利用Tsfresh提取路况时序特征+路况热力图展示
tsfresh包用于提取时序特征并通过假设检验对特征进行筛选。
本文能够得到路况的热力图,所有路况的时序特征,利用样本筛选出来的特征和所有路况对应的筛选出来特征。
官方文档能够解决绝大部分问题,链接如下:
Quick Start — tsfresh 0.18.1.dev39+g611e04f documentation https://tsfresh.readthedocs.io/en/latest/text/quick_start.html利用tsfresh对时序进行分析有两种思路:
https://tsfresh.readthedocs.io/en/latest/text/quick_start.html利用tsfresh对时序进行分析有两种思路:
1.提供学习样本,进行特征值筛选
2.理解tsfresh提供的特征值类型,直接调用
本文通过思路1对路况数据进行处理,利用tsfresh进行特征提取和筛选
import pandas as pd
import numpy as np
df131=pd.read_csv('路况131.csv',encoding='gb2312')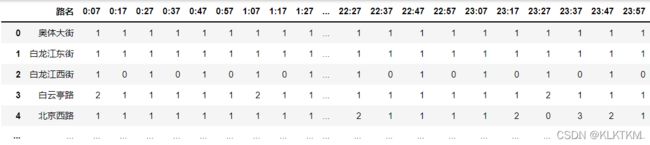
#利用热力图进行可视化
import matplotlib.pyplot as plt
import seaborn as sns #seaborn依赖于matplotlib
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei') # 解决Seaborn中文显示问题
df131=df131.set_index('路名') #需要将路名转换为索引->直接df读进来路名已经是索引
plt.figure(dpi=100, figsize=(20,30)) #(xlable,ylabe)
sns.heatmap(df131,cmap="YlOrRd",annot=False,xticklabels=1,yticklabels=1,cbar=True) #具体调整参数见seaborn文档
plt.tick_params(labelsize=15)
#可视化样本路况
#case_sample文件为样本道路的路名和人为划分的类别,两列名称为namey,casey,将路况分为6类
dfsam=pd.read_csv('case_sample.csv',encoding='gb2312')
frame=pd.DataFrame()
for i in dfsam['namey']:
for index,row in df131.iterrows():
if row['路名']==i:
frame=frame.append(row)
frame.to_csv('sample_time.csv',encoding='gb2312',index=True)
frame=frame.set_index('路名') #需要将路名转换为索引
plt.figure(dpi=100, figsize=(20,5)) #(xlable,ylabe)
sns.heatmap(frame,annot=False,xticklabels=1,yticklabels=1,cbar=False)
plt.tick_params(labelsize=15)
利用tsfresh对时序进行提取首先需要使数据符合tsfresh给出的标准格式
#处理路况矩阵,将原数据以路名-时间-路况值展开
df131=pd.read_csv('路况131.csv',encoding='gb2312')
data = df131.values #data为numpy.ndarray
[rows,cols]=data.shape
frame=[]
for line in range(rows):
for i in range(cols):
dic={}
dic["name"]=data[line,0]
dic["time"]=i
dic["condition"]=data[line,i]
frame.append(dic)
df131_new=pd.DataFrame(frame)
df131_new=df131_new.drop(df131_new[df131_new["time"]==0].index)
df131_new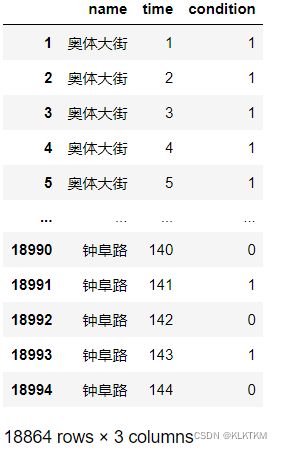 这个是全部131条道路的展开数据
这个是全部131条道路的展开数据
#样本的展开数据
#df131_new=pd.read_csv('time131_list.csv',encoding='gb2312')
#dfsample=pd.read_csv('case_sample.csv',encoding='gb2312')
dfsample0=pd.DataFrame()
for i in dfsample['namey']:
for index,row in df131_new.iterrows():
if row['name']==i:
dfsample0=dfsample0.append(row)
dfsample0  这个是样本道路的展开数据
这个是样本道路的展开数据
#利用tsfresh进行特征提取
import tsfresh
from tsfresh import extract_features
#time1中131条路的指标值
Xtime2 = extract_features(df131_new, column_id='name', column_sort='time')
Xtime2.to_csv('trait_time.csv',encoding='gb2312')#保存所有特征用于之后的分析用
#得到sample指标
Xsample = extract_features(dfsample, column_id='name', column_sort='time')
Xsample 
#找到sample的对应y,并按照Xsample中的路名顺序排列
ysample=pd.DataFrame()
ydf=pd.read_csv('case_sample.csv',encoding='gb2312')
for index,row in Xsample.iterrows():
for yindex,yrow in ydf.iterrows():
if yrow[0]==index:
ysample=ysample.append(yrow)
print(ysample)
ysample_s=pd.Series(ysample['casey'])
ysample_s.index=ysample['namey']
print(ysample_s)
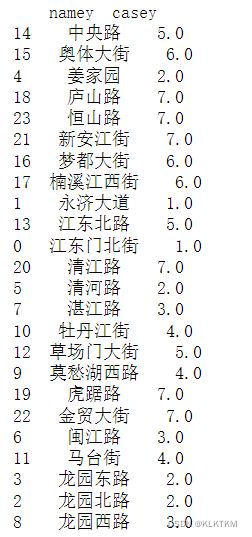

#筛选指标
from tsfresh import select_features
from tsfresh.utilities.dataframe_functions import impute
impute(Xsample)
filtered_features = select_features(Xsample,ysample_s)
#filtered_features = select_features(Xsample,ysample_s,fdr_level=0.05)#最后一个参数是调整置信区间,晒不出来特征值的时候可以将最后一个参数调大
filtered_features 
#对筛选指标结果进行排序
order=pd.DataFrame()
for index,row in ydf.iterrows():
for findex,frow in filtered_features.iterrows():
if row[0]==findex:
order=order.append(frow)
order.to_csv('fliter_time.csv',encoding='gb2312',index=True)
#按照筛出来的特征值得到131条路里的特征值
dfall=pd.read_csv('trait_time.csv',encoding='gb2312')
dfselect=pd.DataFrame()
for i in order.columns:
dfselect[i]=dfall[i]
dfselect.index=dfall['Unnamed: 0']
dfselect.to_csv('all_time.csv',encoding='gb2312',index=True)根据以上操作得到路况的热力图,所有路况的时序特征:trait_time.csv,利用样本筛选出来的特征:fliter_time.csv,所有路况对应的筛选出来特征:all_time.csv
欢迎交流,改进代码