yolox论文研读
yolox论文研读
大家好,我是【豆干花生】,这次我带来了新的文章,与你分享~
文章目录
- yolox论文研读
-
- 一.概述
- 二.改进
-
- 1.Decoupled Head
- 2.Data Augmentation
- 3.Anchor Free 与 OTA
- 4.End2end
- 5.多种可选配的网络
-
- 基准模型:Yolov3_spp
- Yolox-Darknet53
- 三.OTA
- 四.总结
-
- 1.输入端
- 2.Backbone
- 3.Neck
- 4.Prediction层
参考文献:
https://www.zhihu.com/question/473350307/answer/2021031747
https://zhuanlan.zhihu.com/p/397993315
一.概述
YOLOX 里的 X 可以理解为 Exceeding 里的 X,也可以理解为一种不确定性,也可以理解为偷懒用了个 X。
YOLOX达到了某种程度上的稳定与平衡。由于 YOLOX 对目标检测里的重要影响因素进行了着重处理,对于超参 ( reg weight,dynamic k的candidate num 等) 和其他次要的变量 (比如检测头的一些简单变体、回归目标是 xywh 还是 lrtb )则体现出了超出预期的鲁棒性。
与之前 YOLO 最大的区别在于 Decoupled Head,Data Aug,Anchor Free 和样本匹配这几个地方
二.改进
1.Decoupled Head
Decoupled Head 是学术领域一阶段网络一直以来的标准配置 ( RetinaNet,FCOS 等)。相比于它朴素的实现方法,“解耦头”这个词显得有些高大上。我们一开始并没有计划对检测头进行解耦,而是在将 YOLOX 推进到“端到端( 无需NMS )”时发现,不论调整损失权重还是控制梯度回传,End2end 的 YOLOX 始终比标准的 YOLOX 低 4~5 个点( 如 Table1 ),这与我们在 DeFCN 里获得的认知不符。偶然间我们把原始的 YOLO Head 换成 decoupled head,发现这里的差距又显著缩小了,这样的现象说明当前 YOLO Head 的表达能力可能有所欠缺。于是我们将 decoupled head 应用到了非 End2End YOLO 上,结果就如 Fig.3 的所示:不仅在峰值的性能有所提升,收敛速度也明显加快。结合之前 End2end 的实验,这两个现象充分说明 YOLO 系列一直以来使用的检测头可能是不合理的。
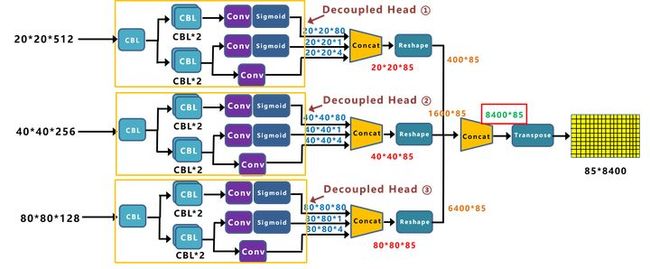
再对三个Decoupled Head信息,进行Reshape操作,并进行总体的Concat,得到**8400*85的预测信息。并经过一次Transpose,变为85*8400大小的二维向量信息。这里的8400,指的是预测框的数量,而85是每个预测框的信息(reg,obj,cls)。**分别为对目标框的坐标信息(x,y,w,h)进行预测、判断目标框是前景还是背景、目标框的类别。

将检测头解耦无疑会增加运算的复杂度,但经过权衡速度和性能上的得失,我们最终使用 1个1x1 的卷积先进行降维,并在分类和回归分支里各使用了 2个3x3 卷积,最终调整到仅仅增加一点点参数,YOLOX 在 s,m,l,x 模型速度上的轻微下降也全源自于此。表面上看,解耦检测头提升了 YOLOX 的性能和收敛速度,但更深层次的,它为 YOLO 与检测下游任务的一体化带来可能。比如:
- YOLOX + Yolact/CondInst/SOLO ,实现端侧的实例分割。
- YOLOX + 34 层输出,实现端侧人体的 17 个关键点检测。
2.Data Augmentation
Mosaic+Mixup
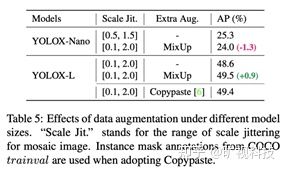
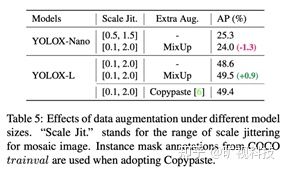
