皮马印第安人糖尿病数据集——模型评估
一、数据集介绍
PimaIndiansdiabetes.csv
这个数据集的原始数据来自国家糖尿病消化和肾病机构。数据集的目的是基于数据集中确定的诊断测量指标来预测一个患者是否患有糖尿病。在从更大的数据库中选择这些实例时受到了一些限制。特别是,所有收录于数据集的患者都是至少21周岁的皮马印第安女性。
数据集包括多个医学预测变量和一个目标变量。预测变量包括患者的怀孕次数,她们的BMI指数,胰岛素水平,年龄等。
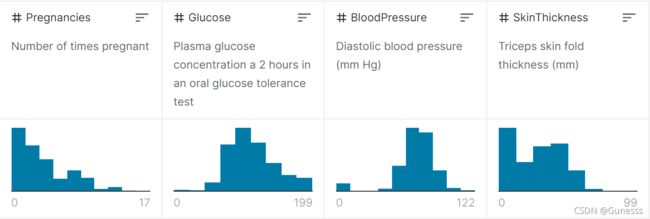
上图从左至右分别为:怀孕次数、葡萄糖、血压、皮肤厚度
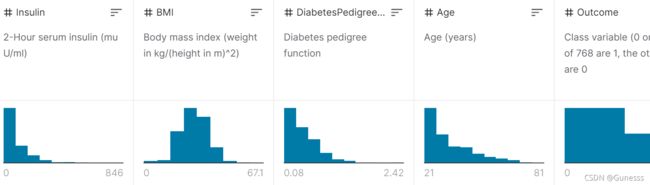
上图从左至右分别为: 胰岛素、BMI指数、糖尿病谱系、年龄、Outcome类标变量(分类:0或1,768人中的268人为1(患病),其他人为0(不患病))
二、模型评估:逻辑回归、混淆矩阵、召回率、F1分数
- 数据预处理
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
#数据预处理
path = 'E:/PimaIndiansdiabetes.csv'
pima = pd.read_csv(path)
print(pima.head())
- X,y赋值和维度确认
#X,y赋值
feature_names = ['Pregnancies','Insulin','BMI','Age']
X = pima[feature_names]
y = pima.Outcome
#维度确认
print(X.shape)
print(y.shape)
- 数据分离
#数据分离
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
- 模型训练
#模型训练
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
- 测试数据集结果预测
#测试数据集结果预测
y_pred = logreg.predict(X_test)
- 使用准确率进行评估
#使用准确率进行评估
from sklearn import metrics
print(metrics.accuracy_score(y_test,y_pred))
- 确认正负样本数据量,0,1的比例,空准确率
#确认正负样本数据量
#y_test.value_counts()
#0,1的比例
#y_test.mean()
#1-y_test.mean()
#空准确率
#max(y_test.mean(),1-y_test.mean())
- 计算并展示混淆矩阵,展示部分实际结果与预测结果
#计算并展示混淆矩阵
print(metrics.confusion_matrix(y_test,y_pred))
#展示部分实际结果与预测结果(25组)
print("true:",y_test.values[0:25])
print("pred:",y_pred[0:25])
- 四个因子赋值,计算正确率、错误率、召回率、特异度、精确率、F1分数
#四个因子赋值
confusion = metrics.confusion_matrix(y_test,y_pred)
TN = confusion[0,0]
FP = confusion[0,1]
FN = confusion[1,0]
TP = confusion[1,1]
print(TN,FP,FN,TP)
#正确率
accuracy = (TP + TN)/(TP +TN + FP + FN)
print(accuracy)
print(metrics.accuracy_score(y_test,y_pred))
#错误率:整体样本中,预测错误样本数的比例
mis_rate = (FP + FN)/(TP + TN + FP + FN)
print(mis_rate)
print(1 - metrics.accuracy_score(y_test,y_pred))
#灵敏度(召回率):正样本中,预测正确的比例
recall = TP / (TP + FN)
print(recall)
#特异度:负样本中,预测正确的比例
specificity = TN/(TN + FP)
print(specificity)
#精确率:预测结果为正的样本中,预测正确的比例
precision = TP/(TP + FP)
print(precision)
#F1分数:综合Precision和Recall的一个判断指标
f1_score = 2*precision*recall/(precision + recall)
print(f1_score)
结论:
- 分类任务中,相比单一的预测准确率,混淆矩阵提供了更全面的模型评估信息
- 通过混淆矩阵,我们可以计算出多样的模型表现衡量指标,从而更好地选择模型