K-Bert 详解
文章目录
- 1. Introduction
-
- 1.1 问题陈述
- 1.2 解决办法
- 1.3 论文贡献
- 2. 模型
-
- 2.1 符号表示
- 2.2 模型架构
- 2.3 Knowledge Layer
- 2.4 Embedding Layer
-
- 2.4.1 Token Embedding
- 2.4.2 Soft-position Embedding
- 2.4.3 Segment Embedding
- 2.5 Seeing Layer
- 2.6 Mask-Transformer
-
- 2.6.1 Mask-Self-Attention
- 3. 实验结果
-
- 3.1 预训练语料库
- 3.2 知识图谱
- 3.3 基线
- 3.4 参数设置和训练细节
- 3.5 开放领域任务
- 3.6 特定领域任务
- 3.7 消融研究
文章链接:https://arxiv.org/pdf/1909.07606.pdf
代码链接: https://github.com/autoliuweijie/K-BERT
Reference: https://zhuanlan.zhihu.com/p/215229044
https://mp.weixin.qq.com/s/adDlczWM5ZVQz9EDJEtjng
https://blog.csdn.net/Coding_1995/article/details/106203269
本论文是由北京大学、腾讯实验室和北京师范大学的七位作者于2020年3月在AAAI2020会议上提出的。文章把知识图谱(KG)应用在BERT中创建了K-BERT模型,用以解决BERT模型在专业领域表现不佳的问题,一举解决了异构嵌入空间(HES)和知识噪声(KN)两大问题。
1. Introduction
1.1 问题陈述
近年来,像BERT(Devlin et al. 2018)这样的无监督的预训练语言表示模型在多个NLP任务中都取得了令人鼓舞的结果。 这些模型在大规模开放域语料库上进行了预训练,以获得通用的语言表示形式,然后在特定的下游任务中进行微调以吸收特定领域的知识。 但是,由于预训练和微调之间的领域差异,这些模型在知识驱动的任务上表现不佳。 例如,在医疗领域处理电子病历(EMR)分析任务时,经过维基百科预训练的BERT无法充分发挥其价值。
对于特殊领域的文本,一般人只能理解字面上表达的,但是专家能够根据相关领域知识进行推理。像BERT这种公共模型就像普通人一样,对于通用领域表现优秀,但是垂直领域表现不佳,除非在垂直领域进行训练,但是非常耗时耗力。
目前已经构建了大量知识图谱,将知识图谱整合到语言表示中,领域知识将能提升垂直领域的任务,并且模型具有更好的可解释性。
1.2 解决办法
预训练模型能够捕捉常见的语言表示,但是缺少领域知识,为了实现这种能力提出了一种具有知识图谱的语言表示模型(K-BERT),将三元组作为领域知识注入句子中。
如何将外部知识整合到模型中成了一个关键点,这一步通常存在两个难点:
- 异构嵌入空间(Heterogeneous Embedding Space): 即文本的单词embedding和知识库的实体embedding通常是通过不同方式获取的,使得向量空间不一致。
- 知识噪声(Knowledge Noise): 即过多的知识融合可能会使原始句子偏离正确的本意。
为了解决这些问题,文章提出一种基于知识图谱的语言表示模型——Knowledge-enabled Bidirectional Encoder Representation from Transformers (K-BERT)。K-BERT能够与BERT模型兼容,加载任何预先训练好的BERT模型;并且通过配置KG可以很容易地将领域知识注入到模型中,而不需要预训练。另外,该模型引入了软位置和可见矩阵来限制知识的影响以克服知识噪音。
1.3 论文贡献
- 提出知识集成语言表示模型,能够解决异构空间嵌入问题和知识噪音问题。
- 通过注入知识图谱,不仅垂直领域的任务得到提升,通用领域也有提升。
- 代码公开 https://github.com/autoliuweijie/K-BERT
2. 模型
2.1 符号表示
英语中的token是在word-level,而中文中的token是在char-level。
将句子 s s s 表示成token序列,即 s = { w 0 , w 1 , … , w n } s=\{w_0,w_1,\dots,w_n\} s={w0,w1,…,wn},其中 n n n 是句子长度;
所有的 w i w_i wi 均存在于词表 V \mathbb{V} V ,即 w i ∈ V w_i\in\mathbb{V} wi∈V ;
知识图谱表示为 K \mathbb{K} K ;
图谱 K \mathbb{K} K 中的三元组表示为 ε = ( w i , r i , w k ) \varepsilon=(w_i,r_i,w_k) ε=(wi,ri,wk), ε ∈ K \varepsilon \in \mathbb K ε∈K。其中 w i w_i wi 和 w k w_k wk 是实体的名称, r j ∈ V r_j\in\mathbb{V} rj∈V 是两个实体的关系;
2.2 模型架构
K-BERT模型主要包括四部分:知识层(Knowledge layer)、嵌入层(Embedding layer)、可见层(Seeing layer)和 Mask-Transformer编码层(Mask-Transformer Encoder)
其模型结构如图:

