【KAWAKO】TVM-tflite模型编译与优化
目录
前言
准备模型
版本问题
精度问题
加载tflite模型
编译模型
在python上运行模型进行测试
加载输入数据
运行四连
优化(Autotune)
注:
前言
TVM的编译与优化主要有两种方法,一种是通过tvmc命令行,另一种是通过python。
tvmc编译出来的模型,在后面c++推理的时候读取不进来,可能是我使用的c++方法与tvmc的模型对应不上导致的,因此本文暂时不讲这种方法,其使用方法可以在官方文档中找到。
python方法虽然不如tvmc灵活,但也挺简单的,本文将对该方法进行讲解。官方文档。
准备模型
本次使用的是DTLN第二阶段的模型,模型结构如下
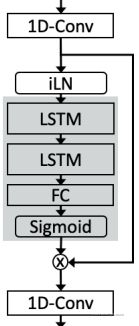
其包含两个输入、两个输出:
输入分别为(1,1,640)的主输入,和(1,2,128,2)的LSTM状态输入。
输出分别为(1,1,640)的主输出,和(1,2,128,2)的LSTM状态输出。
版本问题
使用netron查看网络结构,在“model properties”中可以看到“runtime”版本。
一开始我使用 tensorflow 2.5.0,转出来的tflite模型的runtime版本为2.0,使用该模型在后面的步骤中会发生错误。
后来我把tensorflow降级到2.4.0,转出来的tflite模型的runtime版本为1.14.0,该模型在后面的步骤中未发生错误。

精度问题
使用int8精度的模型在后面的步骤中会发生错误,使用float精度的模型未发生错误。
加载tflite模型
tflite_model_file = "float16_2.tflite"
tflite_model_buf = open(tflite_model_file, "rb").read()
import tflite
tflite_model = tflite.Model.GetRootAsModel(tflite_model_buf, 0)注:我的tflite版本为2.1.0
编译模型
from tvm import relay, transform
input_1 = ["input_5", (1,2,128,2), "float32"]
input_2 = ["input_4", (1,1,640), "float32"]
mod, params = relay.frontend.from_tflite(
tflite_model,
shape_dict={input_1[0]: input_1[1], input_2[0]: input_2[1]},
dtype_dict={input_1[0]: input_1[2], input_2[0]: input_2[2]},
)
target = "llvm"
with transform.PassContext(opt_level=3):
lib = relay.build(mod, target, params=params)target是可以根据情况自行更改,参考这篇博客中的这张图。
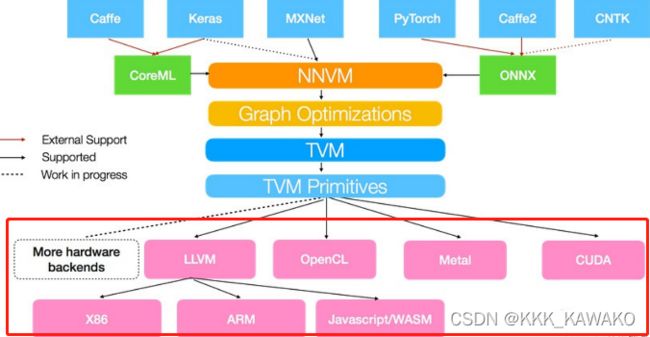
opt_level是优化等级,从【tvmc compiler -h】命令中看到其选择范围为0~3。
![]()
从netron中可以看到模型两个输入的名字和维度。

