词嵌入数据集的预处理--Word2Vec实现(一)
文章目录
-
- 用于预训练词嵌入的数据集
-
- 正在读取数据集
- 下采样
- 中心词和上下文词的提取
- 负采样
- 小批量
- 整合代码
- 小结
用于预训练词嵌入的数据集
在本节中,我们从用于预训练词嵌入模型的数据集开始:
数据的原始格式将被转换为可以在训练期间迭代的小批量。
将准备用于训练word2vec模型。
import math
import os
import random
import torch
import numpy as np
from d2l import torch as d2l
正在读取数据集
此时读取的数据集为 Penn Tree Bank(PTB)。该语料库取自“华尔街日报”的文章,分为训练集、验证集和测试集。在原始格式中,文本文件的每一行表示由空格分隔的一句话。在这里,我们将每个单词视为一个词元。
# 将 Penn Tree Bank 保存到数据集字典中
d2l.DATA_HUB['ptb'] = (d2l.DATA_URL + 'ptb.zip',
'319d85e578af0cdc590547f26231e4e31cdf1e42')
def read_ptb():
"""将 PTB 数据集加载到文本行的列表中"""
data_dir = d2l.download_extract('ptb')
#读取数据集
with open(os.path.join(data_dir, 'ptb.train.txt')) as f:
raw_text = f.read()
# 将所有的句子文本信息转化为tokens数组
return [line.split() for line in raw_text.split('\n')]
sentences = read_ptb()
print(f'# sentences数: {len(sentences)}')
# sentences数: 42069
在读取训练集之后,我们为语料库构建了一个词表,其中出现次数少于10次的任何单词都将由“
# 根据tokens数组构建词典
vocab = d2l.Vocab(sentences, min_freq=10)
print(f'vocab size: {len(vocab)}')
vocab size: 6719
下采样
文本数据通常有“the”、“a”和“in”等高频词:它们在非常大的语料库中甚至可能出现数十亿次。然而,这些词经常在上下文窗口中与许多不同的词共同出现,提供的有用信息很少。例如,考虑上下文窗口中的词“chip”:直观地说,它与低频单词“intel”的共现比与高频单词“a”的共现在训练中更有用。此外,大量(高频)单词的训练速度很慢。因此,当训练词嵌入模型时,可以对高频单词进行下采样 [Mikolov et al., 2013b]。具体地说,数据集中的每个词将有 w i w_{i} wi 概率地被丢弃
P ( w i ) = m a x ( 1 − t f ( w i ) , 0 ) P(w_{i}) = max(1 - \sqrt{\frac{t}{f(w_{i})}}, 0) P(wi)=max(1−f(wi)t,0)
其中, f ( w i ) f(w_{i}) f(wi) 是 w i w_{i} wi 的词数与数据集中的总词数的比率,常量 t t t 是超参数(实验中为 1 0 − 4 10^{-4} 10−4),由上式我们可知,只有当 f ( w i ) > t f(w_{i}) > t f(wi)>t 时, 高频词 w i w_{i} wi 才能被丢弃,且该词的相对比率越高,被丢弃的概率就越大。
def subsample(sentences, vocab):
"""下采样高频词"""
# 排除未知词元 ''
sentences = [[token for token in line if vocab[token] != vocab.unk]
for line in sentences]
# 统计这些tokens出现的频率,并以降序进行排序
counter = d2l.count_corpus(sentences)
# 所有出现tokens的总数
num_tokens = sum(counter.values())
# 如果在下采样期间保留词元,则返回True
def keep(token):
# 其中random.uniform(0, 1)是随机设定的数,
# math.sqrt(1e-4 / counter[token] * num_tokens)越大,即越不容易让舍弃
# 所以此处符合条件时,会返回True,代表保留该词元
return (random.uniform(0, 1) < math.sqrt(1e-4 / counter[token] * num_tokens))
return ([[token for token in line if keep(token)] for line in sentences], counter)
# 返回下采样后的tokens和tokens频率counter
subsampled, counter = subsample(sentences, vocab)
下面的代码片段绘制了下采样前后每句话的词元数量的直方图。正如预期的那样,下采样通过删除高频词来显著缩短句子,这将使训练加速。
d2l.show_list_len_pair_hist(['origin', 'subsampled'], '# tokens per sentence', 'count',
sentences, subsampled)
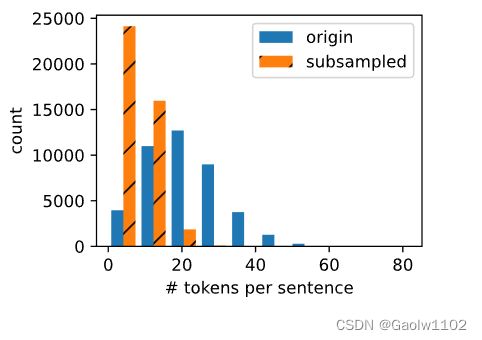
对于单个词元,高频词“the”的采样率不到1/20。
def compare_counts(token):
return (f'"{token}"的数量:'
f'之前={sum([l.count(token) for l in sentences])},'
f'之后={sum([l.count(token) for l in subsampled])}')
compare_counts('the')
'"the"的数量:之前=50770,之后=1946'
相比之下,低频词“join”则被完全保留。
compare_counts('join')
'"join"的数量:之前=45,之后=45'
在下采样之后,我们将词元映射到它们在语料库中的索引。
corpus = [vocab[line] for line in subsampled]
corpus[:3]
[[], [392, 2115], [22, 5277, 3054, 1580, 95]]
中心词和上下文词的提取
下面的 get_centers_and_contexts 函数从corpus中提取所有中心词及其上下文词。它随机采样1到max_window_size之间的整数作为上下文窗口。对于任一中心词,与其距离不超过采样上下文窗口大小的词为其上下文词。
