论文阅读:ICCV2021 TransReID: Transformer-based Object Re-Identifification
作者:何舒婷 罗浩 浙江大学和阿里巴巴
ICCV 2021,首个将Transformer用于Re-ID的工作
TransReID在行人和车辆重识别任务上均表现SOTA!
论文:https://arxiv.org/abs/2102.04378
源码:https://github.com/heshuting555/TransReID
翻译:
Abstract
提取鲁棒特征表示是Object重新识别(ReID)中面临的关键挑战之一。虽然基于卷积神经网络(CNN)的方法取得了很大的成功,但它们一次只处理一个局部邻域,并且遭受了由卷积和降采样算子(如池化和串化卷积)导致的细节信息损失。为了克服这些限制,我们提出了一个纯的基于tansformer的对象ReID框架,名为TransReID。具体来说,我们首先将一个图像编码为一组补丁序列,并构建一个基于tansformer的强基线,并进行了一些关键的改进,在几个ReID基准测试上与基于cnn的方法对比取得了具有竞争力的结果。为了进一步增强tansformer情况下的鲁棒特征学习,我们精心设计了两个新的模块。(i)提出了拼图补丁模块(JPM),通过移位和补丁洗牌操作来重新排列补丁嵌入,产生稳健的特征,识别能力提高,覆盖范围更多样化。(ii)引入了侧信息嵌入(SIE),通过插入可学习的嵌入来合并这些非视觉线索,来减轻对相机/视图变化的特征偏差。据我们所知,这是第一个采用纯变压器进行ReID研究的工作。TransReID的实验结果前景优越,在人和车辆的ReID基准上都取得了最先进的性能。代码可在https://github上找到。com/heshuting555/TransReID.
1. Introduction
Object重新识别(ReID)旨在跨不同的场景和相机视图关联特定的对象,例如在人员ReID和车辆ReID的应用程序中。提取鲁棒和鉴别特征是ReID的重要组成部分,长期以来一直被基于cnn的[19,37,36,44,42]方法所主导。

图1:注意力图的Grad-CAM[34]可视化:(a)原始图像,基于(b)CNN的方法,©CNN+注意方法,(d)基于tansformer的方法,捕获全局上下文信息和更具区别的部分。

图2:2个外观相似的难样本的输出特征图的可视化。与基于cnn的方法相比,基于tansformer的方法在输出特征图上保留了背包的细节,如红框所示。为了更好地可视化,输入图像被缩放到1024×512的大小。
通过回顾基于cnn的方法,我们发现了在 Object ReID领域没有很好地解决的两个重要问题。(1)在全局范围内开发丰富的结构模式对于Object ReID[54]至关重要。然而,由于有效接受域[29]的高斯分布,基于cnn的方法主要集中在小的鉴别区域上。最近,注意模块[54,6,4,48,21,2]被引入来探索远程依赖关系[45],但它们大部分都嵌入了深层,并不能解决CNN的原理问题。因此,基于注意的方法仍然倾向于大的连续区域,且很难提取多个多样化的区分部分(见图1)。(2)具有详细信息的细粒度特性也很重要。然而,CNN的降采样操作符(如池化和strided卷积)降低了输出特征图的空间分辨率,极大地影响了区分外观相似的物体的识别能力。如图2所示,该背包的细节在基于cnn的特征地图中丢失了,因此很难区分这两个人。
最近,Vision Transformer(ViT)[8]和Data efficient image Transformers (DeiT)[40]已经表明,纯Transformer在图像识别方面可以与基于CNN的特征提取方法一样有效。随着多头注意模块的引入和卷积和下采样操作符的去除,基于Transformer的模型适合解决基于cnn的ReID中的上述问题,原因如下。(1)与CNN模型相比,多头自我注意力捕捉了远程依赖关系,并驱动模型参与不同的人体部位(如图1中的大腿、肩膀、腰部)。(2)不需要降采样操作,Transformer就可以保存更详细的信息。例如,我们可以观察到,背包周围的特征图上的差异(在图2中用红色的方框标记)可以帮助模型很容易地区分这两个人。这些优点促使我们在对象ReID中引入Transformer。
