SENet论文解读及代码实例
SENet论文解读及代码实例
在SENet前的网络是针对卷积空间来做处理的,而SENet考虑了卷积通道上的的权重(明确地建模网络卷积特征通道之间的相互依赖关系),通过训练每个通道权重来抑制无用特征,提高有用特征在分类网络的占比,从而实现识别精度的提升。SENet引入权重计算网络,识别精度提升的代价为参数量提高10%左右,计算量提高1%左右。
1)SE block模块原理
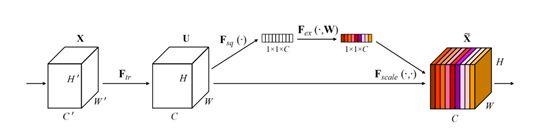
下图为SE模块的建立过程 ,在SE模块中,生成的特征图经聚合层(Squeeze)生成每一个通道的全局信息,公式如下:
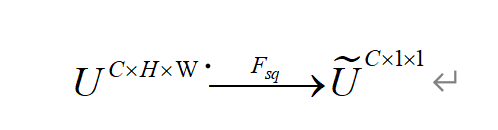
全局信息通过激励层生成每个通道的权值大小,每个通道再与权值相乘便可得到带权值的特征图。
在SE模块实际使用中,Squeeze层通过全局平均池化将全局空间信息压缩压缩到全局信息中, 可由下式表示:
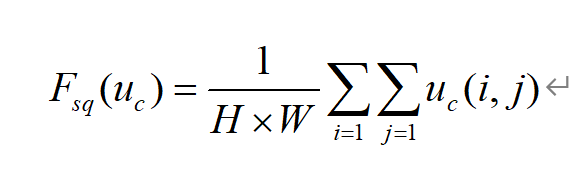
为了利用全局信息来学习通道之间的权重,我们必须通过激励(Excitatio
-n)来获取权重,其中激励必须满足两个条件:必须能够学习通道之间的非线性相互作用;必须学习一种非互斥的关系,因为我们想要确保多个通道被允许被强调。 可用以下公式表示:
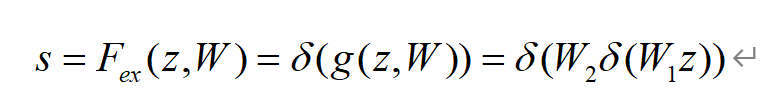
该结构由两个全连接层构成,这两个全连接层的作用就是融合各通道的feature map信息,第一个全连接层起降维作用,降维比取到16,激活函数采用Relu,第二个全连接将维数增加至原始输入维数,激活函数为sigmoid函数。
最后将 和 相乘得到权重
2)SE block模块使用
SE block可以嵌入各种卷积网络中使用,如Resnet、ResNeXt、Xception等,下图为SE block嵌入Resnet50的模块图:
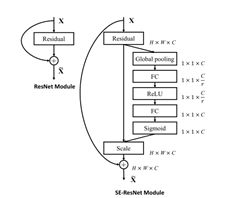
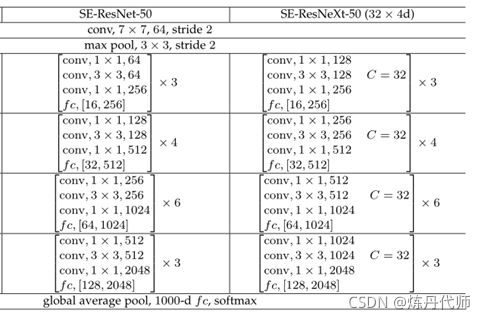
SE-Resnet50在性能的变化:运算量从3.86GFlop增加至3.87GFlop,准确率从Resnet50提升至Resnet101的水平。模型结构如下:
代码实现SE-Resnet50
import torch.nn as nn
import torch.nn.functional as F
import math
from torchsummary import summary
class SElayer(nn.Module):
def __init__(self,ratio,input_aisle):
super(SElayer, self).__init__()
self.pool=nn.AdaptiveAvgPool2d(1)
self.fc=nn.Sequential(
nn.Linear(input_aisle,input_aisle//ratio,bias=False),
nn.ReLU(inplace=True),
nn.Linear(input_aisle//ratio,input_aisle,bias=False),
nn.Sigmoid()
)
def forward(self,x):
a, b, _, _ = x.size()
#读取批数据图片数量及通道数
y = self.pool(x).view(a, b)
#经池化后输出a*b的矩阵
y = self.fc(y).view(a, b, 1, 1)
#经全连接层输出【啊,吧,1,1】矩阵
return x * y.expand_as(x)
#输出权重乘以特征图
class SE_block(nn.Module):
def __init__(self, outchannels, ratio=16, ):
super(SE_block, self).__init__()
self.backbone=nn.Sequential(nn.Conv2d(in_channels=outchannels, out_channels=outchannels // 4, kernel_size=1, stride=1),
nn.BatchNorm2d(outchannels // 4),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=outchannels // 4, out_channels=outchannels // 4, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(outchannels // 4),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=outchannels // 4, out_channels=outchannels, kernel_size=1, stride=1),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True),
)
self.Selayer=SElayer(ratio, outchannels)
def forward(self,x):
residual=x
x=self.backbone(x)
x=self.Selayer(x)
x=x+residual
return x
