论文阅读——Synthetic Medical Images from Dual Generative Adversarial Networks
论文阅读——Synthetic Medical Images from Dual Generative
Adversarial Networks
基于双生成对抗网络合成医学图像
from NIPS2017
Abstract
目前数据驱动型的方法进行医学图像的分类十分受追捧,但鉴于医学图像的稀缺性,有些图像的获取还涉及到病患隐私等问题使得医学图像更加难以获取。一般只允许将病患的数据用于医学期刊或教学中,也意味着无法为公共研究获取。
本文则提出了一种新的两阶段流水线的模型用于合成医学图像,通过将复杂的图像生成任务按层次划分为两部分:几何结构和图像写实性,并成功在视网膜眼底图像上进行了测试。
我们希望学者们能够运用本文的方法将私密的医学数据带入到公共视野中,进一步发展以前依赖于手工调整的模型。
Section I Introduction
计算机辅助医学图像分析广泛用于辅助专家医生进行医学图像的分析解读,今日深度学习算法在特定医学图像的理解上展现了强大的高精度性能,尤其在分类和分割任务中。此外深度学习算法还大大提高了数据分析的效率,因为随着医学图像大量产生,有些还是以3维数据的形式(如MRI,CT图像等),如果还是用手工标注就显得十分笨重且效率低下。
因此基于深度学习技术进行计算机辅助的医学图像分析引起了业界的广泛关注,但是由于数据的隐私及可获取性使得公众无法直接参与推动这一系统的发展。医生也无法在未经病患同意的前提下将大量原始数据向社会开源;除此之外目前开源的一些数据及也往往规模较小或缺乏专家标注,对于一些数据饥饿型网络的训练也无济于事。只有能获取到大量专业的医学数据的专业人士才能从事这一系统的开发,使得这一领域的进展缓慢。
过去十年间,深度学习领域取得了诸多突破。每年的ImageNet挑战赛逐渐提升精度,也显示出大型、精确的数据集对模型的训练时多么重要,如果在医学领域也有这样一个大型精确地数据集我想也会引发这一领域指数式的发展。
本文提出了一种新的流水线式模型用于医学图像的合成,这一模型允许使用公共数据集,没有隐私等问题的考虑,本文使用的数据集来源于SynthMed。
Section II Related Works
不同学科的研究人员已经有借助数据合成的方法将一些隐私数据带到公共领域,比如美国人口普查就会收集个人的职业、教育、收入和位置等信息,即使来源已经被各种混淆打乱但仍有被匿名泄露的风险。Duke大学的一名研究人员则通过合成数据的方式解决了这一数据私密性的问题,发布了第一个开源的商业机构数据库-Synthetic Longitudinal Business Database。
本文则将数据合成的思路用于图像,尤其是GAN的发展展现出数据合成强大的能力。但是GAN生成的数据常常带有伪影或噪声,主要是由于在能量场鞍点附近的不稳定性导致的,本文通过使用一对GAN来解决这一稳定性问题。
Section III Data
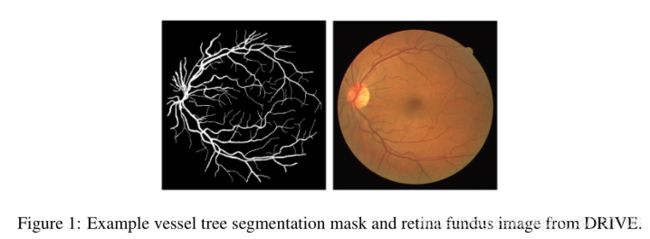
在GAN的第一阶段(stage-I)使用的是DRIVE数据集中的视网膜眼底图像,DRIVE数据集包含40张视网膜血管图像以及对应的分割结果,分割结果由两位专家提供;
GAN的第二阶段(stage-II)的训练图像包括MESSIDOR数据集中的图像以及经过一个分割网络得到的分割掩膜(mask)。
为了对比效果,本文还训练了基于单个GAN在DRIVE数据集上的效果;一个UNet在DRIVE数据集上进行训练,其他的UNet则是在GAN生成的50对图像上进行训练。
 # Section IV General Pipeline
# Section IV General Pipeline
Section IV General Pipeline
为了生成高质量的数据集,本文使用两个GAN,将图像生成问题分成两步:
(1)Stage-I GAN:生成分割掩膜表征数据集可变的几何形状;
(2)Stage-II GAN:将第一阶段的掩膜图像转换为实际图像。

具体的流程参见Fig 2 ,可以看到在第一阶段输入的是真实数据集中的分割图像,经过GAN训练后合成新的分割图像;第二阶段输入的则是{真实眼底图像,分割图}这一组图像对以及上一阶段生成的分割图,经过GAN II后输出合成的视网膜眼底彩图。
Section V GAN
重新回顾一下GAN,其中生成网络负责从随机噪声中合成图像,判别网络则是标准的CNN,对输入的图像输出概率图谱,辨别输入图像是真实的还是合成的而生成网络一般层数更多一些,这样可以学习更多非线性映射关系。
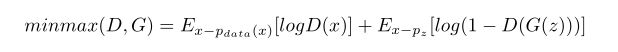
另外GAN的一个重要特征就是可以生成比原始数据集规模更大的图像。
本文则用流水的方式组织GAN网络,在维护病人隐私的基础上生成更广泛的真实图像。
Part A Stage-I GAN
Stage-I GAN的任务时生成不同的分割掩膜,基础网络结构是DCGAN,因为与标准的GAN相比,DCGAN可以同时对生成结果和训练稳定性有较为综合的提升。DCGAN的特别之处在于使用卷积层取代了池化层,池化层虽然有助于提升训练效率但不可避免损失了空间信息等一些重要特征。
第一阶段使用的损失函数:


Part B Stage-II GAN
第二阶段的GAN需要根据输入的图像对,将前一阶段的血管分割图转换成写实的视网膜眼底图像。基础网络是cGAN,参考的分别是前一篇博文[Towards Adversarial Retinal Image Synthesis],损失函数定义为:
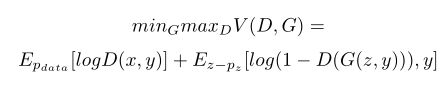
第二阶段的GAN需要学习的就是真实的眼底图像与分割图之间的映射关系,然后根据给定的分割图生成相同几何结构的真实眼底图像。
Section VI UNet
为了测试本文这种合成方法的有效性,本文还训练了一个UNet用于根据输入的视网膜眼底图产生分割的血管图。UNet采用的结构就是Ronneberger提出的原始的编码-解码网络结构。
UNet的优势就是第一没有限定输入图像的规格,二是允许足够多的通道老表征特征,跃层连接还有效传递了原始的低层信息。
而分割任务在医学图像分析中大有可为,比如用于恶性肿瘤的识别。对于视网膜图像。医生通常需要根据血管的微小病变对一些糖尿病视网膜病变等病症做出诊断。
本文展示了基于合成图像进行UNet分割的结果,有效的简化了自动识别过程还提升了精度。这也只是本文这种流水线图像生成方法的一种应用。
Section VII 评价指标
本文会把合成的图像送入UNet分割,因此通过计算F1分数类似评估分割的好坏,还会计算合成图与真实图之间的KL散度来衡量GAN的性能。KL散度:

Section VIII Results
Part A Quantitative Results
合成图与原始图的F1得分分别为0.8877和0.8988,可以看到二者的差距很小。KL散度则分别是4.759和4.121x10-4,DRIVE数据集中两个子集来源于同一分布所以分数才这么低,而两者的差距则表明了合成的数据也不仅仅是完全复制了原始数据的分布。

Part B Qualitative Results
Fig4展示了两张合成的分割图谱以及在DRIVE数据集中与之最相近的分割图,
Fig5展示的则是DRIVE数据集中的眼底图像以及对应的mask;和本文生成的眼底图像与mask的对比。