图 1 K − B E R T 的 模 型 结 构 图1 \space K-BERT的模型结构 图1 K−BERT的模型结构
K-BERT模型的每一部分都有着不可或缺的作用。对于输入的句子,知识层首先从KG向其注入相关的三元组,将原始句子转换为知识丰富的句子树。然后将句子树同时馈送到嵌入层和视觉层,然后将其转换为符号级嵌入表示和可视矩阵。可见矩阵用于控制每个符号的可见区域,防止由于注入过多的知识而改变原句的意思。
2.3 Knowledge Layer
知识层负责将知识图谱中的知识注入到句子中,形成句子树。更正式的来说,给定一个句子 s = { w 0 , w 1 , w 2 , … , w n } s = \{ w_0 , w_1 , w_2 , \dots , w_n \} s={w0,w1,w2,…,wn} 和一个知识图谱 K \mathbb{K} K,知识层输出的矩阵树为: t = { w 0 , w 1 , … , w i { ( r i 0 , w i 0 ) , … , ( r i k , w i k ) } , … , w n } t=\{w_0,w_1,\dots,w_i\{(r_{i0},w_{i0}),\dots,(r_{ik},w_{ik})\},\dots,w_n\} t={w0,w1,…,wi{(ri0,wi0),…,(rik,wik)},…,wn}。

上面转换句子树可以分为两个步骤K-Query(知识查询)和K-Inject(知识注入)。
-
K-Query:负责从知识图谱中找出 s s s 中所有实体所涉及到的三元组,即 E = K _ Q u e r y ( s , K ) E=K\space \_ Query(s,K) E=K _Query(s,K)。其中, E = { ( w i , r i 0 , w i 0 ) , … , ( w i , r i k , w i k ) } E=\{(w_i,r_{i0},w_{i0}),\dots,(w_i,r_{ik},w_{ik})\} E={(wi,ri0,wi0),…,(wi,rik,wik)} 是对应三元组的集合。
-
K-Inject:负责将三元组集合 E E E 加到句子 s s s 中,构造句子树 t t t,即 t = K _ I n j e c t ( s , E ) t=K\space \_Inject(s,E) t=K _Inject(s,E)

