PyTorch Lightning工具学习
Pytorch Lightning是在Pytorch基础上进行封装的库(可以理解为keras之于tensorflow),为了让用户能够脱离PyTorch一些繁琐的细节,专注于核心代码的构建,提供了许多实用工具,可以让实验更加高效。本文将介绍安装方法、设计逻辑、转化的例子等内容。
PyTorch Lightning中提供了以下比较方便的功能:
multi-GPU训练
半精度训练
TPU 训练
将训练细节进行抽象,从而可以快速迭代
 Pytorch Lightning
Pytorch Lightning
1. 简单介绍
PyTorch lightning 是为AI相关的专业的研究人员、研究生、博士等人群开发的。PyTorch就是William Falcon在他的博士阶段创建的,目标是让AI研究扩展性更强,忽略一些耗费时间的细节。
目前PyTorch Lightning库已经有了一定的影响力,star已经1w+,同时有超过1千多的研究人员在一起维护这个框架。
 PyTorch Lightning库
PyTorch Lightning库
同时PyTorch Lightning也在随着PyTorch版本的更新也在不停迭代。
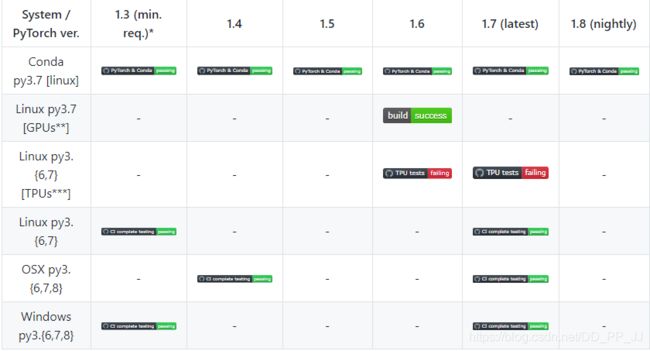 版本支持情况
版本支持情况
官方文档也有支持,正在不断更新:
 官方文档
官方文档
下面介绍一下如何安装。
2. 安装方法
Pytorch Lightning安装非常方便,推荐使用conda环境进行安装。
source activate you_env
pip install pytorch-lightning
或者直接用pip安装:
pip install pytorch-lightning
或者通过conda安装:
conda install pytorch-lightning -c conda-forge
3. Lightning的设计思想
Lightning将大部分AI相关代码分为三个部分:
研究代码,主要是模型的结构、训练等部分。被抽象为LightningModule类。
工程代码,这部分代码重复性强,比如16位精度,分布式训练。被抽象为Trainer类。
非必要代码,这部分代码和实验没有直接关系,不加也可以,加上可以辅助,比如梯度检查,log输出等。被抽象为Callbacks类。
Lightning将研究代码划分为以下几个组件:
模型
数据处理
损失函数
优化器
以上四个组件都将集成到LightningModule类中,是在Module类之上进行了扩展,进行了功能性补充,比如原来优化器使用在main函数中,是一种面向过程的用法,现在集成到LightningModule中,作为一个类的方法。
4. LightningModule生命周期
这部分参考了https://zhuanlan.zhihu.com/p/120331610 和 官方文档 https://pytorch-lightning.readthedocs.io/en/latest/trainer.html
在这个模块中,将PyTorch代码按照五个部分进行组织:
Computations(init) 初始化相关计算
Train Loop(training_step) 每个step中执行的代码
Validation Loop(validation_step) 在一个epoch训练完以后执行Valid
Test Loop(test_step) 在整个训练完成以后执行Test
Optimizer(configure_optimizers) 配置优化器等
展示一个最简代码:
>>> import pytorch_lightning as pl
>>> class LitModel(pl.LightningModule):
...
... def __init__(self):
... super().__init__()
... self.l1 = torch.nn.Linear(28 * 28, 10)
...
... def forward(self, x):
... return torch.relu(self.l1(x.view(x.size(0), -1)))
...
... def training_step(self, batch, batch_idx):
... x, y = batch
... y_hat = self(x)
... loss = F.cross_entropy(y_hat, y)
... return loss
...
... def configure_optimizers(self):
... return torch.optim.Adam(self.parameters(), lr=0.02)
那么整个生命周期流程是如何组织的?
4.1 准备工作
这部分包括LightningModule的初始化、准备数据、配置优化器。每次只执行一次,相当于构造函数的作用。
__init__()(初始化 LightningModule )prepare_data()(准备数据,包括下载数据、预处理等等)configure_optimizers()(配置优化器)
4.2 测试 验证部分
实际运行代码前,会随即初始化模型,然后运行一次验证代码,这样可以防止在你训练了几个epoch之后要进行Valid的时候发现验证部分出错。主要测试下面几个函数:
val_dataloader()validation_step()validation_epoch_end()
4.3 加载数据
调用以下方法进行加载数据。
train_dataloader()val_dataloader()
4.4 训练
每个batch的训练被称为一个step,故先运行train_step函数。
当经过多个batch, 默认49个step的训练后,会进行验证,运行validation_step函数。
当完成一个epoch的训练以后,会对整个epoch结果进行验证,运行validation_epoch_end函数
(option)如果需要的话,可以调用测试部分代码:
-
test_dataloader()
test_step()
test_epoch_end()
5. 示例
以MNIST为例,将PyTorch版本代码转为PyTorch Lightning。
5.1 PyTorch版本训练MNIST
对于一个PyTorch的代码来说,一般是这样构建网络(源码来自PyTorch中的example库)。
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
还有两个主要工作是构建训练函数和测试函数。
在训练函数中需要完成:
数据获取
data, target = data.to(device), target.to(device)清空优化器梯度
optimizer.zero_grad()前向传播
output = model(data)计算损失函数
loss = F.nll_loss(output, target)反向传播
loss.backward()优化器进行单次优化
optimizer.step()
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
def test(model, device, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
test_loss += F.nll_loss(output, target, reduction='sum').item() # sum up batch loss
pred = output.argmax(dim=1, keepdim=True) # get the index of the max log-probability
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
其他部分比如数据加载、数据增广、优化器、训练流程都是在main中执行的,采用的是一种面向过程的方法。
def main():
# Training settings
parser = argparse.ArgumentParser(description='PyTorch MNIST Example')
parser.add_argument('--batch-size', type=int, default=64, metavar='N',
help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=1000, metavar='N',
help='input batch size for testing (default: 1000)')
parser.add_argument('--epochs', type=int, default=14, metavar='N',
help='number of epochs to train (default: 14)')
parser.add_argument('--lr', type=float, default=1.0, metavar='LR',
help='learning rate (default: 1.0)')
parser.add_argument('--gamma', type=float, default=0.7, metavar='M',
help='Learning rate step gamma (default: 0.7)')
parser.add_argument('--no-cuda', action='store_true', default=False,
help='disables CUDA training')
parser.add_argument('--dry-run', action='store_true', default=False,
help='quickly check a single pass')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='random seed (default: 1)')
parser.add_argument('--log-interval', type=int, default=10, metavar='N',
help='how many batches to wait before logging training status')
parser.add_argument('--save-model', action='store_true', default=False,
help='For Saving the current Model')
args = parser.parse_args()
use_cuda = not args.no_cuda and torch.cuda.is_available()
torch.manual_seed(args.seed)
device = torch.device("cuda" if use_cuda else "cpu")
train_kwargs = {'batch_size': args.batch_size}
test_kwargs = {'batch_size': args.test_batch_size}
if use_cuda:
cuda_kwargs = {'num_workers': 1,
'pin_memory': True,
'shuffle': True}
train_kwargs.update(cuda_kwargs)
test_kwargs.update(cuda_kwargs)
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
dataset1 = datasets.MNIST('../data', train=True, download=True,
transform=transform)
dataset2 = datasets.MNIST('../data', train=False,
transform=transform)
train_loader = torch.utils.data.DataLoader(dataset1,**train_kwargs)
test_loader = torch.utils.data.DataLoader(dataset2, **test_kwargs)
