python机器学习之分类预测
目录
- 逻辑回归
-
- 水位判断案例引入逻辑回归计算原理
- 逻辑回归
- 单次项逻辑回归代码示例
- 二阶项及以上项式的边界函数计算和绘制
-
- 二阶多项式逻辑回归案例
-
- 尝试用一阶函数画出边界
- 二阶项逻辑回归
- K近邻分类模型(K-nearest neighbors)
-
- K近邻分类模型算法步骤
- 决策树
-
- 决策树原理
- 核心问题:树结构的每个分支先看哪个特征指标?
-
- ID3算法
- 实战:决策树判断员工是否适合相关工作
-
- 修改leaf参数查看效果,改最小50个样本
- 朴素贝叶斯
-
- 条件概率
- 全概率
- 贝叶斯
-
- 贝叶斯公式
- 贝叶斯用于机器训练
-
- 朴素贝叶斯公式
- 总结
- 实战:朴素贝叶斯预测学生录取及奖学金情况
- K-means聚类分析
-
- 核心流程
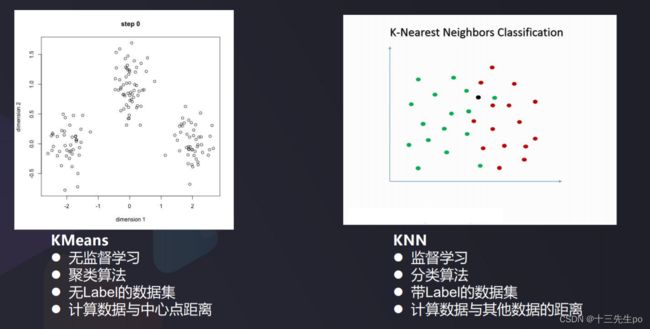
- K均值聚类 (KMeans) VS K近邻分类 (KNN)
- 实战1:普通数值类数据分类
-
- knn建模部分
- 逐步迭代查看KMeans模型训练效果
- 实战2:K均值聚类实现图像分割
-
- 修改分类数(4)
- 未完待续……
逻辑回归
计算机自动寻找垃圾信息共同特征
在新信息中检测是否包含垃圾信息特征内容,
判断其是否为垃圾邮件

部分特征:发件人、是否群发、网址、元、赢、微信、免费
- 根据数据类别与部分特征信息,自动寻找类别与特征信息的关系,
判断一个新的样本属于哪种类别
特征信息以列为单位,行是不同人的信息,输出数据类别(如0是正常,1是垃圾),然后去寻找关系


- 通过股价预测任务区分回归任务与分类任务

分类:非连续性判断类别
模型输出:非连续型标签
(明天股价预测为:上涨)
回归:连续性数值预测
模型输出:连续型数值
(明天股价预测为:125.1)
水位判断案例引入逻辑回归计算原理
任务:根据水位,判断水池是否需要蓄水或放水

特征信息:水位数据
数据类别:待蓄水(0)、放水(1)

- 先尝试用线性回归判断(复杂场景就不适用了)

求得一元线性回归直线方程
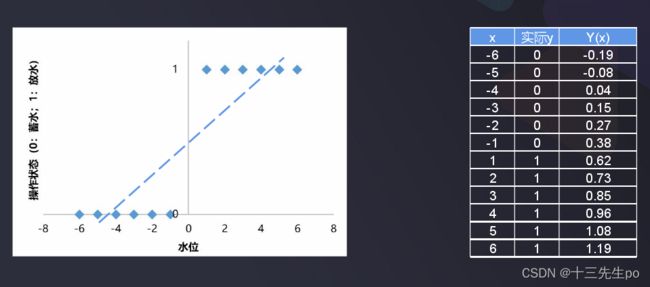

但如果数据样本复杂度增加,模型准确率下降明显

例如增加了一个x=50后,y的直线方程输出了异常的数据,如x=1时,方程判断结果=0

逻辑回归
根据数据特征,计算样本归属于某一类别的概率P(x),根据概率数值判断其所属类别
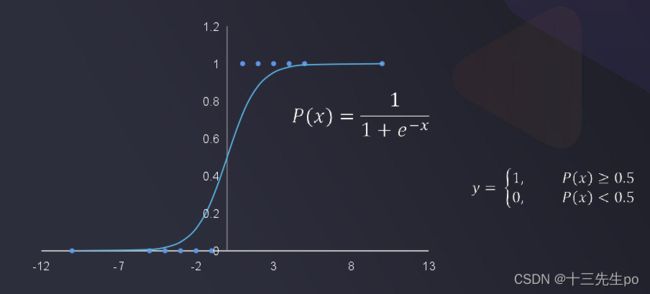
Y(x)界线明显,分类效果好!
- 逻辑回归处理更复杂的分类任务1
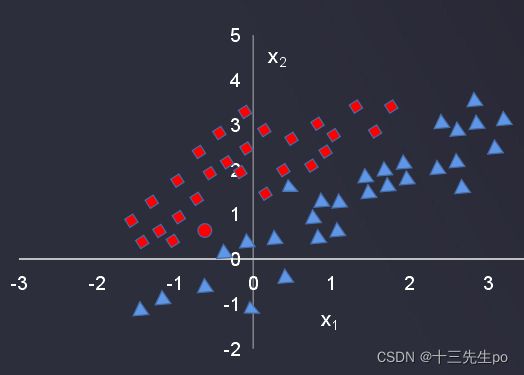
需要画分界线,将p(x)中的x变成了函数g(x),如果g(x)>0 ,则输出方形;如果g(x)<0,则输出三角形


