TCN代码详解-Torch (误导纠正)
TCN代码详解-Torch (误导纠正)
1. 绪论
TCN网络由Shaojie Bai, J. Zico Kolter, Vladlen Koltun 三人于2018提出。对于序列预测而言,通常考虑循环神经网络结构,例如RNN、LSTM、GRU等。他们三个人的研究建议我们,对于某些序列预测(音频合成、字级语言建模和机器翻译),可以考虑使用卷积网络结构。
关于TCN基本构成和他们的原理有相当多的博客已经解释的很详细的了。总结一句话:TCN = 1D FCN + 因果卷积。下面的博客对因果卷积和孔洞卷积有详细的解释。
- 时间卷积网络(TCN):结构+pytorch代码
- TCN论文及代码解读总结
- 时间序列分析(5) TCN
但是,包括TCN原文作者,上面这些博客对TCN网络结构的阐释无一例外都是使用下面这张图片。而问题在于,如果不熟悉Torch操作和基本的卷积网络操作,这张图片具有很大的误导性。
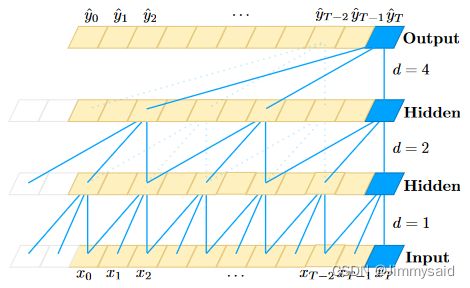 图1 膨胀因果卷积(膨胀因子d = 1,2,4,滤波器大小k = 3)
图1 膨胀因果卷积(膨胀因子d = 1,2,4,滤波器大小k = 3)
结合上图和上面列举的博客,我们可以大致理解到,TCN就是在序列上使用一维卷积核,沿着时间方向,按照空洞卷积的方式,依次计算。
例如,上图中,
- 第一个hidden层是由 d = 1 d=1 d=1 的空洞卷积,卷积而来,退化为基本的一维卷积操作;
- 第二个hidden层是由 d = 2 d=2 d=2 的空洞卷积,卷积而来,卷积每个值时隔开了一个值;
- 第二个hidden层是由 d = 4 d=4 d=4 的空洞卷积,卷积而来,卷积每个值时隔开了三个值;
由此,上图中网络深度为3,每一层有1个卷积操作。
如果你也是这么理解,恭喜你,成功的被我带跑偏了。
2. TCN结构再次图解
上图中网络深度确实为3,但是每一层并不是只有1个卷积操作。这时候就要拿出原论文中第2个图了。
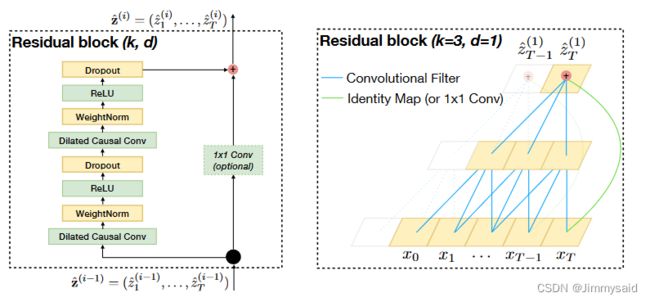
图2 TCN核心结构
这张图左边展示了TCN结构的核心,卷积+残差,作者把它命名为Residual block。我这里简称为block。
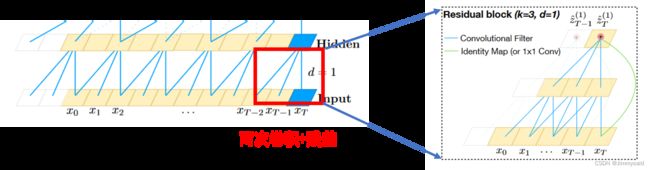
可以发现一个block有两个卷积操作和一个残差操作。因此,图1中每到下一层,都会有两个卷积操作和一个残差操作,并不是一个卷积操作。再次提醒,当 d = 1 d=1 d=1 时,空洞卷积退化为普通的卷积,正如图2右图展示的。
因此,对于图1中由原始序列到第一层hidden的真实结构为:
3. 结合原文的torch代码解释
很多博客再源代码解释时,基本都是一个模子,没有真正解释关键参数的含义,以及他们如何通过torch的tensor作用的。
预了解TCN结构,须明白原论文中作者描述的这样一句话:
Since a TCN’s receptive field depends on the network depth n as well as filter size k and dilation factor d, stabilization of deeper and larger TCNs becomes important.
