使用Pandas处理美国人口数据
本次实验目的是对pandas库进行运用,使用了pandas的读写文件、级联、空值处理、查询语句、数据处理等功能
一、pandas模块导入
Pandas库是一个免费、开源的第三方Python库,是Python数据分析必不可少的工具之一,它为Python数据分析提供了高性能,且易于使用的数据结构,即Series和DataFrame。
使用pip install pandas进行安装,import pandas as pd语句进行模块导入。
二、人口数据下载
美国人口数据可在GitHub - jakevdp/data-USstates: Collection of CSV data on US states for Pandas merge demos进行下载,所需文件如下。

三、人口数据处理
1、级联以及级联后的数据处理
使用read_csv读取文件。
areas = pd.read_csv('state-areas.csv')
abbr = pd.read_csv('state-abbrevs.csv')
pop = pd.read_csv('state-population.csv')
将人口文件和州名缩写文件进行级联。按照州的缩写这一列,对pop和abbr进行合并,分别依据state/region列和abbreviation列进行一对多合并。为了保留所有信息,使用外合并,left_on和right_on指定合并列。但使用外合并,数据不会丢失,却会存在空值。
pop2 = pd.merge(pop, abbr, how='outer', left_on='state/region', right_on='abbreviation')
使用info查看空值。
print(pop2.info())
输出结果如下。
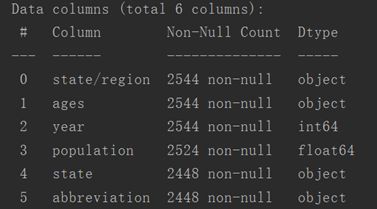
因为state/region列和abbreviation列重复,所以可删除一列,可以看出abbreviation列有空值,所以删除abbreviation列。inplace的意思是直接在pop2上进行数据更改,不会创建新数据。
pop2.drop(labels='abbreviation', axis=1, inplace=True)
pop2.to_excel('pop2.xlsx')
使用isnull().any(),只有某一列存在一个缺失数据,就会显示TRUE
print(pop2.isnull().any())
输出结果如下。

可以发现,人口列和州名列均有空值,人口列没有办法补全,州名可以,现在我们来补全州名。
首先查看州这一列哪些行为空值。
cond = pop2['state'].isnull()
print(cond)
输出结果如下。
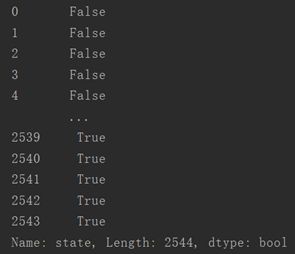
可以发现只有‘USA’和‘PA’这两个州有空值。
写入表中结果如下。
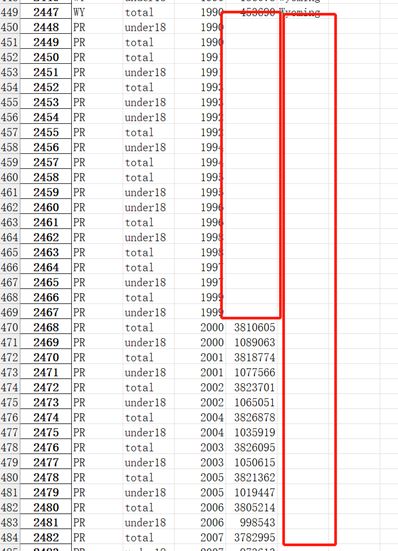
2、空值处理
现在进行数据填充,根据数据是否缺失情况显示数据,如果缺失为True,那么显示。寻找’state/region‘列中等于PR的数据。
cond1 = pop2['state/region'] == 'PR'
进行赋值。
pop2['state'][cond1] = 'Puerto Rico'
同理对USA列数据进行填充。
填充后写入表中结果如下。

查看population的空值,删除population为空的行。
cond = pop2['population'].isnull()
pop2.dropna(inplace=True)
写入文件
pop2.to_excel('pop3.xlsx')
输出结果如下。

可以看出空的人口数据行被删除。
3、三个文件进行级联以及空值填充
将面积文件合并,使用左合并。
pop4 = pd.merge(pop2, areas, how='outer')
继续寻找空数据。
print(pop4.isnull().any())
输出结果如下。

发现area(sq. mi)这一列有缺失数据,为了找出是哪一行,需要找出哪个state没有数据。
cond = pop4['area (sq. mi)'].isnull()
pop4[cond]的意思是输出cond为true时的行,发现是usa没有数据。
print(pop4[cond])
输出结果如下。


因为usa的面积是各个州面积之和,所以可以计算各州面积和。
sum_area = areas['area (sq. mi)'].sum()
填充空数据,因为空数据均为USA的,所以使用fillna函数。并且写入文件。
pop4.fillna(sum_area, inplace=True)
pop4.to_excel('pop4.xlsx')
pop4.xlsx文件如下。

4、人口数据处理
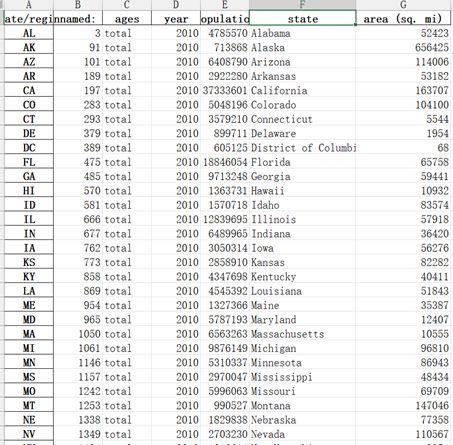
选择对2010年的全国人口数据进行处理。首先使用查询语句找出各个州的2010年人口数据。
pop_2010 = pop4.query("year == 2010 and ages == 'total'")
对查询结果进行处理,以state/region列作为新的行索引,此处使用set_index函数
pop_2010.set_index('state/region', inplace=True)
写入‘pop2010.xlsx’文件。
pop_2010.to_excel('pop2010.xlsx')
输出结果如下。
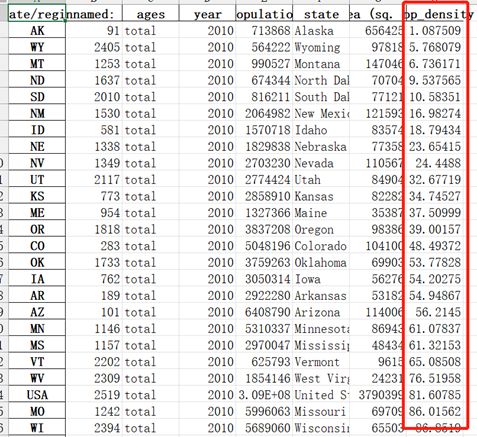
计算人口密度,注意此时接收的pop_density类型是Series
pop_density = pop_2010['population']/pop_2010['area (sq. mi)']
此时的pop_density是series,要将其转换为DateFrame才能合并。
pop_density = DataFrame(pop_density, columns=['pop_density'])
result = pd.merge(pop_2010, pop_density, left_index=True, right_index=True)
写入文件。
result.to_excel('result.xlsx')
输出结果如下。

最后按照人口密度进行排序。
result.sort_values(by='pop_density', inplace=True)
result.to_excel('result.xlsx'