这样去做信用贷款违约预测项目,效果提升明显
项目背景:比赛由 Kaggle 举办,要求选手依据客户的信用卡信息(application)、信用局信息(bureau)、历史申请信息(previous_application)分期付款信息(installments_payments)等7个主、副数据集来预测客户贷款是否会违约。
分析流程:
- 首先对数据进行预览和可视化探索,理解各个属性,查看数据集中的缺失值和异常值并进行相应地处理;
- 其次对违约用户和非违约用户的属性分布进行可视化分析,探索差异点;
- 接着通过用户属性可视化分析和业务理解构造相应特征工程,从用户个人基本属性和用户行为两个角度来刻画违约用户画像;
- 最后进行建模预测;
文章目录
-
- 技术提升
- 一、特征理解:主训练集里有什么?
-
- 1.1、数据概览
- 1.2 缺失值与异常值
-
- 1.2.1 缺失值处理
- 1.2.2 异常值处理
- 二、探索性数据分析
-
- 2.1 用户性别特征探索
- 2.2 用户年龄年龄特征探索
- 2.3 贷款类型特征探索
- 2.4 家庭有无房/车特征探索
- 2.5 家庭角色特色探索
- 2.6 家庭子女数量特征探索
- 2.7 用户收入特征探索
- 2.8 用户职业特征探索
- 2.9 用户教育水平特征探索
- 三、特征工程1:主训练集中新特征构建
- 四、建模预测计算基准性能
- 五、特征工程2:辅助信息集中引入新特征
-
- 5.1 信息局数据集信息探索
- 5.2 辅助数据集上自定义连续型和离散型变量特征提取函数
-
-
- 5.2.1 自定义连续型变量特征提取函数
- 5.2.2 自定义离散型变量特征提取函数
-
- 5.3 整合所有数据集,创建新特征
- 六、特征选择
- 七、建模预测
技术提升
项目代码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
一、特征理解:主训练集里有什么?

1.1、数据概览
Step1:加载相关数据分析库。
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
color = sns.color_palette()
import plotly.offline as py
py.init_notebook_mode(connected=True)
from plotly.offline import init_notebook_mode, iplot
init_notebook_mode(connected=True)
import plotly.graph_objs as go
import pandas as pd
import plotly.offline as offline
offline.init_notebook_mode()
import cufflinks as cf
cf.go_offline()
plt.style.use('fivethirtyeight')
Step2:加载主训练集和测试集数据。
app_train=pd.read_csv('.../信用风险数据集/application_train.csv')
app_test =pd.read_csv('.../信用风险数据集/application_test.csv')
Step3:输入主训练集前5行,查看其属性、数据量等基本信息。
app_train.head()

主训练集中一共有122个属性,其每一行的含义是客户正在申请中的一笔贷款, 唯一主键是SK_ID_CURR,字段的含义可以参考数据文件(HomeCredit_columns_description.csv)中的列名含义描述。
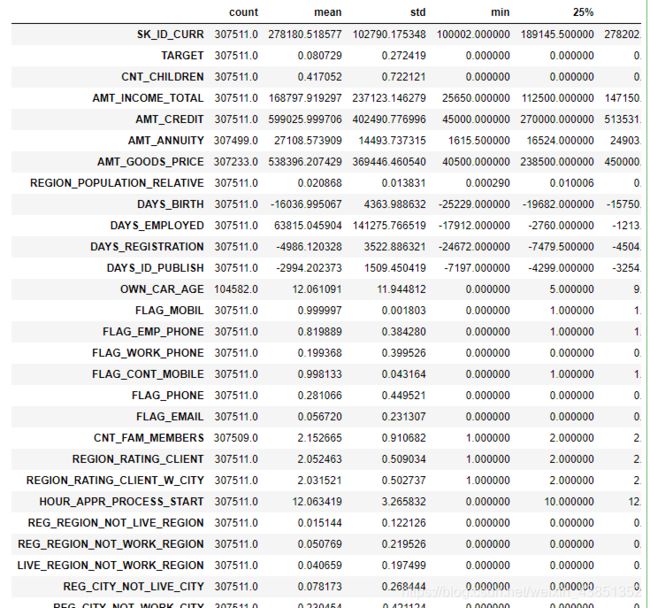
Step4:数据集统计学描述。
app_train.describe().T
1.2 缺失值与异常值
1.2.1 缺失值处理
目的:了解数据的缺失值和异常值情况,以便做对应的数据清洗来提高数据质量。
Step5:通过自定义缺失值查看函数,来查看数据集中的缺失值。
def missing_values_table(df):
mis_val = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum() / len(df)
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
print ("数据集一共有 " + str(df.shape[1]) + "行。\n"
"有 " + str(mis_val_table_ren_columns.shape[0]) +
" 行存在缺失值。")
return mis_val_table_ren_columns
missing_values = missing_values_table(app_train)
missing_values.head(20)