尽管如上所述,Transformer具有巨大的优势,但仍然需要专门为物体ReID设计Transformer,以应对独特的挑战,如图像中的大变化(如遮挡、姿态的多样性、相机视角)。通过基于cnn的方法,人们已作出了大量努力,以减轻这一挑战。其中,局部part特征具有[37,44,20,49,28]和side信息(如摄像机和视点)[7,61,35,30],已被证明是增强特征鲁棒性的必不可少的和有效的。学习部分/条纹聚合特征使其对遮挡和错位[50]具有鲁棒性。然而,将刚性条纹部分方法从基于cnn的方法扩展到基于纯Transformer的方法,可能会由于全局序列分裂为几个孤立的子序列而破坏长期依赖关系。此外,考虑到侧面信息,如摄像机和视点特定的信息,可以构造一个不变的特征空间,以减少侧面信息变化所带来的偏差。然而,在CNN上构建的side信息的复杂设计,如果直接应用Transformer,就不能充分利用Transformer固有的编码能力。因此,一个纯Transformer特定设计的模块是不可避免的,和必要的去成功地处理这些挑战。
因此,我们提出了一个新的对象ReID框架,称为TransReID来学习鲁棒的特征表示。首先,通过进行一些关键的适应,我们构建了一个基于纯变压器的强基线框架。
其次,为了扩展远程依赖性和增强特征的鲁棒性,我们提出了一个拼图补丁模块(JPM),通过移位和洗牌操作重新排列补丁嵌入,并重新分组,以进行进一步的特征学习。在模型的最后一层使用JPM与不包含此特殊操作的全局分支并行提取鲁棒特征。因此,该网络倾向于提取具有全局背景的扰动不变和鲁棒特征。第三,为了进一步增强鲁棒特征的学习能力,引入了一种侧信息嵌入(SIE)。而不是像在cnn方中的那样特殊和复杂的设计去实现这些非视觉的线索。我们提出了一个统一的框架,通过可学习的嵌入有效地整合非视觉线索,以减轻相机或视角带来的数据偏差。以相机为例,所提出的SIE有助于解决相机间和相机内匹配之间巨大的两两相似性差异(见图6)。SIE也可以很容易地扩展到包括除了我们已经演示的线索以外的任何非视觉线索。
据我们所知,我们是第一个研究纯Transformer在对象ReID领域的应用的人。本文的贡献总结如下:
我们提出了一个强大的基线,首次利用纯Transformer用于ReID任务,并实现了与基于cnn的框架相当的性能。
•我们设计了一个拼图补丁模块(JPM),包括移位和补丁洗牌操作,促进对象的扰动不变和鲁棒的特征表示。
•我们引入了一种侧信息嵌入(SIE),它通过可学习的嵌入来编码侧信息,并被证明可以有效地减轻所学习特征的偏差。
•最终框架TransReID在个人和车辆ReID基准上实现了最先进的性能,包括MSMT17[46]、市场-1501[55]、双MTMC-reID[33]、双[31]、VeRi-776[24]和车辆[23]。
2. Related Work
2.1. Object ReID
对object的ReID的研究主要集中在行人的ReID和车辆的ReID上,其中最先进的方法都是基于CNN结构的。Object ReID的一个流行的pipeline是设计合适的损失函数来训练CNN主干(例如ResNet[14]),它用于提取图像的特征。交叉熵损失(ID损失)[56]和三联体损失[22]在深度ReID中应用最为广泛。罗等人。[27]提出,BNNeck可以更好地结合ID损失和三联体损失。孙等人。[36]提出了ID损失和三联体损失的统一观点。
Fine-grained Features.
我们已经学习了细粒度的特征来聚合来自不同部分/区域的信息。细粒度的部分要么由大致水平条纹自动生成,要么通过语义解析自动生成。方法如PCB[37],MGN[44],A对齐dReID++[28],SAN[32]等将图像分成几条,并提取每个条的局部特征。使用解析或关键点估计来对齐不同的部件或两个对象也已被证明对人和车辆的ReID[25,30,47,31]都是有效的。
Side Information.
