Linux正则表达式
基础的正则表达式
1.“.”(一个点)符号
点符号用于匹配除换行符之外的任意一个字符。例如:r.t可以匹配rot、rut,但是不能匹配root,若使用r…t就可以匹配root、ruut、rt(中间是
两个空格)等。下面的例子是从/etc/passwd中搜索出“包含r,紧跟着两个字符,后面再接t”的行。

2.“*”符号
“ * ” 符号用于匹配前一个字符0次或任意多次,比如ab*,可以匹配a、ab、abb等。“ * ” 号经常和 “ . ” 符号加在一起使用。比如“.*”代表任意长度的不包含换行的字符。下面的例子是试图找到连续的r字母紧跟着字母t的行。由于在/etc/passwd中没有rt、rrt这样的匹配,所以该表达式实际上只找出了包含t的行(r匹配了0次)。
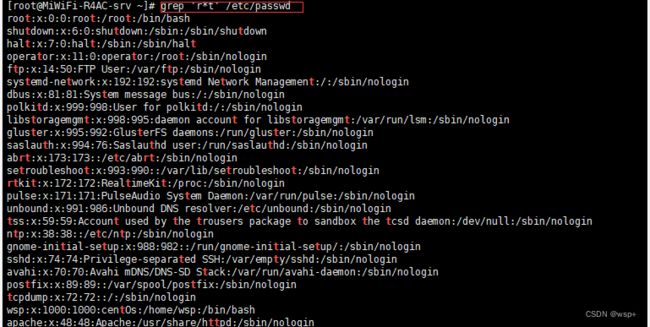
如果把上面的‘r*t’换成‘r.*t’,代表查找包含字母r,后面紧跟任意长度的字符,再跟一个字母t的行。如下所示:

3.“{n,m}”符号
虽然“*”可用于重复匹配前一个字符,但却不能精确地控制匹配的重复次数,使用“\ {n,m\ }”符号则能更加灵活地控制字符的重复次数,典型的有以下3种形式:
·\ {n\ }匹配前面的字符n次。下例匹配的是包含root的行(r和t中包含两个o)

·\ {n,\ }匹配前面的字符至少n次以上(含n次)。
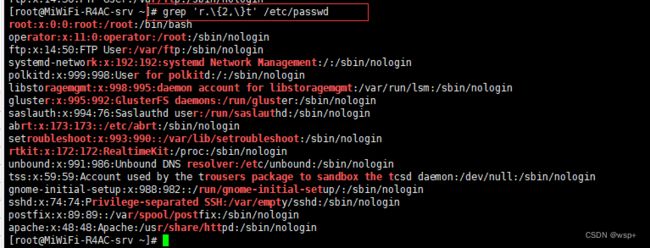
·\ {n,m\ }匹配前面的字符n到m次。
4.“^”符号
这个符号位于键盘数字6的上面,又称尖角号。这个符号用于匹配开头的字符。比如说“^root”匹配的是以字母root开始的行。
![]()
5.“$”符号
和上面的尖角号相对,“ $ ” 用于匹配尾部,比如说“abc $ ”代表的是以abc结尾的行。如果是“^ $ ”则代表该行为空,因为^和$间什么都没有。下例匹配的是以r开头,中间有一串任意字符,以h结尾的行。

6.“[]”符号
这是一对方括号,用于匹配方括号内出现的任一字符。比如说单项选择题的答案,可能是A、B、C、D选项中的任意一种,用正则表达式表示就是[ABCD]。如果遇到比较大范围的匹配,比如说要匹配任意一个大写字母,就需要使用“-”号做范围限定,写成[A-Z],要匹配所有字母则写成[A-Za-z]。一定要注意,这里“-”的作用不是充当一个字符。如果是要匹配不是大写字母A、B、C、D的字符又该怎么写呢?还记得上面的“^”号吗,如果这个符号出现在[]中,则代表取反,也就是“不是”的意思。那这里的写法就是[ ^ A-D],事情变得有点复杂了。
这里举个例子,看如何匹配手机号。手机号是11位连续的数字,第一位一定是1,所以表示为“^1”;第二位有可能是3(移动)或8(联通),
表示为“[38]”;后面连续9个任意数字,表示为“[0-9]\ {9\ }”;所以整个表达式应该写为“^1[38][0-9]\ {9\ }”。
7.“\”符号
假设有个固定电话号码021-88888888,当然也可以写成021 88888888(区号和电话号码之间用空格隔开),它们的不同之处就是区号和电话号码之间使用的符号不同,一个是“-”,一个是空格。那么,对于这个电话号码要怎么匹配呢,很容易地想到应该使用“[]”来匹配。但是这么写:[-],对吗?
答案是否定的,因为“-”放到“[]”中有特别的含义。为了表示其作为一个字符的本意,就要使用“\”符了。这个符号代表转义字符,我们可以对很多特殊的字符进行“转义”,让它只代表字符本身,因此这里的写法就应该是[\ \ -]。
再举个例子,之前我们了解到 “.* ” 代表的是任意长度的不包含换行的重复字符。但是如果想要匹配任意长度的点号呢?这时使用转义字符就对了:“\ .*”。如果想要对“\”符号进行转义,就可以这样写:“\ \”。
8.“<”符号和“>”符号
这两个符号分别用于界定单词的左边界和右边界。比如说“\

