数据集学习笔记(一):常用检测、行为检测数据集
文章目录
- 常用检测数据集
-
-
- 一 CIFAR系列
- 二 COCO
- 三 VOC系列
- 四 CIFAR10
- 五、TT100K
- 六 将图像数据集划分为训练集,验证集,测试集
-
- 常用行为检测数据集
-
-
- UCF101
-
常用检测数据集
一 CIFAR系列
CIFAR10有6w张32*32的图片,一共有10个类别,每个类别6000张,5w张训练,1w张测试。
数据集实际被分为6batches,5份训练,1份测试,每份均为1w张。测试集的1w张,是随机从10个类别中分别抽取的1000张,类别完全均衡。5份训练集中,可能某份内,一个类别的数据比另一个类别少或多,但是整体5份里面各类数据的总和是5000份。

从官网下载的数据已经不是原始图片啦,而是经过数值化的numpy数组
- 数据读取
- 确定文件路径
file_data_batch_1 = '.\\major_dataset_repo\\cifar10\\data_batch_1'
file_data_batch_2 = '.\\major_dataset_repo\\cifar10\\data_batch_2'
file_data_batch_3 = '.\\major_dataset_repo\\cifar10\\data_batch_3'
file_data_batch_4 = '.\\major_dataset_repo\\cifar10\\data_batch_4'
file_data_batch_5 = '.\\major_dataset_repo\\cifar10\\data_batch_5'
file_batches_meta = '.\\major_dataset_repo\\cifar10\\batches.meta'
file_test_batch = '.\\major_dataset_repo\\cifar10\\test_batch'
- 将数据文件转为dict
def unpickle(file): # 该函数将cifar10提供的文件读取到python的数据结构(字典)中
import pickle
fo = open(file, 'rb')
dict = pickle.load(fo, encoding='iso-8859-1')
fo.close()
return dict
- 查看训练集
dict_train_batch1 = unpickle(file_data_batch_1) # 将data_batch文件读入到数据结构(字典)中
print(dict_train_batch1.keys()) # 字典里有4组键值对
print(dict_train_batch1) # 每个batch是一个字典
#训练集的dict有四组值
"""
batch_label:表示是第几个训练集
labels:每张训练图片对应的label,data每一行对应的标签(数字0-9),是个一维数组,10000个元素
data:训练集数据(数据在0-255之间),32*32图片的数值化数组,是一个10000*3072的numpy二维数组, 每一行代表一张图片,一行分3段(红绿蓝色道),每段1024个元素
filenames:每张训练图片数据的名字(png格式), data每一行对应的文件名,同是一个一维数组,10000个元素
"""
- 写入文件夹
for i in range(5):
dict_train_batch = unpickle(file_data_batch_list[i])
data_train_batch = dict_train_batch.get('data') # 字典中取data
labels = dict_train_batch.get('labels') # 字典中取labels
for j in range(10000):
matrix = np.reshape(data_train_batch[j], (3, 32, 32))
matrix = matrix.transpose(1, 2, 0)
label = labels[j]
cv2.imwrite("./image/"+str(label)+"/"+str(i)+"_"+str(j)+".png", matrix)
二 COCO
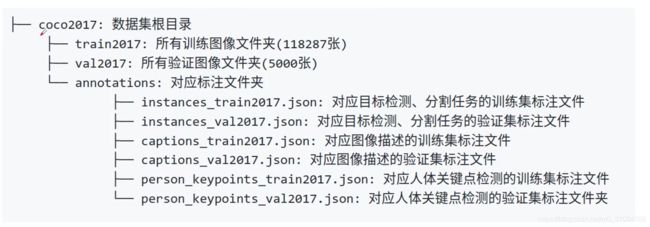
80个类别, MS COCO的全称是Microsoft Common Objects in Context,起源于是微软于2014年出资标注的Microsoft COCO数据集,与ImageNet 竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
当在ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检测等领域的一个最权威、最重要的标杆,也是目前该领域在国际上唯一能汇集Google、微软、Facebook以及国内外众多顶尖院校和优秀创新企业共同参与的大赛。
该数据集主要解决3个问题:目标检测,目标之间的上下文关系,目标的2维上的精确定位。COCO数据集有91类,虽然比ImageNet和SUN类别少,但是每一类的图像多,这有利于获得更多的每类中位于某种特定场景的能力,对比PASCAL VOC,其有更多类和图像。
