【论文阅读】超分辨率——Towards Real-World Blind Face Restoration with Generative Facial Prior
Towards Real-World Blind Face Restoration with Generative Facial Prior利用生成式人脸先验进行真实世界盲目的人脸重构
- 1. Introduction
-
- 解决的问题
- 贡献
- GAN逆映射
- [SFT Layer](https://zhuanlan.zhihu.com/p/45145504)
- [Perceptual Loss](https://blog.csdn.net/u013289254/article/details/102880140)
- LapSRN
- 2. Related Work
- 3. Methodology
-
- 3.1. Overview of GFP-GAN
- 3.2. Degradation Removal Module
- 3.3. Generative Facial Prior and Latent Code Mapping
- 3.4. Channel-Split Spatial Feature Transform
- 3.5. Model Objectives
- 4. Experiments
-
- 4.1. Datasets and Implementation
- 4.2. Comparisons with State-of-the-art Methods
- 4.3. Ablation Studies
- 4.4. Limitations
- 5. Conclusion
论文链接: Arxiv
团队:腾讯ARC
会议及时间:CVPR 2021
代码:暂未发布
1. Introduction
盲目的人脸修复的目标是从存在未知退化的低质量人脸中修复出高质量的人脸,如低分辨率、噪声、模糊、压缩伪影等。当应用到现实世界的场景中,由于更复杂的退化,不同的姿态和表情,它变得更具挑战性。以往的研究典型地利用了人脸修复中的特定人脸先验,如人脸关键点检测、解析映射、人脸成分热图,并表明这些几何人脸先验对于修复准确的人脸形状和细节至关重要。然而,这些先验信息通常是从输入图像中估计出来的,并且不可避免地会在输入质量很低的情况下退化。
解决的问题
如何从低分辨率低质量的真实图像中获得较好的先验知识,复原人脸图像
最近,对于人脸复原问题,需要从低分辨率人脸图像中提取几何人脸先验,用于复原人脸。但是许多时候,从现实低分辨图像中所提取的许多人脸的先验都不太准确,并且纹理信息也受限。
另一个策略是引入参考先验,即高质量引导人脸或者人脸成分字典,生成真实的人脸结果。但是,高分辨率参考文件的不可访问性限制了它的实际适用性,而字典的固定容量限制了它的面部细节的多样性和丰富性。
—> 我们提出了一种生成式的人脸先验(GFP),用于真实世界的盲人脸图像复原。由于预训练的人脸生成对抗网络(如styleGAN)所生成的假脸,具有高分辨率,丰富的几何形状、人脸纹理和颜色,这些使到其能够联合用于复原人脸的细节和增强颜色。
提出了一种GFP-GAN,其包含了一个退化去除模块和一个预训练的人脸GAN作为人脸先验。通过直接的潜在代码映射和几个通道分割空间特征变换(CS-SFT)层以粗调方式连接。
贡献
- 利用丰富多样的生成人脸先验来进行绑定人像复原。这些先验包含足够的面部纹理和生动的色彩信息,能够联合执行人脸修复和色彩增强。
- 提出GFP-GAN框架,该框架具有精巧的架构设计,并能融合人脸生成先验。带有CS-SFT层的GFP-GAN在一次正向传递中实现了保真度和纹理忠实度之间的良好平衡。
- 大量实验表明,GFP-GAN在合成数据集和真实数据集上均取得了优于现有技术的性能。
GAN逆映射
定义: GAN 逆映射指将给定图像转化到预训练 GAN 模型的隐空间,生成器可用其逆映射码进行可靠的图像重建。
理解: 一个无监督、训练好的GAN可以通过从潜在空间Z中采样然后合成高质量的图像,也就是Z->image。而所谓的GAN逆映射指的是,找到一个合适Z去恢复目标图像,也就是image->Z(Z此时是一个待优化的参数)。GAN逆映射成为连接真实图像和假图像的公共空间。
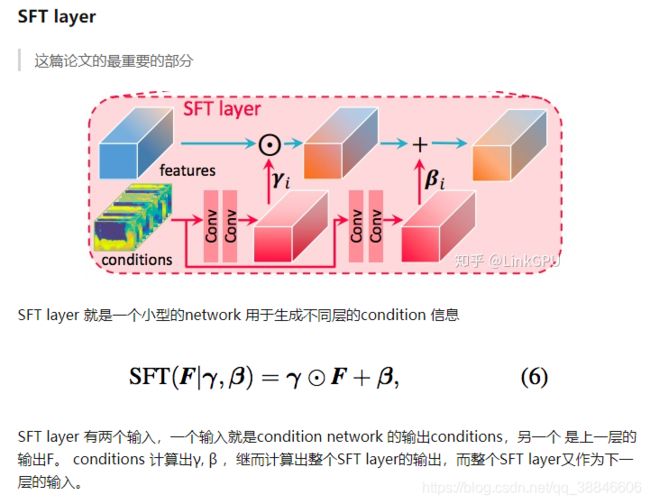
SFT Layer
Perceptual Loss
1.介绍
在讲感知损失函数之前,我们先讲一下,网络所提取到的特征代表什么,在下图中,layer1,layer2学到的是边缘,颜色,亮度等底层的特征;layer3开始变得复杂,学到的是纹理的特征,Layer4则学到的是一些有区别性的特征,Layer5学到的特征是比较完整的,具有辨别性的关键特征。可以知道CNN学习到的特征逐渐抽象到更高级别上。
那么感知损失函数和这个有什么关系呢?
它是将真实图片卷积得到的feature(一般是用vgg16或者vgg19来提取)与生成图片卷积得到的feature作比较(一般用MSE损失函数),使得高层信息(内容和全局结构)接近,也就是感知的意思。