- 逻辑回归处理更复杂的分类任务2
g(x)大于0,小于0,等于0分别对应值在圆圈外,圆圈内,圆圈上
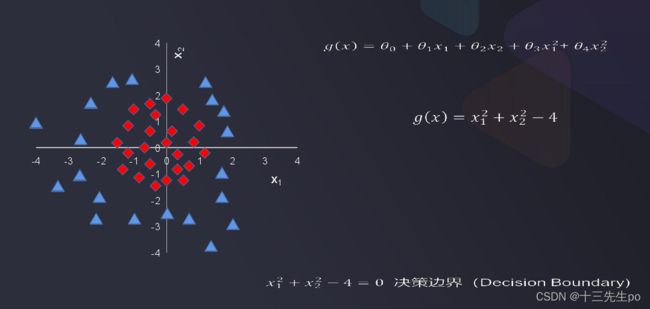
通过以上两个复杂任务的探索,可以知道:
逻辑回归结合多项式边界函数可解决复杂的分类问题
模型求解的核心,在于寻找到合适的多项式边界函数
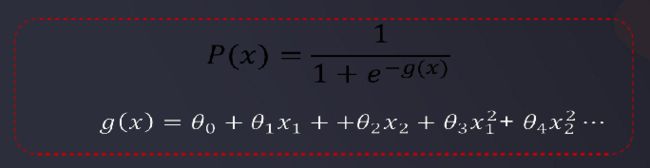
- 因此求解边界函数变成了主要的问题
求解边界函数(可以理解为找到回归方程,但输出的未必是一条直线,而是分界线),需要用到损失函数J来判断预测值和实际值的偏差程度:
求损失函数J(判断预测值和实际值的偏差程度),由原来计算一元线性回归时计算预测yi值与实际y值差的平方和变成了如下图的公式,此时yi就是实际要判断出来值(不是机器预测的值),而-log(p(x))、-log(1-p(x))就是对p(x)这个预测值计算出损失函数J

P(x)就是刚刚的逻辑函数,公式为:

输出的是偏向0或1的值
- 损失函数J计算值的解释
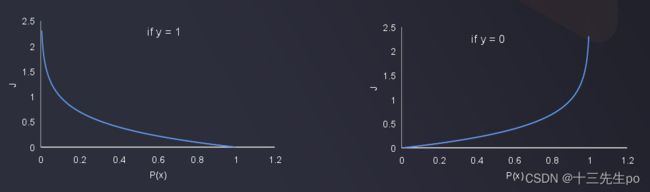
如果y=1,而p(x)=1,则计算出的J=0

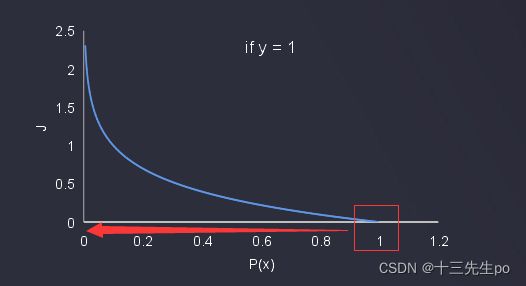
如果y=1,而p(x)=0(说明预测错了),则计算出的J会很大,即损失值很大

同理,对于要测出的实际值是0,如果y=0,而p(x)=1,则计算出的J=0,是符合的
![]()

如果y=0,而p(x)=1(说明预测错了),则计算出的J会很大,即损失值很大,也是符合我们的预期判断的

- 损失函数有关计算汇总
损失函数的两个公式可以整合成一个,也是合理的,当yi=0时,yi*log(p(x))就会=0,而恰好log(1-P(x))就可以输出值;当yi=0时,同理可得,也能得到相应的值

而g(x)中各个θ需要通过梯度下降法进行求解,令θ=tempθ,重新代入计算,直到收敛

单次项逻辑回归代码示例
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression # 逻辑回归
# 数据读取
data = pd.read_csv(r'task1_data.csv')
data.head()
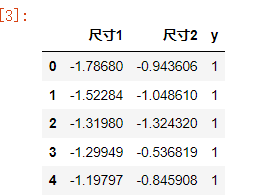
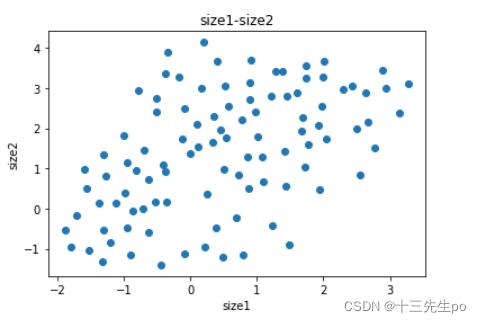
# 可视化数据
fig1 = plt.figure()
plt.scatter(data.loc[:,'尺寸1'],data.loc[:,'尺寸2'])
plt.title('size1-size2')
plt.xlabel('size1')
plt.ylabel('size2')
plt.show()
# 建立一个用于筛选类别的变量
mask = data.loc[:,'y'] ==1
print(mask)

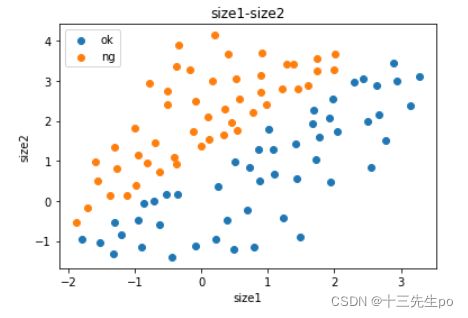
# 重新数据可视化,利用布尔筛选显示的数值
ok = plt.scatter(data.loc[:,'尺寸1'][mask],data.loc[:,'尺寸2'][mask])
ng = plt.scatter(data.loc[:,'尺寸1'][~mask],data.loc[:,'尺寸2'][~mask])
plt.title('size1-size2')
plt.xlabel('size1')
plt.ylabel('size2')
plt.legend((ok,ng),('ok','ng'))
plt.show()
# x,y赋值
x = data.drop(['y'],axis=1)
y = data.loc[:,'y']
x.head()

# 创建模型
model = LogisticRegression()
print(model)
# 模型训练
model.fit(x,y)

# 预测值
y_predict = model.predict(x)
print(y_predict)

# 预测值
y_test = model.predict([[1,10]])
print('ok' if y_test == 1 else 'ng')

二阶项及以上项式的边界函数计算和绘制
如果想输出这样的边界函数

需要用到的g(x)函数就会变成如下图的二阶边界函数


而二阶函数其实也是一个二次函数(抛物线方程),数值方面可以进行变成,变成如下图的:

二阶多项式逻辑回归案例
就是有更多的θ,画的边界曲线也更加复杂,如
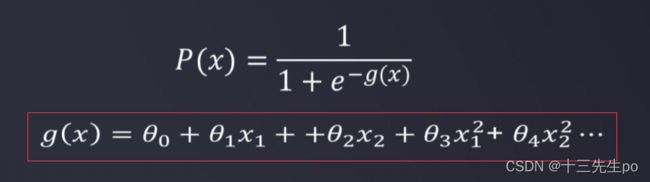
尝试用一阶函数画出边界
边界函数: 0+11+22=0
二阶边界函数: 0+11+22+321+422+512=0
#数据加载
import pandas as pd
import numpy as np
data = pd.read_csv('task2_data.csv')
data.head()

#数据可视化
from matplotlib import pyplot as plt
fig1= plt.figure()
plt.scatter(data.loc[:,'pay1'],data.loc[:,'pay2'])
plt.title('pay1_pay2')
plt.xlabel('pay1')
plt.ylabel('pay2')
plt.show()

#创建mask
mask= data.loc[:,'y']==1
print(mask)

fig1= plt.figure()
abnormal = plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal = plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.title('pay1_pay2')
plt.xlabel('pay1')
plt.ylabel('pay2')
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()

#X y赋值
X = data.drop(['y'],axis=1)
y = data.loc[:,'y']
X.head()
y.head()
print(X.shape,y.shape)

#建立线性边界分类模型
from sklearn.linear_model import LogisticRegression
LR1 = LogisticRegression()
LR1.fit(X,y)

#模型预测
y_predict = LR1.predict(X)
print(y_predict)
print(y)

#准确率计算
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
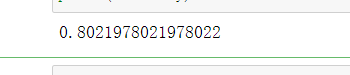
准确率挺高的,但是我们来看一下实际画出的线
#边界函数参数获取
theta0 = LR1.intercept_
theta1,theta2 = LR1.coef_[0][0],LR1.coef_[0][1]
print(theta0,theta1,theta2)

X1 = data.loc[:,'pay1']
print(X1)
X2_new = -(theta0+theta1*X1)/theta2
print(X2_new)

fig2= plt.figure()
abnormal = plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal = plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.plot(X1,X2_new)
plt.title('pay1_pay2')
plt.xlabel('pay1')
plt.ylabel('pay2')
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()

其实并没有很好的输出分类情况,这个时候就要用二阶的边界函数进行计算绘制
二阶项逻辑回归

# 对x2进行赋值
X2 = data.loc[:,'pay2']
X2
# 生成二次项
X1_2 = X1*X1
X2_2 = X2*X2
X1_X2 = X1*X2
print(X1_2.shape,X2_2.shape,X1_X2.shape)
# 检查
print(X1[0],X2[0],X1_2[0],X2_2[0],X1_X2[0])

# 创建二次分类边界数据
X_new = {'X1':X1,'X2':X2,'X1_2':X1_2,'X2_2':X2_2,'X1_X2':X1_X2}
X_new = pd.DataFrame(X_new)
X_new
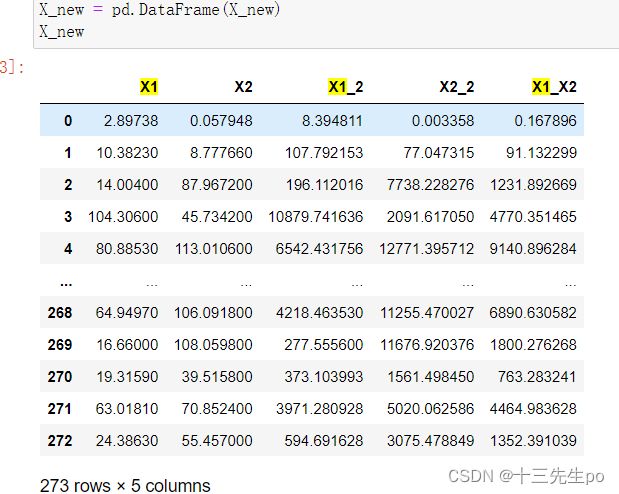
# 建立新模型
LR2 = LogisticRegression()
LR2.fit(X_new,y)

# 模型预测
y2_predict = LR2.predict(X_new)
print(y2_predict)

# 准确率
accuracy2 = accuracy_score(y,y2_predict)
print(accuracy2)
# 二阶的效果明细要比一阶的好

#边界函数参数获取
theta0 = LR2.intercept_
theta1,theta2,theta3,theta4,theta5 = LR2.coef_[0][0],LR2.coef_[0][1],LR2.coef_[0][2],LR2.coef_[0][3],LR2.coef_[0][4]
print(theta0,theta1,theta2,theta3,theta4,theta5)
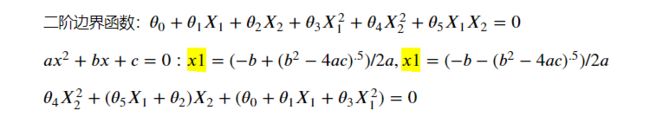
# x1需要排序,否则画图比较乱
X1_new = X1.sort_values()
X1_new

a = theta4
b = theta5*X1_new + theta2
c = theta0+theta1*X1_new+theta3*X1_new*X1_new
x2_new_2 = (-b+np.sqrt(b*b-4*a*c))/(2*a)
print(x2_new_2)
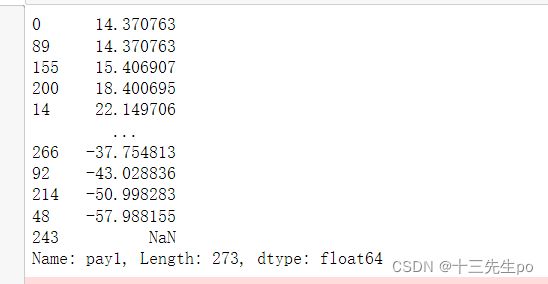
fig2= plt.figure()
abnormal = plt.scatter(data.loc[:,'pay1'][mask],data.loc[:,'pay2'][mask])
normal = plt.scatter(data.loc[:,'pay1'][~mask],data.loc[:,'pay2'][~mask])
plt.plot(X1_new,x2_new_2)
plt.title('pay1_pay2')
plt.xlabel('pay1')
plt.ylabel('pay2')
plt.legend((abnormal,normal),('abnormal','normal'))
plt.show()

