【Python实战】听书就用它了:海量资源随便听,内含几w书源,绝对精品哦~(好消息好消息)
前言
有温度 有深度 有广度 就等你来关注哦~

所有文章完整的素材+源码都在
粉丝白嫖源码福利,请移步至CSDN社区或文末公众hao即可免费。
哈喽!我是栗子同学,继续更新——今天聊一聊“西马拉雅”。(谐音梗不然爬不了拉)
PS——小故事
“西马拉雅”——地球上最高大的山脉,8848 米的巅峰,几乎要碰触太空,75 座 7000 米级雪山,
俯瞰地球所有地方,平均海拔 4000 米的高原,垂直高度 5000 米的峡谷,孕育出世界上最多
样的动植物群落。搞错了,再来

今天讲的西马拉雅听书是一款手机听书软件,这货的好评是名不虚传的,分类明确的到了各个
领域,今天,小编就来用代码给大家扒一扒那些数据,让大家实现听书自由。
正文
一、运行环境
1)Python环境
环境: Python 3 、Pycharm、requests 、re 。re内置模块,安装 好python环境就可以了。
(win + R 输入cmd 输入安装命令 pip install 模块名 (如果你觉得安 装速度比较慢, 你可
以切换国内镜像源))
第三方库的安装:pip install + 模块名 或者 带镜像源 pip install -i pypi.douban.com/simple/ +模块名
2) 爬虫基本流程思路
一. 数据来源分析:
1. 明确需求: - 采集什么数据? 音频名字, 音频播放链接 url
2. 抓包分析, 分析我们想要数据内容, 它是来自于哪里 抓包分析 --> 通过浏览器<谷歌>自带工
具: 开发者工具 - 打开开发者工具: F12 或者 鼠标右键点击检查选择network - 刷新网页 --->
让本网页数据内容重新加载一遍 <可以看到相应的数据包> - 分析 音频播放链接 在什么地方 点
击播放 ---> media 里面就有音频播放链接:
https://aod.cos.tx.xmcdn.com/group31/M00/21/93/wKgJX1mBk5uisCN6ARUZGpfUCIk519-aacv2-48K.m4a
- 继续分析 这个 音频播放链接 是从什么地方生成的 ---> 生成数据包 通过搜索
wKgJX1mBk5uisCN6ARUZGpfUCIk519-aacv2-48K
找到相应数据包 音频数据包:
https://www.ximalaya.com/revision/play/v1/audio?id=45982639&ptype=1
通过两个音频数据包请求url地址对比 ---> 主要改变 ID
只要获取所有音频ID, 就可以获取所有音频播放链接 -
通过搜索 ID 找到ID所在的地方 ---> 在什么地方可以获取到所有音频ID
https://www.ximalaya.com/album/9723091 <音频列表页面>
目的: 获取音频播放链接 --> 音频数据包 ---> 需要传入音频ID ---> 音频列表页面