2.作用
1)在超分中,因为我们经常使用MSE损失函数,会导致输出图片比较平滑(丢掉了细节部分/高频部分),因此适当选择某个层输出的特征输入感知损失函数是可以增强细节。
2)在风格转移中,我们用一个感知损失函数来训练我们的图像转换网络能让输出非常接近目标图像y,但并不是让他们做到完全的匹配
3.优点
风格转移或者超分辨率中,速度快,GAN中收敛效果好,具有高频细节信息。
4.收敛速度快
回传导数时,相比于MSE对pixel与pixel之间的差异, 回传分布更具有普适性。所以用perceptual loss收敛速度快。
LapSRN

整个LapSRN网络由特征提取和图像重建两个分支组成。
具体实现:
1、特征提取:
在s层,特征提取分支由d个卷积层和1个上采样层组成,将提取的特征按2的尺度向上采样。
每个上采样后的卷积层的输出连接到两个不同的层:
(1)一个卷积层用于重建s级的残差图像,以及(2)一个卷积层用于提取s+1级更细的特征。
网络在粗分辨率下执行特征提取,而在较细分辨率下仅使用一个上采样层生成特征图。
2、图像重建
在s层,输入图像上采样为2,并设置了一个上采样层。我们用双线性核初始化这一层,并允许它与所有其他层共同优化。然后,将上采样图像(使用元素求和)与来自特征提取分支的预测残差图像相结合,生成高分辨率的输出图像。
将输出的s层的高分辨率图像送入s+1层图像重建分支。
3、损失函数
损失函数采用了鲁棒的Charbonnier 损失函数:

2. Related Work
Image Restoration
图像修复通常包括超分辨率、去噪、去模糊和压缩去除。生成对抗网络通常被用作损失监督,以推动方案更接近自然流形,而我们的工作试图利用预先训练的GANs作为生成式人脸先验(GFP)。
Face Restoration
在一般人脸超分辨率技术的基础上,引入两种典型的人脸特异性先验:几何先验和参考先验,进一步提高模型表现。
- 几何先验包括人脸关键点(facial landmarks),人脸分割图(face parsing maps)和人脸成分热力图(facial component heatmaps )。
然而,1) 从低质量的图片中很难取得比较准确的几何信息;2) 它们很难提供纹理方面的信息。
相反,我们采用的GFP不涉及从退化图像中明确的几何估计,并在其预先训练的网络中包含足够的纹理。 - 参考先验通常依赖于相同身份的参考图像。即从数据库中取得相同或者相似的人脸作为参考(Reference)来复原。但是这样的高质量的参考图在实际中很难获取。ECCV20 提出的 DFDNet 工作进一步构建了一个人脸五官的字典来作为参考, 它可以取得更好的效果, 但是会受限于字典的容量, 而且只考虑了五官, 没有考虑整个脸。而GFP可以提供丰富多样的先验,包括几何、纹理和颜色。GFP-GAN可以将面部作为一个整体进行修复。
Generative Priors
预训练过的GAN的生成先验先前被GAN逆映射(GAN inversion)所利用,其主要目的是找到给定输入图像的最接近的隐变量(latent code)。PULSE迭代优化StyleGAN的隐变量,直到输出和输入之间的距离低于阈值。mGANprior尝试优化多个代码,以提高重构质量。然而,由于低维隐变量不足以指导修复,这些方法通常会产生低保真度的图像。相比之下,我们提出的CS-SFT调制层能够预先结合多分辨率空间特征,以实现高保真度。此外,我们的GFP-GAN在推理过程中不需要高成本的迭代优化。
Channel Split Operation
为了设计紧凑的模型,提高模型表示能力,通常采用通道分割操作。MobileNet提出了深度卷积,而GhostNet将卷积层分成两部分,并使用较少的滤波器来生成内在特征映射。
DPN的双路径结构能够对每条路径进行特征重用和新特征探索,从而提高了DPN的表示能力。在超分辨率中也采用了类似的思路。我们的CS-SFT层有着相似的精神,但是有着不同的操作和目的。我们在一次分裂上采用空间特征变换,将左分裂作为身份特征,以达到很好的真实性和保真度的平衡。
Local Component Discriminators
局部成分判别器。本文提出了局部标识符来关注局部块分布。当应用到人脸时,这些区别性损失被强加在单独的语义面部区域。我们引入的人脸成分损失也采用了这样的设计,但在学习到的判别特征的基础上进行了进一步的样式监督,证明了这种方法对恢复面部细节是有效的。
3. Methodology
3.1. Overview of GFP-GAN
在给定退化未知的输入人脸图像 x x x的情况下,盲目的人脸修复的目的是估计出与GT图像 y y y尽可能相似的高质量图像 y ^ \hat{y} y^。
下图是该研究的主要框架, 输入一张低质量的人脸, 首先经过 UNet 结构, 在这里有复原 loss 的 L1 约束 (灰色箭头),用以粗略地去除 degradations, 比如噪声、模糊、JPEG 等。同时更重要的是, 得到提取的 latent 特征向量 (绿色箭头) 和空间特征 (黄色箭头)。
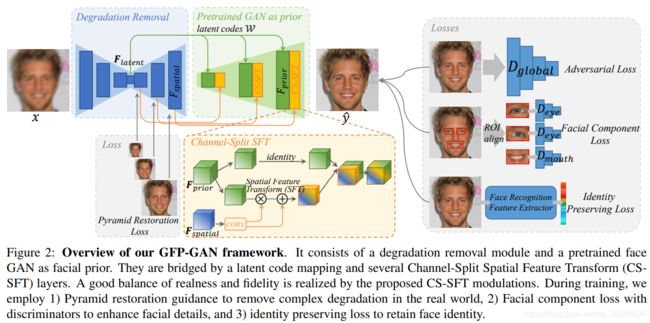
如图2所示,GFP-GAN网络架构包含了一个退化去除模块和一个预训练的人脸GAN作为人脸先验,其中预训练的人脸GAN通过直接的隐变量映射和几个通道分割空间特征变换(CS-SFT)层以粗调方式连接。首先退化模块,去除输入 x x x的可计算退化,并提取清晰的隐变量 F l a t e n t F_{latent} Flatent和不同分辨率空间特征 F s p a t i c a l F_{spatical} Fspatical;然后隐变量 F l a t e n t F_{latent} Flatent匹配到中间隐变量W,其是有所学习的人脸GAN分布中接近人脸的粗糙检索特征 F p r i o r F_{prior} Fprior ;在所提出的CS-SFT中以粗糙到精细的方式,将不同分辨率空间特征 F s p a t i a l F_{spatial} Fspatial用于调制人脸GAN特征 F p r i o r F_{prior} Fprior,最后生成高清的人脸。
3.2. Degradation Removal Module
图像包含有许多不同的退化因素。本文所提出的退化去除模块,用于提取清晰特征;本模块基于U-net网络模型,并提高大范围模糊的适应性和生成不同分辨率的特征。利用金字塔复原指导中间结果。
3.3. Generative Facial Prior and Latent Code Mapping
采用StyleGANg2的方法,将输入图像转换到中间隐变量W,该变量W 用于从可学习的人脸GAN分布中检索最相近的人脸特征;然后,能够用GAN特征获得生成式人脸先验 F p r i o r F_{prior} Fprior。

