词典构造方法之LDA主题模型
词典构造方法之LDA主题模型
主题模型LDA原理理解
LDA是一种非监督学习技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。
举例来说,假设一个语料库中有三个主题:体育,科技,电影 。一篇描述电影制作过程的文档,可能同时包含主题科技和主题电影,而主题科技中有一系列的词,这些词和科技有关,并且他们有一个概率,代表的是在主题为科技的文章中该词出现的概率。同理在主题电影中也有一系列和电影有关的词,并对应一个出现概率。当生成一篇关于电影制作的文档时,首先随机选择某一主题,选择到科技和电影两主题的概率更高(这三个主题的概率分布决定大小);然后选择单词,选择到那些和主题相关的词的概率更高(主题下面的选的词也是符合一定的概率分布的)。这样就就完成了一个单词的选择。不断选择N个单词,这样就组成了一篇文档。
那么,如果我们要生成一篇文档,它里面的每个词语出现的概率为:
P ( w o r d │ d o c u m e n t ) = ∑ P ( w o r d │ t o p i c ) × P ( t o p i c ∣ d o c u m e n t ) P(word│document)=∑P(word│topic)×P(topic|document) P(word│document)=∑P(word│topic)×P(topic∣document)
这个其实可以更加形象表示如下:

LDA提取关键词和可视化
了解LDA的一些基本原理后,我们可以很轻松就可以利用LDA找出文章的主题词。因为LDA模型每次都可以找到这个主题的单词,我们只要把数据主题数目topic_num确定下来就可以构建这个领域的词典。
其构建词典的步骤可以归纳如下:
(1) 利用八爪鱼 ,Web 爬虫完成数据的爬取,并存储到本地,获取的数据。
(2) 对所获的大宗语料数据进行处理操作,有数据清洗、分词、停用词过滤、词性标注等处理。
(3) 用LDA方法构造基础领域词典,并可视化。
读取文件
数据集选新闻数据10类,事现人工标注好,这样分类的时候可以直接设置topic_num = 10
label都有’时尚’,‘财经’,‘科技’,‘游戏’,‘房产’,‘娱乐’,‘时政’,‘体育’,‘家具’。
import pandas as pd
import numpy as np
import jieba
import jieba.posseg as pseg
import re
import string
import os
import matplotlib.pyplot as plt
df = pd.read_csv('chinese_news.csv')
df.head()
| label | content | |
|---|---|---|
| 0 | 体育 | 鲍勃库西奖归谁属? NCAA最强控卫是坎巴还是弗神新浪体育讯如今,本赛季的NCAA进入到了末... |
| 1 | 体育 | 麦基砍28+18+5却充满寂寞 纪录之夜他的痛阿联最懂新浪体育讯上天对每个人都是公平的,贾维... |
| 2 | 体育 | 黄蜂vs湖人首发:科比冲击七连胜 火箭两旧将登场新浪体育讯北京时间3月28日,NBA常规赛洛... |
| 3 | 体育 | 双面谢亚龙作秀终成做作 谁来为低劣行政能力埋单是谁任命了谢亚龙?谁放纵了谢亚龙?谁又该为谢亚... |
| 4 | 体育 | 兔年首战山西换帅后有虎胆 张学文用乔丹名言励志今晚客场挑战浙江稠州银行队,是山西汾酒男篮的兔... |
df['label'].value_counts()
体育 1000
娱乐 1000
家居 1000
房产 1000
教育 1000
时尚 1000
时政 1000
游戏 1000
科技 1000
财经 1000
Name: label, dtype: int64
数据清洗
主要在去重,去停用词,分词
def length_bigger_than_10(text):
if len(text)>=10:
return True
else:
return False
def stopwordslist():#加载停用词表,这个中文停用词表.txt也
stopwords = [line.strip() for line in open('D:/conda_python/NLP_goods_comment/stopwords-master/cn_stopwords.txt',encoding='UTF-8').readlines()]
return stopwords
def deleteStop(sentence): #去停用词
stopwords=stopwordslist()
outstr=""
for i in sentence:
if i not in stopwords and i!="\n":
outstr+=i
return outstr
def wordCut(Review):
rec = re.sub('[%s]' % re.escape(string.punctuation), '',Review)
fenci=jieba.lcut(rec) #精准模式分词
stc=deleteStop(fenci)
seg_list=pseg.cut(stc) #标注词性
rec = [w for w,flag in seg_list if flag not in ["nr","ns","nt","nz","m","f","ul","l","r","t"] and len(w)>=2]
document = " ".join(rec)
return document
df.drop_duplicates(subset='content',inplace=True)
df['content'] = df['content'].str.replace("[^\u4e00-\u9fa5]", "")
df['length'] = df.agg({'content': length_bigger_than_10})
newdf = df[df['length']==True]
