面经:卷积方面、池化方面
如何理解卷积
卷积相当于对图片进行像素级别的处理,通过卷积核在图片上滑动,能够降低图片的尺寸,加深图片的通道数,提取特征。多层深层的卷积能够更好的提取特征,这些特征将被用于深度学习的预测。
1*1的卷积核的好处?
针对每个像素点,在不同的通道数上进行线性组合(信息整合),且保留了图片原有的平面结构,调整depth,从而完成升维或者降维的功能。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力。
维度上升是为了使网络具有更好的特征表征能力,维度下降是因为让网络有更低的运算量。
膨胀卷积
膨胀卷积与普通卷积的相同点在于:卷积核的大小是一样的,在神经网络中即参数数量不变,区别在于膨胀卷积具有更大的感受野。
保持参数个数不变的情况下增大了卷积核的感受野,让每个卷积输出都包含较大范围的信息;同时它可以保证输出的特征映射(feature map)的大小保持不变。一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,但参数数量仅为9个,是5×5卷积参数数量的36%。
神经网络中,基于感受视野,感知上一层特征。感受视野越大,越易于感知全局特征。
在分割任务中,感受视野越大,越易于检测分割大目标。
卷积核大小如何选择?比如1 * 3,3 * 1代替3*3的原理?
在达到相同感受野的情况下,卷积核越小,所需要的参数和计算量越小。比如(3 * 3)的卷积叠加在一起,相比一个大的卷积(7 * 7),与原图的连通性不变,但是大大降低了参数的个数以及计算的复杂度。
kernel_size = 3, stride = 2, padding = 1的卷积会将输入图像宽高减半,因此常用作堆叠卷积操作。
depthwise卷积的原理?
不同于常规卷积操作,Depthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积。

Depthwise Convolution完成后的Feature map数量与输入层的通道数相同,无法扩展Feature map。而且这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息。
反卷积和其他上采样的缺点?棋盘格现象产生的原因?
反卷积有个比较大的问题就是,如果参数配置不当,很容易出现输出feature map带有明显棋盘状的现象。当卷积核大小不能被步长整除的时候,会出现棋盘现象。
正确的方法尝试:调整图像大小(使用最近邻插值或双线性插值),然后执行卷积操作。这似乎是一种自然的方法,大致相似的方法在图像超分辨率方面表现良好。
反卷积/转置卷积实现原理
反卷积和转置卷积都是一个意思,所谓的反卷积,就是卷积的逆操作,我们将卷积看成是输入通过卷积核的透视,那么反卷积就可以看成输出通过卷积核的透视,具体如下图所示:

我们将得到的四张特征图进行叠加(重合的地方其值相加),可以得到下图:
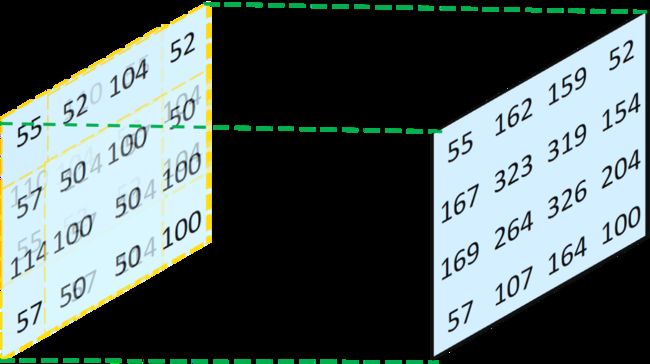
最终我们得到的特征图与卷积输入的特征图值的大小并不相同,说明卷积和反卷积并不是完全对等的可逆操作(因为采用相同的卷积核,卷积和反卷积得到的输入输出不同),也就是反卷积只能恢复尺寸,不能恢复数值。
反卷积实现原理
直接转置卷积和先上采样再卷积的区别?
常用的上采样插值方法有:最近邻插值(Nearest neighbor interpolation)、双线性插值(Bi-Linear interpolation)、双立方插值(Bi-Cubic interpolation)
我们可以利用转置卷积进行上采样,并且,转置卷积矩阵中的权值是可以学习的,所以我们不需要一个预先定义的插值方法。
3D卷积和2D卷积的区别?
3D卷积和多通道卷积差别:多通道卷积不同的通道上的卷积核的参数是不同的,而3D卷积则由于卷积核本身是3D的,所以这个由于“深度”造成的看似不同通道上用的就是同一个卷积,权重共享嘛。
总之,多了一个深度通道,这个深度可能是视频上的连续帧,也可能是立体图像中的不同切片(比如医学CT)。
三维卷积需要向三个方向滑动,分别是width、height、depth(注意这个深度不是RGB)。
在CNN卷积核上进行dropout操作的流程?
Dropout说的简单一点就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
- 首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变。
- 然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
- 然后继续重复这一过程:
CNN中池化的作用?
降低特征维度,从而减少了参数的数量,避免过拟合。
可达到降维特征、突显特征、减少参数量、减少计算量、增加非线性、防止过拟合及提升模型泛化能力等作用。
- 均值池化
对邻域内特征数值求平均,能够抑制由于邻域内大小受限造成估计值方差增大的现象,特点是对于背景的保留效果更好。 - 最大池化
选取邻域内特征的最大值,能够抑制网络参数误差造成估计均值偏移的现象,特点是更好地提取纹理信息。
步长为2的卷积替换池化层,有什么作用?
池化层是一种先验的下采样方式,即人为的确定好下采样的规则(选取覆盖范围内最大的那个值,默认最大值包含的信息是最多的);而对于步长为2的卷积层来说,其参数是通过学习得到的,采样的规则是不确定的,这种不确定性会增加网络的学习能力。
反向传播时,max-pooling怎么反向传播误差?
在反向传播时,梯度是按位传播的,那么,一个解决方法,就是如何构造按位的问题,但一定要遵守传播梯度总和保持不变的原则。
对于平均池化,其前向传播是取某特征区域的平均值进行输出,这个区域的每一个神经元都是有参与前向传播了的,因此,在反向传播时,框架需要将梯度平均分配给每一个神经元再进行反向传播,相关的操作示意如下图所示。