3.4. Channel-Split Spatial Feature Transform
利用先验特征 F p r i o r F_{prior} Fprior和提取的清晰特征 F l a t e n t F_{latent} Flatent,本模块生成高清图像。借鉴分割特征转换方法,给定从清晰特征 F l a t e n t F_{latent} Flatent中学习到的一组变换参数 ( β , α ) (\beta,\alpha) (β,α),然后对先验特征进行调整:
F o u t p u t = S F T ( F p r i o r ∣ α , β ) = α ⊙ F p r i o r + β F_{output} = SFT(F_{prior}|\alpha,\beta) = \alpha \odot F_{prior} + \beta Foutput=SFT(Fprior∣α,β)=α⊙Fprior+β
![]()
但是这种方法难以在真实性和保真度之间达到好的平衡;因此本文将先验特征分解为身份特征部分(用于保留)以及变换特征部分(用于特征调制),采用以下的形式进行求解:

在人脸复原中, 与其他工作不同, 仅仅通过调制 StyleGAN 的 latent codes, 因为没有考虑局部的空间信息会极大影响人脸的 identity。因此也要利用空间的特征来调制 StyleGAN 里面的特征。
GFP-GAN 基于现有的高效的空间特征变换 (Spatial Feature Transform,SFT) 层来达到这个目的。它能够根据输入的条件(这里是提取的低质量的图像特征), 生成乘性特征和加性特征,对 StyleGAN 的特征做仿射变换。为了进一步平衡输入图像的信息和 StyleGAN 中的信息, GFP-GAN 进一步将通道拆分为两部分, 一部分用来调制, 一部分直接跳跃过去。这样的调制会在由小到大的每个空间尺度上进行, 提高调制的效果。
3.5. Model Objectives
损失函数主要包括四个:
- 约束输出 y ^ \hat{y} y^接近GT y y y的重建损失
- 恢复真实纹理的对抗损失
- 提出面部组成损失进一步提升面部细节
- 身份保留损失
Reconstruction Loss L r e c \mathcal{L}_{rec} Lrec: 图像像素级重构以及VGG层次的感知loss重构

Adversarial Loss L a d v \mathcal{L}_{adv} Ladv: 生产真实纹理,类似于StyleGAN2,采用了Logistic Loss,训练全局的 Discriminator, 判断人脸是否真实;没有理解这里为什么不写判别器损失


StyleGAN选用饱和逻辑斯谛损失,Loss_G=-log(exp(D(G(z)))+1)
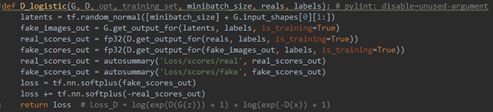
不含梯度惩罚时,Loss_D=log(exp(D(G(z)))+1)+log(exp(-D(x))+1)
SoftPlus函数

所以公式(4)可以写成:
L a d v = − λ a d v E y ^ l o g [ e x p ( D ( G ( z ) ) ) + 1 ] \mathcal{L}_{adv}=-\lambda_{adv}\mathbb{E}_{\hat{y}}log[exp(D(G(z)))+1] Ladv=−λadvEy^log[exp(D(G(z)))+1]
Facial Component Loss L c o m p \mathcal{L}_{comp} Lcomp: 首先用ROI对齐来裁剪感兴趣的区域,对于每个区域,训练独立的和小的局部识别器来区分恢复的patches是否真实,将patches推向接近自然的面部成分分布。
通过ROI align之后,对每一个ROI部分进行判定;首先,是判定对应的ROI是否真,接着,利用Gram matrix statistics[6],判断ROI的风格loss
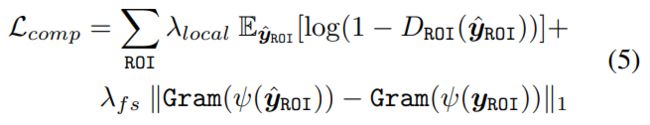
Identity Preserving Loss L i d \mathcal{L}_{id} Lid: 为了保持人脸 identity 的一致, 使用了人脸 identity 一致损失函数(预训练的ArcFace),即在人脸识别模型的特征空间中去拉近,确保重构结果与GT接近。
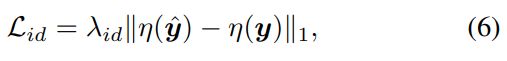