对于在跨照相机系统中捕获的图像,在姿态、方向、照明、分辨率等方面存在很大的变化。由不同的相机设置和对象视点引起的。一些工作的[61,7]使用side信息,如相机ID或视点信息来学习不变的特征。例如,基于相机的批处理归一化(CBN)[61]迫使来自不同相机的图像数据投影到同一子空间上,从而使相机间和相机内对之间的分布差距大大减小。观点/方向不变特征学习[7,60]对人和车辆ReID都很重要。
2.2. Pure Transformer in Vision
在[41]中提出了Transformer模型来处理自然语言处理(NLP)领域的顺序数据。许多研究也表明了它在计算机视觉任务中的有效性。韩等人。[11]和Salman等人。[18]研究了Transformer在计算机视觉领域的应用。
纯Transformer的模型越来越受欢迎。例如,Image Processing Transformer(IPT)[3]利用Transformer进行了大规模的预训练,并在超分辨率、去噪和de-raining等多个图像处理任务上实现了最先进的性能。最近提出了ViT[8],它将纯Transformer直接应用于图像补丁序列。然而,ViT需要一个大规模的数据集来对模型进行预训练。为了克服这个缺点,Touvron等人。[40]提出了一个名为DeiT的框架,该框架引入了一种针对Transformer的师生策略,以加快ViT训练,而不需要大规模的训练前数据。
3. Methodology
我们的对象ReID框架是基于基于Transformer的图像分类,但有几个关键的改进来捕获鲁棒的特征(Sec。3.1)。为了进一步增强Transformer背景下的鲁棒特性学习,我们在Sec3.2和3.3中精心设计了一个拼图补丁模块(JPM)和一个侧信息嵌入(SIE)。.这两个模块以端到端的方式进行联合训练,如图4所示。
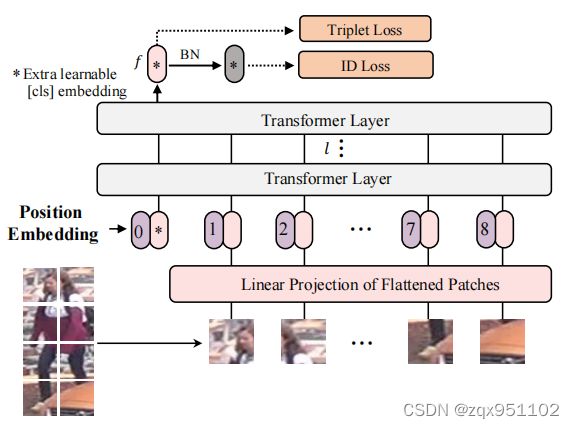
图3:基于Transformer的强基线框架(显示了一个不重叠的分区)。标记有∗的输出[cls]标记作为全局特性f。受[27]的启发,我们在f之后引入了BNNeck。

图4:建议的TransReID的框架。侧面信息嵌入(浅蓝色)将非视觉信息,如摄像机或视点编码为嵌入表示。它与补丁嵌入和位置嵌入一起被输入到变压器编码器中。最后一层包括两个独立的transform层。一个是编码全局特性的标准方法。另一个包含拼图补丁模块(JPM),它将所有的补丁重新洗牌,并将它们重新分组为几个组。所有这些组都被输入到一个共享的变压器层中,以学习本地特性。全局特性和本地特性都会导致ReID丢失。
3.1. Transformer-based strong baseline
我们为对象ReID构建了一个基于Transformer的强基线,并遵循对象ReID[27,44]的一般强管道。该方法有两个主要阶段,即特征提取和监督学习。如图3所示。给定一个图像x∈RH×××C,其中H、W、C分别表示其高度、宽度和通道数,我们将其分成N个固定大小的补丁{xip|i=1,2,···、N}。在输入序列的前面有一个额外的可学习的嵌入标记,表示为xcls。输出标记cls作为一个全局特征表示为f。通过添加可学习的位置嵌入来整合空间信息。然后,输入到变压器层的输入序列可以表示为:
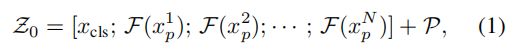
其中z0表示输入序列嵌入和![]()
是位置嵌入。F是一个将补丁映射到D维数的线性投影。此外,我们还使用了l个Transformer层来学习特征表示。解决了基于cnn的方法的有限接受域问题( limited receptive field),因为所有的Transformer层都有一个全局的接受域。也没有降采样操作,因此保留了详细信息。
Overlapping Patches.