预测值需要这么多数值是因为函数问题,需要的参数有5个

# 预测
x_test = np.array([[80,20,80*80,20*20,80*20]])
# 第二个模型预测
y_predict = LR2.predict(x_test)
print(y_predict)
K近邻分类模型(K-nearest neighbors)
物以类聚,人以群分
通过计算新数据与训练数据之间的距离,然后选取K(K>=1个距离最近的邻居进行分类判断(K个邻居), 这K个邻居的多数属于某个类,就把该新数据实例分类到这个类中。(看看我周围的伙伴是什么类型的)
- 案例

K=3,绿色圆点(50,50)的最近的3个邻居是2个红色小三角形(60,50)、(50,60)和1个蓝色小正方形(40,40),判定其属于红色的三角形一类。
K=5,绿色圆点的最近的5个邻居是2个红色三角形(60,50)、K=5(50,60)和3个蓝色的正方形(40,40)、(40,80)、(30,60),判定其属于蓝色的正方形一类。
K值是认为给的
我和谁一队?看看你周围哪个队的人多!
K近邻分类模型算法步骤
输入:训练数据集D={(x1. Y1)。。。(xm,ym)}
xi为数据的特征向量,yi代表数据所属类别;对于新样本数据Xtest:
(1)计算训练数据集每个样本x;与新的样本数据xtest的距离di-test;
(2)将计算出的距离按照升序排列,并取出前K个距离最小的样本;
(3)统计这K个样本的标签值y,并找出出现频率最高的标签;
(4)新的样本数据xtest的标签值ytest即为该频率最高的标签值。
- 计算距离的方法
欧氏距离:两点之间的直线距离,KNN计算中应用最多的距离。

曼哈顿距离:两个点在标准坐标系上的绝对轴距总和

- K值越小,分类边界越曲折,抗干扰性更弱(噪声数据影响结果明显)
k=1时,分界会很明显,可能会对结果造成影响,虽然很精确

决策树
- 案例
根据求职者的相应技能、工作经验、学历背景和薪资要求判断能否安排该求职者面试。
逻辑回归的做法,把他们变成参数代入进行并使用激励函数simgod分类

决策树则是问不同的问题,一步一步走下去
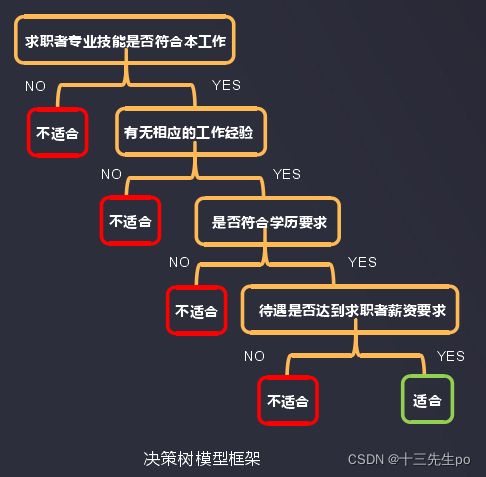
问:求职者是否有本岗位相应的专业技能?
答:有
问:求职者是否有本岗位相关的工作经验?
答:有
问:求职者是否符合学历要求?
答:符合
问:公司给出的待遇是否达到求职者薪资要求?
答:达到
结论:该求职者可以安排面试
决策树原理
一种基于样本分布概率,以树形结构的方式,实现多层判断从而确定目标所属类别

根据数据集D的分布,生成树形结构,实现最终类别判断
核心问题:树结构的每个分支先看哪个特征指标?
有这么多列,该先从哪一列开始看起呢?

- 三种求解方法:
ID3、C4.5、CART
参考资料:
1、https://blog.csdn.net/dfly_zx/article/details/107797695
2、https://blog.csdn.net/dfly_zx/article/details/107797864
ID3算法
ID3是利用信息熵原理选择信息增益最大的属性作为分类属性,依次确定决策树的分枝,完成决策树的构造
信息熵(entropy)是度量随机变量不确定性的指标,熵越大,样本的不确定性就越大。假定当前样本集合D中第k类样本所占的比例为pk,则D的信息熵为
Ent(D)的值越小,样本分布的不确定性越小。其实通过pk也可以看到他的不确定性,当pk=0或者1时(即样本完全确定)Ent(D)=0
根据信息熵,可以计算以属性a进行样本划分带来的信息增益:V为根据属性a划分出的类别数(注意和信息熵中的y区分)、D为当前样本总数,Dv为类别v样本数

![]()
目标:划分后样本分布不确定性尽可能小,即划分后信息熵小,信息增益大,例如右边的结点第一次分类出30和70后,70又分出去30和40,反而没有左边分的好

- 案例
这里有10个样本(k=10),类别有2种(y=2),

y为结果的类别,而不是k有几种,像如下图中

技能这一列得到的结果(y)只有两种:适合和不适合因此计算为

计算出信息熵后计算信息增益

拿第二列——经验做计算演示,注意不要搞混y的比例和D中v的比例(y为总类别的不同,v为各列中不同属性值,可以明显的看到计算时分母有变化)


总的计算结果如图

实战:决策树判断员工是否适合相关工作
- 导入文件
import pandas as pd
import numpy as np
data = pd.read_csv('task1_data.csv')
data.head()

# x,y赋值
x = data.drop(['y'],axis=1)
y = data.loc[:,'y']
y.head()

- 检查结构是否正确
print(x.shape,y.shape)

- 创建决策树模型
# 创建决策树模型
from sklearn import tree
# criterion='entropy':以信息嫡的变化作为建立树结构的标准
# min_samples_leaf=5:建立树结构最小分支的样本数(最少也得有5个样本)
dc_tree = tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=5)
dc_tree.fit(x,y)

