_num < len(key_words):
query_params["query"] = key_words[key_word_num]#替换搜索关键词
time.sleep(random.random()*10)
if next:#现在需要爬取的是该搜索结果的第二页
r = requests.get(url, auth = bearer_oauth, params = query_params_two)
else:#现在需要爬取的是该搜索结果的首页
r = requests.get(url, auth = bearer_oauth, params = query_params)
js = r.json()
for one_user in js["includes"]["users"]:
if one_user["id"] in id_haved_lst:continue#已经爬取过的用户信息跳过
id_haved_lst.append(one_user["id"])
user_info_lst.append(one_user)
print("完成一页")
if "next_token" not in js["meta"]:#下一页有数据
key_word_num+=1
next = False
print("完成第{}个关键词".format(key_word_num))
continue
else:
query_params_two["next_token"] = js["meta"]["next_token"]#将下一页的参数写入请求头
next = True
continue
注意:该代码并不复杂,只使用了最基本的requests获取。重点在于,观察调用api返回的结果以及我们所请求的参数,我们会发现并没有翻页的参数,但只获取一页的数据毫无疑问太少了。观察返回结果,我们会发现next_token参数,该值即为查询下一页的该参数值。因此,如果要查询一个关键词搜索结果的非首页,我们需要将上一页查询到的next_token值写入请求头。因此此处我们构造了两个类似的请求头,并使用next变量指示是否使用翻页请求头。
以上代码即可实现第一轮的爬取,即通过查询关键词的推来获取作者信息,第一轮爬取之后的有效用户数据信息不到一万条,因此要根据以上结果进行第二轮爬取。
首先对爬取的结果将每一个用户的关注者数提取出来,作为排序的依据,提取出需要进行二次爬取的目标用户id列表:
data["followers_num"] = [i for i in range(data.shape[0])]#初始化关注者数量列
followers_num_lst = []
for i in range(data.shape[0]):
if "followers_count" not in data.iloc[i]["public_metrics"].keys():#该用户无该信息
followers_num_lst.append(0)
continue
followers_num_lst.append(int(data.iloc[i]["public_metrics"]["followers_count"]))
data["followers_num"] = followers_num_lst
id_lst = list(data.sort_values(by = ["followers_num"], ascending=False)["id"])[200:]#根据关注者数量对结果进行倒叙排列,并选取一定量作为二次爬取的目标,此处选取前200个
注意:此处选取多少结果作为二次爬取目标可以灵活变动,需要适中,太多则爬取的速度较慢,因为twitter对查询用户信息api速率限制较大,太少则获取到的数据量不足。以及从实践中得知,由于结果中存在一定量的非极客用户,而真正的极客用户的关注者数量排序一般在50~200之间,这一区间的极客用户比例最高,前50个的比例反而偏低,建议可以进行一定程度的人工筛选。
url = "https://api.twitter.com/2/users/{}/followers" #用户查询原网站
query_params_three = {"max_results":"1000",#每页显示的最大结果数
"user.fields": 'created_at,entities,description,id,location,name,pinned_tweet_id,profile_image_url,protected,public_metrics,url,username,verified,withheld'#显示的信息
}
query_params_four = query_params_three.copy()#与上文机制类似
#id_haved_lst = []
#user_info_lst = []
id_num = 1
next = False
while id_num < len(id_lst):
url_now = url.format(id_lst[id_num])
time.sleep(60)#休眠60秒,因为twitter对用户查询api的速率限制是15min/15次
try:
if next:
r = requests.get(url_now, auth = bearer_oauth, params = query_params_four)
else:
r = requests.get(url_now, auth = bearer_oauth, params = query_params_three)
js = r.json()
for one_user in js["data"]:
if one_user["id"] in id_haved_lst:continue
id_haved_lst.append(one_user["id"])
user_info_lst.append(one_user)
print(len(user_info_lst))
print("完成一页")
if "next_token" not in js["meta"]:
id_num+=1
next = False
print("完成第{}个用户".format(key_word_num))
continue
else:
query_params_two["next_token"] = js["meta"]["next_token"]
next = True
continue
except requests.exceptions.ProxyError:
time.sleep(random.random()*60)
print("错误一次")
continue
注意:此处代码逻辑同上文类似,也使用了翻页机制。注意由于twitter对该API的速率限制较大,此种爬取的速度较慢。
二轮爬取之后,爬取到的结果数就可以达到十万条以上,然后将结果存入csv文件即可。
pd.DataFrame(user_info_lst).to_csv(r"twitter.csv")
注意:由于twitter是国外网站,访问twitter需要使用代理,网络状况容易不稳定,因此此处使用了try-except异常捕捉机制,如果是代理不稳定引起的异常则休眠一段时间重来
5. 全部代码:
import requests
import pandas as pd
import time
import random
def bearer_oauth(r):
"""
Method required by bearer token authentication.