在python上运行模型进行测试
加载输入数据
import numpy as np
input_state = np.load("input_states.npy")
inputs = np.load("input.npy")运行四连
创建模型执行器 → 输入数据 → 运行 → 得到输出
import tvm
from tvm import te
from tvm.contrib import graph_executor as runtime
# Create a runtime executor module
module = runtime.GraphModule(lib["default"](tvm.cpu()))
# Feed input data
module.set_input(input_1[0], tvm.nd.array(input_state))
module.set_input(input_2[0], tvm.nd.array(inputs))
# Run
import time
times = 100000
a = time.time()
for i in range(times):
module.run()
print(1000*(time.time()-a)/times)
# Get output
tvm_output_0 = module.get_output(0).numpy()
tvm_output_1 = module.get_output(1).numpy()优化(Autotune)
加载各种库
import tvm.auto_scheduler as auto_scheduler
from tvm.autotvm.tuner import XGBTuner
from tvm import autotvm创建TVM runner
number = 10
repeat = 1
min_repeat_ms = 0 # since we're tuning on a CPU, can be set to 0
timeout = 10 # in seconds
# create a TVM runner
runner = autotvm.LocalRunner(
number=number,
repeat=repeat,
timeout=timeout,
min_repeat_ms=min_repeat_ms,
enable_cpu_cache_flush=True,
)设置一些tuning的参数
tuning_option = {
"tuner": "xgb",
"trials": 1500,
"early_stopping": 100,
"measure_option": autotvm.measure_option(
builder=autotvm.LocalBuilder(build_func="default"), runner=runner
),
"tuning_records": "model-autotuning.json",
}开始autotune,autotune会将结果记录在上面设置的"tuning_records"中。
# begin by extracting the tasks from the onnx model
tasks = autotvm.task.extract_from_program(mod["main"], target=target, params=params)
# Tune the extracted tasks sequentially.
for i, task in enumerate(tasks):
prefix = "[Task %2d/%2d] " % (i + 1, len(tasks))
tuner_obj = XGBTuner(task, loss_type="rank")
tuner_obj.tune(
n_trial=min(tuning_option["trials"], len(task.config_space)),
early_stopping=tuning_option["early_stopping"],
measure_option=tuning_option["measure_option"],
callbacks=[
autotvm.callback.progress_bar(tuning_option["trials"], prefix=prefix),
autotvm.callback.log_to_file(tuning_option["tuning_records"]),
],
)根据"tuning_records"中的autotune结果,重新编译模型
with autotvm.apply_history_best(tuning_option["tuning_records"]):
with tvm.transform.PassContext(opt_level=3, config={}):
lib = relay.build(mod, target=target, params=params)将模型导出为so文件,待后续c++推理使用
lib.export_library("./model_autotune.so")注:
autotune使用的算法可以自行修改,候选算法可以在tvm工程下的“gallery/how to/tune_with_autotvm”中找到。

根据自己的平台选择相应的文件,在里面找到类似下图这样的(各个平台可选择的算法不同)

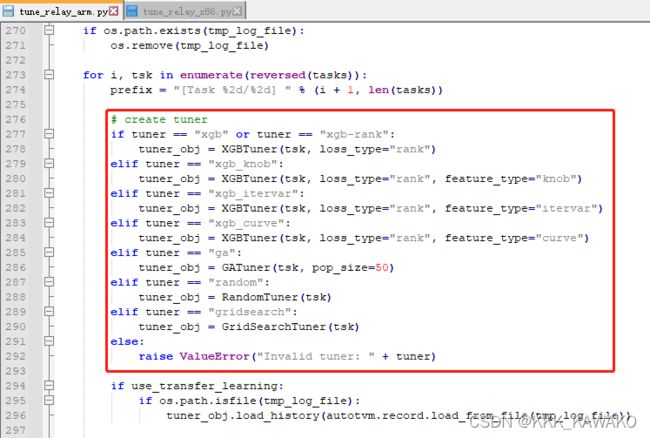
选择自己想使用的算法,将对应的字符串(如“gridsearch”)替换到前面tuning_option中的“tuner”里,然后从tvm.autotvm.tuner中将对应的函数import进来(如from tvm.autotvm.tuner import GridSearchTuner),最后在for i, task in enumerate(tasks):的循环中替换掉Tuner的函数(如tuner_obj = GridSearchTuner(task))。