基于纯Transformer的模型(例如ViT、DeiT)将图像分割成不重叠的补丁,失去了补丁周围的局部邻近结构。相反,我们使用一个滑动窗口来生成具有重叠像素的补丁。将步长表示为S,块大小表示为P(例如16),则两个相邻块重叠区域的形状表示为(P−S)×P。分辨率为H×W的输入图像将被分割成N个斑块。
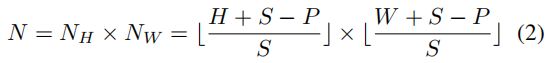
其中![]()
为地板函数,S设置小于P.NH和NW分别表示高度和宽度上的分裂的块数。S越小,图像将被分割成的补丁就越多。直观地说,更多的补丁通常会带来更好的性能和更多的计算成本。
Position Embeddings.
由于ReID任务的图像分辨率在图像分类中可能与原始的图像分辨率不同,因此在这里不能直接加载在ImageNet上预训练的位置嵌入。因此,引入了一个双线性二维插值来帮助处理任何给定的输入分辨率。与ViT类似,位置嵌入也是可学习的。
Supervision Learning.
我们通过构造全局特征的ID损失和三联体损失来优化网络。ID损失LID是不进行标签平滑的交叉熵损失。对于三联体集合{a、p、n},具有soft—margin的三联体损失LT如下所示:
![]()
3.2. Jigsaw Patch Module
虽然基于Transformer的强基线可以在对象ReID中实现令人印象深刻的性能,但它利用了来自整个图像的信息用于object ReID。然而,由于遮挡和错位等挑战,我们可能只能部分地观察到一个物体。学习细粒度的局部特性,如条纹化特征已被广泛用于基于cnn的方法来解决这些挑战。
假设最后一层输入的隐藏特征记为Zl−1=[z0l−1;z11−1,z2l−1,…,zNl−1]。要学习细粒度的局部特征,一个简单的解决方案是将[z1l−1、z2l−1、…,zNl−1]分割为k组,以便连接共享标记z0l−1,然后将k特征组输入共享Transformer层,学习k个局部特征表示为{flj|j=1、2、···、k},flj是第j组的输出标记。但是它可能没有充分利用Transformer的全局依赖关系,因为每个局部段只考虑一部分的连续补丁嵌入。
为了解决上述问题,我们提出了一个拼图补丁模块(JPM)来将补丁嵌入重新洗牌,然后将它们重新分组到不同的部分,每个部分包含整个图像的几个随机补丁嵌入。此外,在训练中引入的额外扰动也有助于提高目标ReID模型的鲁棒性。受shuffle Net[53]的启发,补丁嵌入通过移位操作和补丁洗牌操作进行洗牌。序列嵌入Zl−1的打乱如下:
步骤1:the shift操作。前m补丁(除[cls]标记外)移动到最后,即[zl1−1、zl2−1、…,zlN−1]按m步移动变成[zlm−+1 1 、zlm−+2 1 、…,zlN−1、zl1−1、zl2−1、…,zlm−1]。
步骤2:The patch shufflfle operation. 通过k组的补丁洗牌操作,进一步打乱。隐层的特征成为[zx1l−1,zx2l−1,…,zxNl−1]、xi∈[1,N]。
通过shift和shuffle操作,局部特征flj可以覆盖来自不同车身或车辆部位的补丁,说明局部特征具有全局鉴别能力。
如图4所示,与拼图补丁平行,另一个全局分支将Zl−1编码为Zl=[fg;zl1,zl2,…,zlN],其中fg作为基于cnn的方法的全局特征。最后,利用LID和LT对全局特征fg和k个局部特征进行训练。总损失的计算方法如下:

在推理过程中,我们将全局特征和局部特征[fg、fl1、fl2、…,flk]连接作为最终的特征表示。仅使用fg是一种计算成本较低且性能略有下降的变化。
3.3. Side Information Embeddings