class SE_Idenitity(nn.Module):
def __init__(self, inchannel,outchannels, stride=2,ratio=16,):
super(SE_Idenitity, self).__init__()
self.backbone = nn.Sequential(
nn.Conv2d(in_channels=inchannel, out_channels=outchannels//4, kernel_size=1, stride=1),
nn.BatchNorm2d(outchannels//4),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=outchannels//4, out_channels=outchannels//4, kernel_size=3, stride=stride, padding=1),
nn.BatchNorm2d(outchannels//4),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=outchannels//4, out_channels=outchannels, kernel_size=1, stride=1),
nn.BatchNorm2d(outchannels),
nn.ReLU(inplace=True),
)
self.residual=nn.Conv2d(in_channels=inchannel, out_channels=outchannels, kernel_size=1, stride=stride)
self.selayer = SElayer(ratio, outchannels)
def forward(self,x):
residual=self.residual(x)
x=self.backbone(x)
x=self.selayer(x)
x=x+residual
return x
class SE_Resnet(nn.Module):
def __init__(self,layer_num,outchannel_num,num_class=10):
super(SE_Resnet, self).__init__()
self.initial=nn.Sequential(nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,padding=3,stride=2),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,padding=1,stride=2))
self.residual=self.make_layer(layer_num,outchannel_num)
self.pool=nn.AdaptiveAvgPool2d(1)
self.fc=nn.Linear(2048,num_class)
def make_layer(self,number_layer,number_outchannel):
layer_list=[]
for i in range(len(number_layer)):
if i==0:
stride=1
else:
stride=2
layer_list.append(SE_Idenitity(number_outchannel[i],number_outchannel[i+1],stride))
for j in range(number_layer[i]-1):
layer_list.append(SE_block(number_outchannel[i+1]))
return nn.Sequential(*layer_list)
def forward(self,x):
x=self.initial(x)
x=self.residual(x)
x=self.pool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return F.softmax(x,dim=1)
def SE_Resnet50(num_class):
model=SE_Resnet([3,4,6,3],[64,256,512,1024,2048],num_class)
return model
def SE_Resnet101(num_class):
model=SE_Resnet([3,4,23,3],[64,256,512,1024,2048],num_class)
return model
def SE_Resnet151(num_class):
model = SE_Resnet([3, 8, 36, 3], [64,256, 512, 1024, 2048], num_class)
return model
device=torch.device("cuda:0")
Xception=SE_Resnet50(10).to(device)
summary(Xception,(3,224,224))
Resnet50与SE-Resnet50模型参数及计算量对比如下图:
1)SE-Resnet50参数:

2)Resnet50参数:

整体大小由328M提高至417M,感觉比论文中说的10%要大上不少,运行时间上跑了一个epoch在我这吃土的MX150上多接近40%的时间。
总结:电脑差的话,SE-Resnet整体性价比不高!!!