数据一共有122列,但是有67列存在缺失情况,最高缺失值的列缺失率高达为69.9%。 一般对于缺失值的处理有三种方法:
- 一是可以采用 LightGBM这种能够自动处理缺失值的模型,这样就无需处理缺失值;
- 二是可以进行填补,主要利用属性的平均值、众数、中位数、固定值以及利用已知值预测缺失值来填充;
- 三是可以对缺失值较高的列直接删除;
特别注意的是,前面的几列属性的缺失率的都是相同的,并且它们都是属于房屋相关的特征。因此,根据这个规律可以做出假设:用户缺失房屋信息可能是因为某种特定原因导致的,而不是随机缺失,可以考虑在特征工程时利用该假设来构架新特征。
1.2.2 异常值处理
Step6:利用描述统计的方法,即查看特征的均值、极大值、极小值等信息,结合常识来判断是否存在异常值。
- 查看用户年龄的数据分布情况
(app_train['DAYS_BIRTH'] / -365).describe()
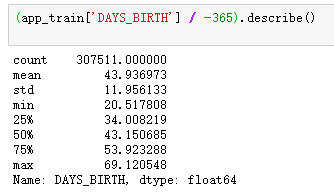
根据用户年龄的数据统计描述分布情况,年龄值是负数,反映的是申请贷款前,这个用户活了多少天,所以这里除以负365天以得到用户的实际年龄。发现数据的分布比较正常的,最大年龄69岁,最小年龄20岁,没有很异常的数值出现。
- 查看用户的工作时间分布情况发现
(app_train['DAYS_EMPLOYED']/-365).describe()
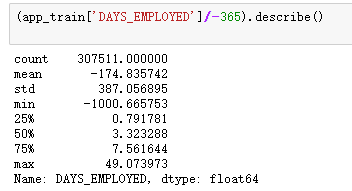
通过查看用户的工作时间分布情况发现:工作时间也是负数,也除以负365天。结果得到最小值是-1000年。这里的-1000年明显是一个异常数据,因为根据常识没有人的工作时间是负数的,这可能是个异常值。
app_train['DAYS_EMPLOYED'].plot.hist(title = 'Days Employment Histogram');
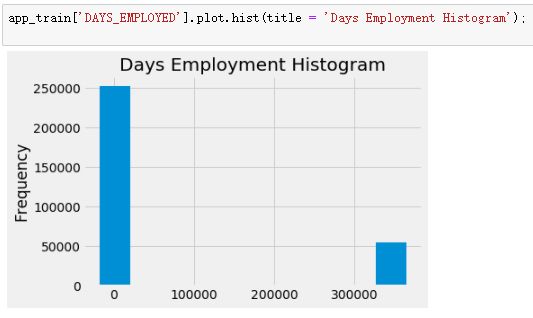
做出用户的工作时间的数据直方图,发现所有的异常值都是一个值,365243,对于这个异常值可能是代表缺失值。因此,将这个异常值用空值去替换,这样即可以保留这个信息,又抹去了异常值,替换之后再次看工作时间的分布情况,此时数据分布正常了很多。
app_train['DAYS_EMPLOYED'].replace({365243: np.nan}, inplace = True)
(app_train['DAYS_EMPLOYED']/-365).plot.hist(title = 'Days Employment Histogram');
plt.xlabel('Days Employment');