在获得细粒度的特征表示后,特征仍然容易受到相机或视点变化的影响。换句话说,由于场景偏差,训练后的模型很容易无法从不同的角度区分同一物体。因此,我们提出了一种侧信息嵌入(SIE)来将非视觉信息,如摄像机或视点,纳入嵌入表示中,以学习不变特征。
受采用可学习嵌入编码位置信息的启发,我们插入可学习的一维嵌入来保留边信息。特别是,如图4所示,SIE与patch嵌入和位置嵌入一起插入到变压器编码器中。具体来说,假设总共有NC摄像机id,我们将可学习的侧信息嵌入初始化为SC∈RNC×D。如果图像的相机ID为r,则其相机嵌入可以表示为SC[r]。与不同补丁之间的位置嵌入系统不同,相机嵌入系统对于图像的所有补丁都是相同的。此外,如果对象的视点可用,无论是通过视点估计算法还是人工注释,我们也可以将视点标签q编码为SV[q],用于图像的所有补丁,其中SV∈RNV×D和NV表示视点id的数量。
现在出现的问题是,如何集成两种不同类型的信息。一个简单的解决方案可能是直接将这两个嵌入添加在一起,就像SC[r]+SV[q]一样。然而,由于冗余或对抗性,这两种嵌入可能会产生对抗性而相互抵消消息我们建议将照相机和视点联合编码为S(C,V)∈R(NC×NV)×D。
最后,将摄像机IDr和视点IDq的输入序列输入Transformer层如下:
![]()
其中z0为Eq中的原始输入序列在公式2中,和λ是平衡SIE权重的超参数。由于每个补丁的位置嵌入不同,但在不同的图像上是相同的,而S(C,V)是相同的,但对于不同的图像可能有不同的值。Transformer层能够对具有不同分布属性的嵌入进行编码,然后可以直接添加这些属性。
这里我们只演示了SIE与相机和视点信息的使用,这都是分类变量。在实践中,SIE可以进一步扩展到编码更多类型的信息,包括分类变量和数值变量。在我们对不同基准的实验中,相机和视点信息都包括在内。
4. Experiments
4.1. Datasets
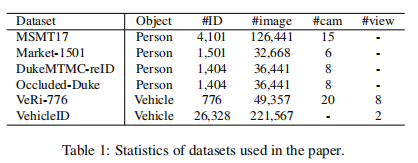
我们在四个人ReID数据集、Market-1501[55]、DukeMTMC-reID[33]、MSMT17[46]、闭塞-Duke[31]和两个车辆ReID数据集、[31]-776[24]和车辆ID[23]上评估了我们提出的方法。值得注意的是,与其他数据集不同,被遮挡-duke中的图像是从DukeMTMC-reID中选择的,训练/查询/图库集分别包含9%/100%/10%的被遮挡图像。除车辆外,所有数据集都为每幅图像提供相机ID,而只有VeRi-776和车辆数据集为每幅图像提供视点标签。表1总结了这些数据集的细节。
4.2. Implementation
除非另有说明,所有人员图像的大小将调整为256×128,所有车辆图像的大小将调整为256×256。采用随机水平翻转、填充、随机裁剪和随机擦除[57]来增强训练图像。批处理大小设置为64,每个ID有4张图像。采用SGD优化器的动量为0.9和权重为1e-4的衰减。学习率初始化为0.008,余弦学习率衰减。除非另有说明,我们分别为人和车辆的ReID数据集设置m=5、k=4和m=8、k=4。所有的实验都使用一个英伟达TeslaV100GPU进行,使用PyTorch工具箱1和FP16训练。ViT的初始权重在ImageNet-21K上进行预先训练,然后在ImageNet-1K上进行细化,而DeiT的初始权重仅在ImageNet-1K上进行训练。
评估协议。根据ReID社区的惯例,我们使用累积匹配特征(CMC)曲线和平均平均精度(mAP)来评估所有的方法。
4.3. Results of Transform-based Baseline
在本节中,我们在表2中比较了基于cnn和基于转换器的骨干。为了显示计算和性能之间的权衡,我们选择了几个不同的主干。DeiT小、DeiT基、ViT-Base分别记为DeiT-S、DeiT-B、ViT-B。ViT-B/16s=14表示重叠补丁设置中的ViT-Base,补丁大小为16,步长为S=14。为了进行全面的比较,还包括了每个主干的推理时间消耗。