Mosaic 经过 YOLOv5 和 v4 的验证,证明其在极强的 baseline 上能带来显著涨点。我们早期在其他研究上发现,为 Mosaic 配上 Copypaste,依然有不俗的提升。组内的共识是:当模型容量足够大的时候,相对于先验知识(各种 tricks,hand-crafted rules ),更多的后验(数据/数据增强)才会产生本质影响。通过使用 COCO 提供的 ground-truth mask 标注,我们在 YOLOX 上试了试 Copypaste,下表表明,在 48.6mAP 的 YOLOX-Large 模型上,使用 Copypaste 带来0.8%的涨点。
Mosaic通过随机缩放、随机裁剪、随机排布的方式进行拼接,对于小目标的检测效果提升,还是很不错的。

我们早期在其他研究上发现,为 Mosaic 配上 Copypaste,依然有不俗的提升。可 Copypaste 的实现依赖于目标的 mask 标注,而 mask 标注在常规的检测业务上是稀缺的资源。而由于 MixUp 和 Copypaste 有着类似的贴图的行为,还不需要 mask 标注,因此可以让 YOLOX 在没有 mask 标注的情况下吃到 Copypaste 的涨点。不过我们实现的 Mixup,没有原始 Mixup 里的 Bernoulli Distribution 和 Soft Label ,有的仅是 0.5 的常数透明度和 Copypaste 里提到的尺度缩放 ( scale jittering )。 YOLOX 里的 Mixup 有如此明显的涨点,大概是因为它在实现和涨点原理上更接近 Copypaste,而不是原版 Mixup。

其实方式很简单,比如我们在做人脸检测的任务。
先读取一张图片,图像两侧填充,缩放到640*640大小,即Image_1,人脸检测框为红色框。
再随机选取一张图片,图像上下填充,也缩放到640*640大小,即Image_2,人脸检测框为蓝色框。
然后设置一个融合系数,比如上图中,设置为0.5,将Image_1和Image_2,加权融合,最终得到右面的Image。
从右图可以看出,人脸的红色框和蓝色框是叠加存在的。
我们知道,在Mosaic和Mixup的基础上,Yolov3 baseline增加了2.4个百分点。
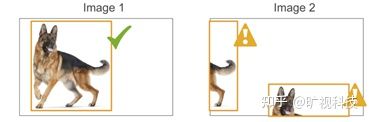
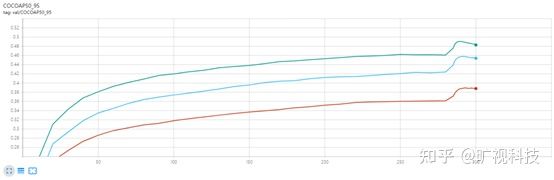
Data Augmentation 里面需要强调的一点是: 要在训练结束前的15个 epoch 关掉 Mosaic 和Mixup ,这对于 YOLOX 非常重要。可以想象,Mosaic+Mixup 生成的训练图片,远远脱离自然图片的真实分布,并且 Mosaic 大量的 crop 操作会带来很多不准确的标注框,见下图 (来源:https://github.com/ultralytics/yolov5/issues/2151):

YOLOv5 目前在考虑使用 mask 标注去修正这些框,使用了 mask 的 Copypaste 也已经有了 PR,相信很快会在 v5 的性能表上有所体现。这点上,我们认为 YOLOX 走在了 v5 的前面。回到提前关 Data Aug,核心目的是为了让检测器避开不准确标注框的影响,在自然图片的数据分布下完成最终的收敛。为此我们也补上新的一条使用 YOLOX 的 best practice:
如果训不到 300 个 epoch 便打算终止,请记得将关 Aug 的时间节点设定为终止前的 10~15 个 epoch 。
具体参考 yolox/exp/yolox_base.py 里的 no_aug_epochs 以及 yolox/core/trainer.py 里调用 close_mosaic 的方式。提前关 Data Aug 疗效如下:

3.Anchor Free 与 OTA
Anchor Free 的好处是全方位的。
1). Anchor Based 检测器为了追求最优性能通常会需要对anchor box 进行聚类分析,这无形间增加了算法工程师的时间成本;