- 测试
# 测试
x_test = np.array([[1,0,1,1]])
y_test = dc_tree.predict(x_test)
print('yes' if y_test == 1 else 'no')

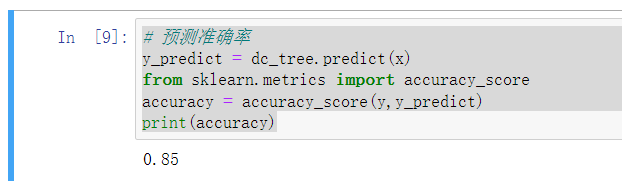
- 预测准确率
# 预测准确率
y_predict = dc_tree.predict(x)
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
- 可视化决策树结构(图片过大,可以保存下来看)
# 可视化决策树结构
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(200,200))
# filled是否填充颜色,feature_names属性名称,各指标名称;class_name对应结果
tree.plot_tree(dc_tree,filled='True',feature_names=['Skill','Experience','Degree','Income'],class_names=['Un-qualified','Qualified'])

- 中文化
# 中文化
import matplotlib as mpl
mpl.rcParams['font.family']='SimHei'
fig1 = plt.figure(figsize=(200,200))
# feature_names结构名称,各指标名称;class_name对应结果
tree.plot_tree(dc_tree,filled='True',feature_names=['技能','经验','学历','薪资'],class_names=['不适合','适合'])

- 模型保存
# 模型保存
fig.savefig('test1.png')
修改leaf参数查看效果,改最小50个样本
- 修改leaf参数查看效果,改最小50个样本
# 修改leaf参数查看效果,改最小50个样本
dc_tree2 = tree.DecisionTreeClassifier(criterion='entropy',min_samples_leaf=50)
dc_tree2.fit(x,y)

- 预测准确率
# 预测准确率
y_predict2 = dc_tree2.predict(x)
from sklearn.metrics import accuracy_score
accuracy2 = accuracy_score(y,y_predict2)
print(accuracy2)

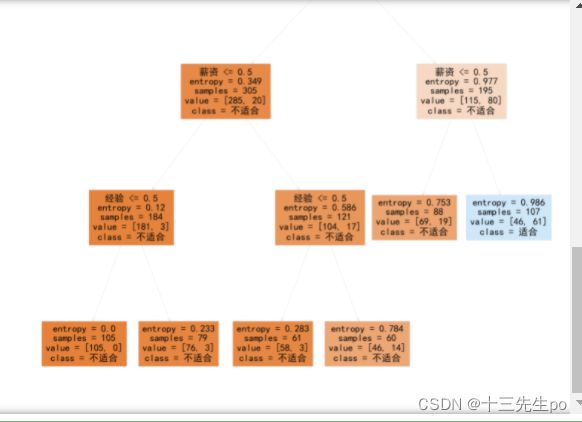
- 可视化决策树结构
# 可视化决策树结构
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(200,200))
# filled是否填充颜色,feature_names属性名称,各指标名称;class_name对应结果
tree.plot_tree(dc_tree2,filled='True',feature_names=['Skill','Experience','Degree','Income'],class_names=['Un-qualified','Qualified'])

- 中文化
# 中文化
import matplotlib as mpl
mpl.rcParams['font.family']='SimHei'
fig2 = plt.figure(figsize=(200,200))
# feature_names结构名称,各指标名称;class_name对应结果
tree.plot_tree(dc_tree2,filled='True',feature_names=['技能','经验','学历','薪资'],class_names=['不适合','适合'])
- 模型保存
# 模型保存
fig2.savefig('test2.png')
朴素贝叶斯
分类任务中,逻辑回归模型直接预测的结果是某种情况对应的概率。机器预测出来的就是某个概率

市场交易预测中,操作建议基于股票价格的涨、跌的概率。

参考链接:
https://blog.csdn.net/dfly_zx/article/details/104461097
条件概率
- 两个白球、两个黑球,从中抽取一个,如果为白球,退还下注并奖励1.1倍,玩家是否应该下注?如果抽取的第一个为白球并且不放回,游戏继续,玩家是否应该下注?
按照题意,解题思路如下,如果是第一种情况,就是拿白球:

长久来看是有收益的,如果是第二种情况,会是负的:

由此我们引申出条件概率:
定文∶事件A已经发生的条件下事件B发生的概率,表示为P(B|A)
刚刚的计算我们引入这个公式,可以得到相同的答案:

全概率
- 两个箱子中,第一箱装有4个黑球1个白球,第二箱装有3个黑球2个白球,现任取一箱,再从该箱中任取一球,试求:取出的球是白球的概率。

- 我们引申出全概率的定义:将复杂事件A的概率求解问题,转化为在不同情况下发生的简单事件的概率的求和问题。
变成B1发生的情况下,A发生的概率,随着不同事件Bi的出现,

对于事件Bi来说:

就可以写成是子事件的概率之和

原来的计算方式

也可以变成:事件A为拿到白球,B12分别是拿到第1,2个箱子

- 练习:有三个盒子甲乙丙,甲装了两个红球,乙装了一红一蓝两个球,丙装了两个蓝球。随机取一个盒子,从该盒子中随机取一个球,计算是红球的概率。如果第一个球确实是红球,求该盒子中另一个球也是红球的概率?

贝叶斯
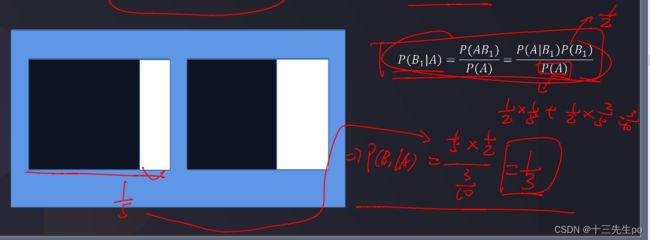
- 案例:两个箱子中,第一箱装有4个黑球1个白球,第二箱装有3个黑球2个白球,现任取一箱,再从该箱中任取一球为白球,试求:取出的球是第一个箱子的概率。
案例转化:该箱子为第1个箱子的事件记为事件B1,
去出来为白球的事件记为事件A,相当于计算P(B1|A)

转化一下可以得到:


计算的结果为:
贝叶斯公式

核心:基于事件先验概率,及可能性函数(事件发生的约束条件),得到特定情况下事件发生的概率(后验概率)
- 案例:猫对你叫,猫喜欢你的概率是多少?
已知:猫喜欢一个人的概率是0.1,它对喜欢的人叫的概率是0.4,它平时叫的概率是0.2
转化一下问题就是,在猫对你叫(A)的情况下,喜欢你(B)的概率,求P(B|A)
再将已知的条件转化一下,计算出结果

贝叶斯用于机器训练
基于训练数据集(X,Y)与贝叶斯概率公式,机器学习从输入到输出的概率分布,计算求出使得后验概率最大的类别作为预测输出。


朴素贝叶斯公式
现实案例的输入特征高于1维,假设特征之间相互独立:

贝叶斯和朴素贝叶斯公式的关系如下两张图(后一张图是自己的理解)

y是输出的结果,如y=0或者y=1

- 案例

手写计算

总结

概率是反映随机事件出现的可能性大小的量度
条件概率则是给定某事件A的条件下,另一事件B发生的概率。
全概率公式则是利用条件概率,将复杂事件A分割为若干简单事件概率的求和问题。
贝叶斯公式则是利用条件概率和全概率公式计算后验概率。
实战:朴素贝叶斯预测学生录取及奖学金情况
- 文件读取
data2 = pd.read_csv('task2_data.csv')
data2.head()

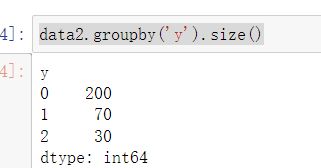
- x,y赋值
# x,y赋值
x2 = data2.drop(['y'],axis=1)
y2 = data2.loc[:,'y']
data2.groupby('y').size()
y2.head()
- 查看维度
print(x2.shape,y2.shape)

- 创建朴素贝叶斯模型
# 创建朴素贝叶斯模型
from sklearn.naive_bayes import CategoricalNB
model = CategoricalNB()
model.fit(x2,y2)

- 概率预测
# 概率预测
y_predict_prob = model.predict_proba(x2)
print(y_predict_prob)
# 有三种结果,分别对应三种概率,0没有录取,1录取了也奖学金,2录取了有奖学金

- 类别预测
# 类别预测
y2_predict = model.predict(x2)
print(y2_predict)
- 预测准确率
# 预测准确率
from sklearn.metrics import accuracy_score
accuracy2 = accuracy_score(y2,y2_predict)
print(accuracy2)

- 测试数据集预测
# 测试数据集预测
x2_test = np.array([[2,1,1,1,1],
[2,1,1,1,0],
[2,1,1,0,0],
[2,1,0,0,0],
[2,0,0,0,0]])
# 预测的概率
y2_test_predict_proba = model.predict_proba(x2_test)
# 预测的结果
y2_test_predict = model.predict(x2_test)
# 不符合项增加,无奖学金录取的概率(第二列)在增加
print(y2_test_predict)

y2_test_predict_proba
# 录取但不获奖(第二列)的概率在不断降低

- 确认存储的数据:测试样本,预测的概率,预测的结果
# 确认存储的数据:测试样本,预测的概率,预测的结果
x2_test
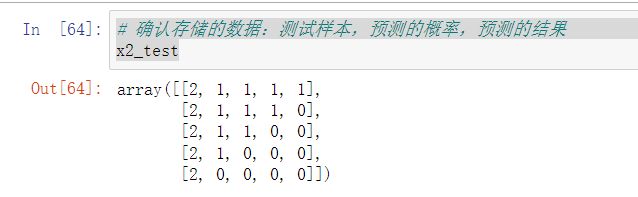
y2_test_predict_proba

- 该列需要置换一下,没有列维度
y2_test_predict,y2_test_predict.shape

# y2_test_predict没有列维度,需要reshape重置一下
test_data_result = np.concatenate((x2_test,y2_test_predict_proba,
y2_test_predict.reshape(5,1)),axis=1)
- 格式转换
# 格式转换
test_data_result2 = pd.DataFrame(test_data_result)
test_data_result2.head()

- 修改列名
test_data_result2.columns = ['score','school','award',
'gender','english','p0','p1','p2','y_test_predict']
test_data_result2.head()

- 保存文件
test_data_result2.to_csv('test_data_result2.csv')
K-means聚类分析
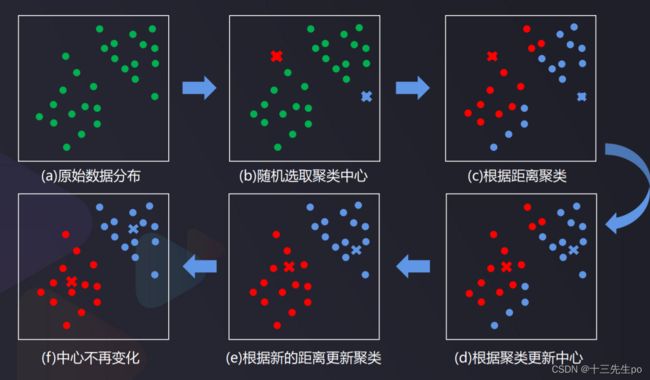
在样本数据空间中选取K个点作为中心,计算每个样本到各中心的距离,根据距离确定数据类别,是聚类算法中最为基础但也最为重要的算法。
- 中心点会根据类别内样本数据分布进行更新

核心流程

- 核心公式

- 可视化流程
K均值聚类 (KMeans) VS K近邻分类 (KNN)
实战1:普通数值类数据分类
- 调入库
import pandas as pd
import numpy as np
- 导入文件
#无结果的数据
data1 = pd.read_csv('task1_data1.csv')
# 有结果的数据
data1_result = pd.read_csv('task1_data2.csv')
data1.head()