我们可以观察到ResNet系列和DeiT/ViT之间的模型容量很大差距。DeiT-S/16在性能和速度上都比ResNet50好一些。DeiT-B/16和ViT-B/16在ResNeSt50[51]骨干上实现了类似的性能,其推理时间少于ResNeSt50
(1.79xvs1.86x)。当我们减小滑动窗口S的步长时,基线的性能可以提高,同时推理时间也在提高。ViT-B/16s=12比ResNeSt200更快(2.81xvs3.12x)并且在ReID基准测试上的性能略优于ResNeSt200。因此,ViT-B/16s=12比ResNeSt200实现了更好的速度-精度权衡。此外,我们认为DeiT/ViT在计算效率方面仍有很大的改进空间
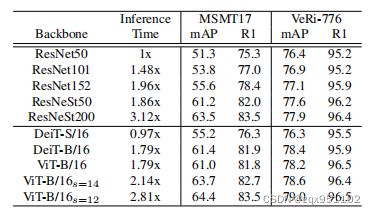
表2:不同骨干项目的比较。推理时间通过将每个模型与ResNet50进行比较来表示,因为只需要进行相对比较。所有实验均在同一台机器上进行,以进行公平比较。本文以ViT-B/16为基线模型,简称为基线
4.4. Ablation Study of JPM

表3:拼图贴片模块的消融情况研究。“不重新排列”意味着补丁功能被分成几部分而不重新排列,包括移位和洗牌操作。“w/o本地”意味着我们在不连接局部特征的情况下评估全局特征。
表3验证了所提出的JPM模块的有效性。与MSMT17和VeRi-776相比,JPM分别提供了+2.6%的mAP和+1.0%的mAP改善。增加组数k可以提高性能,同时略微提高推理时间。在我们的实验中,k=4是一个权衡速度和性能的选择。比较JPM和JPM,我们可以观察到,在MSMT17和VeRi-776上,+0.5%的mAP和+0.2%的mAP改进,通过移位和洗牌操作帮助模型学习更多的鉴别特征。还观察到,如果只有全局特性fg用于推理阶段(仍然训练全JPM),性能(表示为“w/o本地”)几乎可以与版本的功能,这表明我们只使用全局特性作为一个有效的变化与低存储成本和计算成本在推理阶段。图5中可视化的注意图显示,通过重新排列操作的JPM可以帮助模型学习更多的全局上下文信息和更具鉴别性的部分,这使模型对扰动的鲁棒性更强。

图5:注意力地图的grad-cam可视化。(a)输入图像,(b)基线,©JPM没有重新排列,(d)JPM。
4.5. Ablation Study of SIE
Performance Analysis.
在表4中,我们评估了SIE对MSMT17和VeRi-776的有效性。MSMT17不提供视点注释,所以为MSMT17显示了只编码相机信息的SIE的结果。VeRi-776不仅有每个图像的照相机ID,而且还根据车辆方向标注了8个不同的视点。因此,用SIE编码摄像机ID和/或视点信息的各种组合来显示结果。
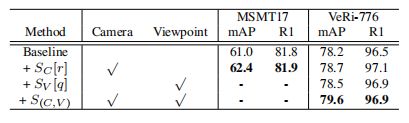
表4:SIE的消融研究。由于行人ReID数据集不提供视点注释,因此视点信息只能在VeRi-776中进行编码。
当SIE只编码图像的相机id时,该模型比MSMT17提高了1.4%的mAP和0.1%的rank-1精度。对VeRi-776也可以得出类似的结论。当SIE编码视点信息时,基线获得78.5%的mAP。当相机id和视点标签同时出现时,准确率提高到79.6%同时进行编码。如果将编码更改为SC[r]+SV[q],这是第3.3节中讨论的次优编码,我们只能在VeRi-776上达到78.3%的mAP。因此,所提出的S(C、V)是一种更好的编码方式。
Visualization of Distance Distribution.