model = Net().to(device)
optimizer = optim.Adadelta(model.parameters(), lr=args.lr)
scheduler = StepLR(optimizer, step_size=1, gamma=args.gamma)
for epoch in range(1, args.epochs + 1):
train(args, model, device, train_loader, optimizer, epoch)
test(model, device, test_loader)
scheduler.step()
if args.save_model:
torch.save(model.state_dict(), "mnist_cnn.pt")
5.2 Lightning版本训练MNIST
第一部分,也就是归为研究代码,主要是模型的结构、训练等部分。被抽象为LightningModule类。
class LitClassifier(pl.LightningModule):
def __init__(self, hidden_dim=128, learning_rate=1e-3):
super().__init__()
self.save_hyperparameters()
self.l1 = torch.nn.Linear(28 * 28, self.hparams.hidden_dim)
self.l2 = torch.nn.Linear(self.hparams.hidden_dim, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
x = torch.relu(self.l1(x))
x = torch.relu(self.l2(x))
return x
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
return loss
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
self.log('valid_loss', loss)
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
self.log('test_loss', loss)
def configure_optimizers(self):
return torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
@staticmethod
def add_model_specific_args(parent_parser):
parser = ArgumentParser(parents=[parent_parser], add_help=False)
parser.add_argument('--hidden_dim', type=int, default=128)
parser.add_argument('--learning_rate', type=float, default=0.0001)
return parser
可以看出,和PyTorch版本最大的不同之处在于多了几个流程处理函数:
training_step,相当于训练过程中处理一个batch的内容
validation_step,相当于验证过程中处理一个batch的内容
test_step, 同上
configure_optimizers, 这部分用于处理optimizer和scheduler
add_module_specific_args代表这部分控制的是与模型相关的参数
除此以外,main函数主要有以下几个部分:
args参数处理
data部分
model部分
训练部分
测试部分
def cli_main():
pl.seed_everything(1234) # 这个是用于固定seed用
# args
parser = ArgumentParser()
parser = pl.Trainer.add_argparse_args(parser)
parser = LitClassifier.add_model_specific_args(parser)
parser = MNISTDataModule.add_argparse_args(parser)
args = parser.parse_args()
# data
dm = MNISTDataModule.from_argparse_args(args)
# model
model = LitClassifier(args.hidden_dim, args.learning_rate)
# training
trainer = pl.Trainer.from_argparse_args(args)
trainer.fit(model, datamodule=dm)
result = trainer.test(model, datamodule=dm)
pprint(result)
可以看出Lightning版本的代码代码量略低于PyTorch版本,但是同时将一些细节忽略了,比如训练的具体流程直接使用fit搞定,这样不会出现忘记清空optimizer等低级错误。
6. 评价
总体来说,PyTorch Lightning是一个发展迅速的框架,如同fastai、keras、ignite等二次封装的框架一样,虽然易用性得到了提升,让用户可以通过更短的代码完成任务,但是遇到错误的时候,往往就需要查看API甚至涉及框架源码才能够解决。前者降低门槛,后者略微提升了门槛。
笔者使用这个框架大概一周了,从使用者角度来谈谈优缺点:
6.1 优点
简化了部分代码,之前如果要转到GPU上,需要用to(device)方法判断,然后转过去。有了PyTorch lightning的帮助,可以自动帮你处理,通过设置trainer中的gpus参数即可。
提供了一些有用的工具,比如混合精度训练、分布式训练、Horovod
代码移植更加容易
API比较完善,大部分都有例子,少部分讲的不够详细。
社区还是比较活跃的,如果有问题,可以在issue中提问。
实验结果整理的比较好,将每次实验划分为version 0-n,同时可以用tensorboard比较多个实验,非常友好。
6.2 缺点
引入了一些新的概念,进一步加大了使用者的学习成本,比如pl_bolts
很多原本习惯于在Pytorch中使用的功能,在PyTorch Lightning中必须查API才能使用,比如我想用scheduler,就需要去查API,然后发现在configure_optimizers函数中实现,然后模仿demo实现,因此也带来了一定的门槛。
有些报错比较迷,笔者曾遇到过执行的时候发现多线程出问题,比较难以排查,最后通过更改distributed_backend得到了解决。遇到新的坑要去API里找答案,如果没有解决继续去Issue里找答案。
7. 参考
【1】 https://zhuanlan.zhihu.com/p/120331610
【2】https://pytorch-lightning.readthedocs.io/en/latest/introduction_guide.html
【3】https://github.com/pytorch/examples/blob/master/mnist/main.py
【4】 https://github.com/PyTorchLightning/pytorch-lightning/blob/master/pl_examples/basic_examples/simple_image_classifier.py


