神经网络的常用方法有,神经网络原理及应用
BP人工神经网络方法
(一)方法原理人工神经网络是由大量的类似人脑神经元的简单处理单元广泛地相互连接而成的复杂的网络系统。理论和实践表明,在信息处理方面,神经网络方法比传统模式识别方法更具有优势。
人工神经元是神经网络的基本处理单元,其接收的信息为x1,x2,…,xn,而ωij表示第i个神经元到第j个神经元的连接强度或称权重。
神经元的输入是接收信息X=(x1,x2,…,xn)与权重W={ωij}的点积,将输入与设定的某一阈值作比较,再经过某种神经元激活函数f的作用,便得到该神经元的输出Oi。
常见的激活函数为Sigmoid型。
人工神经元的输入与输出的关系为地球物理勘探概论式中:xi为第i个输入元素,即n维输入矢量X的第i个分量;ωi为第i个输入与处理单元间的互联权重;θ为处理单元的内部阈值;y为处理单元的输出。
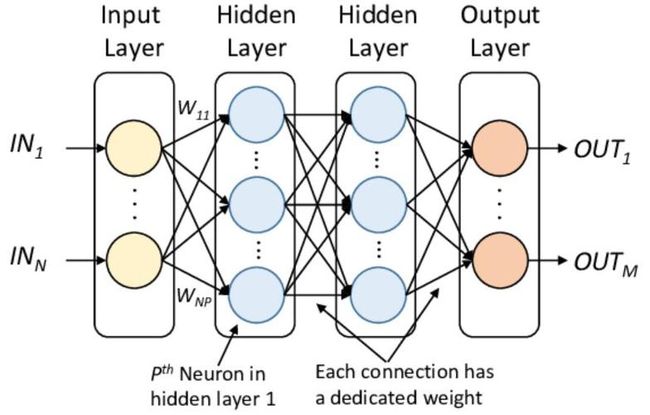
常用的人工神经网络是BP网络,它由输入层、隐含层和输出层三部分组成。BP算法是一种有监督的模式识别方法,包括学习和识别两部分,其中学习过程又可分为正向传播和反向传播两部分。
正向传播开始时,对所有的连接权值置随机数作为初值,选取模式集的任一模式作为输入,转向隐含层处理,并在输出层得到该模式对应的输出值。每一层神经元状态只影响下一层神经元状态。
此时,输出值一般与期望值存在较大的误差,需要通过误差反向传递过程,计算模式的各层神经元权值的变化量。这个过程不断重复,直至完成对该模式集所有模式的计算,产生这一轮训练值的变化量Δωij。
在修正网络中各种神经元的权值后,网络重新按照正向传播方式得到输出。实际输出值与期望值之间的误差可以导致新一轮的权值修正。正向传播与反向传播过程循环往复,直到网络收敛,得到网络收敛后的互联权值和阈值。
(二)BP神经网络计算步骤(1)初始化连接权值和阈值为一小的随机值,即W(0)=任意值,θ(0)=任意值。(2)输入一个样本X。
(3)正向传播,计算实际输出,即根据输入样本值、互联权值和阈值,计算样本的实际输出。
其中输入层的输出等于输入样本值,隐含层和输出层的输入为地球物理勘探概论输出为地球物理勘探概论式中:f为阈值逻辑函数,一般取Sigmoid函数,即地球物理勘探概论式中:θj表示阈值或偏置;θ0的作用是调节Sigmoid函数的形状。
较小的θ0将使Sigmoid函数逼近于阈值逻辑单元的特征,较大的θ0将导致Sigmoid函数变平缓,一般取θ0=1。
(4)计算实际输出与理想输出的误差地球物理勘探概论式中:tpk为理想输出;Opk为实际输出;p为样本号;k为输出节点号。
(5)误差反向传播,修改权值地球物理勘探概论式中:地球物理勘探概论地球物理勘探概论(6)判断收敛。若误差小于给定值,则结束,否则转向步骤(2)。
(三)塔北雅克拉地区BP神经网络预测实例以塔北雅克拉地区S4井为已知样本,取氧化还原电位,放射性元素Rn、Th、Tc、U、K和地震反射构造面等7个特征为识别的依据。
构造面反映了局部构造的起伏变化,其局部隆起部位应是油气运移和富集的有利部位,它可以作为判断含油气性的诸种因素之一。
在该地区投入了高精度重磁、土壤微磁、频谱激电等多种方法,一些参数未入选为判别的特征参数,是因为某些参数是相关的。
在使用神经网络方法判别之前,还采用K-L变换(Karhaem-Loeve)来分析和提取特征。S4井位于测区西南部5线25点,是区内唯一已知井。
该井在5390.6m的侏罗系地层获得40.6m厚的油气层,在5482m深的震旦系地层中获58m厚的油气层。
取S4井周围9个点,即4~6线的23~25点作为已知油气的训练样本;由于区内没有未见油的钻井,只好根据地质资料分析,选取14~16线的55~57点作为非油气的训练样本。
BP网络学习迭代17174次,总误差为0.0001,学习效果相当满意。以学习后的网络进行识别,得出结果如图6-2-4所示。
图6-2-4塔北雅克拉地区BP神经网络聚类结果(据刘天佑等,1997)由图6-2-4可见,由预测值大于0.9可得5个大封闭圈远景区,其中测区南部①号远景区对应着已知油井S4井;②、③号油气远景区位于地震勘探所查明的托库1、2号构造,该两个构造位于沙雅隆起的东段,其西段即为1984年钻遇高产油气流的Sch2井,应是含油气性好的远景区;④、⑤号远景区位于大涝坝构造,是yh油田的组成部分。
谷歌人工智能写作项目:小发猫

人工神经网络分类方法
从20世纪80年代末期,人工神经网络方法开始应用于遥感图像的自动分类rfid。
目前,在遥感图像的自动分类方面,应用和研究比较多的人工神经网络方法主要有以下几种:(1)BP(BackPropagation)神经网络,这是一种应用较广泛的前馈式网络,属于有监督分类算法,它将先验知识融于网络学习之中,加以最大限度地利用,适应性好,在类别数少的情况下能够得到相当高的精度,但是其网络的学习主要采用误差修正算法,识别对象种类多时,随着网络规模的扩大,需要的计算过程较长,收敛缓慢而不稳定,且识别精度难以达到要求。
(2)Hopfield神经网络。属于反馈式网络。主要采用Hebb规则进行学习,一般情况下计算的收敛速度较快。
这种网络是美国物理学家J.J.Hopfield于1982年首先提出的,它主要用于模拟生物神经网络的记忆机理。
Hopfield神经网络状态的演变过程是一个非线性动力学系统,可以用一组非线性差分方程来描述。
系统的稳定性可用所谓的“能量函数”进行分析,在满足一定条件下,某种“能量函数”的能量在网络运行过程中不断地减少,最后趋于稳定的平衡状态。
Hopfield网络的演变过程是一种计算联想记忆或求解优化问题的过程。(3)Kohonen网络。
这是一种由芬兰赫尔辛基大学神经网络专家Kohonen(1981)提出的自组织神经网络,其采用了无导师信息的学习算法,这种学习算法仅根据输入数据的属性而调整权值,进而完成向环境学习、自动分类和聚类等任务。
其最大的优点是最终的各个相邻聚类之间是有相似关系的,即使识别时把样本映射到了一个错误的节点,它也倾向于被识别成同一个因素或者一个相近的因素,这就十分接近人的识别特性。
神经网络算法原理
4.2.1概述人工神经网络的研究与计算机的研究几乎是同步发展的。
1943年心理学家McCulloch和数学家Pitts合作提出了形式神经元的数学模型,20世纪50年代末,Rosenblatt提出了感知器模型,1982年,Hopfiled引入了能量函数的概念提出了神经网络的一种数学模型,1986年,Rumelhart及LeCun等学者提出了多层感知器的反向传播算法等。
神经网络技术在众多研究者的努力下,理论上日趋完善,算法种类不断增加。目前,有关神经网络的理论研究成果很多,出版了不少有关基础理论的著作,并且现在仍是全球非线性科学研究的热点之一。
神经网络是一种通过模拟人的大脑神经结构去实现人脑智能活动功能的信息处理系统,它具有人脑的基本功能,但又不是人脑的真实写照。它是人脑的一种抽象、简化和模拟模型,故称之为人工神经网络(边肇祺,2000)。
人工神经元是神经网络的节点,是神经网络的最重要组成部分之一。目前,有关神经元的模型种类繁多,最常用最简单的模型是由阈值函数、Sigmoid函数构成的模型(图4-3)。
图4-3人工神经元与两种常见的输出函数神经网络学习及识别方法最初是借鉴人脑神经元的学习识别过程提出的。
输入参数好比神经元接收信号,通过一定的权值(相当于刺激神经兴奋的强度)与神经元相连,这一过程有些类似于多元线性回归,但模拟的非线性特征是通过下一步骤体现的,即通过设定一阈值(神经元兴奋极限)来确定神经元的兴奋模式,经输出运算得到输出结果。
经过大量样本进入网络系统学习训练之后,连接输入信号与神经元之间的权值达到稳定并可最大限度地符合已经经过训练的学习样本。
在被确认网络结构的合理性和学习效果的高精度之后,将待预测样本输入参数代入网络,达到参数预测的目的。
4.2.2反向传播算法(BP法)发展到目前为止,神经网络模型不下十几种,如前馈神经网络、感知器、Hopfiled网络、径向基函数网络、反向传播算法(BP法)等,但在储层参数反演方面,目前比较成熟比较流行的网络类型是误差反向传播神经网络(BP-ANN)。
BP网络是在前馈神经网络的基础上发展起来的,始终有一个输入层(它包含的节点对应于每个输入变量)和一个输出层(它包含的节点对应于每个输出值),以及至少有一个具有任意节点数的隐含层(又称中间层)。
在BP-ANN中,相邻层的节点通过一个任意初始权值全部相连,但同一层内各节点间互不相连。
对于BP-ANN,隐含层和输出层节点的基函数必须是连续的、单调递增的,当输入趋于正或负无穷大时,它应该接近于某一固定值,也就是说,基函数为“S”型(Kosko,1992)。
BP-ANN的训练是一个监督学习过程,涉及两个数据集,即训练数据集和监督数据集。
给网络的输入层提供一组输入信息,使其通过网络而在输出层上产生逼近期望输出的过程,称之为网络的学习,或称对网络进行训练,实现这一步骤的方法则称为学习算法。
BP网络的学习过程包括两个阶段:第一个阶段是正向过程,将输入变量通过输入层经隐层逐层计算各单元的输出值;第二阶段是反向传播过程,由输出误差逐层向前算出隐层各单元的误差,并用此误差修正前层权值。
误差信息通过网络反向传播,遵循误差逐步降低的原则来调整权值,直到达到满意的输出为止。
网络经过学习以后,一组合适的、稳定的权值连接权被固定下来,将待预测样本作为输入层参数,网络经过向前传播便可以得到输出结果,这就是网络的预测。
反向传播算法主要步骤如下:首先选定权系数初始值,然后重复下述过程直至收敛(对各样本依次计算)。
(1)从前向后各层计算各单元Oj储层特征研究与预测(2)对输出层计算δj储层特征研究与预测(3)从后向前计算各隐层δj储层特征研究与预测(4)计算并保存各权值修正量储层特征研究与预测(5)修正权值储层特征研究与预测以上算法是对每个样本作权值修正,也可以对各个样本计算δj后求和,按总误差修正权值。
数据挖掘的常用方法都有哪些?
在数据分析中,数据挖掘工作是一个十分重要的工作,可以说,数据挖掘工作占据数据分析工作的时间将近一半,由此可见数据挖掘的重要性,要想做好数据挖掘工作需要掌握一些方法,那么数据挖掘的常用方法都有哪些呢?
下面就由小编为大家解答一下这个问题。首先给大家说一下神经网络方法。
神经网络是模拟人类的形象直觉思维,在生物神经网络研究的基础上,根据生物神经元和神经网络的特点,通过简化、归纳、提炼总结出来的一类并行处理网络,利用其非线性映射的思想和并行处理的方法,用神经网络本身结构来表达输入和输出的关联知识。
神经网络方法在数据挖掘中十分常见。然后给大家说一下粗糙集方法。粗糙集理论是一种研究不精确、不确定知识的数学工具。粗糙集处理的对象是类似二维关系表的信息表。
目前成熟的关系数据库管理系统和新发展起来的数据仓库管理系统,为粗糙集的数据挖掘奠定了坚实的基础。粗糙集理论能够在缺少先验知识的情况下,对数据进行分类处理。
在该方法中知识是以信息系统的形式表示的,先对信息系统进行归约,再从经过归约后的知识库抽取得到更有价值、更准确的一系列规则。
因此,基于粗糙集的数据挖掘算法实际上就是对大量数据构成的信息系统进行约简,得到一种属性归约集的过程,最后抽取规则。而决策树方法也是数据挖掘的常用方法之一。
决策树是一种常用于预测模型的算法,它通过一系列规则将大量数据有目的分类,从中找到一些有价值的、潜在的信息。
它的主要优点是描述简单,分类速度快,易于理解、精度较高,特别适合大规模的数据处理,在知识发现系统中应用较广。它的主要缺点是很难基于多个变量组合发现规则。在数据挖掘中,决策树常用于分类。
最后给大家说的是遗传算法。遗传算法是一种基于生物自然选择与遗传机理的随机搜索算法。数据挖掘是从大量数据中提取人们感兴趣的知识,这些知识是隐含的、事先未知的、潜在有用的信息。
因此,许多数据挖掘问题可以看成是搜索问题,数据库或者数据仓库为搜索空间,挖掘算法是搜索策略。
上述的内容就是我们为大家讲解的数据挖掘工作中常用的方法了,数据挖掘工作常用的方法就是神经网络方法、粗糙集方法、决策树方法、遗传算法,掌握了这些方法才能够做好数据挖掘工作。
神经网络模型有几种分类方法,试给出一种分类
神经网络模型的分类人工神经网络的模型很多,可以按照不同的方法进行分类。其中,常见的两种分类方法是,按照网络连接的拓朴结构分类和按照网络内部的信息流向分类。
1按照网络拓朴结构分类网络的拓朴结构,即神经元之间的连接方式。按此划分,可将神经网络结构分为两大类:层次型结构和互联型结构。
层次型结构的神经网络将神经元按功能和顺序的不同分为输出层、中间层(隐层)、输出层。输出层各神经元负责接收来自外界的输入信息,并传给中间各隐层神经元;隐层是神经网络的内部信息处理层,负责信息变换。
根据需要可设计为一层或多层;最后一个隐层将信息传递给输出层神经元经进一步处理后向外界输出信息处理结果。
而互连型网络结构中,任意两个节点之间都可能存在连接路径,因此可以根据网络中节点的连接程度将互连型网络细分为三种情况:全互连型、局部互连型和稀疏连接型2按照网络信息流向分类从神经网络内部信息传递方向来看,可以分为两种类型:前馈型网络和反馈型网络。
单纯前馈网络的结构与分层网络结构相同,前馈是因网络信息处理的方向是从输入层到各隐层再到输出层逐层进行而得名的。
前馈型网络中前一层的输出是下一层的输入,信息的处理具有逐层传递进行的方向性,一般不存在反馈环路。因此这类网络很容易串联起来建立多层前馈网络。反馈型网络的结构与单层全互连结构网络相同。
在反馈型网络中的所有节点都具有信息处理功能,而且每个节点既可以从外界接受输入,同时又可以向外界输出。
rbf神经网络用哪种学习算法好
RBF网络的设计包括结构设计和参数设计。结构设计主要解决如何确定网络隐节点数的问题。参数设计一般需考虑包括3种参数:各基函数的数据中心和扩展常数,以及输出节点的权值。
当采用FullRBF网络结构时,隐节点数即样本数,基函数的数据中心即为样本本身,参数设计只需考虑扩展常数和输出节点的权值。
当采用广义RBF网络结构时,RBF网络的学习算法应该解决的问题包括:如何确定网络隐节点数,如何确定各径向基函数的数据中心及扩展常数,以及如何修正输出权值。
根据数据中心的取值方法,RBF网的设计方法可分为两类。第一类方法:数据中心从样本输入中选取。
一般来说,样本密集的地方中心点可以适当多些,样本稀疏的地方中心点可以少些;若数据本身是均匀分布的,中心点也可以均匀分布。总之,选出的数据中心应具有代表性。
径向基函数的扩展常数是根据数据中心的散布而确定的,为了避免每个径向基函数太尖或太平,一种选择方法是将所有径向基函数的扩展常数设为:max(d)/sqrt(2M),M为数据中心点数,max(d)为所选数据中心之间的最大距离。
第二类方法:数据中心的自组织选择。常采用各种动态聚类算法对数据中心进行自组织选择,在学习过程中需对数据中心的位置进行动态调节。
常用的方法是K-means聚类,其优点是能根据各聚类中心之间的距离确定各隐节点的扩展常数。
由于RBF网的隐节点数对其泛化能力有极大的影响,所以寻找能确定聚类数目的合理方法,是聚类方法设计RBF网时需首先解决的问题。除聚类算法外还有梯度训练方法资源分配网络RAN等。
目前进行图像处理,通常使用什么神经网络
模糊神经网络的基本形式
模糊神经网络有如下三种形式:1.逻辑模糊神经网络2.算术模糊神经网络3.混合模糊神经网络模糊神经网络就是具有模糊权系数或者输入信号是模糊量的神经网络。上面三种形式的模糊神经网络中所执行的运算方法不同。
模糊神经网络无论作为逼近器,还是模式存储器,都是需要学习和优化权系数的。学习算法是模糊神经网络优化权系数的关键。对于逻辑模糊神经网络,可采用基于误差的学习算法,也即是监视学习算法。
对于算术模糊神经网络,则有模糊BP算法,遗传算法等。对于混合模糊神经网络,目前尚未有合理的算法;不过,混合模糊神经网络一般是用于计算而不是用于学习的,它不必一定学习。