如图6所示,图6a和图6b分别显示了摄像机和视点变化的分布间隙和明显。当我们将SIE模块引入基线时,减少了摄像机间/视点与摄像机内/视点之间的分布间隙,这表明SIE模块减弱了各种摄像机和视点引起的场景偏差的负面影响。
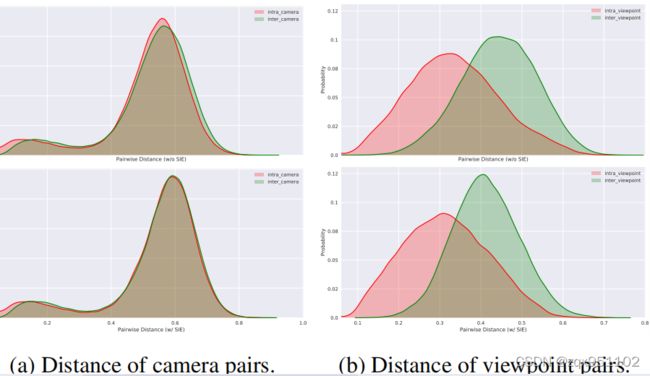
图6:我们可视化了VeRi-776上不同相机对和视点对的距离分布。(a)相机间和相机内距离分布。(b)视点间和视点内距离分布。
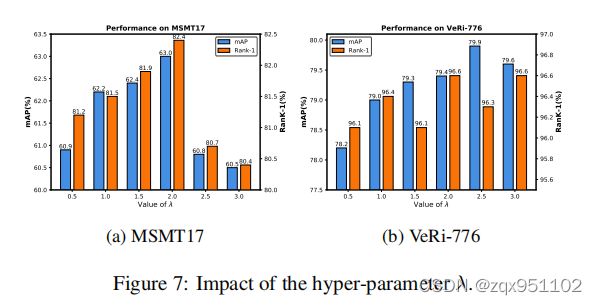
Ablation Study of λ.
我们在图7中分析了SIE模块的权重λ对性能的影响。当λ=0时,基线在MSMT17和VeRi-776上分别达到61.0%mAP和78.2%mAP。随着λ的增加,mAP被提高到63.0%mAP(MSMT17的λ=2.0)和79.9%mAP(VeRi-776的λ=2.5),这意味着SIE模块现在有利于学习不变特性。随着λ值的不断增加,由于特征嵌入和位置嵌入的权重减弱,性能有所下降。
4.6. Ablation Study of TransReID
最后,我们在表5中评估了引入JPM和SIE的好处。对于基线,JPM和SIE分别提高了+2.6%/+1.0%mAP和+1.4%/+1.4%mAP在MSMT17/VeRi-776上的性能。将这两个模块一起使用后,TransReID在MSMT17和VeRi-776上分别达到64.9%(+3.9%)和80.6%(+2.4%)。实验结果表明了我们提出的JPM、SIE和整体框架的有效性。
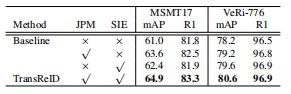
表5:TransReID的消融术研究。
4.7. Comparison with State-of-the-Art Methods
在表6中,我们的TransReID与最先进的方法进行了比较,包括行人ReID、遮挡ReID和车辆ReID。
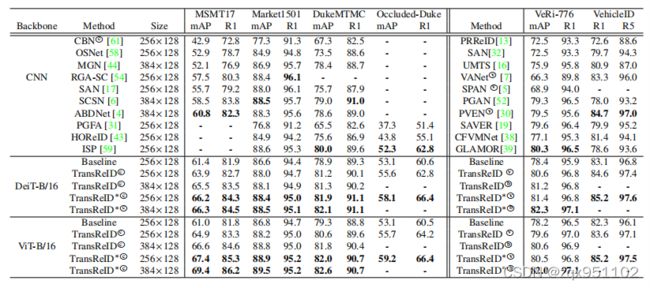
表6:与最先进的方法的比较。DukeMTMC表示DukeMTMC-reID基准测试。上标中的星号*表示主干具有滑动窗口设置。显示了人员ReID数据集(左)和车辆ReID数据集(右)的结果。本文只使用了车辆识别的一小子集。c和v表示这些方法分别使用了相机id和视点标签。b表示两者都被使用了。视点和相机信息可随时使用。以前方法的最佳结果和我们的方法的最佳结果用粗体标记。
Person ReID.在MSMT17和DukeMTMC-reID上,TransReID∗(DeiT-B/16)在很大程度上优于以前最先进的方法(+5.5%/+2.1%mAP)。在market-1501上,TransReID∗(256×128)取得了与最先进的方法相当的性能,特别是在map。与CBN[61]等集成相机信息的方法相比,我们的方法也显示出了优越性。
Occluded ReID. ISP通过迭代聚类隐式地使用人体语义信息,HOReID引入外部姿态模型来对齐身体部位。与上述方法相比,TransReID(DeiT-B/16)实现了55.6%的mAP,有很大的边际提高(至少+3.3%的mAP),而不需要任何语义和姿态信息来对齐身体部位,这表明TransReID生成稳健的特征表示的能力。此外,TransReID∗通过重叠补丁将性能提高到58.1%的mAP。
Vehicle ReID.在VeRi-776上,TransReID∗(DeiT-B/16)达到mAP的82.3%,超过魅力2.0%的mAP。当只使用视点注释时,TransReID∗在VeRi-776和车辆上仍然优于VANet和保护程序。我们的方法在车辆上取得了约85.2%的最先进的性能。