2). Anchor 增加了检测头的复杂度以及生成结果的数量,将大量检测结果从NPU搬运到CPU上对于某些边缘设备是无法容忍的。
3). Anchor Free 的解码代码逻辑更简单,可读性更高。
(1) Anchor Based方式
比如输入图像,经过Backbone、Neck层,最终将特征信息,传送到输出的Feature Map中。
这时,就要设置一些Anchor规则,将预测框和标注框进行关联。
从而在训练中,计算两者的差距,即损失函数,再更新网络参数。
最后的三个Feature Map上,基于每个单元格,都有三个不同尺寸大小的锚框。
(2)Anchor Free方式
网络最终得到的不是类似于Yolov3中的Feature Map,而是特征向量。比基于Anchor Based的方式,少了2/3的参数量。
之后的锚框,就相当于桥梁。这时需要做的,就是将8400个锚框,和图片上所有的目标框进行关联,挑选出正样本锚框。而相应的,正样本锚框所对应的位置,就可以将正样本预测框,挑选出来。这里采用的关联方式,就是标签分配。
至于为什么 Anchor Free 现在可以上 YOLO ,并且性能不降反升,这与样本匹配有密不可分的联系。与 Anchor Free 比起来,样本匹配在业界似乎没有什么关注度。但是一个好的样本匹配算法可以天然缓解拥挤场景的检测问题( LLA、OTA 里使用动态样本匹配可以在 CrowdHuman 上提升 FCOS 将近 10 个点),缓解极端长宽比的物体的检测效果差的问题,以及极端大小目标正样本不均衡的问题。甚至可能可以缓解旋转物体检测效果不好的问题,这些问题本质上都是样本匹配的问题。在我们的认知中,样本匹配有 4 个因素十分重要:
- loss/quality/prediction aware :基于网络自身的预测来计算 anchor box 或者 anchor point 与 gt 的匹配关系,充分考虑到了不同结构/复杂度的模型可能会有不同行为,是一种真正的 dynamic 样本匹配。而 loss aware 后续也被发现对于 DeTR 和 DeFCN 这类端到端检测器至关重要。与之相对的,基于 IoU 阈值 /in Grid(YOLOv1)/in Box or Center(FCOS) 都属于依赖人为定义的几何先验做样本匹配,目前来看都属于次优方案。
- center prior : 考虑到感受野的问题,以及大部分场景下,目标的质心都与目标的几何中心有一定的联系,将正样本限定在目标中心的一定区域内做 loss/quality aware 样本匹配能很好地解决收敛不稳定的问题。
- 不同目标设定不同的正样本数量( dynamic k ):我们不可能为同一场景下的西瓜和蚂蚁分配同样的正样本数,如果真是那样,那要么蚂蚁有很多低质量的正样本,要么西瓜仅仅只有一两个正样本。Dynamic k 的关键在于如何确定k,有些方法通过其他方式间接实现了动态 k ,比如 ATSS、PAA ,甚至 RetinaNet ,同时,k的估计依然可以是 prediction aware 的,我们具体的做法是首先计算每个目标最接近的10个预测,然后把这个 10 个预测与 gt 的 iou 加起来求得最终的k,很简单有效,对 10 这个数字也不是很敏感,在 5~15 调整几乎没有影响。
- 全局信息:有些 anchor box/point 处于正样本之间的交界处、或者正负样本之间的交界处,这类 anchor box/point 的正负划分,甚至若为正,该是谁的正样本,都应充分考虑全局信息。
(3)标签分配
需要利用锚框和实际目标框的关系,挑选出一部分适合的正样本锚框。
那么在Yolox中,是如何挑选正样本锚框的呢?
这里就涉及到两个关键点:初步筛选、SimOTA。
初步筛选的方式主要有两种:根据中心点来判断、根据目标框来判断;
寻找anchor_box中心点,落在groundtruth_boxes矩形范围的所有anchors
以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。
我们将SimOTA的前后流程进行拆解,看一下是如何进行精细化筛选的?