最终损失如下:
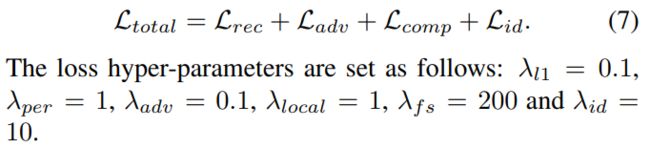
4. Experiments
4.1. Datasets and Implementation
和之前大部分工作类似,GFP-GAN 采用了 Synthetic 数据的训练方式。研究者们发现在合理范围的 Synthetic 数据上训练, 能够涵盖大部分的实际中的人脸。GFP-GAN 的训练采用了经典的降质模型, 即先高斯模糊, 再降采样, 然后加白高斯噪声, 最后使用 JPEG 压缩。

训练数据集: 合成退化图像;FFHQ数据集
测试数据集:CelebA-Test、LFW-Test、CelebChild-Test、WebPhoto-Test
评价指标: PSNR、SSIM, FID(计算真实样本与生成样本在特征空间之间的距离)、NIQE、学习知觉图像补丁相似度(LPIPS)

实现: 采用输出为 512 × 512 512\times512 512×512的预训练StyleGAN作为GFP。StyleGAN2的通道乘数设置为1。用于降解去除的UNet由7个下采样和7个上采样组成,每次采样一个残差块。对于每个CS-SFT层,我们使用两个卷积层分别生成仿射参数α和β。
4.2. Comparisons with State-of-the-art Methods
我们比较了GFP-GAN与几种最先进的面部修复方法:HiFaceGAN[69]、DFDNet[46]、
PSFRGAN [6], Super-FAN [4], Wan等[63]。用于面部修复的氮化镓倒置方法:脉冲[54]和manprior[20]也被纳入比较。我们还比较了我们的GFP-GAN与图像恢复方法:
RCAN [75], ESRGAN[66]和DeblurGANv2[41],我们在我们的面部训练集上对它们进行微调,以便进行公平比较。我们采用了他们的官方代码,除了Super-FAN,我们使用了重新实现。
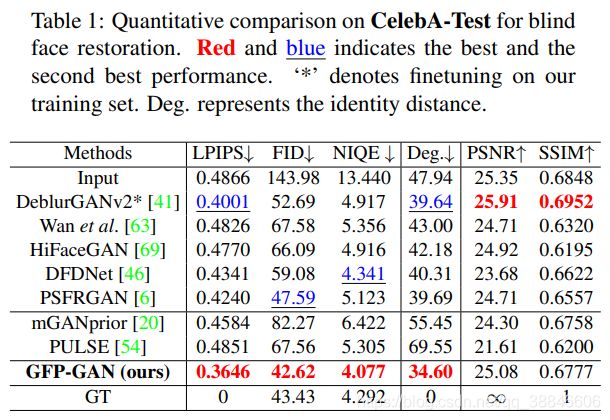
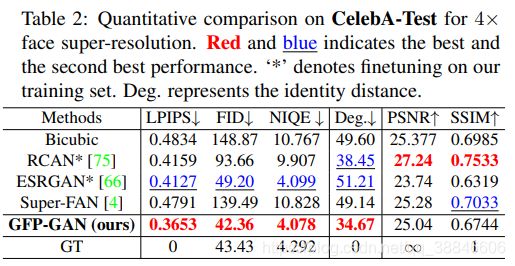
为了进行评估,我们使用了广泛使用的非参考感知指标:FID[28]和NIQE[55]。我们还采用像素级度量(PSNR和SSIM)和感知度量(LPIPS[74])与CelebA-Test的GT进行比较。我们在ArcFace[11]特征嵌入中用角度来测量身份距离,数值越小表明身份越接近GT。
合成CelebA-Test。在两种设置下进行比较:1)输入和输出分辨率相同的盲目人脸修复。2) 4 × 4\times 4×人脸超分辨率。注意,我们的方法可以获取更新的采样图像作为人脸超分辨率的输入。
各设置的定量结果如表1和表2所示。在这两种设置下,GFP-GAN都达到了最低的LPIPS,这表明我们的结果在感知上接近于GT。GFP-GAN也获得了最低的FID和NIQE,表明输出分别接近真实人脸分布和自然图像分布。除了感知性能,我们的方法还保留了更好的身份,以最小的程度在人脸特征嵌入。需要注意的是,像素尺度的PSNR和SSIM与人类观察者的主观评价的相关性并不好,我们的模型也不擅长这两个尺度。


