SRCNN论文学习笔记
SRCNN是将深度学习卷积神经网络应用于单幅图像重建领域的开山之作,网络结构如下:

首先将输入原始低分辨率图像(LR),通过双三次插值放大至目标高分辨率图像(HR)尺寸,中间包括三个卷积层:图像特征提取层、非线性映射层、重建输出层,最终输出目标大小的高分辨率图像。
训练集:91张自然图像,切割为大小33×33的子图像块作为输入,因此可以分解为2-3万个子图像,LR子图像与HR标签生成一个h5文件;
验证集:set5数据集(5张图像,无需划分子图像)
图像特征提取层:64个大小为1×9×9的卷积核,padding=4(用于保证输出图像与输入图像大小相同),生成特征图大小为33×33×64,后加一个relu激活函数;
非线性映射层:32个大小为64×5×5的卷积核,padding=2,生成特征图大小为33×33×32,后加一个relu激活函数;
重建输出层:1个大小为32×5×5的卷积核,padding=2,生成大小为33×33×1的HR图像输出,该层不使用激活函数。
损失函数:MSE均方误差
此外,论文中还通过改变数据集大小、卷积核的个数、网络的深度与宽度等来测试网络性能,并寻找最优的参数设置。
还需注意输入图像前要经过一个插值操作,首先将原始图片重设尺寸,使之可以被放大倍数scale整除:
hr_width = (hr.width // args.scale) * args.scale hr_height = (hr.height // args.scale) * args.scale
其次将HR图像经过双三次插值缩小scale倍:
lr = hr.resize((hr_width // args.scale, hr_height // args.scale), resample=pil_image.BICUBIC)
最后将其通过双三次插值放大scale倍,作为与目标图像相同大小的LR图像:
lr = lr.resize((lr.width * args.scale, lr.height * args.scale), resample=pil_image.BICUBIC)
关于一些图像预处理细节:输入图片为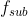 ×的子图像,无padding卷积后生成图像大小为
×的子图像,无padding卷积后生成图像大小为![]() ,其对应label为对应X的中心像素。如输入图像大小为33×33(以14步长在原图中进行等距划分),生成图像大小为(33-9-1-5+3)×(33-9-1-5+3)=21×21,则对应label大小为21×21的X中心像素(原文网络无padding,复现时大多都设置了padding以保证输入输出图像大小一致),输入网络的h5文件同时包含了LR子图像以及对应的HRlabels。测试时需使用padding以保证输入输出图像大小一致,且测试图像无需划分子图像,可以为任意尺寸。
,其对应label为对应X的中心像素。如输入图像大小为33×33(以14步长在原图中进行等距划分),生成图像大小为(33-9-1-5+3)×(33-9-1-5+3)=21×21,则对应label大小为21×21的X中心像素(原文网络无padding,复现时大多都设置了padding以保证输入输出图像大小一致),输入网络的h5文件同时包含了LR子图像以及对应的HRlabels。测试时需使用padding以保证输入输出图像大小一致,且测试图像无需划分子图像,可以为任意尺寸。
三层卷积网络的实现较为简单:
class SRCNN(nn.Module):
def __init__(self, num_channels=1):
super(SRCNN, self).__init__()
self.conv1 = nn.Conv2d(num_channels, 64, kernel_size=9, padding=9 // 2)
self.conv2 = nn.Conv2d(64, 32, kernel_size=5, padding=5 // 2)
self.conv3 = nn.Conv2d(32, num_channels, kernel_size=5, padding=5 // 2)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
x = self.relu(self.conv1(x))
x = self.relu(self.conv2(x))
x = self.conv3(x)
return x
网络测试:输入一张低分辨率图像,输出插值后的LR图像与重建后的HR图像。