二、探索性数据分析
Step7:探索性数据分析。此环节的目标主要是分析违约用户和非违约用户的特征分布情况,对违约用户的画像建立一个基本的了解,为后续特征工程打下基础。
比如数据集里面有性别、年龄、工作时间等属性,那么就性别而言,男性更容易违约还是女性更容易违约呢?对于年龄而言,是年龄大的人更容易违约还是年龄小的人?教育水平、家庭情况等这些用户基本属性数据探索。
为了后续通过可视化违约用户和非违约用户的特征分布情况,现自定义一个做图函数,方便后期调用。
def plot_stats(feature,label_rotation=False,horizontal_layout=True):
temp = app_train[feature].value_counts()
df1 = pd.DataFrame({feature: temp.index,'Number of contracts': temp.values})
cat_perc = app_train[[feature, 'TARGET']].groupby([feature],as_index=False).mean()
cat_perc.sort_values(by='TARGET', ascending=False, inplace=True)
if(horizontal_layout):
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
else:
fig, (ax1, ax2) = plt.subplots(nrows=2, figsize=(12,14))
sns.set_color_codes("pastel")
s = sns.barplot(ax=ax1, x = feature, y="Number of contracts",data=df1)
if(label_rotation):
s.set_xticklabels(s.get_xticklabels(),rotation=90)
s = sns.barplot(ax=ax2, x = feature, y='TARGET', order=cat_perc[feature], data=cat_perc)
if(label_rotation):
s.set_xticklabels(s.get_xticklabels(),rotation=90)
plt.ylabel('Percent of target with value 1 [%]', fontsize=10)
plt.tick_params(axis='both', which='major', labelsize=10)
plt.show();
def plot_distribution(var):
i = 0
t1 = app_train.loc[app_train['TARGET'] != 0]
t0 = app_train.loc[app_train['TARGET'] == 0]
sns.set_style('whitegrid')
plt.figure()
fig, ax = plt.subplots(2,2,figsize=(12,12))
for feature in var:
i += 1
plt.subplot(2,2,i)
sns.kdeplot(t1[feature], bw=0.5,label="TARGET = 1")
sns.kdeplot(t0[feature], bw=0.5,label="TARGET = 0")
plt.ylabel('Density plot', fontsize=12)
plt.xlabel(feature, fontsize=12)
locs, labels = plt.xticks()
plt.tick_params(axis='both', which='major', labelsize=12)
plt.show();
2.1 用户性别特征探索
- 查看男性和女性用户的违约率情况。
plot_stats('CODE_GENDER')
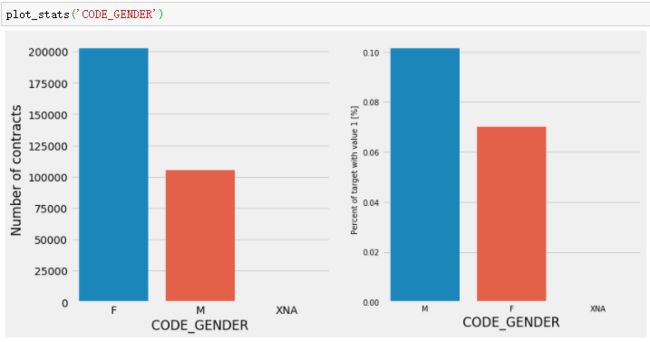
通过上图发现,男性用户违约率更高,男性用户违约率为10%,女性为7%。
2.2 用户年龄年龄特征探索
- 查看违约用户和正常用户的年龄分布对违约率的影响情况。
plt.figure(figsize = (10, 8))
sns.kdeplot(app_train.loc[app_train['TARGET'] == 0, 'DAYS_BIRTH'] / -365, label = 'target == 0')
sns.kdeplot(app_train.loc[app_train['TARGET'] == 1, 'DAYS_BIRTH'] / -365, label = 'target == 1')
plt.xlabel('Age (years)'); plt.ylabel('Density'); plt.title('Distribution of Ages');
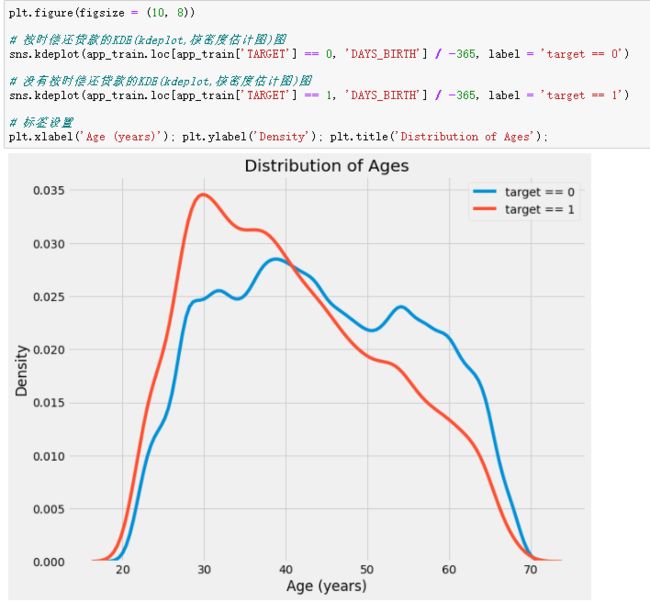
因为年龄是连续型变量,和性别不同,所以可以使用分布图去看年龄的分布情况,通过数据分布可以看到,违约用户年轻用户分布更多,所以可以假设用户年龄越小,违约的可能性越大。
- 接下来来验证上述“用户年龄越小,违约的可能性越大”这个假设。
age_data = app_train[['TARGET', 'DAYS_BIRTH']]
age_data['YEARS_BIRTH'] = age_data['DAYS_BIRTH'] / -365
age_data['YEARS_BINNED'] = pd.cut(age_data['YEARS_BIRTH'], bins = np.linspace(20, 70, num = 11))
age_groups = age_data.groupby('YEARS_BINNED').mean()
plt.figure(figsize = (8, 8))
plt.bar(age_groups.index.astype(str), 100 * age_groups['TARGET'])
plt.xticks(rotation = 75); plt.xlabel('Age Group (years)'); plt.ylabel('Failure to Repay (%)')
plt.title('Failure to Repay by Age Group');
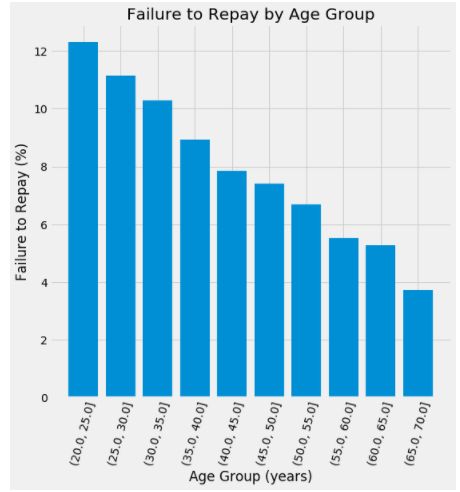
通过对用户的年龄进行分捅,进一步观察不同年龄段用户的违约概率。发现确实是用户年龄越小,违约的可能性越高。
2.3 贷款类型特征探索
- 查看不同贷款类型的违约率情况。
plot_stats('NAME_CONTRACT_TYPE')