2.4 Embedding Layer
由于传统的BERT模型只能处理序列结构的句子输入,而句子树无法直接输入,如果强行把句子树转换成序列就会丢失结构信息。因此,在转换过程中要保留树结构的结构信息,这是K-BERT模型的关键。K-BERT的Embedding层类似于BERT的Embedding层,也是由token embedding、position embedding和segment embedding组成。而与Bert不同的是K-BERT引入了soft-position embedding。
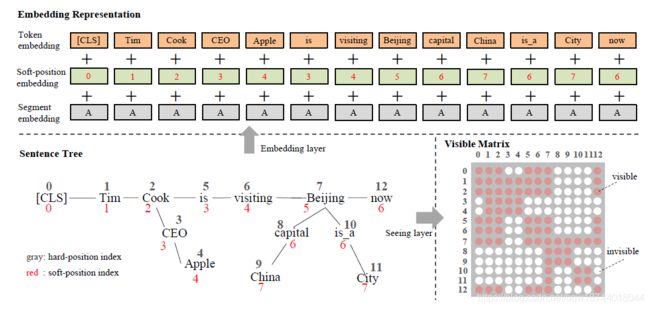
图 2 K − B E R T 流 程 图2\space K - BERT流程 图2 K−BERT流程
- 在句子树中,红色数字是软位置索引,灰色是硬位置索引。
- 为了进行令牌嵌入,将句子树中的令牌通过其硬位置索引展平为一系列令牌嵌入;
- 将软位置索引与令牌嵌入一起用作位置嵌入;
- 在段嵌入中,第一句中的所有标记都标记为“ A”;
- 在可见矩阵中,红色表示可见,白色表示不可见。例如,第4行第9列的单元格为白色表示“Apple(4)”看不到“ China(9)”。
2.4.1 Token Embedding
与BERT完全相同。每个token转换为 H H H 维的向量,并且使用 [CLS] \text{[CLS]} [CLS] 作为分类标签 [MASK] \text{[MASK]} [MASK]作为掩码。特别地是,这里需要将句子树拉平。具体的作法是,将分支拼接在对应token的后面,其后的原始token依次后移。而这样的方式导致了句子不可读并且丢失了结构信息,但是可以通过后面的soft-position和visible matrix来解决该问题。具体原理见图二。
2.4.2 Soft-position Embedding
对于BERT来说,如果没有位置嵌入,那么它的作用就会仅仅如同一个词袋模型。对于重排后的句子,由于丢失了结构信息,作者希望可以利用软位置嵌入来补充结构信息。位置信息的编写方式是,主干持续编号,支节继续编号。该方法仍然遗留的一个问题是作者不希望实体对应三元组的内容影响到句子中其他词的表示(KN 问题,比如说:[is] 和 [CEO] 的位置编号都是 3,这使得它们在计算 self-attention 时位置接近,但实际上它们之间没有联系),因此需要后面的Mask-Self-Attention来解决。
2.4.3 Segment Embedding
和BERT一样,K-BERT也使用Segment embedding 来表示不同的句子。比如,对于句子 { w 00 , w 01 , … , w 0 n } \left\{w_{00}, w_{01}, \dots, w_{0 n}\right\} {w00,w01,…,w0n} 和 { w 10 , w 11 , … , w 1 m } \left\{w_{10}, w_{11}, \dots, w_{1 m}\right\} {w10,w11,…,w1m},把他们整合为一个句子: { [ C L S ] , w 00 , w 01 , … , w 0 n , [ S E P ] , w 10 , w 11 , … , w 1 m } \left\{[C L S], w_{00}, w_{01}, \dots, w_{0 n},[S E P], w_{10}, w_{11}, \dots, w_{1 m}\right\} {[CLS],w00,w01,…,w0n,[SEP],w10,w11,…,w1m},为了标记出每个句子,需要标签 { A , A , A , A , … , A , B , B , … , B } \{A, A, A, A, \ldots, A, B, B, \ldots, B\} {A,A,A,A,…,A,B,B,…,B}。
2.5 Seeing Layer
Seeing layer是K-BERT与BERT之间最大的不同,也是K-BERT有效的原因。由于句子树中的三元组可能影响原始句子的含义。例如,图2中的 C h i n a China China是用来修饰 B e i j i n g Beijing Beijing的,其与 A p p l e Apple Apple完全没有关系,因此单词 A p p l e Apple Apple不应该被 C h i n a China China所影响。类似的 [ C L S ] [CLS] [CLS]也不应该获取单词 A p p l e Apple Apple的信息。因此,为了防止知识噪音,K-BERT引入了可见矩阵(visible matrix) M 来限制句子树中token的相互可见性。可见矩阵的定义为:

可视区域:
- 主干上的词只和主干上的词可见
- 交叉节点上的词和主干上的词和分支上的词都可见
- 分支上的词只和节点和分支上的词可见
2.6 Mask-Transformer
从某种程度上来说,可见矩阵 $M$ 包含了句子树中的结构化信息,但是BERT中的Transformer无法直接利用这些信息。因此,论文提出了Mask-Transformer,其能够根据 $M$ 来限制自注意机制的可见区域。Mask-Transformer是多个mask-self-attention堆叠而且。像BERT那样,其层数为 L L L,隐藏层输出的大小为 H H H,mask-self-attention的头数量为 A A A。
2.6.1 Mask-Self-Attention
为了解决知识噪音,在self-attention的基础上提出了mask-self-attention。具体形式为