Section VIIII Pipeline Validation
为了测试本文这种流水线式的灵活性,本文还在另一个数据集-BU-BIL上进行了测试。
BU-BIL数据集包含35张大鼠平滑肌细胞图像以及对应的分割mask作为训练数据。
本文选择这一数据集的原因是因为它变化较大,前景物体的位置和形状都有较大的变化,这就使得GAN难以学习特征之间的相关性。但通过本文的Dual-GAN模型还是成功的合成了逼真的平滑肌细胞图像以及对应的mask。

Fig6展示了BU-BIL图像的合成情况。 而且有一点值得强调,那就是这仅仅是基于35张图像,这就说明在第二阶段的GAN足以根据分割的mask学习到真实图像的映射,但如果数据更加多样的话也许对图像中的背景部分学习的更好。
Section X Discussioin
鉴于医学图像常常变化较多,容易受噪声、光照、模式等的影响,单一的GAN不足以产生令人信服的图像。比如Fig7就展示了用一个GAN生成的结果。
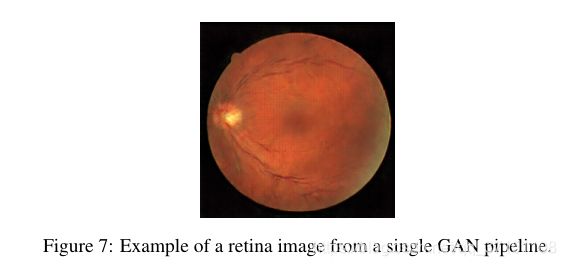
可以看到无法学习较为复杂的结构,因此看到生成图像中对于血管树和dark spot部分都有较大缺陷,只能学习到一些简单的特征,如颜色、光照、形状等。
而在细节上的缺失是无法应用于医学图像生成的,本文的Dual-GAN通过将这一具有挑战性的生成任务切分为两个子任务,有效提升了生成图像的质量。在Stacking GAN中,也体现了相似的思路,通过对每一个GAN提供相关的补充任务来解决GAN的不稳定问题。
而本文中Stage-I GAN只关注于:如何产生分割后的几何结构,而不考虑图像写实的问题;
而Stage-II GAN则关注于如何根据输入的结构图生成更高维度的视网膜眼底图,包括颜色、光照、纹理等特征的学习。这样每个GAN都能达到较高质量,收敛的也更快,比常规的GAN系统生成的图像更加逼真、写实。
除此之外,本文会比原始数据集生成更为丰富的图像,通过Fig3中二者的分布就能看出。
因此,给定一个数据集,能够生成更多的不属于任何一个真实病人的图像,这样就可以向公众开源。基于此,本文还设计了一个开放的医学图像数据库平台-SynthMed,上边所有的数据都是合成的,无法被追溯到任何一个病人,这样就可以提供更多图像供公众使用。
我们希望未来可以有更多的研究者利用这种数据合成技术开源更多的医学图像数据,共同推动计算机辅助医学图像分析这一领域的发展。
Section XI Future Work
我们相信本文的Dual-GAN可以应用到其他医学图像中,因为场景合成一直是计算机视觉一个很火热的领域,往往图像都是极其复杂却变化多端的,这种两步走的方法可以有效简化问题。
未来我们希望Stage-I 可以探索其他模式的图像表征,比如贝塞尔曲线、2D点云或者图像的素描,这样可以在图像生成中尽量压缩维度,从而有效减少计算时间以及产生伪影的可能。
处理不同的数据,本文的模型需要调整一些超参数,也可以设计一些更深层更有效的模块来替代模型中的一些网络。
此外本文的模型依赖于精确的高方差的数据,虽然可以用于各种医学图像但需要在获得私密数据的基础上在进行,关键是获得这些数据从而进一步生成数据,向公众开放,这需要更多人的共同协作。