定性结果见图3、图4。1)T由于强大的面部生成先验,我们的GFPGAN恢复如实的细节在眼睛(瞳孔和睫毛),牙齿等;2)我们的方法是将面部作为一个整体来处理还可以恢复和生成逼真的头发,而以前依赖组件字典的方法(DFDNet)或者解析映射(PSFRGAN)不能产生如实的头发纹理(第二排,图3)。3)GFP-GAN能够表示保持保真度,与PSFRGAN一样,GFP-GAN的嘴自然闭合,不强制增加牙齿(第二排,图3)。在图4中,GFP-GAN还能恢复合理的眼睛注视方向
真实世界的LFW, CelebChild和WedPhoto-Test。 为了测试泛化能力,我们在三个不同的真实数据集上评估我们的模型。定量结果见表3。我们的GFP-GAN在三个真实世界的数据集上都取得了卓越的性能,显示了其卓越的泛化能力。
虽然PULSE也可以获得较高的感知质量(较低的FID分数),但并不能保留如图5所示的人脸身份。

定性比较如图5所示。GFP-GAN通过强大的生成先验功能,对真实照片联合进行面部修复和色彩增强。我们的方法可以在复杂的真实世界退化情况下产生逼真的人脸,而其他方法无法恢复忠实的人脸细节或产生伪影(特别是在图5的webphoto测试中)。除常见的人脸成分如眼睛和牙齿外,GFP-GAN在头发和耳朵上的表现也更好,因为GFP优先考虑的是整个面部,而不是单独的部分。使用SC-SFT层,我们的模型能够实现高保真度。如图5最后一行所示,以往的方法大多无法恢复闭上的眼睛,而我们的方法可以用较少的人工成功恢复。
4.3. Ablation Studies
CS-SFT层。 如表4[配置a)]和图6所示,当去除空间调制层,如,只保留没有空间信息的隐变量时,即使有身份保留损失,恢复后的人脸仍不能保留人脸身份(较高的LIPS score和较大的Deg.)。因此,在CS-SFT层中使用的多分辨率空间特征对于保持保真度至关重要。当我们切换CS-SFT层简单SFT层(配置b)在表4),我们观察到1)感知质量会降低所有指标和2)它保留强大的身份(小度。)作为输入图像特性施加影响所有的调制特性和退化的输入输出的偏见,从而导致较低的感知质量。相比之下,CSSFT层通过调整特征的分裂提供了一个很好的真实性和保真度的平衡。
预训练GAN为GFP。预训练的GAN提供丰富多样的恢复功能。如果我们不使用生成人脸先验,可以观察到性能下降,如表4[配置c)]和图6所示。
金字塔恢复的损失。在退化去除模块中引入了金字塔恢复损失,增强了对现实世界中复杂退化的恢复能力。如果没有这种中间监督,后续调制的多分辨率空间特征仍可能发生退化,导致性能较差,如表4[配置d)]和图6所示。
面部组件损失。我们比较了1)去除所有的面部成分损失,2)只保留成分鉴别器,3)像[64]那样增加额外的特征匹配损失,4)基于Gram统计[16]采用额外的特征风格损失的结果。如图7所示,特征风格丢失的分量鉴别器可以更好地捕捉眼球分布,并恢复貌似可信的细节。

4.4. Limitations
尽管我们用合成数据训练的模型证明了对真实世界图像的良好泛化,仍然有一些局限性。如图8所示,退化时对真实图像来说是极其严重的,复原的面部细节被GFP-GAN扭曲了。我们的方法也会产生不自然的结果。这是因为综合退化和训练数据分布与现实世界的情况不同。一个可能的方法是从真实数据中学习这些分布,而不是只是使用合成数据,这是未来的工作。

5. Conclusion
提出GFP-GAN框架,利用丰富和多样化的生成式人脸先验来完成具有挑战性的盲目的人脸修复任务。这一先验被纳入到新的通道分割空间特征转换层的修复过程中,使模型能够很好地平衡真实性和保真度。此外,介绍了人脸组成损失、身份保留损失和金字塔修复指导等精细设计。广泛的比较表明,GFP-GAN在联合面部恢复和真实世界图像的颜色增强方面具有优越的能力,优于现有技术。
参考文献
https://zhuanlan.zhihu.com/p/344602972
https://finance.sina.com.cn/tech/2021-04-05/doc-ikmyaawa6744662.shtml
https://www.bilibili.com/video/BV1qi4y1t7nb?from=search&seid=3107006202936880119
https://www.jianshu.com/p/58fd418fcabf