53 语言模型 动手学深度学习 PyTorch版 李沐视频课笔记
动手学深度学习 PyTorch版 李沐视频课笔记
李沐视频课笔记其他文章目录链接(不定时更新)
文章目录
- 动手学深度学习 PyTorch版 李沐视频课笔记
- 一、语言模型
-
- 1. 语言模型和数据集
- 2. 词频图
- 3. 二元语法词频
- 4. 三元语法词频
- 5. 三种语法词频直观对比
- 6. 随机采样
- 7. 随机生成生成一个0到34的序列
- 8. 顺序分区
- 9. 顺序分区生成
- 10. 将上面两个采样函数包装到一个类中
- 11. 定义load_data_time_machine函数
一、语言模型
1. 语言模型和数据集
使用时光机器数据集构建词表,并打印前10个最常用的(频率最高的)单词。
Code:
import random
import torch
from d2l import torch as d2l
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个⽂本⾏不⼀定是⼀个句⼦或⼀个段落,因此我们把所有⽂本⾏拼接到⼀起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus)
vocab.token_freqs[:10]
Result:

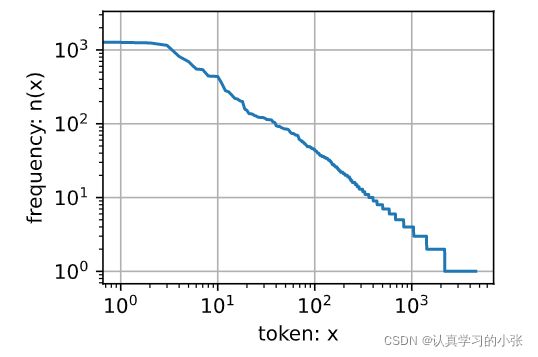
2. 词频图
最流行的词看起来很无聊,这些词通常被称为停用词(stop words),因此可以被过滤掉
Code:
freqs = [freq for token, freq in vocab.token_freqs]
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)',xscale='log', yscale='log')
Result:
3. 二元语法词频
Code:
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
bigram_vocab.token_freqs[:10]
Result:

4. 三元语法词频
Code:
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
trigram_vocab.token_freqs[:10]
Result:

5. 三种语法词频直观对比
Code:
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
Result:

6. 随机采样
在随机采样中,每个样本都是在原始的长序列上任意捕获的子序列。在迭代过程中,来自两个相邻的、随机的、小批量中的子序列不⼀定在原始序列上相邻。对于语言建模,目标是基于到目前为止我们看到的词元来预测下⼀个词元,因此标签是移位了⼀个词元的原始序列。每次可以从数据中随机生成⼀个小批量,参数batch_size指定了每个小批量中子序列样本的数目,参数num_steps是每个子序列中预定义的时间步数。
Code:
def seq_data_iter_random(corpus, batch_size, num_steps): #@save
"""使⽤随机抽样⽣成⼀个⼩批量⼦序列"""
# 从随机偏移量开始对序列进⾏分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# ⻓度为num_steps的⼦序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来⾃两个相邻的、随机的、⼩批量中的⼦序列不⼀定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的⻓度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这⾥,initial_indices包含⼦序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
yield torch.tensor(X), torch.tensor(Y)
7. 随机生成生成一个0到34的序列
Code:
my_seq = list(range(35))
for X, Y in seq_data_iter_random(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
Result:

8. 顺序分区
保证两个相邻的小批量中的子序列在原始序列上也是相邻的。这种策略在基于小批量的迭代过程中保留了拆分的子序列的顺序,因此称为顺序分区。
Code:
def seq_data_iter_sequential(corpus, batch_size, num_steps): #@save
"""使⽤顺序分区⽣成⼀个⼩批量⼦序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
9. 顺序分区生成
Code:
for X, Y in seq_data_iter_sequential(my_seq, batch_size=2, num_steps=5):
print('X: ', X, '\nY:', Y)
Result:

10. 将上面两个采样函数包装到一个类中
Code:
class SeqDataLoader: #@save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
11. 定义load_data_time_machine函数
它同时返回数据迭代器和词表
Code:
def load_data_time_machine(batch_size, num_steps, use_random_iter=False, max_tokens=10000):#@save
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab