广州大学机器学习与数据挖掘实验一
实验一 线性回归
一、 实验目的
本实验课程是计算机、人工智能、软件工程等专业学生的一门专业课程,通过实验,帮助学生更好地掌握数据挖掘与机器学习相关概念、技术、原理、应用等;通过实验提高学生编写实验报告、总结实验结果的能力;使学生对机器学习模型、算法等有比较深入的认识。要掌握的知识点如下:
- 掌握机器学习中涉及的相关概念、模型、算法;
- 熟悉机器学习模型训练、验证、测试的流程;
- 熟悉常用的数据预处理方法;
- 掌握线性回归优化问题的表示、求解及编程。
二、基本要求
5. 实验前,复习《数据挖掘与机器学习》课程中的有关内容。
6. 准备好实验数据,编程完成实验内容,收集实验结果。
7. 独立完成实验报告。
三、实验软件
推荐使用Python编程语言(允许使用numpy库,需实现详细实验步骤,不允许直接调用scikit-learn中关于回归、分类等高层API)。
四、实验内容:
基于California Housing Prices数据集,完成关于房价预测的线性回归模型训练、测试与评估。
1 准备数据集并认识数据
下载California Housing Prices数据集https://www.kaggle.com/camnugent/california-housing-prices
了解数据集各个维度特征及预测值的含义
2 探索数据并预处理数据
观察数据集各个维度特征及预测值的数值类型与分布
预处理各维度特征(如将类别型维度ocean_proximity转换为one-hot形式的数值数据),参考:https://blog.csdn.net/SanyHo/article/details/105304292
划分70%的样本作为训练数据集,30%的样本作为测试数据集
3 求解模型参数
编程实现线性回归模型的闭合形式参数求解
编程实现线性回归模型的梯度下降参数优化
4 测试和评估模型
在测试数据集上计算所训练模型的R2指标
五、学生实验报告要求
实验报告需要包含以下几个部分
(1)简要介绍线性回归闭合形式参数求解的原理
直接让损失函数J(θ)对参数θ求偏导并令其等于0,来算出损失函数最小时的参数。即令 :
![]()
对于多元线性回归来说,拟合函数为:

损失函数为:
![]()
将拟合函数代入,并将向量表达式转化为矩阵表达式,即将![]() 写成矩阵相乘的形式:
写成矩阵相乘的形式:
![]()
令

= 0,得到:
![]()
(2)简要介绍线性回归梯度下降参数求解的原理
类似于下山,每次选定一段距离,从当前位置高度下降最快的方向走。每走一段距离,就重新确定当前高度下降最快的方向走。这个思想引入到线性回归,就是找到参数矩阵θ值使得损失函数J(θ)最小。山底就是损失函数最小的地方,求解参数矩阵θ的过程,就是人走道山底的过程。
对于多元线性回归来说,拟合函数为:
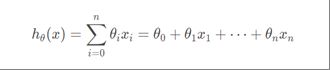
损失函数为:

损失函数的偏导数为:

θ每次更新参数的操作为

每一次θ的更新,就相当于下山走的每一段,学习率就类似下山走的步长,而损失函数的偏导数就类似于每段下山时当前位置高度下降最快的方向。
(3)程序清单(包含详细求解步骤)
①要引进的库
1. import pandas as pd
2. import numpy as np
3. import matplotlib.pyplot as plt
4. from sklearn.preprocessing import OneHotEncoder
5. from sklearn.model_selection import train_test_split
②导入数据集,观察数据特点
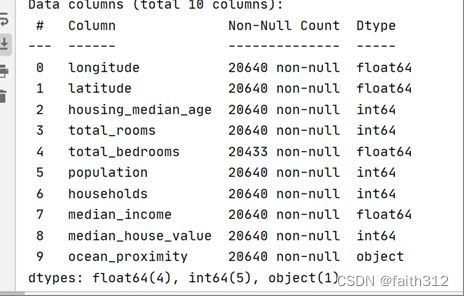
1. data=pd.read_csv("housing.csv")
2. print(data)
3. data.info()
4. print(data['ocean_proximity'].value_counts())
1. print(data)
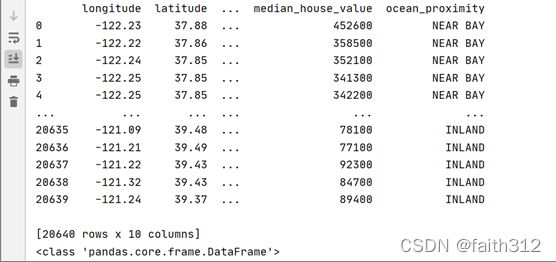
1. data.info()
1. print(data['ocean_proximity'].value_counts())