DeiT vs ViT vs CNN.TrangReID∗(DeiT-B/16)在公平比较下(ImageNet-1K训练前)与现有方法取得了竞争性能。我们的ViT-B/16方法的额外结果也报告在表6中,以供进一步比较。DeiT-B/16对于较短的图像补丁序列,实现了与ViT-B/16类似的性能。当输入补丁数量的增加时,ViT-B/16的性能达到了比DeiT-B/16更好的性能,这表明ImageNet-21K预训练提供了ViTB/16更好的泛化能力。虽然基于cnn的方法主要报告使用ResNet50主干的性能,但它们可能包括多个分支、注意模块、语义模型或其他增加计算消耗的模块。我们在同一计算硬件上对TransReID∗和MGN[44]的推理速度进行了公平的比较。与MGN相比,TransReID的速度要快4.8%。因此,TransReID可以在大多数基于cnn的方法下获得更有希望的性能。**
5. Conclusion
本文研究了一个用于对象ReID任务的纯Transformer框架,并提出了两个新的模块,即拼图补丁模块(JPM)和侧信息嵌入(SIE)。最终的框架TransReID在几个流行的人/车辆ReID数据集上,包括MSMT17、Market-1501、DukeMD,大大优于所有其他最先进的方法。基于TransReID取得的良好结果,我们认为该变压器在ReID任务中有很大的探索潜力。基于cnn的方法所获得的丰富经验,我们希望可以设计出具有更好的表示能力和更低的计算成本的更高效的基于Transformer的网络。
补充:Csdn: 这个里面标黄的是重点 不错的 参考看
https://blog.csdn.net/lwplwf/article/details/120038089?utm_medium=distribute.pc_relevant.none-task-blog-2defaultbaidujs_baidulandingword~default-1.highlightwordscore&spm=1001.2101.3001.4242.2
整体详细翻译
https://blog.csdn.net/amusi1994/article/details/115365104?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-1.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-1.no_search_link
里面有一点自己的见解想法 关于trans 需要再整理
https://blog.csdn.net/gzq0723/article/details/119813919?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-2.no_search_link&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2defaultCTRLISTdefault-2.no_search_link
讲了行人跟踪和reid之间的区别 可以参考
作者基于ViT和Bag of tricks1设计了一个名为ViT-BoT的强baseline,性能媲美ResNet、ResNeSt等CNN网络,此外,ReID数据集除了包含ID信息和视觉信息外,往往还带有相机(非视觉)信息,传统的CNN Based方法很少用到非视觉信息,想用这些信息的话也得重新设计CNN,但是transformer很容易将非视觉信息编码为vector进行嵌入表示,这是其一大优点,作者考虑到了这点,并介绍了一个Side Information Embedding (SIE)模块。最后,为了作者设计了一个Jigsaw分支(包含一个Jigsaw patch module,JPM)以更好地训练ViT-Bot,JPM是受那些切割stripes方法的启发,与后者不同,JPM中的patches被打乱形成更大的patches。结合SIE和JPM,作者提出了TransReID模型架构。
原文链接:https://blog.csdn.net/qq_38633536/article/details/115506872
这些话可以整理 写在ppt上。
作者在最后的class token后面接了一个BNNeck1(就是联合ID loss和triplet loss), 是不带标签平滑的交叉熵损失,三元组损失是如式(2)的soft-margin版本。