- 获取唯一一个有标签的数据点
# 获取唯一一个有标签的数据点
x_label = data1.iloc[0,:]
x_label
- 获取用于模型评估的正确结果
# 获取用于模型评估的正确结果
y = data1_result.loc[:,'y']
y.head()
- 数据可视化
# 数据可视化
from matplotlib import pyplot as plt
import matplotlib as mlp
font2 = {'family':'SimHei','weight':'normal','size':14}
# 创建画布
fig1 = plt.figure()
# 绘制
plt.scatter(data1.loc[:,'x1'],data1.loc[:,'x2'],label='unlabeled')
# 将带有标签的点单独画出
plt.scatter(x_label['x1'],x_label['x2'],label='labeled')
plt.title('原始数据分布',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend(loc='upper left')
plt.show()

- 和已经带结果的数据对比一下
# 已经带结果的数据可视化
# 创建画布
fig2 = plt.figure()
# 绘制
label0 = plt.scatter(data1_result.loc[:,'x1'][y==0],data1_result.loc[:,'x2'][y==0],label='labeled1')
# 将带有标签的点单独画出
label1 = plt.scatter(data1_result.loc[:,'x1'][y==1],data1_result.loc[:,'x2'][y==1],label='labeled2')
plt.title('label_data',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend((label0,label1),('label0','label2'),loc='upper left')
plt.show()

- 模型建立与训练
# 模型建立与训练
# 去掉y值,保留两个特征列
x = data1.drop(['y'],axis=1)
from sklearn.cluster import KMeans
# n_clusters类别数,init初始中心点寻找方式,random_state随机状态为0才能重复结果
KM = KMeans(n_clusters=2,init='random',random_state=0)
KM.fit(x)

- 查看聚类中心
# 查看聚类中心
centers = KM.cluster_centers_
print(centers)

- 重新可视化,并将中心点也绘制出来
# 创建画布
fig2 = plt.figure()
# 绘制
label0 = plt.scatter(data1_result.loc[:,'x1'][y==0],data1_result.loc[:,'x2'][y==0],label='labeled1')
# 将带有标签的点单独画出
label1 = plt.scatter(data1_result.loc[:,'x1'][y==1],data1_result.loc[:,'x2'][y==1],label='labeled2')
# 加入中心点可视化
plt.scatter(centers[:,0],centers[:,1],100,marker='x',label='centers')
plt.title('原始数据分布',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend((label0,label1),('label0','label2'),loc='upper left')
plt.show()

- 结果预测
# 结果预测
y_predict = KM.predict(x)
print(pd.value_counts(y_predict),pd.value_counts(y))

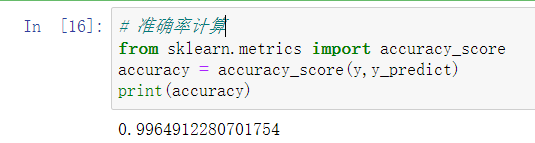
- 准确率计算
# 准确率计算
from sklearn.metrics import accuracy_score
accuracy = accuracy_score(y,y_predict)
print(accuracy)
- 创建两张图同时对比预测结果y_predict和原来的结果
# 创建两张图同时对比预测结果y_predict和原来的结果y_result
fig5 = plt.figure(figsize=(16,8))
fig3 = plt.subplot(121)
1
# 绘制已有结果的
label0 = plt.scatter(data1_result.loc[:,'x1'][y==0],data1_result.loc[:,'x2'][y==0],label='labeled1')
# 将带有标签的点单独画出
label1 = plt.scatter(data1_result.loc[:,'x1'][y==1],data1_result.loc[:,'x2'][y==1],label='labeled2')
# 加入中心点可视化
plt.scatter(centers[:,0],centers[:,1],100,marker='x',label='centers')
plt.title('原始数据分布',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend((label0,label1),('label0','label2'),loc='upper left')
fig4 = plt.subplot(122)
# 绘制计算结果的
plt.scatter(x.loc[:,'x1'][y_predict==0],x.loc[:,'x2'][y_predict==0],label='labeled1')
# 将带有标签的点单独画出
plt.scatter(x.loc[:,'x1'][y_predict==1],x.loc[:,'x2'][y_predict==1],label='labeled2')
# 加入中心点可视化
plt.scatter(centers[:,0],centers[:,1],100,marker='x',label='centers')
plt.title('预测结果',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend((label0,label1),('label0','label2'),loc='upper left')
plt.show

- 对于训练后的数据,如果直接按结果筛选的话也是可行的,尽管并没有创造这个列出来,如:
x[y_predict==0]

x.loc[:,'x1'][y_predict==0]

- 查看第一个带有正确结果标签的样本点的标签
# 查看第一个带有正确结果标签的样本点的标签
print(x_label)
print(y_predict[0])

- 由于算法的计算问题,并没有提前分类好对应值的类别,有可能出了正确的结果,但是标签却掉反了,因此需要矫正(如果有需要的话)
# 结果矫正(如果结果掉反了的话)
# y_corrected = []
# for i in y_predict:
# if i==0:
# y_corrected.append(1)
# elif i==1:
# y_corrected.append(0)
# print(y_corrected)
# print(y_predict)
# 转化成numpy结构
# y_corrected = np.array(y_corrected)
值被成功掉反

- 统计分布
# 统计分布
pd.value_counts(y_predict)

knn建模部分
用knn算法对比一下结果
- knn建模与训练
# knn建模部分
# knn建模与训练
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=3)
knn.fit(x,y)

- knn预测
# knn预测
y_predict_knn = knn.predict(x)
accuracy_knn = accuracy_score(y,y_predict_knn)
accuracy_knn

- 统计类别分布
# 统计类别分布
pd.value_counts(y_predict_knn),pd.value_counts(y)