二. 代码实现步骤:
基本四大步骤: 发送请求, 获取数据, 解析数据, 保存数据
1. 发送请求, 模拟浏览器对于 音频列表页面 发送请求
https://www.ximalaya.com/album/97230912. 获取数据, 获取服务器返回响应数据 开发者工具当中所看到 response
3. 解析数据, 提取我们想要的数据内容 - 音频名字 - 音频ID
4. 发送请求, 模拟浏览器对于 音频数据包 发送请求
https://www.ximalaya.com/revision/play/v1/audio?id=45982639&ptype=15. 获取数据, 获取服务器返回响应数据 开发者工具当中所看到 response
6. 解析数据, 提取我们想要的数据内容 - 音频url
7. 保存数据, 把数据内容保存本地。
二、代码展示
1)主程序
import requests
# 正则表达式模块 --> 内置模块 不需要安装
import re
"""
1. 发送请求, 模拟浏览器对于 音频列表页面 发送请求
爬虫代码, 需要伪装一下
不伪装, 可能会被反爬 --> 得不到数据, 或者得到数据不是你想要的内容
"""
# 音频列表页面
url = 'http://www.ximalaya.com/album/9723091'
# 伪装模拟 headers 请求头<字典数据类型>
headers = {
# user-agent 用户代理, 表示浏览器基本身份信息
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
# 发送请求:
# 调用requests模块里面get请求方法, 对于url地址发送请求, 并且携带上headers请求头伪装, 最后用自定义变量response接受返回数据
response = requests.get(url=url, headers=headers)
# response响应<>对象 200 状态码 表示请求成功
print(response)
"""
2. 获取数据, 获取服务器返回响应数据
开发者工具当中所看到 response
- response.text 获取响应文本数据
3. 解析数据, 提取我们想要的数据内容
- 音频名字
- 音频ID
正则表达式 --> re
调用re模块里面findall方法 --> 找到所有, 找到所有我们想要的数据内容
re.findall('匹配什么数据', '什么地方'): 从什么地方, 去匹配什么数据
- .*? 表示匹配任意字符<除了\n换行符 回车>
- \d+ 表示匹配0个或者多个数字
"""
# 音频名字
titles = re.findall('"tag":0,"title":"(.*?)","playCount"', response.text)
# 音频ID
audio_id_list = re.findall('"url":"/sound/(\d+)","duration"', response.text)
# for循环遍历, 把列表里面元素一个一个提取出来
for title, audio_id in zip(titles, audio_id_list):
"""
4. 发送请求, 模拟浏览器对于 音频数据包 发送请求
https://www.ximalaya.com/revision/play/v1/audio?id=45982639&ptype=1
5. 获取数据, 获取服务器返回响应数据
开发者工具当中所看到 response
根据开发者工具当中的response的数据显示, 可以选择不同数据获取方式
"""
# 字符串格式化方法 format 把 audio_id 传到 这个链接里面
link = f'https://www.ximalaya.com/revision/play/v1/audio?id={audio_id}&ptype=1'
# 发送请求
response_1 = requests.get(url=link, headers=headers)
# 获取数据 response.json() 获取响应json字典数据
# print(response_1.json())
"""
6. 解析数据, 提取我们想要的数据内容
- 音频url
根据字典取值: 键值对取值, 根据冒号左边的内容[键], 提取冒号右边的内容[值]
7. 保存数据
"""
audio_url = response_1.json()['data']['src']
# 对于 音频链接 发送请求, 获取数据
audio_content = requests.get(url=audio_url, headers=headers).content
with open('data\\' + title + '.mp3', mode='wb') as f:
f.write(audio_content)
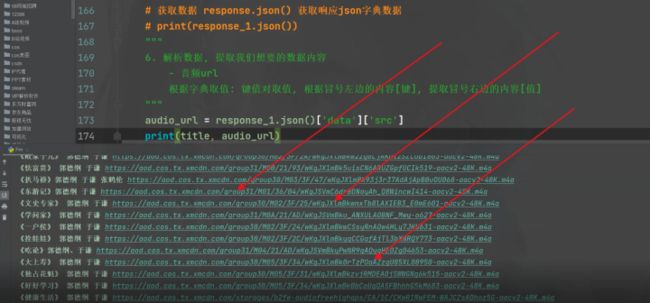
print(title, audio_url) 三、效果展示
1)展示效果1.

 1)展示效果2.
1)展示效果2.
总结
好啦!文章到这里就正式结束了哈——想我的话我们下期再见,记得三连啊哈~
✨完整的素材源码等:可以滴滴我吖!或者点击文末hao自取免费拿的哈~
推荐往期文章——
项目0.2 【Python实战】WIFI密码小工具,甩万能钥匙十条街,WIFI任意连哦~(附源码)
项目0.3 【Python实战】再分享一款商品秒杀小工具,我已经把压箱底的宝贝拿出来啦~
项目0.1 【Python抢票神器】火车票枪票软件到底靠谱吗?实测—终极攻略。
项目0.4 【Python实战】年底找工作,年后不用愁,多个工作岗位随你挑哦~
文章汇总——
Python文章合集 | (入门到实战、游戏、Turtle、案例等)
(文章汇总还有更多你案例等你来学习啦~源码找我即可免费!)