9.“\d”符号
匹配一个数字,等价于[0-9],使用grep匹配这种正则表达式时可能会遇到无法匹配的问题。示例如下:
#123
是一个数字,用[0-9]
匹配成功
[root@localhost ~]# echo 123 | grep [0-9]
123
#
但是用这种方式却匹配不成功
[root@localhost ~]# echo 123 | grep '\d'
[root@localhost ~]# #
没有输出,表示匹配不成功,为什么呢?
#
这是因为“\d
”是一种Perl
兼容模式的表达式,又称作PCRE
,要想使用这种模式的匹配符,
需要加上-P
参数
[root@localhost ~]# echo 123 | grep -P '\d'
123 #
这样就匹配成功了
10.“\b”符号
匹配单词的边界,比如“\bhello\b”可精确匹配“hello”单词。
[root@localhost ~]# echo "hello world" | grep '\bhello\b'
hello world
[root@localhost ~]# echo "helloworld" | grep '\bhello\b'
[root@localhost ~]# #
这里没有匹配
11.“\B”符号
匹配非单词的边界,比如hello\B可以匹配“helloworld”中的“hello”。
[root@localhost ~]# echo "helloworld" | grep 'hello\B'
helloworld
12.“\w”符号
匹配字母、数字和下划线,等价于[A-Za-z0-9]。
[root@localhost ~]# echo "a" | grep '\w'
a
[root@localhost ~]# echo "\\" | grep '\w'
[root@localhost ~]# #
这里没有匹配
13.“\W”符号
匹配非字母、非数字、非下划线,等价于[^A-Za-z0-9]。
14.“\n”符号
匹配一个换行符。
15.“\r”符号
匹配一个回车符。
16.“\t”符号
匹配一个制表符。
17.“\f”符号
匹配一个换页符。
18.“\s”符号
匹配任何空白字符。
19.“\S”符号
匹配任何非空白字符。
扩展的正则表达式
顾名思义,扩展的正则表达式一定是针对基础正则表达式的一些补充。实际上,扩展正则表达式比基础正则表达式多了几个重要的符号。不过要注意的是,在使用这些扩展符号时,需要使用egrep命令。
·“?”符号
“?”符号用于匹配前一个字符0次或1次,所以“ro?t”仅能匹配rot或rt。
·“+”符号
“+”符号用于匹配前一个字符1次以上,所以“ro+t”就可以匹配rot、root等。
·“|”符号
“|”符号是“或”的意思,即多种可能的罗列,彼此间是一种分支关系。比如说有些地区固定电话的区号是4位数,有些地方却是3位数,这样针对不同的区号就有不同的固定电话的表示方式,如下所示:
#
区号是3位的固定电话的正则表达式方式
^0[0-9]\{2\}-[0-9]\{8\}
#
区号是4位的固定电话的正则表达式方式
^0[0-9]\{3\}-[0-9]\{8\}
#
两种区号的固定电话号码可以如下写
^0[0-9]\{2,3\}-[0-9]\{8\}
#
使用"|"符号也可以,但是显然比上面的方式麻烦
^0[0-9]\{2\}-[0-9]\{8\}|^0[0-9]\{3\}-[0-9]\{8\}
·“()”符号
“()”符号通常需要和“|”符号联合使用,用于枚举一系列可替换的字符。比如说固定电话的区号和电话号码之间,可能用“-”符号或者用一个空格连接,用于匹配的正则表达式如下:
#
使用"()"
和"|"
定义连接符的写法
#
这样021-88888888
和0511 88888888
都可以匹配
^0[0-9]\{2,3\}(-| )[0-9]\{8\}
#
这种写法可以换用"[]"
符号表示
^0[0-9]\{2,3\}[\ \-][0-9]\{8\}
虽然以上这两种写法没有本质的不同,因为“()”和“|”可以和“[]”相互混用,但是在某些场景下,“()”和“|”可以做得更多,比如说像hard、hold或
hood等这类开头和结尾的字母都一样的单词,要匹配这些就必须使用“()”和“|”了。如下所示:
#
使用"()"
和"|"
匹配hard
、hold
或hood
h(ar|oo|ol)d