整个筛选流程,主要分为四个阶段:
a.初筛正样本信息提取
b.Loss函数计算
c.cost成本计算
d.SimOTA求解
在 CVPR 21 年的工作 OTA 充分考虑到了以上 4 点,通过把样本匹配建模成最优传输问题,求得了全局信息下的最优样本匹配方案,欢迎大家阅读原文。但是 OTA 最大的问题是会增加约 20~25 %的额外训练时间,对于动辄 300epoch 的 COCO 训练来说是有些吃不消的,此外 Sinkhorn-Iter 也会占用大量的显存,所以在 YOLOX 上,我们去掉了 OTA 里的最优方案求解过程,保留上面 4 点的前 3 点,简而言之: loss aware dynamic top k。由于相对 OTA 去掉了Sinkhorn-Iter 求最优解的过程,我们把 YOLOX 采用的样本匹配方案称为 SimOTA ( Simplified OTA )。我们在 Condinst 这类实例分割上用过 SimOTA ,获得了 box 近1个点, seg 0.5 左右的涨点。同时在内部 11 个奇奇怪怪,指标五花八门的业务数据上也测试过 SimOTA ,平均下来发现 SimOTA>FCOS>>ATSS ,这些实验都满足我们不去过拟合 COCO 和 COCO style mAP 的初衷。没有复杂的数学公式和原理,不增加额外的计算时间,但是有效。用今年非常流行的句式为这个小节结个尾: Anchor free and dynamic label assignment are all you need.
4.End2end
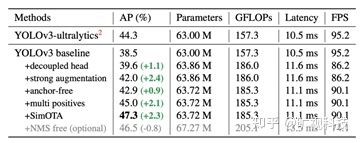
端到端( 无需 NMS )是个很诱人的特性,如果预测结果天然就是一个 set ,岂不是完全不用担心后处理和数据搬运?去年有不少相关的工作放出( DeFCN,PSS, DeTR ),但是在 CNN 上实现端到端通常需要增加2个 Conv 才能让特征变的足够稀疏并实现端到端,且要求检测头有足够的表达能力( Decoupled Head 部分已经详细描述了这个问题),从下表中可以看到,在 YOLOX 上实现 NMS Free 的代价是轻微的掉点和明显的掉 FPS 。所以我们没有在最终版本中使用 End2End 特性。

5.多种可选配的网络
将Yolox模型,变为多种可选配的网络,比如标准网络结构和轻量级网络结构。
**(1)标准网络结构:**Yolox-s、Yolox-m、Yolox-l、Yolox-x、Yolox-Darknet53。
**(2)轻量级网络结构:**Yolox-Nano、Yolox-Tiny。
在实际的项目中,大家可以根据不同项目需求,进行挑选使用。
(1)基准模型:Yolov3_spp
选择Yolov3_spp结构,并添加一些常用的改进方式,作为Yolov3 baseline基准模型;
(2)Yolox-Darknet53
对Yolov3 baseline基准模型,添加各种trick,比如Decoupled Head、SimOTA等,得到Yolox-Darknet53版本;
(3)Yolox-s、Yolox-m、Yolox-l、Yolox-x系列
对Yolov5的四个版本,采用这些有效的trick,逐一进行改进,得到Yolox-s、Yolox-m、Yolox-l、Yolox-x四个版本;
(4)轻量级网络
设计了Yolox-Nano、Yolox-Tiny轻量级网络,并测试了一些trick的适用性;
总体来说,论文中做了很多的工作,下面和大家一起,从以上的角度,对Yolox算法的网络结构,以及各个创新点进行讲解。
基准模型:Yolov3_spp
在设计算法时,为了对比改进trick的好坏,常常需要选择基准的模型算法。
而在选择Yolox的基准模型时,作者考虑到:
Yolov4和Yolov5系列,从基于锚框的算法角度来说,可能有一些过度优化,因此最终选择了Yolov3系列。
不过也并没有直接选择Yolov3系列中,标准的Yolov3算法,而是选择添加了spp组件,进而性能更优的Yolov3_spp版本。