"""
r.headers["Authorization"] = f"your token"
r.headers["User-Agent"] = "Mozilla/5.0"
return r
query_params = {'query': 'Python',#搜索关键词
'tweet.fields': 'author_id',
'expansions':'author_id',
'max_results': '100',#一页显示的最大结果数
'user.fields': 'created_at,entities,description,id,location,name,pinned_tweet_id,profile_image_url,protected,public_metrics,url,username,verified,withheld'#显示的信息,可定制
}
url = "https://api.twitter.com/2/tweets/search/recent" #搜索API网址
query_params_two = query_params.copy()#使用翻页请求时的请求头参数
id_haved_lst = []#存储已获取过的用户id
user_info_lst = []#存储爬取结果
key_word_num = 0#正在爬取第几个关键词的搜索结果
next = False#是否翻页
while key_word_num < len(key_words):
query_params["query"] = key_words[key_word_num]#替换搜索关键词
time.sleep(random.random()*10)
if next:#现在需要爬取的是该搜索结果的第二页
r = requests.get(url, auth = bearer_oauth, params = query_params_two)
else:#现在需要爬取的是该搜索结果的首页
r = requests.get(url, auth = bearer_oauth, params = query_params)
js = r.json()
for one_user in js["includes"]["users"]:
if one_user["id"] in id_haved_lst:continue#已经爬取过的用户信息跳过
id_haved_lst.append(one_user["id"])
user_info_lst.append(one_user)
print("完成一页")
if "next_token" not in js["meta"]:#下一页有数据
key_word_num+=1
next = False
print("完成第{}个关键词".format(key_word_num))
continue
else:
query_params_two["next_token"] = js["meta"]["next_token"]#将下一页的参数写入请求头
next = True
continue
data["followers_num"] = [i for i in range(data.shape[0])]#初始化关注者数量列
followers_num_lst = []
for i in range(data.shape[0]):
if "followers_count" not in data.iloc[i]["public_metrics"].keys():#该用户无该信息
followers_num_lst.append(0)
continue
followers_num_lst.append(int(data.iloc[i]["public_metrics"]["followers_count"]))
data["followers_num"] = followers_num_lst
id_lst = list(data.sort_values(by = ["followers_num"], ascending=False)["id"])[200:]#根据关注者数量对结果进行倒叙排列,并选取一定量作为二次爬取的目标,此处选取前200个
url = "https://api.twitter.com/2/users/{}/followers" #用户查询原网站
query_params_three = {"max_results":"1000",#每页显示的最大结果数
"user.fields": 'created_at,entities,description,id,location,name,pinned_tweet_id,profile_image_url,protected,public_metrics,url,username,verified,withheld'#显示的信息
}
query_params_four = query_params_three.copy()#与上文机制类似
#id_haved_lst = []
#user_info_lst = []
id_num = 1
next = False
while id_num < len(id_lst):
url_now = url.format(id_lst[id_num])
time.sleep(60)#休眠60秒,因为twitter对用户查询api的速率限制是15min/15次
try:
if next:
r = requests.get(url_now, auth = bearer_oauth, params = query_params_four)
else:
r = requests.get(url_now, auth = bearer_oauth, params = query_params_three)
js = r.json()
for one_user in js["data"]:
if one_user["id"] in id_haved_lst:continue
id_haved_lst.append(one_user["id"])
user_info_lst.append(one_user)
print(len(user_info_lst))
print("完成一页")
if "next_token" not in js["meta"]:
id_num+=1
next = False
print("完成第{}个用户".format(key_word_num))
continue
else:
query_params_two["next_token"] = js["meta"]["next_token"]
next = True
continue
except requests.exceptions.ProxyError:
time.sleep(random.random()*60)
print("错误一次")
continue
pd.DataFrame(user_info_lst).to_csv(r"twitter.csv")