- 创建两张图同时对比预测结果y_predict和原来的结果
# 创建两张图同时对比预测结果y_predict和原来的结果y_result
fig6 = plt.figure(figsize=(16,8))
fig7 = plt.subplot(121)
1
# 绘制已有结果的
label0 = plt.scatter(data1_result.loc[:,'x1'][y==0],data1_result.loc[:,'x2'][y==0],label='labeled1')
# 将带有标签的点单独画出
label1 = plt.scatter(data1_result.loc[:,'x1'][y==1],data1_result.loc[:,'x2'][y==1],label='labeled2')
# 加入中心点可视化
plt.scatter(centers[:,0],centers[:,1],100,marker='x',label='centers')
plt.title('原始数据分布',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend((label0,label1),('label0','label2'),loc='upper left')
fig8 = plt.subplot(122)
# 绘制计算结果的
plt.scatter(x.loc[:,'x1'][y_predict_knn==0],x.loc[:,'x2'][y_predict_knn==0],label='labeled1')
# 将带有标签的点单独画出
plt.scatter(x.loc[:,'x1'][y_predict_knn==1],x.loc[:,'x2'][y_predict_knn==1],label='labeled2')
# 加入中心点可视化
plt.scatter(centers[:,0],centers[:,1],100,marker='x',label='centers')
plt.title('knn预测结果',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend((label0,label1),('label0','label2'),loc='upper left')
plt.show
有一点点不太一样

逐步迭代查看KMeans模型训练效果
可以利用一下代码实现逐步观察中心点的变化过程
- kmeans迭代一次的结果
# kmeans迭代一次的结果
# n_init随机取了一组中心点,因为原本是同时生成几组点数进行区分;max_iter是迭代次数
km2 = KMeans(n_clusters=2,init='random',random_state=1,n_init=1,max_iter=1)
km2.fit(x)
# 中心点
centers2 = km2.cluster_centers_
y_perdict2 = km2.predict(x)
# 创建画布
fig2 = plt.figure()
# 绘制
label0 = plt.scatter(x.loc[:,'x1'][y_perdict2==0],x.loc[:,'x2'][y_perdict2==0],label='labeled1')
# 将带有标签的点单独画出
label1 = plt.scatter(x.loc[:,'x1'][y_perdict2==1],x.loc[:,'x2'][y_perdict2==1],label='labeled2')
# 加入中心点可视化
plt.scatter(centers2[:,0],centers2[:,1],100,marker='x',label='centers')
plt.title('predict_result_max_inter=1',font2)
plt.xlabel('x1',font2)
plt.xlabel('x2',font2)
plt.legend(loc='upper left')
plt.show()
此时是聚类中心计算出的第一次结果

- 逐步迭代查看KMeans模型训练效果
#逐步迭代查看KMeans模型训练效果
centers = np.array([[0,0,0,0]])
for i in range(1,10):
KM = KMeans(n_clusters=2,random_state=1,init='random',n_init=1,max_iter=i)
KM.fit(x)
centers_i = KM.cluster_centers_
centers_i_temp = centers_i.reshape(1,-1)
centers = np.concatenate((centers,centers_i_temp),axis=0)
#predict based on training data
y_predict = KM.predict(x)
#visualize the data and results
fig_i = plt.figure()
label0 = plt.scatter(x.loc[:,'x1'][y_predict==0],x.loc[:,'x2'][y_predict==0])
label1 = plt.scatter(x.loc[:,'x1'][y_predict==1],x.loc[:,'x2'][y_predict==1])
plt.title("predicted data")
plt.xlabel('x1')
plt.ylabel('x2')
plt.legend((label0,label1),('label0','label1'), loc='upper left')
plt.scatter(centers_i[:,0],centers_i[:,1],100,marker='x')
fig_i.savefig('2d_output/{}.png'.format(i),dpi=500,bbox_inches = 'tight')
可以看到聚类中心的变化过程

实战2:K均值聚类实现图像分割
图像分割就是把图像分成若干个特定的、具有独特性质的区域的技术,是由图像处理到图像分析的关键步骤。
- 最基础的实现方法:灰度阈值分割


- 导入图像学习库
from skimage import io as io
- 导入数据(任意一张图片)
img = io.imread('2.jpg')
plt.imshow(img)

- 查看数据结构与维度
# 查看数据结构与维度
print(type(img))
print(img.shape)

图片是由三个颜色通道rgb构成的
print(img)#对应的是rgb三个颜色通道上的数值

- 维度存储
# 维度存储
img_width = img.shape[1]
img_height = img.shape[0]
print(img_height,img_width)
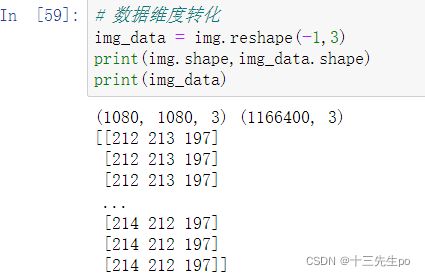
- 数据维度转化,想办法把他的维度降低,这样我们才能进行分割
# 数据维度转化
img_data = img.reshape(-1,3)
print(img.shape,img_data.shape)
print(img_data)
- x赋值
# x赋值
x = img_data
- 模型建立与训练
# 模型建立与训练
model = KMeans(n_clusters=3,random_state=0)
model.fit(x)

- 聚类结果预测
# 聚类结果预测
label = model.predict(x)
print(label)
print(pd.value_counts(label))

- 结果数据维度转化
# 结果数据维度转化
label = label.reshape([img_height,img_width])
print(label)
print(label.shape)
- 后续的灰度处理
# 后续的灰度处理
label = 1/(label+1)
print(label)
- 可视化
# 可视化
plt.imshow(label)

- 存储
# 存储
io.imsave('result_k33.png',label)
修改分类数(4)
和上面的步骤一样,只不过把分类数n_clusters修改成其他值
# 模型建立与训练
model = KMeans(n_clusters=4,random_state=0)
model.fit(x)

# 聚类结果预测
label = model.predict(x)
print(label)
print(pd.value_counts(label))

# 结果数据维度转化
label = label.reshape([img_height,img_width])
print(label)
print(label.shape)

# 后续的灰度处理
label = 1/(label+1)
print(label)

# 可视化
plt.imshow(label)
可以看到颜色分类区域更多了一些

# 存储
io.imsave('result_k34.png',label)