def get_centers_and_contexts(corpus, max_window_size):
"""返回跳元模型中的中心词和上下文词"""
centers, contexts = [], []
for line in corpus:
# 要形成”中心词-上下文词“对,每个句子至少需要有两个词
if len(line) < 2:
continue
centers += line # line中的每一个词均要作为中心词
# 上下文窗口中间 i
for i in range(len(line)):
# 随机取得窗口大小
window_size = random.randint(1, max_window_size)
# 获取单个词的下标信息,并作边界判断,防止列表下溢或者上溢
indices = list(range(max(0, i - window_size),
min(len(line), i + 1 + window_size)))
# 从上下文词中排除中心词
indices.remove(i)
# 将上下文词加入到contexts列表之中
contexts.append([line[idx] for idx in indices])
# 返回中心词和上下文词列表
return centers, contexts
接下来,我们创建一个人工数据集,分别包含7个和3个单词的两个句子。设置最大上下文窗口大小为2,并打印所有中心词及其上下文词。
tiny_dataset = [list(range(7)), list(range(7, 10))]
print('数据集', tiny_dataset)
for center, context in zip(*get_centers_and_contexts(tiny_dataset, 2)):
print('中心词', center, '的上下文词时是', context)
print(get_centers_and_contexts(tiny_dataset, 2))
数据集 [[0, 1, 2, 3, 4, 5, 6], [7, 8, 9]]
中心词 0 的上下文词时是 [1, 2]
中心词 1 的上下文词时是 [0, 2, 3]
中心词 2 的上下文词时是 [1, 3]
中心词 3 的上下文词时是 [2, 4]
中心词 4 的上下文词时是 [2, 3, 5, 6]
中心词 5 的上下文词时是 [4, 6]
中心词 6 的上下文词时是 [4, 5]
中心词 7 的上下文词时是 [8]
中心词 8 的上下文词时是 [7, 9]
中心词 9 的上下文词时是 [8]
([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], [[1], [0, 2, 3], [0, 1, 3, 4], [1, 2, 4, 5], [3, 5], [4, 6], [4, 5], [8, 9], [7, 9], [8]])
在 PTB 数据集上进行训练时,我们将最大上下文窗口大小设置为 5。下面提取数据集的所有中心词及其上下文词。
all_centers, all_contexts = get_centers_and_contexts(corpus, 5)
print(f'# "中心词-上下文对"的数量: {len(all_centers)}')
# "中心词-上下文对"的数量: 342766
负采样
我们使用负采样进行近似训练。为了根据预定义的分布对噪声词进行采样,我们定义以下的 RandomGenerator 类,其中(可能未规范化的)采样分布通过变量 sampling_weights 传递。
class RandomGenerator:
"""根据 n 个采样权重在{1, ..., n}中随机抽取"""
def __init__(self, sampling_weights):
# Exclude
self.population = list(range(1, len(sampling_weights) + 1)) # 返回一个 [1, 2, ..., n]的列表
self.sampling_weights = sampling_weights # 采样的权重列表
self.candidates = [] # 用以缓存k个抽取结果
self.i = 0 # 表示candidata中缓存的个数
def draw(self):
if self.i == len(self.candidates):
# 缓存k个随机采样结果
# random.choices(population,weights=None,*,cum_weights=None,k=1)函数
# population:集群
# weights:相对权重
# k:选取次数
self.candidates = random.choices(
self.population, self.sampling_weights, k=10000)
self.i = 0
self.i += 1
return self.candidates[self.i - 1]
例如,我们可以在索引1、2和3中绘制10个随机变量 X X X ,采样概率为 P ( X = 1 ) = 2 / 9 , P ( X = 2 ) = 3 / 9 P(X=1)=2/9, P(X=2)=3/9 P(X=1)=2/9,P(X=2)=3/9 和 P ( X = 3 ) = 4 / 9 P(X=3)=4/9 P(X=3)=4/9,如下所示。
generator = RandomGenerator([2, 3, 4])
[generator.draw() for _ in range(10)]
[3, 3, 2, 2, 3, 3, 1, 3, 1, 1]
def get_negatives(all_contexts, vocab, counter, k):
"""返回负采样中的噪声词"""
# 索引为 1, 2, ... (索引 0 是词表中排除的未知标记)
sampling_weights = [counter[vocab.to_tokens(i)]**0.75 for i in range(1, len(vocab))]
all_negatives, generator = [], RandomGenerator(sampling_weights)
for contexts in all_contexts:
negatives = []
while len(negatives) < len(contexts) * k: # 生成 k * len(contexts)个噪声词
neg = generator.draw()
# 噪声词不能是上下文词
if neg not in contexts: # 且噪声词不能是上下文词
negatives.append(neg)
all_negatives.append(negatives) # 追加上下文噪声词至所有噪声词的列表