COCO数据集包含20万个图像;
80个类别中有超过50万个目标标注,它是最广泛公开的目标检测数据库;
平均每个图像的目标数为7.2,这些是目标检测挑战的著名数据集。
2014年数据集的下载:https://link.csdn.net/?target=http%3A%2F%2Fmsvocds.blob.core.windows.net%2Fcoco2014%2Ftrain2014.zip
2017的数据集的下载
http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/annotations/annotations_trainval2017.zip
http://images.cocodataset.org/zips/val2017.zip
http://images.cocodataset.org/annotations/stuff_annotations_trainval2017.zip
http://images.cocodataset.org/zips/test2017.zip
http://images.cocodataset.org/annotations/image_info_test2017.zip
COCO数据集使用:https://www.cnblogs.com/Meumax/p/12021913.html
class_names: ['person','bicycle','car','motorcycle','airplane','bus','train','truck','boat','traffic light','stop sign','parking meter','bench','bird','cat',
'dog','horse','sheep','cow','elephant','bear','zebra','giraffe','backpack','umbrella','handbag','tie','suitcase','frisbee','skis','snowboard','sports ball',
'kite','baseball bat','baseball glove','skateboard','surfboard','tennis racket','bottle','wine glass','cup','fork','knife','spoon','bowl','banana','apple',
'sandwich','orange','broccoli','carrot','hot dog','pizza','donut','cake','chair','couch','potted plant','bed','dining table','toilet','tv','laptop','mouse','remote','keyboard',
'cell phone','microwave','oven','toaster','sink','refrigerator','book','clock','vase','scissors','teddy bear','hair drier','toothbrush']
三 VOC系列
四 CIFAR10
https://blog.csdn.net/Teeyohuang/article/details/79210525?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162961674416780269871680%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162961674416780269871680&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2allbaidu_landing_v2~default-1-79210525.pc_search_result_control_group&utm_term=torchvision%E5%8A%A0%E8%BD%BDCIFAR-10&spm=1018.2226.3001.4187
五、TT100K
交通目标检测数据集
TT100K字面的意思就是腾讯和清华一起合作制作的交通标志数据集(100K就是10万张)
但是,里面差不多有1万多张图片有包含交通标志,训练数据集(train文件夹里面是有6105张图片),测试数据集(test文件夹里面是有3071张图片),当然每张图片包含多个实例,图片的标注文件格式是json,经过计算,训练数据集总共包含16527个实例,测试数据集包含8190个实例。
mkdir TT100K && cd TT100K
wget http://cg.cs.tsinghua.edu.cn/traffic-sign/data_model_code/data.zip
wget http://cg.cs.tsinghua.edu.cn/traffic-sign/data_model_code/code.zip
六 将图像数据集划分为训练集,验证集,测试集
# -*- coding: utf-8 -*-
"""
将数据集划分为训练集,验证集,测试集
"""
import os
import random
