在服务器上利用mmdetection来训练自己的voc数据集
在服务器上利用mmdetection来训练自己的voc数据集
- 服务器上配置mmdetection环境
-
- 在服务器上用anaconda配置自己的环境
- 进入自己的虚拟环境,开始配置mmdetection
- 跑通 mmdetection 一些简单的demo
- 实现pc端与服务器之间的文件传输(SFTP)
-
- 在Xshell上配置SFTP实现pc端和服务器的文件传输
- 在Pycharm上配置SFTP实现pc端和服务器的文件传输
- 利用 mmdetection训练自己的voc数据集
-
- 制作voc数据集
- 利用SFTP将数据集传至服务器
- 训练自己的数据集
- 利用tensorboard查看训练日志,对模型训练效果进行评估
-
- 安装tensorboardx
- 配置SSH端口映射
- 使用tensorboard 查看训练日志
- 总结
服务器上配置mmdetection环境
由于是使用公司的服务器,所以在配置mmdetection环境之前,最好先利用anaconda在服务器上配置一个自己的虚拟环境,当然也可以用Docker来管理自己的环境,但是不太熟悉,暂时先用anaconda。
在服务器上用anaconda配置自己的环境
首先,通过SSH连接服务器(可以使用xshell、putty之类的工具,推荐xshell)
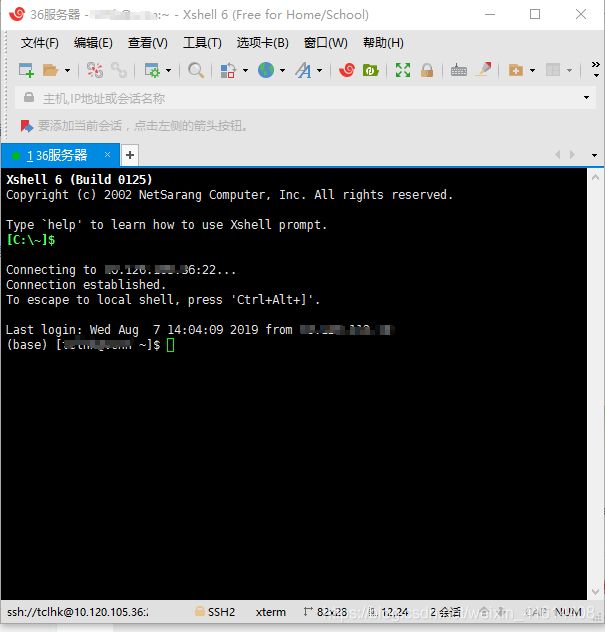
然后,利用anaconda创建自己的虚拟环境
conda create --name[虚拟环境名][python版本][需要的包]
虚拟环境名需要指定,后俩者可选填 eg:
conda create --name myenv
conda create --name myenv python==3.5
conda create --name myenv python==3.6 tensorflow-gpu==1.12.0
创建完了之后,进入自己的环境,并根据需求可以自己配置环境中的库
conda activate linpeng_zhou # 此时进入自己的虚拟环境
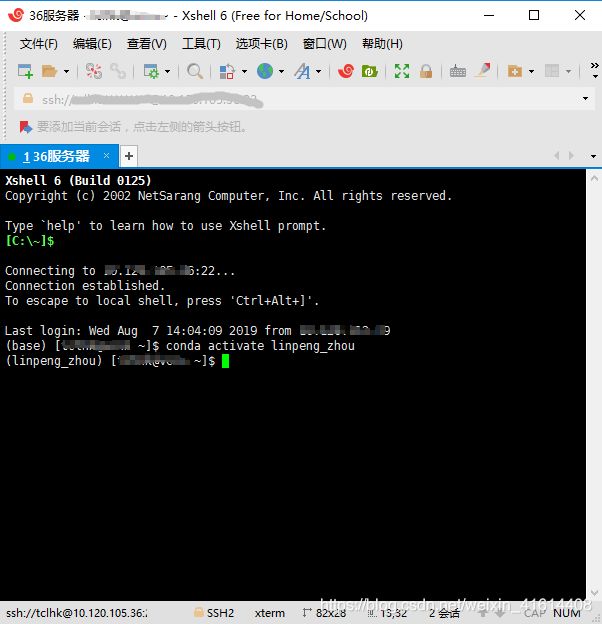
最后,为anaconda更换国内源,方便以后安装各种库
vim ~/.condarc
channels:
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
- https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2/
- defaults
show_channel_urls: true
进入自己的虚拟环境,开始配置mmdetection
在服务器上先创建自己的文件夹,各自管理各自的文件夹
mkdir zlp
cd zlp
mmdetection是基于pytorch的一个框架,pytorch底层是c实现的,所以需要安装cython库
conda install cython
# Clone mmdetection from github
git clone https://github.com/open-mmlab/mmdetection.git
cd mmdetection
#install mmdetection
python3 setup.py develop
#or "pip install -v -e ."
最终,在服务器上配置好了mmdetection环境。
跑通 mmdetection 一些简单的demo
下面是网上找到一个demo,需要先下载一个模型文件
from mmdet.apis import init_detector, inference_detector, show_result
# 首先下载模型文件https://s3.ap-northeast-2.amazonaws.com/open-mmlab/mmdetection/checkpoints/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth
config_file = 'configs/faster_rcnn_r50_fpn_1x.py'
checkpoint_file = 'checkpoints/faster_rcnn_r50_fpn_1x_20181010-3d1b3351.pth'
#checkpoint_file = 'checkpoints/faster_rcnn_r101_fpn_2x_20181129-73e7ade7.pth'
# 初始化模型
model = init_detector(config_file, checkpoint_file)
# 测试一张图片
img = 'demo/coco_test_12510.jpg'
result = inference_detector(model, img)
#show_result(img, result, model.CLASSES)
print(result)
#测试一系列图片
#imgs = ['test1.jpg', 'test2.jpg']
#for i, result in enumerate(inference_detector(model, imgs, #device='cuda:0')):
# show_result(imgs[i], result, model.CLASSES, #out_file='result_{}.jpg'.format(i))
由于服务器上无法可视化效果,可以将result打印出来,可以看到result里面包含了检测框的坐标信息。
实现pc端与服务器之间的文件传输(SFTP)
同样是用Xshell这个工具,后面会介绍用pycharm实现文件传输,其实俩者都是利用SFTP来实现传输功能的,pycharm还有一个好处就是方便pc端调试服务器上的代码。
在Xshell上配置SFTP实现pc端和服务器的文件传输
在新建会话时选择SFTP协议,名称可以修改为SFTP,端口号默认22不变
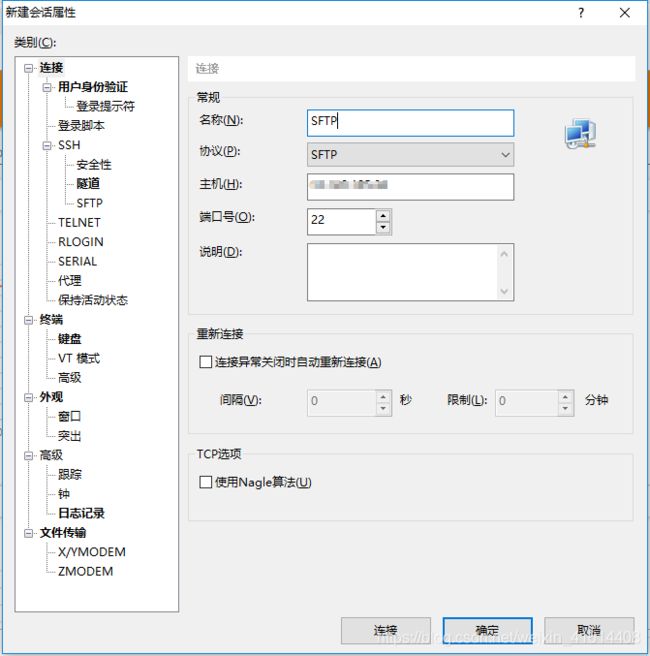
输入登录用户名,并勾选记住用户名,下次登陆直接双击即可进入。

输入服务器登陆密码,并勾选记住密码。
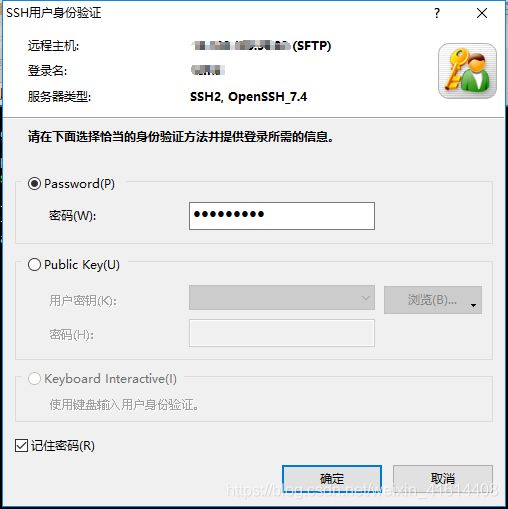
此时,我们在pc端利用Xshell,通过SFTP协议与服务器建立了连接,接下来可以进行文件传输操作。
首先,实现pc端传文件至服务器,我们先要设置本地文件路径以及服务器端文件路径:
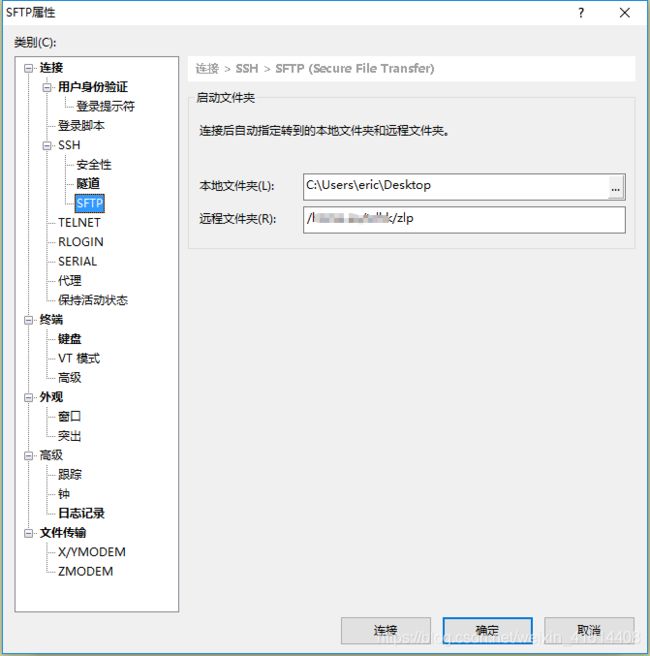
设置完成后,双击开启之前创建的SFTP这个会话,此时我们可以将文件传输到刚刚设置的服务器端路径下。
put ./SFTP_PC.txt ./ #前面是PC端文件路径+文件名 后面是服务器端文件路径
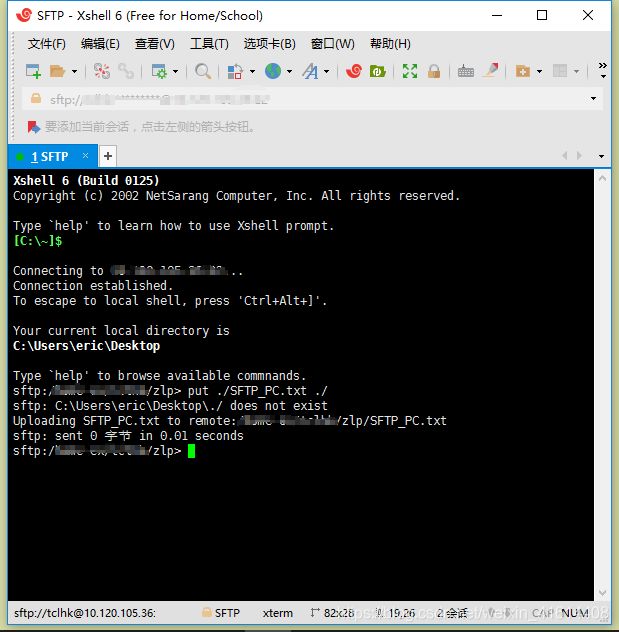
从服务器上下载文件至本地也是类似:
get ./SFTP_Linux.txt ./ #前面是服务器端路径加文件名,后面是PC端路径
在Pycharm上配置SFTP实现pc端和服务器的文件传输
其实方法和Xshell上面配置类似,首先选择SFTP协议,再选择pc端文件路径与服务器端文件路径通过账号密码连接服务器。
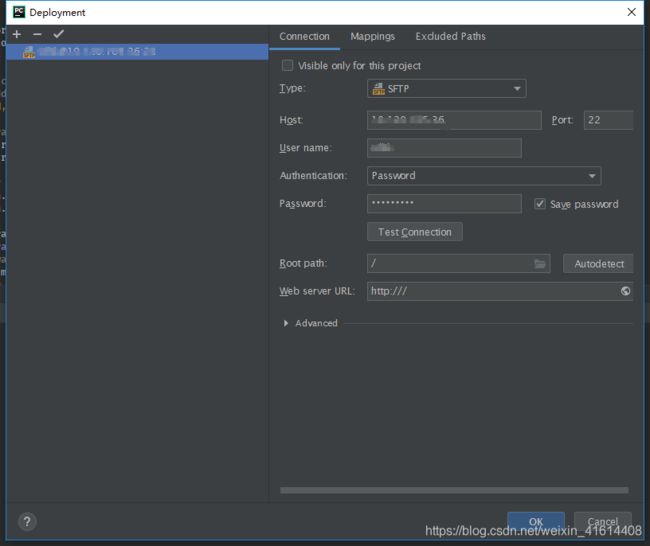
1.打开pycharm,选择菜单栏Tools->Deployment->Configuration,选择SFTP,输入Host、User name、Password
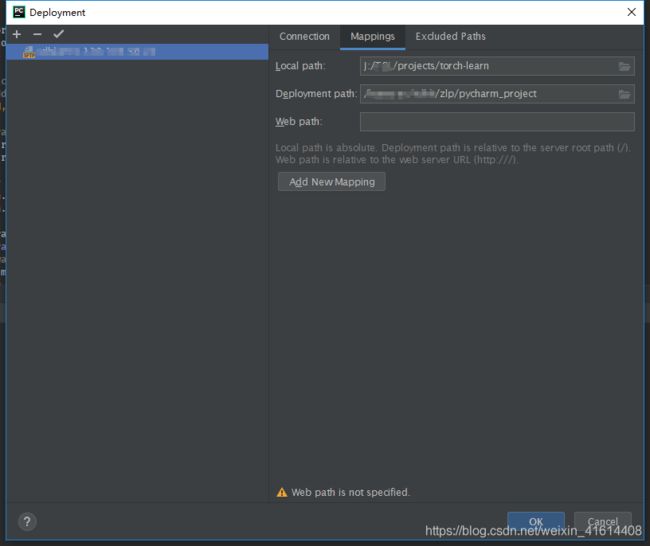
2.选择菜单栏的Mappings,填好PC端路径以及服务器端路径,之后点击确认,就可以在pycharm的右侧看到服务器上的文件了。
3.pycharm上进行文件传输也很简单,pc端上传到服务器端,只需选中需要传输的文件右键选择Deployment->uploadto name@host就能上传至服务器。
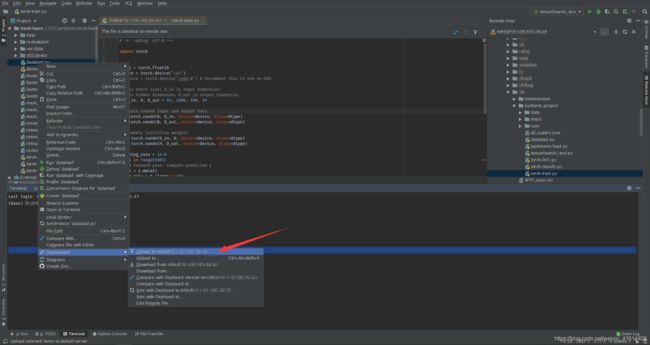
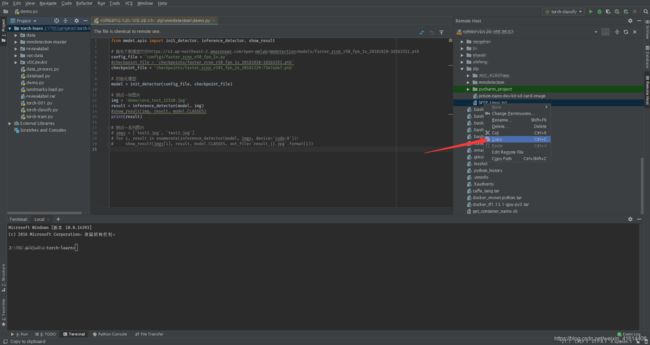
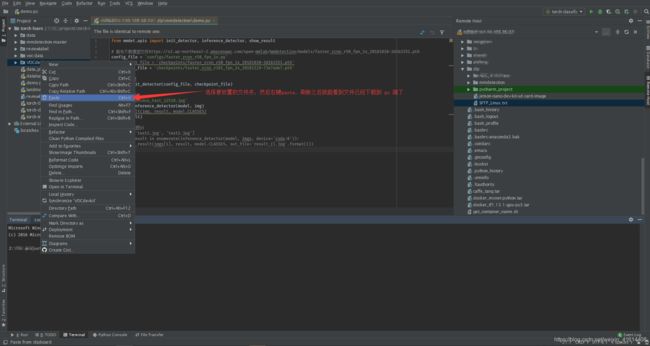
服务器上文件下载到pc端只需选中文件右键,选择copy,到左侧目录下paste就可以将文件下载下来。
利用 mmdetection训练自己的voc数据集
在这些基础工作完成之后,我们开始利用mmdetection来训练自己的数据集,由于mmdetection对于voc,coco,cityscapes这些经典数据集写好了Dataloader,我们可以直接将我们的数据集做成voc数据集的格式,省去自己写Dataloader的时间。
制作voc数据集
制作voc数据集的第一步就是按voc数据集的格式创建好文件夹,下面是文件夹的组织方式,Annotations中存放图片的标注文件,JPEGImages存放图片数据。
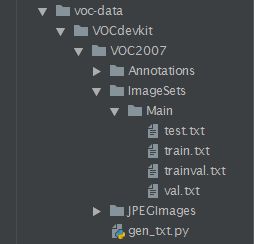
可以看到Main文件夹下存放了四个txt文件,这些文件里面的内容其实就是将数据集打乱并划分为测试集,训练集,训练验证集,验证集之后的文件名。在网络训练过程中,可以通过文件名来索引训练样本。这四个文件可由 gen_txt.py 来生成。
import os
import random
trainval_percent = 0.8 # trainval数据集占所有数据的比例
train_percent = 0.6 # train数据集占trainval数据的比例
filepath = 'JPEGImages'
txtsavepath = 'ImageSets\Main'
total = os.listdir(xmlfilepath)
num=len(total)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('ImageSets/Main/trainval.txt', 'w')
ftest = open('ImageSets/Main/test.txt', 'w')
ftrain = open('ImageSets/Main/train.txt', 'w')
fval = open('ImageSets/Main/val.txt', 'w')
for i in list:
name=total[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
注意自己的文件路径,可能需要根据自己的存放位置进行修改。
创建好文件夹之后,将所有图片数据放到JPEGImages文件夹下,利用labelimg标注工具进行标注,labelimg工具的安装和使用都很方便:
pip install labelimg #安装labelimg
使用时只需在cmd下输入labelimg回车即可进入使用界面。
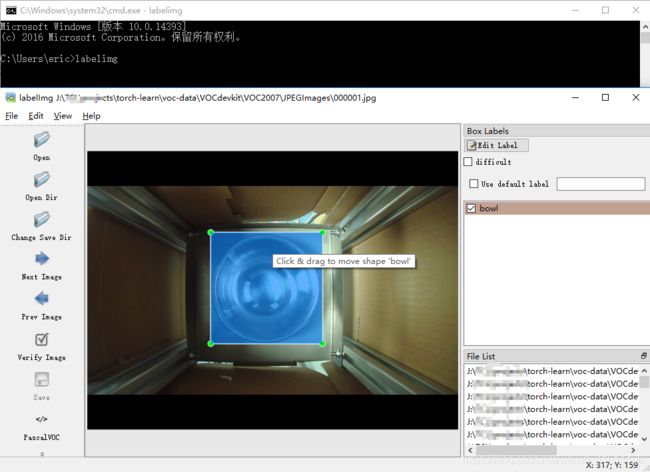
我们采用的数据集是之前实验室采集来训练四分类网络的图片数据,所以都是单类简单场景图片,上面为标注效果图,在标注前我们先选择图片文件夹为JPEGImages,标注文件保存文件夹为Annotations,我们先标注100张(实际项目中的数据量远不止这么多,一般都是上万张图),我们主要的目的是把mmdetection训练自己的数据集的整个流程先熟悉一遍。
利用SFTP将数据集传至服务器
按文件目录组织好待训练的数据之后,利用SFTP将数据集传到服务器上mmdetection文件夹中,命名为voc_data,具体的执行步骤参照之前的章节描述。
训练自己的数据集
所有的准备工作做好之后,就可以训练自己的数据集了,官方给出的训练脚本有多GPU并行训练以及单GPU训练版本,由于服务器资源有限,我采用了单GPU训练模式。
- 首先,登陆服务器,激活自己的虚拟环境
conda activate linpeng_zhou # conda activate your_env_name
cd zlp/mmdetection # 进到自己的文件夹下
- 在mmdetection/configs文件夹下创建一个my_voc.py
# model settings
model = dict(
type='RetinaNet',
pretrained='torchvision://resnet101',
backbone=dict(
type='ResNet',
depth=101,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
start_level=1,
add_extra_convs=True,
num_outs=5),
bbox_head=dict(
type='RetinaHead',
num_classes=81,
in_channels=256,
stacked_convs=4,
feat_channels=256,
octave_base_scale=4,
scales_per_octave=3,
anchor_ratios=[0.5, 1.0, 2.0],
anchor_strides=[8, 16, 32, 64, 128],
target_means=[.0, .0, .0, .0],
target_stds=[1.0, 1.0, 1.0, 1.0],
loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=1.0),
loss_bbox=dict(type='SmoothL1Loss', beta=0.11, loss_weight=1.0)))
# training and testing settings
train_cfg = dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.5,
neg_iou_thr=0.4,
min_pos_iou=0,
ignore_iof_thr=-1),
allowed_border=-1,
pos_weight=-1,
debug=False)
test_cfg = dict(
nms_pre=1000,
min_bbox_size=0,
score_thr=0.05,
nms=dict(type='nms', iou_thr=0.5),
max_per_img=100)
# dataset settings
dataset_type = 'VOCDataset'
data_root = 'my_voc/VOCdevkit/' #修改为自己的数据集路径
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
data = dict(
imgs_per_gpu=6, #根据自己的情况来设置,我的显卡是16G的Tesla p100 图片是1024*768 6张图已经接近GPU极限了
workers_per_gpu=2,
train=dict(
type='RepeatDataset', # to avoid reloading datasets frequently
times=3,
dataset=dict(
type=dataset_type,
ann_file=[
data_root + 'VOC2007/ImageSets/Main/train.txt',#train.txt
],
img_prefix=[data_root + 'VOC2007/'],
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0.5,
with_mask=False,
with_crowd=False,
with_label=True)),
val=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/trainval.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=False,
with_label=True),
test=dict(
type=dataset_type,
ann_file=data_root + 'VOC2007/ImageSets/Main/test.txt',
img_prefix=data_root + 'VOC2007/',
img_scale=(1333, 800),
img_norm_cfg=img_norm_cfg,
size_divisor=32,
flip_ratio=0,
with_mask=False,
with_crowd=False,
with_label=False,
test_mode=True))
# optimizer
optimizer = dict(type='SGD', lr=0.01, momentum=0.9, weight_decay=0.0001)
optimizer_config = dict(grad_clip=dict(max_norm=35, norm_type=2))
# learning policy
lr_config = dict(
policy='step',
warmup='linear',
warmup_iters=500,
warmup_ratio=1.0 / 3,
step=[8, 11])
checkpoint_config = dict(interval=1)
# yapf:disable
log_config = dict(
interval=1, # 设置多少步打印一次一次日志
hooks=[
dict(type='TextLoggerHook'),
dict(type='TensorboardLoggerHook') #设置通过tensorboard来查看训练日志,需要安装tensorboardx,否则可能会报错
])
# yapf:enable
# runtime settings
total_epochs = 50 # 设置训练epochs,根据自己的数据集来设定。
device_ids = range(8)
dist_params = dict(backend='nccl')
log_level = 'INFO'
#work_dir = './work_dirs/retinanet_r101_fpn_1x'
work_dir = './work_dirs/my_voc_retinanet_r101_fpn_1x' #设置checkpoints、以及log文件保存路径
load_from = None #可以设置从最后一次训练结果中加载权重继续训练
#load_from = './work_dirs/32A05_retinanet_r101_fpn_1x/latest.pth'
resume_from = None
workflow = [('train', 1)]
- 修改mmdetection/mmdet/datasets中的voc.py
from .registry import DATASETS
from .xml_style import XMLDataset
@DATASETS.register_module
class VOCDataset(XMLDataset):
# CLASSES = ('aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car',
# 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse',
# 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train',
# 'tvmonitor')
#4350 32A05
CLASSES = ('bowl',) #修改CLASSES为自己的类名,单类时记得注意加个逗号,否则会报 label=self.cat2label
def __init__(self, **kwargs):
super(VOCDataset, self).__init__(**kwargs)
if 'VOC2007' in self.img_prefix:
self.year = 2007
elif 'VOC2012' in self.img_prefix:
self.year = 2012
else:
raise ValueError('Cannot infer dataset year from img_prefix')
- 执行训练脚本
python3 tools/train.py configs/my_voc.py
- 指定GPU训练(不指定默认使用GPU:0)
CUDA_VISIBLE_DEVICES=1 python3 tools/train.py configs/my_voc.py
附上一张正在训练的日志截图
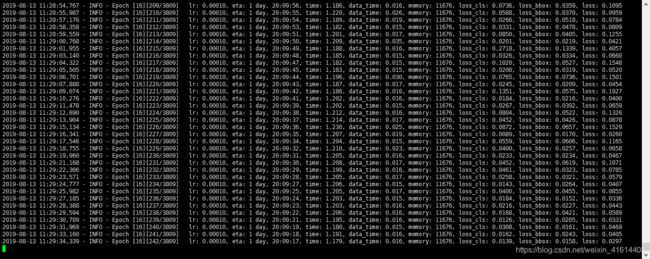
利用tensorboard查看训练日志,对模型训练效果进行评估
训练日志保存在了mmdetection/workdirs文件路径下,我们可以通过tensorboard来对训练效果进行可视化操作,不过在pytorch1.1.0之前的版本并不能直接使用tensorboard,我们需要安装tensorboardx来使用tensorboard查看训练日志。
安装tensorboardx
安装tensorboardx十分简单,直接 conda install 即可
To install this package with conda run one of the following:
conda install -c conda-forge tensorboardx
conda install -c conda-forge/label/gcc7 tensorboardx
conda install -c conda-forge/label/cf201901 tensorboardx
配置SSH端口映射
安装完tensorboardx之后,我们还无法直接在本地打开服务器上利用tensorboard得到的网址,这时我们需要利用SSH配置一下端口映射。
- 首先,选中我们的服务器,选择属性
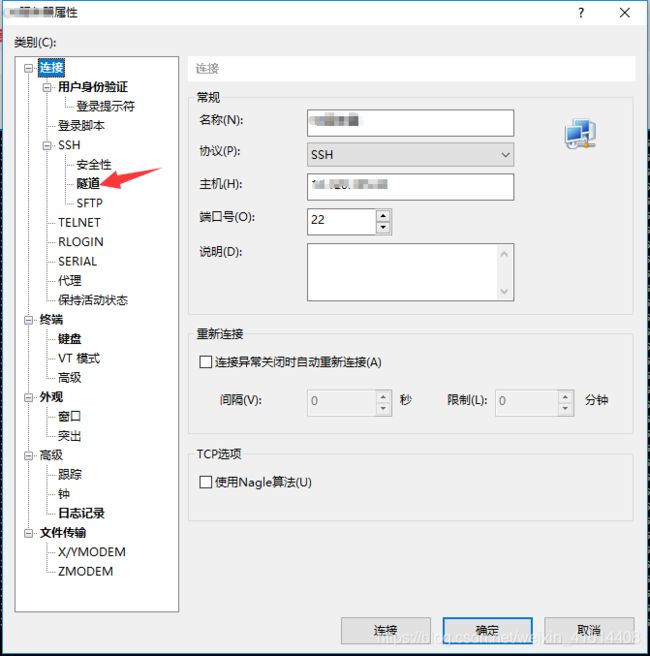
- 在属性页面选择隧道,进去之后选择添加
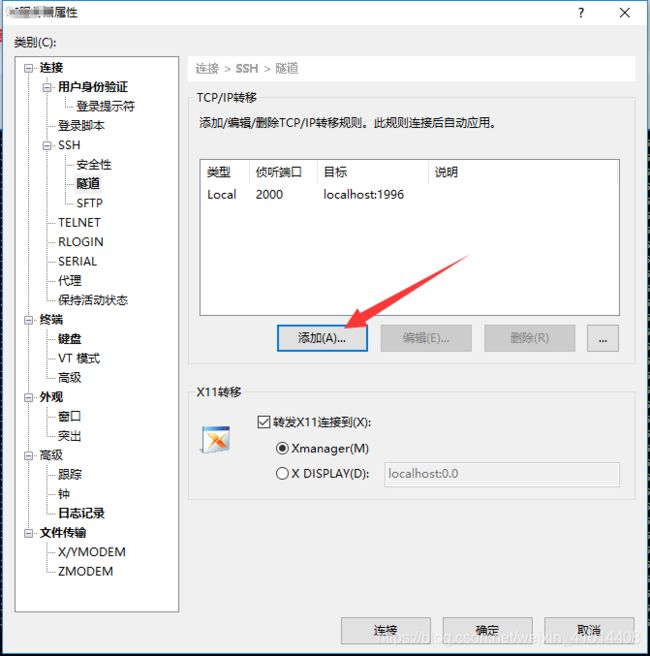
- 设置侦听端口及目标端口
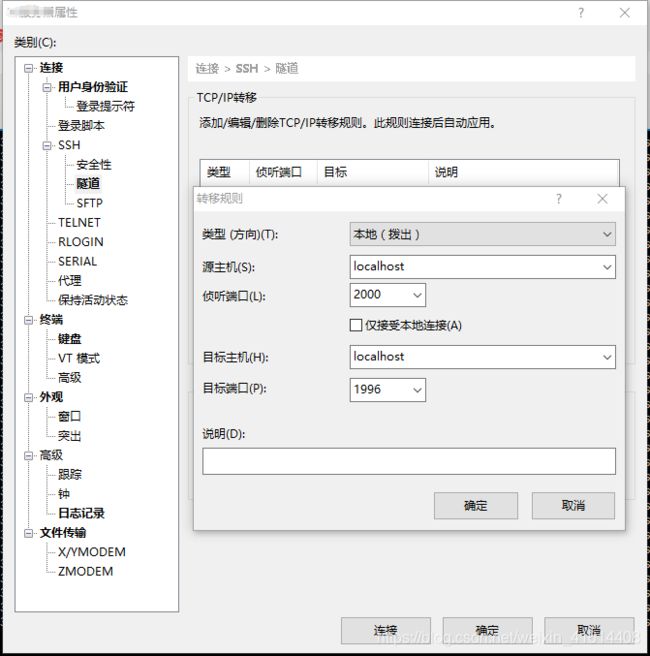
侦听端口为本地访问时输入127.0.0.1后面的端口号,目标端口则为服务器上tensorboard加载日志信息后,生成的网页的端口号,在执行tensorboard语句时需要给 --port参数,需与本次设置的一致。上面是我的配置信息。
使用tensorboard 查看训练日志
在配置完端口映射之后,我们可以使用tensorboard来对我们的训练日志进行可视化操作。
cd zlp/mmdetection
tensorboard --logdir=work_dirs/my_voc_retinanet_r101_fpn_1x/ --port=1996
不出意外的话,后面会生成一串网址
TensorBoard 1.11.0 at http://vcnn:1996 (Press CTRL+C to quit)
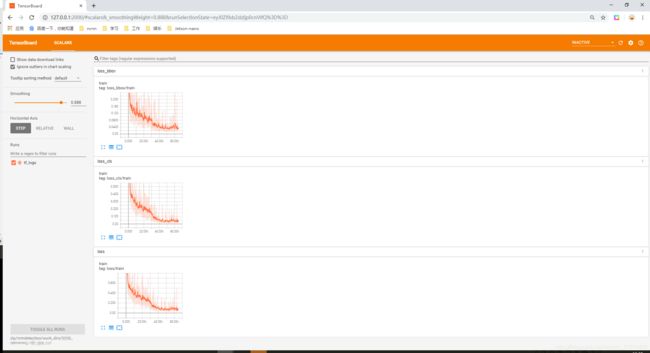
这个时候,我们在本地浏览器输入127.0.0.1;2000,即可看到bbox_loss,cls_loss和total_loss在训练过程中的变化趋势
总结
最后,总结一下,由于是第一次写CSDN,还有许多技巧需要学习,除此之外,针对于本项目:
- 学习使用Docker代替Anaconda来管理虚拟环境
- mmdetection 其实对coco标注格式的数据集支持的更好,后面可以将自己的数据集做成coco数据集的格式,再利用mmdetection去训练
- 在log中可以记录accuracy的变化情况,从多个维度来评价模型的优劣。
- 对不同的模型进行深入研究,对于不同的数据选择不同的模型来训练
- 退出及时保存!!!(未保存退出白白浪费了一俩个小时)