# 返回总的噪声词列表
return all_negatives
生成所有上下文词的噪声词。
all_negatives = get_negatives(all_contexts, vocab, counter, 5)
小批量
def batchify(data):
"""返回带有负采样的跳元模型的小批量样本"""
max_len = max(len(c) + len(n) for _, c, n in data) # 找出最大的context和negative组合
# 中心词、上下文和负采样、掩蔽、标签
# 掩蔽mask用以将填充的词置为 0
# 标签label用以将context上下文词置1, 其余置 0
centers, contexts_negatives, masks, labels = [], [], [], []
for center, context, negative in data:
cur_len = len(context) + len(negative) # cur_len表示context和negative有效长度
centers += [center] # centers存放所有中心词
# contexts_negatives存放上下文词和负采样样本的连接
contexts_negatives += [context + negative + [0] * (max_len - cur_len)]
masks += [[1] * cur_len + [0] * (max_len - cur_len)] # masks用以区分填充词元
# label用以区分 上下文词元的位置
labels += [[1] * len(context) + [0] * (max_len - len(context))]
# 返回批量数据
return (torch.tensor(centers).reshape((-1, 1)), torch.tensor(contexts_negatives),
torch.tensor(masks), torch.tensor(labels))
让我们使用一个小批量的两个样本来测试此函数。
x_1 = (1, [2, 2], [3, 3, 3, 3])
x_2 = (1, [2, 2, 2], [3, 3])
batch = batchify((x_1, x_2))
names = ['centers', 'contexts_negatives', 'masks', 'labels']
for name, data in zip(names, batch):
print(name, '=', data)
centers = tensor([[1],
[1]])
contexts_negatives = tensor([[2, 2, 3, 3, 3, 3],
[2, 2, 2, 3, 3, 0]])
masks = tensor([[1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 0]])
labels = tensor([[1, 1, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0]])
整合代码
#@save
def load_data_ptb(batch_size, max_window_size, num_noise_words):
"""下载PTB数据集,然后将其加载到内存中"""
# num_workers = d2l.get_dataloader_workers()
# 读取数据集,返回tokens列表
sentences = read_ptb()
# 根据tokens列表和最小频率数构建词典
vocab = d2l.Vocab(sentences, min_freq=10)
# 进行下采样,并统计词频
subsampled, counter = subsample(sentences, vocab)
# 根据下采样的结果生成词元索引的列表
corpus = [vocab[line] for line in subsampled]
# 根据词元索引的列表生成中心词列表和上下文列表
all_centers, all_contexts = get_centers_and_contexts(
corpus, max_window_size)
# 进行负采样,生成噪声词
all_negatives = get_negatives(
all_contexts, vocab, counter, num_noise_words)
class PTBDataset(torch.utils.data.Dataset):
def __init__(self, centers, contexts, negatives):
assert len(centers) == len(contexts) == len(negatives)
self.centers = centers
self.contexts = contexts
self.negatives = negatives
def __getitem__(self, index):
return (self.centers[index], self.contexts[index],
self.negatives[index])
def __len__(self):
return len(self.centers)
dataset = PTBDataset(all_centers, all_contexts, all_negatives)
# 生成数据迭代器
data_iter = torch.utils.data.DataLoader(
dataset, batch_size, shuffle=True,
collate_fn=batchify)
# 返回数据迭代器和词表
return data_iter, vocab
让我们打印数据迭代器的第一个小批量。
data_iter, vocab = load_data_ptb(512, 5, 5)
for batch in data_iter:
for name, data in zip(names, batch):
print(name, 'shape:', data.shape)
break
centers shape: torch.Size([512, 1])
contexts_negatives shape: torch.Size([512, 60])
masks shape: torch.Size([512, 60])
labels shape: torch.Size([512, 60])
小结
1、高频词在训练中可能不是那么有用。我们可以对他们进行下采样,以便在训练中加快速度。
2、为了提高计算效率,我们以小批量方式加载样本。我们可以定义其他变量来区分填充标记和非填充标记,以及正例和负例。