import shutil
# 创建保存图像的文件夹
def makedir(new_dir):
if not os.path.exists(new_dir):
os.makedirs(new_dir)
random.seed(1) # 随机种子
# 1.确定原图像数据集路径
dataset_dir = os.path.join(".", "major_dataset_repo", "image")
# 2.确定数据集划分后保存的路径
split_dir = os.path.join(".", "major_dataset_repo", "split_data")
train_dir = os.path.join(split_dir, "train")
valid_dir = os.path.join(split_dir, "valid")
test_dir = os.path.join(split_dir, "test")
# 3.确定将数据集划分为训练集,验证集,测试集的比例
train_pct = 0.8
valid_pct = 0.1
test_pct = 0.1
# 4.划分
for root, dirs, files in os.walk(dataset_dir):
for sub_dir in dirs: # 遍历0,1,2,3,4,5...9文件夹
imgs = os.listdir(os.path.join(root, sub_dir)) # 展示目标文件夹下所有的文件名
imgs = list(filter(lambda x: x.endswith('.png'), imgs)) # 取到所有以.png结尾的文件,如果改了图片格式,这里需要修改
random.shuffle(imgs) # 乱序图片路径
img_count = len(imgs) # 计算图片数量
train_point = int(img_count * train_pct) # 0:train_pct
valid_point = int(img_count * (train_pct + valid_pct)) # train_pct:valid_pct
for i in range(img_count):
if i < train_point: # 保存0-train_point的图片到训练集
out_dir = os.path.join(train_dir, sub_dir)
elif i < valid_point: # 保存train_point-valid_point的图片到验证集
out_dir = os.path.join(valid_dir, sub_dir)
else: # 保存valid_point-结束的图片到测试集
out_dir = os.path.join(test_dir, sub_dir)
makedir(out_dir) # 创建文件夹
target_path = os.path.join(out_dir, imgs[i]) # 指定目标保存路径
src_path = os.path.join(dataset_dir, sub_dir, imgs[i]) #指定目标原图像路径
shutil.copy(src_path, target_path) # 复制图片
print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,
img_count-valid_point))
常用行为检测数据集
UCF101
- 数据集:UCF101:链接:https://gas.graviti.cn/dataset/hello-dataset/UCF101/download
- 数据集大小为6.46G,主要包括5大类动作 :人与物体交互,单纯的肢体动作,人与人交互,演奏乐器,体育运动。
具体类别:涂抹眼妆,涂抹口红,射箭,婴儿爬行,平衡木,乐队游行,棒球场,篮球投篮,篮球扣篮,卧推,骑自行车,台球射击,吹干头发,吹蜡烛,体重蹲,保龄球,拳击沙袋,拳击速度袋,蛙泳,刷牙,清洁和挺举,悬崖跳水,板球保龄球,板球射击,在厨房切割,潜水,打鼓,击剑,曲棍球罚款,地板体操,飞盘接球,前爬网,高尔夫挥杆,理发,链球掷,锤击,倒立俯卧撑,倒立行走,头部按摩,跳高,跑马,骑马,呼啦圈,冰舞,标枪掷,杂耍球,跳绳,跳跃杰克,皮划艇,针织,跳远,刺,阅兵,混合击球手,拖地板,修女夹头,双杠,披萨折腾,弹吉他,弹钢琴,弹塔布拉琴,弹小提琴,弹大提琴,弹Daf,弹Dhol,弹长笛,弹奏锡塔琴,撑竿跳高,鞍马,引体向上,拳打,俯卧撑,漂流,室内攀岩,爬绳,划船,莎莎旋转,剃胡子,铅球,滑板溜冰,滑雪,Skijet,跳伞,足球杂耍,足球罚球,静环,相扑摔跤,冲浪,秋千,乒乓球拍,太极拳,网球秋千,投掷铁饼,蹦床跳跃,打字,高低杠,排球突刺,与狗同行,墙上俯卧撑,在船上写字,溜溜球。剃胡须,铅球,滑冰登机,滑雪,Skijet,跳伞,足球杂耍,足球罚款,静物环,相扑,冲浪,秋千,乒乓球射击,太极拳,网球秋千,掷铁饼,蹦床跳跃,打字,不均匀酒吧,排球突刺,与狗同行,壁式俯卧撑,船上写字,溜溜球。剃胡须,铅球,滑冰登机,滑雪,Skijet,跳伞,足球杂耍,足球罚款,静物环,相扑,冲浪,秋千,乒乓球射击,太极拳,网球秋千,掷铁饼,蹦床跳跃,打字,不均匀酒吧,排球突刺,与狗同行,壁式俯卧撑,船上写字,溜溜球