以下是论文中的解释:
Considering YOLOv4 and YOLOv5 may be a little over-optimized for the anchor-based pipeline, we choose YOLOv3 [25] as our start point (we set YOLOv3-SPP as the default YOLOv3)。
为了便于大家理解,大白在前面Yolov3结构图的基础上,添加上spp组件,变为下图所示的Yolov3_spp网络。
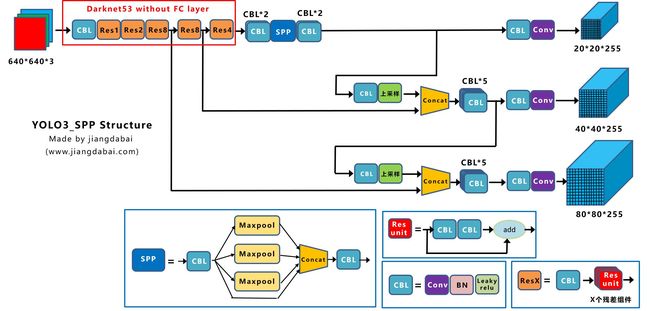
大家可以看到,主干网络Backbone后面,增加了一个SPP组件。
当然在此基础上,对网络训练过程中的很多地方,都进行了改进,比如:
(1)添加了EMA权值更新、Cosine学习率机制等训练技巧
(2)使用IOU损失函数训练reg分支,BCE损失函数训练cls与obj分支
(3)添加了RandomHorizontalFlip、ColorJitter以及多尺度数据增广,移除了RandomResizedCrop。
在此基础上,Yolov3_spp的AP值达到38.5,即下图中的Yolov3 baseline。
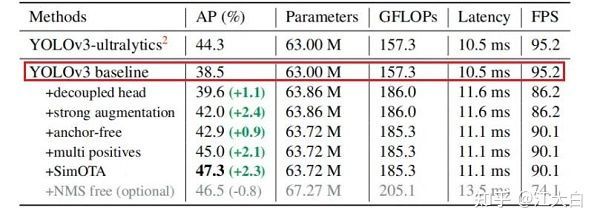
YOLOv3_ultralytics的AP值为44.3,论文中引用时,说是目前Yolov3_spp算法中,精度最好的版本。(the current best practice of YOLOv3)。
接着对此代码进行查看,发现正如论文中所说,增加了很多trick的Yolov3_spp版本,AP值为44.3。
而Yolox的基准模型,是最原始的Yolov3_spp版本,经过一系列的改进后,AP值达到38.5。
在此基础上,又增加了Strong augmentation、Decoupled head、anchor-free、multi positives、SimOTA,等5种trick,最终达到了AP47.3。
我们在前面知道,当得到Yolov3 baseline后,作者又添加了一系列的trick,最终改进为Yolox-Darknet53网络结构。
Yolox-Darknet53
我们在前面知道,当得到Yolov3 baseline后,作者又添加了一系列的trick,最终改进为Yolox-Darknet53网络结构。
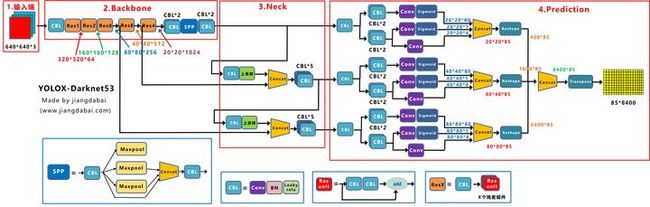
上图即是Yolox-Darknet53网络结构图。
为了便于分析改进点,我们对Yolox-Darknet53网络结构进行拆分,变为四个板块:
**① 输入端:**Strong augmentation数据增强
**② BackBone主干网络:**主干网络没有什么变化,还是Darknet53。
③ Neck:没有什么变化,Yolov3 baseline的Neck层还是FPN结构。
④ Prediction:Decoupled Head、End-to-End YOLO、Anchor-free、Multi positives。
在经过一系列的改进后,Yolox-Darknet53最终达到AP47.3的效果。

下面我们对于Yolox-Darknet53的输入端、Backbone、Neck、Prediction四个部分,进行详解的拆解。
三.OTA
参考链接:https://zhuanlan.zhihu.com/p/389986395
对于基于CNN的检测器,一个能考虑全局信息分配正负样本的策略是必要的。为了解决这个问题,旷视提出OTA——一个专门进行标签分配的优化算法。
OTA把标签分配视作最优传输问题,在GT和所有预测框之间计算运输成本,通过寻找一个合适的映射关系,使得运输成本最低。对于最优传输问题,我们在下一部分进行介绍。
OTA是第一个提出全局分配策略的方法,它可以同时插入一阶段和两阶段的检测网络,并可以获得不可忽视的性能提升。