对于最大池化,其前向传播是取某特征区域的最大值进行输出,这个区域仅有最大值神经元参与了前向传播,因此,在反向传播时,框架仅需要将该区域的梯度直接分配到最大值神经元即可,其他神经元的梯度被分配为0且是被舍弃不参与反向传播的,但如何确认最大值神经元,这个还得框架在进行前向传播时记录下最大值神经元的Max ID位置,这是最大池化与平均池化差异的地方,相关的操作示意如下图所示。

引入BN层的原因
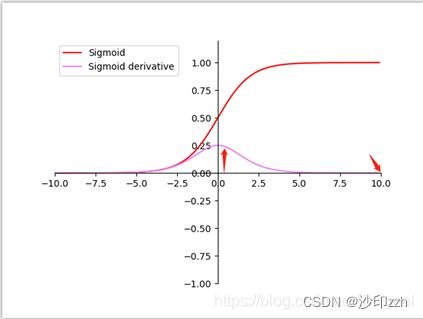
我们在图像预处理过程中通常会对图像进行标准化处理,也就是image normalization,使得每张输入图片的数据分布能够统均值为u,方差为h的分布。这样能够加速网络的收敛。但是当一张图片输入到神经网络经过卷积计算之后,这个分布就不会满足刚才经过image normalization操作之后的分布了,可能适应了新的数据分布规律,这个时候将数据接入激活函数中,很可能一些新的数据会落入激活函数的饱和区,导致神经网络训练的梯度消失,如下图所示当feature map的数据为10的时候,就会落入饱和区,影响网络的训练效果。这个时候我们引入Batch Normalization的目的就是使我们卷积以后的feature map满足均值为0,方差为1的分布规律。在接入sigmoid激活函数时落入导数相对最大的部分,便于梯度下降。
1、加速网络的收敛速度。在神经网络中,存在内部协变量偏移的现象,如果每层的数据分布不同的话,会导致非常难收敛,如果把每层的数据都在转换在均值为零,方差为1的状态下,这样每层数据的分布都是一样的,训练会比较容易收敛。
2、防止梯度爆炸和梯度消失。对于梯度消失而言,以Sigmoid函数为例,它会使得输出在[0,1]之间,实际上当x到了一定的大小,sigmoid激活函数的梯度值就变得非常小,不易训练。归一化数据的话,就能让梯度维持在比较大的值和变化率;对于梯度爆炸而言,在反向传播的过程中,每一层的梯度都是由上一层的梯度乘以本层的数据得到。如果归一化的话,数据均值都在0附近,很显然,每一层的梯度不会产生爆炸的情况。
3、防止过拟合。在网络的训练中,Bn使得一个minibatch中所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果,这样就会使得整个网络不会朝这一个方向使劲学习。一定程度上避免了过拟合。
为什么要引入γ和β变量
Bn层在进行前三步后,会引入γ和β变量,对输入进来的数据进行缩放和平移。
γ和β变量是网络参数,是可学习的。
引入γ和β变量进行缩放平移可以使得神经网络有自适应的能力,在标准化效果好时,尽量不抵消标准化的作用,而在标准化效果不好时,尽量去抵消一部分标准化的效果,相当于让神经网络学会要不要标准化,如何折中选择。
参考这篇博文,感谢bubling大佬