发现total_rooms的数据有207个位空值,ocean_proximity特征为object类型,特征变量之间的值不在一个相近的范围内,需要对特征变量进行特征缩放
③预处理各维度特征
1’ 将类别型维度ocean_proximity转换为one-hot形式的数值数据

2’处理维度total_rooms中的缺失值,将为缺失值的数据行从数据集中删除
![]()
3’调整数据集列位置

④划分样本(划分70%的样本作为训练数据集,30%的样本作为测试数据集)

⑤将训练集和测试集分别整理成拟合函数中的X矩阵,y矩阵和X_test矩阵,y_test矩阵
1’取出数据

X.shape:
(14303,13)
y.shape:
(14303,1)
2’只对X,X_test矩阵中的特征进行特征缩放,不对y,y_test矩阵进行特征缩放

![]()
3’X,X_test矩阵塞入一列值为1的特征列

X.shape:
(14303,14)
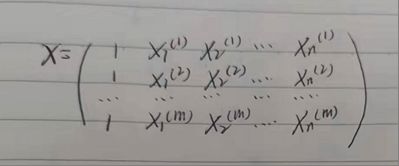
⑥准备梯度下降的数据

theta.shape:
(14,1)

⑦定义代价函数costfun()

⑧定义梯度下降函数gradient_descent()

其中@符号用于矩阵乘法
⑦定义正规方程函数

⑧求解theta及theta1并画图

得出图形如下:

⑨定义计算R^2的函数
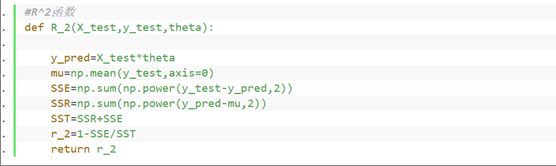
⑩在测试集、训练集上分别计算梯度下降和正规方程求得的拟合函数的R^2

结果分别为:

(4)展示实验结果,比较两种求解方式的优劣
①因为R^2 值越大代表函数的拟合程度越好,则由以上在训练集上梯度下降和正规方程求得的拟合函数的R^2分别为0.6400256017617079和0.6504027229609346得知,相比梯度下降求得的函数,正规方程的拟合程度更好。
②

输出结果如下:

会发现最小二乘法会比梯度下降求得的loss值小,因为正规方程求得的解一定是最优解,而梯度下降求得的只是局部最优解。
③由在测试集上正规方程求得的R^2
值0.6344067718662287和梯度下降求得的R^2值0.6444513749468619可知,在将由训练集训练出的拟合函数套用到测试集上进行测试是,仍是正规方程求得的函数拟合更好
④随着特征维度的上升,正规方程的计算难度会愈加复杂,不一定可解;但梯度下降是一种优化算法,总能求得局部最小值,甚至有可能逼近全局最小值。正规方程更适用于特征维度低的情况
⑤机器学习笔记中对梯度下降算法和正规方程的比较

(5)讨论实验结果,分析各个特征与目标预测值的正负相关性
计算数据集上各个特征与房价的相关系数

输出结果如下:

发现median_income特征与房价正相关,并且影响最大。
(6)源代码
使用pycharm编译器
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
data=pd.read_csv("housing.csv")
print(data)
data.info()
print(data['ocean_proximity'].value_counts())
#total_rooms的数据有207个位空值,ocean_proximity特征为object类型,特征变量之间的值不在一个相近的范围内,需要对特征变量进行特征缩放
#独热编码
s=(data.dtypes=='object')
object_cols=list(s[s].index) #['ocean_proximity']
OH_encoder=OneHotEncoder(handle_unknown='ignore',sparse=False)
OH_cols_data=pd.DataFrame(OH_encoder.fit_transform(data[object_cols]))
print(OH_cols_data)
#data1是one-hot code处理好后的数据集
num_data=data.drop(object_cols,axis=1)
data1=pd.concat([num_data,OH_cols_data],axis=1)
#处理缺失值 丢弃缺失值数据
data1=data1.dropna(axis=0,subset=["total_bedrooms"])
#调整数据集特征位置,将median_house_value特征列调换值最后一列
housing=data1.drop('median_house_value',axis=1)
housing_labels=data1['median_house_value']
#Final_data即为调整成功后的数据集
Final_data=pd.concat([housing,housing_labels],axis=1)
# #划分样本 70%训练集 30%测试集
train_set, test_set = train_test_split(Final_data, test_size=0.3, random_state=42)
#将train_set中的数据取出
col=train_set.shape[1] #col为数据行的列数
#将median_house_value单独分出给y,剩余数据给X
X=train_set.iloc[:,0:col-1]
y=train_set.iloc[:,col-1:col]
X_test=test_set.iloc[:,0:col-1]
y_test=test_set.iloc[:,col-1:col]
#将X,y分到的数据值转为矩阵类型,便于后续的计算
X = np.matrix(X.values)
y=np.matrix(y.values)
X_test = np.matrix(X_test.values)
y_test=np.matrix(y_test.values)
print(X.shape)
print(y.shape)
m = y.size
n=y_test.size
print(m)
def norm(X):
sigma = np.std(X, axis=0) # axis=0计算每一列的标准差,=1计算行的
mu = np.mean(X, axis=0)
X = (X-mu)/sigma
return X, mu, sigma
X, mu, sigma = norm(X)
X_test,mu,sigma=norm(X_test)
X = np.c_[np.ones(m), X] #矩阵合并,第一列加1
X_test=np.c_[np.ones(n),X_test]
print(X_test)
print(X)
print(X.shape)
# 初始化theta,theta1的值(其中theta用于梯度下降中,theta1用于正规方程中)
theta=(np.matrix([0,0,0,0,0,0,0,0,0,0,0,0,0,0])).T
theta1=theta
print(theta.shape)
num_iteration = 2000 #初始化迭代次数
alpha = 0.01 #初始化学习速率
#初始化一个一维向量用于存放每次迭代的代价值
J = np.zeros(num_iteration)
#定义代价函数
def costfun(theta, X=X, y=y, m=m):
h_x=X@theta
inner=np.sum(np.power(h_x-y,2))
return inner/(2*m)
#梯度下降函数
def gradient_descent(theta, alpha):
for i in range(num_iteration):
J[i]=costfun(theta,X) #将每次迭代的代价函数值计入
theta=theta-(alpha/m)*(X.T@(X@theta-y))
return theta
# '''正规方程’‘’
#定义正规方程函数
def NormalEquation(theta1):
theta1= np.linalg.inv(X.T@X)@X.T@y #求矩阵的逆
return theta1
#求解theta
theta = gradient_descent(theta, alpha)
#求解theta1
theta1=NormalEquation(theta1)
#图形表示迭代过程中代价函数的变化
plt.figure(0)
plt.plot(J) #打印代价函数-迭代次数图
plt.xlabel('Number of Iterations')
plt.ylabel('Cost Function Value')
plt.title('The Rate of Convergence')
plt.show()
#R^2函数
def R_2(X_test,y_test,theta):
y_pred=X_test*theta
mu=np.mean(y_test,axis=0)
SSE=np.sum(np.power(y_test-y_pred,2))
SSR=np.sum(np.power(y_pred-mu,2))
SST=SSR+SSE
r_2=1-SSE/SST
return r_2
#测试集上梯度下降的R2
print("测试集上梯度下降的R2:")
print(R_2(X_test,y_test,theta))
#测试集上正规方程的R2
print("测试集上正规方程的R2:")
print(R_2(X_test,y_test,theta1))
#训练集上梯度下降的R2
print("训练集上梯度下降的R2:")
print(R_2(X,y,theta))
#训练集上正规方程的R2
print("训练集上正规方程的R2:")
print(R_2(X,y,theta1))
print("梯度下降方法的代价值:")
print(costfun(theta)) #输出梯度下降方法的代价值
print("正规方程的代价值:")
print(costfun(theta1)) #输出正规方程的代价值
# print(X_test*theta)
# print(y_test)
print("theta:")
print(theta)
print("theta1:")
print(theta1)
#各变量与房价的相关系数
temp=data.copy()
corr=temp.corr()
score=corr['median_house_value'].sort_values()
print(score)