翻译是:
由于TCN的感受野依赖于网络深度n、滤波器大小k和扩张因子d,因此更大更深的TCN的稳定变得很重要。
下面结合作者源代码,对这三个参数解释。
3.1 TemporalConvNet
网络深度n就是有多少个block,反应到源代码的变量为num_channels的长度,即 l e n ( n u m c h a n n e l s ) len(num_channels) len(numchannels)。
class TemporalConvNet(nn.Module):
def __init__(self, num_inputs, num_channels, kernel_size=2, dropout=0.2):
super(TemporalConvNet, self).__init__()
"""
:param num_inputs: int, 输入通道数或者特征数
:param num_channels: list, 每层的hidden_channel数. 例如[5,12,3], 代表有3个block,
block1的输出channel数量为5;
block2的输出channel数量为12;
block3的输出channel数量为3.
:param kernel_size: int, 卷积核尺寸
:param dropout: float, drop_out比率
"""
layers = []
num_levels = len(num_channels)
# 可见,如果num_channels=[5,12,3],那么
# block1的dilation_size=1
# block2的dilation_size=2
# block3的dilation_size=4
for i in range(num_levels):
dilation_size = 2 ** i
in_channels = num_inputs if i == 0 else num_channels[i-1]
out_channels = num_channels[i]
layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,
padding=(kernel_size-1) * dilation_size, dropout=dropout)]
self.network = nn.Sequential(*layers)
def forward(self, x):
return self.network(x)
3.2 TemporalBlock
参数dilation的解释,结合上面和下面的代码。
class TemporalBlock(nn.Module):
def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):
super(TemporalBlock, self).__init__()
"""
构成TCN的核心Block, 原作者在图中成为Residual block, 是因为它存在残差连接.
但注意, 这个模块包含了2个Conv1d.
:param n_inputs: int, 输入通道数或者特征数
:param n_outputs: int, 输出通道数或者特征数
:param kernel_size: int, 卷积核尺寸
:param stride: int, 步长, 在TCN固定为1
:param dilation: int, 膨胀系数. 与这个Residual block(或者说, 隐藏层)所在的层数有关系.
例如, 如果这个Residual block在第1层, dilation = 2**0 = 1;
如果这个Residual block在第2层, dilation = 2**1 = 2;
如果这个Residual block在第3层, dilation = 2**2 = 4;
如果这个Residual block在第4层, dilation = 2**3 = 8 ......
:param padding: int, 填充系数. 与kernel_size和dilation有关.
:param dropout: float, dropout比率
"""
self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
# 因为 padding 的时候, 在序列的左边和右边都有填充, 所以要裁剪
self.chomp1 = Chomp1d(padding)
self.relu1 = nn.ReLU()
self.dropout1 = nn.Dropout(dropout)
self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,
stride=stride, padding=padding, dilation=dilation))
self.chomp2 = Chomp1d(padding)
self.relu2 = nn.ReLU()
self.dropout2 = nn.Dropout(dropout)
self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,
self.conv2, self.chomp2, self.relu2, self.dropout2)
# 1×1的卷积. 只有在进入Residual block的通道数与出Residual block的通道数不一样时使用.
# 一般都会不一样, 除非num_channels这个里面的数, 与num_inputs相等. 例如[5,5,5], 并且num_inputs也是5
self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else None
# 在整个Residual block中有非线性的激活. 这个容易忽略!
self.relu = nn.ReLU()
self.init_weights()
def init_weights(self):
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
if self.downsample is not None:
self.downsample.weight.data.normal_(0, 0.01)
def forward(self, x):
out = self.net(x)
res = x if self.downsample is None else self.downsample(x)
return self.relu(out + res)
3.3 Chomp1d
裁剪模块。这里注意,padding的时候对数据列首尾都添加了,torch官方解释如下:
padding controls the amount of padding applied to the input. It can be either a string {‘valid’, ‘same’} or a tuple of ints giving the amount of implicit padding applied on both sides.
注意这里是both sides。例如,还是上述代码中的例子,kernel_size = 3,在第一层(对于第一个block),padding = 2。对于长度为20的序列,先padding,长度为 20 + 2 × 2 = 24 20+2\times2=24 20+2×2=24,再卷积,长度为 ( 24 − 3 ) + 1 = 22 (24-3)+1=22 (24−3)+1=22。所以要裁掉,保证输出序列与输入序列相等。
class Chomp1d(nn.Module):
def __init__(self, chomp_size):
super(Chomp1d, self).__init__()
self.chomp_size = chomp_size
def forward(self, x):
return x[:, :, :-self.chomp_size].contiguous()
4. 验证TCN的输入输出
根据上述代码的解释和理解,我们可以方便的验证其输入和输出。
# 输入27个通道,或者特征
# 构建1层的TCN,最后输出一个通道,或者特征
model2 = TemporalConvNet(num_inputs=27, num_channels=[32,16,4,1], kernel_size=3, dropout=0.3)
import torch
# 检测输出
with torch.no_grad():
# 模型输入一定是 (batch_size, channels, length)
model2.eval()
print(model2(torch.randn(16,27,20)).shape)
打印结果为(16, 1, 20) 。通道数降为1。输入序列长度20, 输出序列长度也是20。