如图所示,Apple对[cls]是没用的,因为它们之间是不可见的,但是[cls]可以间接从apple获得信息,因为[cls]和cook可见,cook和apple可见,这样做的好处是,apple能够enrich单词cook的representation,但是没有直接改变原始句子的含义。
3. 实验结果
作者把K-BERT应用在12个中文NLP任务上, 其中8个是开放领域,4个是特定领域。
3.1 预训练语料库
本文采用两种中文语料库进行预训练,即WikiZh2和WebtextZh3:
- WikiZh 指中文维基百科语料库,用于训练中文BERT(Devlin et al. 2018)。 WikiZh总共包含100万个格式正确的中文条目,其中1.2亿个句子的大小为1.2G。
- WebtextZh 是大规模,高质量的中文问答(Q&A)语料库,有410万个条目,大小为3.7G。WebtextZh中的每个条目都属于一个主题,共有28,000个主题。
3.2 知识图谱
本文使用了三个中国知识图谱,CN-DBpedia,HowNet和MedicalKG。
- CN-DBpedia (Xu et al. 2017)是复旦大学知识工作实验室开发的大型开放域百科全书,涵盖数千万个实体和数亿个关系。在本文中,我们通过消除实体名称长度小于2或包含特殊字符的三元组来完善官方的CN-DBpedia。改进后的CN-DBpedia总共包含517万个三元组。
- HowNet 是针对中文词汇和概念的大型语言知识库(Dong,Dong&Hao,2006),其中每个中文单词都用称为音素的语义单元进行注释。如果我们将{单词,包含,音素}作为三元组,则HowNet是一种语言知识图谱。类似地,我们通过消除实体名称长度小于2或包含特殊字符的那些三元组。改进后的HowNet总共包含52,576个三元组。
- MedicalKG 是我们自行开发的中医概念KG,包含四种类型的词(症状,疾病,部位和治疗)。 MedicalKG总共包含13,864个三元组,并且作为K-BERT的一部分是开源的。
3.3 基线
本文将K-BERT与两个基线进行比较:
- Google BERT 该模型已在WikiZh上进行了预训练,并由Google发布(Devlin et al. 2018)。
- 我们的BERT 通过WikiZh和WebtextZh的预训练对BERT的重新实现。
3.4 参数设置和训练细节
为了能和BERT进行对比,K-BERT的参数设置和BERT一样,即:L=12,A=12,H=768。其中L代表自注意力的层数,A代表多头的头数,H代表隐含层的层数。
对于K-BERT预训练,所有设置均与(Devlin et al. 2018)一致。需要强调的一件事是,在预训练阶段我们不会向模型中添加任何知识图谱。由于知识图谱将两个相关的实体名称绑定在一起,因此使两者的预训练词向量非常接近甚至相等,从而导致语义损失。因此,在预训练阶段,K-BERT和BERT是等效的,后者的参数可以分配给前者。 KG将在微调和推断阶段启用。
3.5 开放领域任务
本文首先比较KBERT和BERT在8个中文开放域NLP任务上的性能。
在这八项任务中,书评,Chnsenticorp,购物和微博属于单句分类任务:
- 书评 该数据集包含从豆瓣网11收集的20,000条正面评论和20,000条负面评论;
- Chnsenticorp 是一个酒店评论数据集,共有12,000条评论,其中6,000条正面评论和6,000条负面评论;
- 购物是一个在线购物评论数据集,包含40,000条评论,包括21,111条正面评论和18,889条负面评论;
- 微博微博是一个包含来自新浪微博的情感注释的数据集,包括60,000个正样本和60,000个负样本。
XNLI(Conneau et al. 2018),LCQMC(Liu et al. 2018)是两句分类任务,NLPCC-DBQA12是问答匹配任务,MSRA-NER(Levow 2006)是命名实体识别(NER)任务 :
- XNLI 是一种跨语言的语言理解数据集,其中每个条目包含两个句子,任务是确定它们之间的关系(“包含”,“矛盾”或“中立”);
- LCQMC 是大规模的中文问题匹配语料库。 这项任务的目的是确定两个问题是否具有相似的意图。
- NLPCC-DBQA 是预测给定文档中每个问题的答案的任务;
- MSRA-NER 是微软发布的NER数据集。 此任务是识别文本中的实体名称,包括人员名称,地名,组织名称等。


3.6 特定领域任务
K-BERT真正发挥作用的任务是在特定领域。 因为KG善于提供具有领域知识的LR模型。
- 领域问答:我们在金融和法律领域从百度知道13抓取了大约770,000和36,000个问答样本,包括问题,网民答案和最佳答案,在此基础上,我们建立了两个数据集,分别是财务问答和法律问答。 我们的任务是从网民的答案中选择最佳答案。
- 领域命名实体识别: Finance NER是一个数据集,其中包含3000篇金融新闻文章,并人工标记了65,000多个名称实体(人员,位置和组织)。Medicine NER是CCKS 2017中发布的临床名称实体识别(CNER)任务。目标是从电子病历中提取与医学相关的实体名称。

结论:知识图谱适用于提升需要背景知识的任务,而对于不需要背景知识的开放领域任务效果不是十分显著。即K-BERT在特定领域上的具有明显的语言表示优势。
3.7 消融研究

总的来说,我们可以得出结论,soft-position 和 visible matrix可以使 K-BERT 对 KN 干扰更加鲁棒,从而更有效地利用知识。