DSGN: Deep Stereo Geometry Network for 3D Object Detection---基于双目视觉的3D目标检测(1)
主要工作
- 为了弥合2D图像和3D空间之间的差距,在平面扫描体中建立立体对应关系,然后将其转换为3DGV(3D geometric volume),以便能够对3D几何体和语义线索进行编码,并能在世界坐标系中进行目标检测。
- 设计了一条端到端的pipeline,用于提取像素级特征以进行立体匹配,并提取高级特征以进行对象识别。所提出的网络联合估计场景深度和目标检测,实现了许多实际应用。
3DGV:
3DGV定义在世界坐标系中,由构造在相机截锥中的平面扫描体(PSV)转换而来。在PSV中可以很好地学习像素对应约束进行深度估计,而真实世界目标目标检测可以在3DGV学习。该结构体是完全可微的,因此可以联合优化学习立体匹配和目标检测。
方法论
主要就是对3D空间中表达形式的探索
动机
相机得到的透视图有两个缺陷:
- 近大远小,但是同一类目标也有大有小,用此估计深度不可靠。
- 透视缩短的视觉效果导致附近的3D对象在图像中缩放不均匀。一辆规则的长方体汽车看起来像一个不规则的截头体。
而在3D世界中可以规避这些问题,两种常见的3D表示:
- 基于点的表示:
通过深度预测方法生成点云的中间3D结构,并应用基于激光雷达的3D对象检测器。主要可能的缺点是涉及几个独立的网络,可能在中间转换过程中丢失信息。而且这种表示经常在物体边缘附近遇到条纹伪影。
-
基于体素的表示
-
本论文的方法:建立有效3D表示的关键取决于对3D空间的精确3D几何信息进行编码的能力。立体相机为计算深度提供了明确的像素对应约束。
为了设计一个统一的网络来利用这一约束,文章探索了能够提取立体对应的像素级特征和语义线索的高级特征的深层架构。
另一方面,假设像素对应约束沿着穿过每个像素的投影射线施加,根据三角测量原理,其中深度被认为是确定的。为此,我们从双目图像对创建一个平面扫描体( plane-sweep volume),以学习相机视锥中的立体对应约束,然后将其转换为3D空间中的3D物体。在这个三维体积中,从平面扫描体中提取了三维几何信息,我们能够很好地学习真实世界对象的三维特征。
DSGN
DSGN以双目图像对(IL,IR)为输入,通过Siamese网络提取特征并构建plane-sweep volume(PSV)。在volume中学习像素对应关系。通过相机参数,我们将PSV转换为3D几何体(3DGV),以在3D世界空间中建立3D几何体。然后,就是利用3D神经网络在3DGV中进行3D目标检测。
整个神经网络由四个部分组成。
- (a) 用于捕获像素和高级特征的2D图像特征提取器。
- (b) 构建平面扫描体PSV和三维几何体3DGSV。
- (c) 基于平面扫描体(PSV)的深度估计。
- (d) 基于三维几何体(3DGV)的三维目标检测。

(a)图像特征提取
采用了PSMNet的主要设计,并进行了一些修改,详细修改可看代码。
(b)构造3DGV
首先通过将Plane-Sweep Volume变形到三维规则空间来创建一个三维几何体(3DGV)。在不丧失一般性的前提下,我们将三维世界空间中感兴趣的区域离散为一个三维体素占用网格(Wv、Hv、Dv),网格沿相机视图的右、下、前方向分布。Wv、Hv、Dv 分别表示栅格的宽度、高度和长度。每个体素的大小 (Vw, Vh, Vd)。
Plane-Sweep Volume
在双目视觉中,使用图像对(IL,IR)来构建一个基于视差的cost volume用于计算匹配成本,该匹配成本将左图像中的像素i与水平偏移了视差d的右图像IR中的对应像素相匹配。深度与视差成反比。因此很远的距离很难区分物体间距离,因为二者的视差很难区分。
在构建PSV时,遵循了经典的plane sweeping,PSV是通过在左相机截头体中以等距深度(蓝色虚线)投影图像来构建的,在这个volume上应用3D卷积,然后在所有深度位置上得到关于匹配的cost volume。
补充:这里构建PSV我是比较疑惑的,之前看的MVSNET中虽然也是有一个参考图像,但是plane sweeping构建在3D空间里而不是视锥的,所有视角图片都通过单应性变换映射到不同深度位置。
而这里不一样,方法是右图映射到了一个参考图像(左图)的视锥里的不同深度平面,强调是视锥,怎么实现呢?论文没说,代码我还没看,我的理解是右图先单应变换到参考图像(左图)的对应3D空间里每个深度(假设m个深度间隔)参考面,然后这些映射后的m个图再纷纷透射到参考图像(左图)与其各个像素点对应,这样就有了m个组合,每个组合左图的特征图都是一样的,而右图有所不同。(此处理解不知道是否正确,只是不理解为什么不像MVSNET那样直接映射到3D空间里构建PSV,视锥里的好处是啥)

3D Geometric Volume
PSV是在相机视锥构建的,汽车会有畸变,因此可以在对PSV计算匹配损失前将PSV的特征图从camera frustum space(u, v, d)转换到世界坐标系(x,y,z),其中fx、fy是水平焦距和垂直焦距。

补充:这里的PSV到3DGV的转换我也有点疑惑,下面是原文,the last feature map of PSV中的last是什么意思啊?不知道他在构造psv时有咩有像经典plane sweeping那样,从后向前,如果前面深度的特征匹配得分更高,则以得分高的点进行更新,那说last我还能勉强理解,但这里似乎不是这样啊,因为说的是feature map。总不是我想复杂了,last就是时序上最后的意思?


补充:此处也说了低成本的表示匹配的概率大,那么cost是如何构造的啊,傻缺,不写我咋知道,还有在他的主流程图中,四分之一下采样的图是如何上采样构造3DGV的啊?而且3DGV的构成来源有两处输入啊,还有一处直接来自特征图,二者怎么结合的啊,好晕
Depth Regression on Plane-Sweep Cost Volume
为了在PSV上计算匹配成本,利用3D卷积对特征维降维得到1D cost Volume,Soft arg-min 被用来计算所有可能深度分布的概率σ(−Cd)
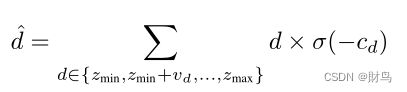
3D Object Detector on 3D Geometric Volume
采用了以往基于锚框的设置,并在3DGV上逐步下采样获得鸟瞰图F,在F的每个位置(x,z)上放了大小方向不同的初始化锚框,然后利用网络进行位置大小的回归预测。在样本进行分配时利用了一个距离定义,即锚框的八个角的距离:
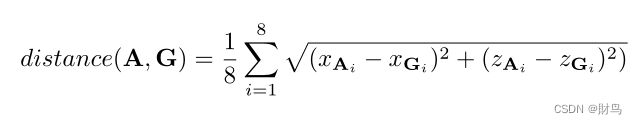
为了平衡正样本和负样本的比例,我们让距离ground truth最近的前N个锚框作为正样本,其中N=γ×k,k是鸟瞰图中地面真相框内的体素数。γ调整阳性样本的数量。
Multi-task Training
立体匹配网络和3D对象检测器网络以端到端的方式进行训练。3D对象检测器损失定义为:


ND is the number of pixels with ground-truth depth

Npos denotes the number of positive samples

Fpos denotes all positive samples on bird’s eye view
在进行回归时采用了两种不同的regression targets(有无联合优化)
Separably optimizing box parameters:在进行行人和自行车损失 优化时用了这个
Jointly optimizing box corners:在其他目标都使用了联合优化
相关学习:
【A】讲述了单目视觉深度估计----DORN(64条消息) 三维视觉论文阅读:DORN2018单目深度估计_yanqs_whu的博客-CSDN博客_dorn网络【B】讲述了多视角图像进行三维重建---MVSNet
理解MVSnet_朽一的博客-CSDN博客_mvsnet
【C】三维重建算法-plane sweep,对平面扫描进行了详细的介绍
三维重建之平面扫描算法(Plane-sweeping)_小玄玄的博客-CSDN博客_plane sweep
【D】对于C中的公式对应变量看不懂时,看这篇论文,他的公式都是这里截取的
Real-Time Plane-Sweeping Stereo with Multiple Sweeping Directions
【E】该论文代码:github.com