newdf['content'] = newdf.agg({'content': wordCut})
corpus = newdf['content']
corpus
对10000篇文章做的一个去重 ,分词,去停用词的操作。文章处理后的结果如下:
0 归属 最强 控卫 坎巴 体育讯 进入 末段 奖项 评选 即将 出炉 评选 最佳 控卫 最终 …
1 充满 寂寞 纪录 夜痛 体育讯 公平 维尔 例外 奇才 客场 负于 勇士 软柿子 机会 打出…
2 湖人 首发 科比 冲击 火箭 登场 体育讯 时间 常规赛 湖人 主场 迎战 新奥尔良 双方 …
3 双面 作秀 终成 做作 低劣 行政 能力 埋单 任命 放纵 倒掉 负责 进去 远一语 足坛 …
4 兔年 首战 虎胆 名言 励志 客场 挑战 银行 男篮 兔年 积分榜 差距 山西队 已经 惧怕…
9995 基金 成立 股市 新增 资金 兴业 有机 增长 混合 基金 发布公告 基金 募得 份额 这份…
9996 基金 政策性 主题 投资 机会 实录 财经 和谐 主题 基金 拟任 基金 经理助理 做客 财…
9997 基金 投资 信心 指数 问世 记者 基金 宣布 推出 基金 投资者 信心 指数 国内 基金 …
9998 私募 月份 火速 成立 证券时报 记者 私募 产品 迎来 发行 统计 显示 月份 成立 证券…
9999 股票 基金 全线 受挫 基金 全景网 基金净值 普降 股票 型基金 全线 受挫 基金 跌幅 …
提取每个topic对应的词
def print_top_words(model, feature_names, n_top_words):
#打印每个主题下权重较高的term
for topic_idx, topic in enumerate(model.components_):
print ("Topic #%d:" % topic_idx)
print (" ".join([feature_names[i]
for i in topic.argsort()[:-n_top_words - 1:-1]]))
import pyLDAvis
import pyLDAvis.sklearn
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
vectorizer = CountVectorizer()
n_top_words=20 #词数目
doc_term_matrix = vectorizer.fit_transform(corpus)
lda_model = LatentDirichletAllocation(n_components=10, random_state=888,doc_topic_prior=0.1,topic_word_prior=0.1)
lda_model.fit(doc_term_matrix)
tf_feature_names = vectorizer.get_feature_names()
print_top_words(lda_model, tf_feature_names, n_top_words)
这里面有的topic=10,n_top_words=20,提取结果如下:
Topic 0:
移民 工作 规定 申请 国家 要求 进行 情况 管理 问题 部门 投资 人员 政策 相关 实施 制度 政府 社会 意见
Topic 1:
市场 房地产 房价 楼市 政策 价格 增长 上涨 出现 成交 销售 认为 楼盘 已经 经济 投资 开发商 月份 需求 平方米
Topic 2:
学生 留学 大学 学校 申请 教育 学习 专业 孩子 留学生 考试 签证 工作 选择 课程 提供 国内 信息 没有 出国
Topic 3:
搭配 时尚 组图 性感 黑色 设计 导语 造型 选择 风格 外套 白色 气质 款式 装扮 感觉 流行 优雅 颜色 图案
Topic 4:
发展 项目 表示 记者 土地 问题 经济 企业 合作 政府 建设 进行 开发 公司 地产 国家 开发商 投资 房地产 地块
Topic 5:
比赛 球队 篮板 球员 没有 时间 热火 火箭 已经 进攻 得分 防守 表现 湖人 命中 体育讯 助攻 得到 对手 科比
Topic 6:
电影 游戏 玩家 活动 导演 手机 影片 没有 获得 观众 角色 任务 娱乐 觉得 拍摄 已经 票房 表示 世界 时间
Topic 7:
产品 家具 企业 品牌 市场 消费者 行业 家居 地板 发展 设计 装修 公司 活动 服务 没有 销售 非常 环保 家装
Topic 8:
基金 投资 公司 市场 股票 指数 投资者 型基金 收益 债券 经理 发行 分红 资产 管理 上涨 显示 仓位 净值 表示
Topic 9:
功能 采用 像素 拍摄 支持 英寸 机身 光学 佳能 拥有 镜头 自动 相机 使用 具有 对焦 模式 方面 产品 设计
import pyLDAvis.gensim
#import pyLDAvis.gensim_models
data = pyLDAvis.sklearn.prepare(lda_model, doc_term_matrix, vectorizer)
pyLDAvis.show(data)
可视化
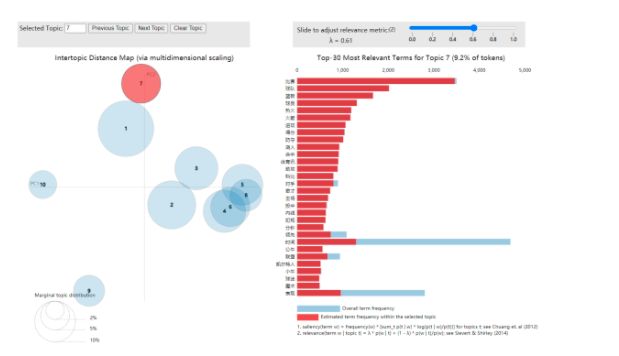
可视化的topic7的主题可以看出topic是属于“体育”这一主题。但是如果在没有事先确定的多少类中,LDA的主题数即topic_num我们要自己设定,一般情况n_topics可能要实验多次,才可以找到最佳的n_topics。
利用LDA词典构造
利用topic里面的词典和可视化工具,我们可以轻松得到一些领域的词,从而组成一个基本词典。至于词典的扩充,可以使用别的方法多词典扩张,例如TF-IDF。例如体育领域可以使用如下的词组成一个词典:
体育领域词典词:比赛 球队 篮板 球员 没有 时间 热火 火箭 已经 进攻 得分 防守 表现 湖人 命中 体育讯 助攻 得到 对手 科比
教育领域词典词:学生 留学 大学 学校 申请 教育 学习 专业 孩子 留学生 考试 签证 工作 选择 课程 提供 国内 信息 没有 出国
依次类推。至此,NLP的领域词典就构造成功啦。小伙伴们也动手试试吧。