最优传输是多个学科交叉的研究领域,它的主要目标是建立有效比较概率分布的几何工具。对于OTA的分配方法,这主要基于最优传输理论中的wasserstein距离来建立模型的
OTA通过引入最优传输理论探索了全局分配标签的可能性,很大程度上减少了模糊框的个数,提高了训练数据的利用率。并且这种策略可以插入到的大部分的检测网络,可移植性强。不过由于sinkhorn算法的复杂度不容小觑,以及该数学模型存在从经验上预设的超参数,个人认为该策略仍然有非常大的改进空间和提升空间
四.总结
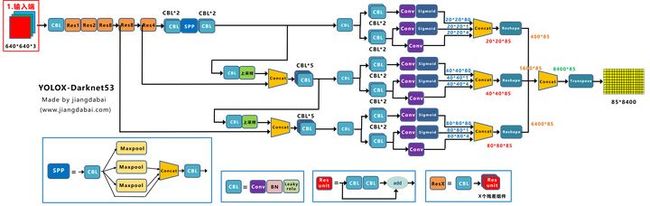
1.输入端
Strong augmentation
在网络的输入端,Yolox主要采用了Mosaic、Mixup两种数据增强方法。
而采用了这两种数据增强,直接将Yolov3 baseline,提升了2.4个百分点。
2.Backbone
Yolox-Darknet53的Backbone主干网络,和原本的Yolov3 baseline的主干网络都是一样的。
都是采用Darknet53的网络结构
3.Neck
在Neck结构中,Yolox-Darknet53和Yolov3 baseline的Neck结构,也是一样的,都是采用FPN的结构进行融合。
4.Prediction层
在输出层中,主要从四个方面进行讲解:Decoupled Head、Anchor Free、标签分配、Loss计算。
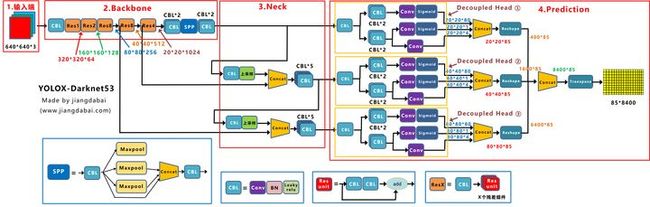
(1)Decoupled Head
Decoupled Head的收敛速度更快,且精度更高一些。将检测头解耦,会增加运算的复杂度。
(2)Anchor-free
在Yolov3、Yolov4、Yolov5中,通常都是采用Anchor Based的方式,来提取目标框,进而和标注的groundtruth进行比对,判断两者的差距。
Anchor Free比基于Anchor Based的方式,少了2/3的参数量。
(3)标签分配
需要利用锚框和实际目标框的关系,挑选出一部分适合的正样本锚框。
那么在Yolox中,是如何挑选正样本锚框的呢?
这里就涉及到两个关键点:初步筛选、SimOTA。
初步筛选的方式主要有两种:根据中心点来判断、根据目标框来判断;
寻找anchor_box中心点,落在groundtruth_boxes矩形范围的所有anchors
以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。
我们将SimOTA的前后流程进行拆解,看一下是如何进行精细化筛选的?
整个筛选流程,主要分为四个阶段:
a.初筛正样本信息提取
b.Loss函数计算
c.cost成本计算
d.SimOTA求解
(4)Loss计算
在前面精细化筛选中,使用了reg_loss和cls_loss,筛选出和目标框所对应的预测框。
在Decoupled Head中,cls_output和obj_output使用了sigmoid函数进行归一化
nchor_box中心点,落在groundtruth_boxes矩形范围的所有anchors
以groundtruth中心点为基准,设置边长为5的正方形,挑选在正方形内的所有锚框。
我们将SimOTA的前后流程进行拆解,看一下是如何进行精细化筛选的?
整个筛选流程,主要分为四个阶段:
a.初筛正样本信息提取
b.Loss函数计算
c.cost成本计算
d.SimOTA求解
(4)Loss计算
在前面精细化筛选中,使用了reg_loss和cls_loss,筛选出和目标框所对应的预测框。
在Decoupled Head中,cls_output和obj_output使用了sigmoid函数进行归一化
码字不易,都看到这里了不如点个赞哦~
我是【豆干花生】,你的点赞+收藏+关注,就是我坚持下去的最大动力~

亲爱的朋友,这里是我新成立的公众号,欢迎关注!
公众号内容包括但不限于人工智能、图像处理、信号处理等等~之后还将推出更多优秀博文,敬请期待! 关注起来,让我们一起成长!