通过上图发现,对于现金贷款和流动资金循坏贷款,现金贷款的违约率更高。
2.4 家庭有无房/车特征探索
- 查看用户有没有房和车对违约率的影响。
plot_stats('FLAG_OWN_CAR')
plot_stats('FLAG_OWN_REALTY')

通过上图发现,没有车和房的人违约率更高,但相差并不大。
2.5 家庭角色特色探索
- 家庭角色对违约率的影响情况。
plot_stats('NAME_FAMILY_STATUS',True, True)

通过上图发现,申请的用户大多已经结婚,单身和民事婚姻的用户违约率较高,寡居的违约率最低。
注:civil marriage:民事婚姻,世俗结婚(不采用宗教仪式);
2.6 家庭子女数量特征探索
- 查看家庭子女对违约率的影响情况。
plot_stats('CNT_CHILDREN')
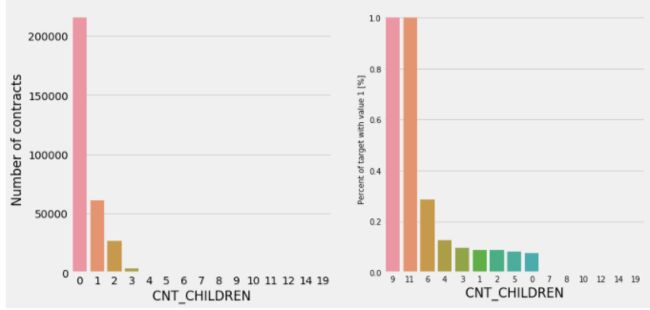
通过上图发现,大部分申请者没有孩子或孩子在3个以下,孩子越多的家庭违约率越高,发现对于有9、11个孩子的家庭违约率达到了100%(这点于该类型样本数量少也有一定的关系)。
2.7 用户收入特征探索
- 查看用户的收入类型对违约率的影响情况。
plot_stats('NAME_INCOME_TYPE',False,False)

通过上图发现,休产假和失业用户违约率较高,超过35%,对于这两类人群放款需较为谨慎。
2.8 用户职业特征探索
- 查看不同的职业对违约率的影响情况。
plot_stats('OCCUPATION_TYPE',True, False)

通过上图发现,从职业来看,越相对收入较低、不稳定的职业违约率越高,比如低廉劳动力、司机、理发师,而像会计、高科技员工、管理层等具有稳定高收入的职业违约率较低。
2.9 用户教育水平特征探索
- 查看用户的教育水平对违约率的影响情况。
plot_stats('NAME_EDUCATION_TYPE',True)

通过上图发现,贷款申请人受教育程度大多为中学,学历越低越容易违约。
三、特征工程1:主训练集中新特征构建
Step7:基于第二部分对违约用户和非违约用户的基本属性特征探索性分析,现利用主训练集属性结合对业务的理解,构造如下新特征。
- CREDIT_INCOME_PERCENT: 贷款金额/客户收入,猜测该比值越大,说明贷款金额大于用户的收入,用户违约的可能性就越大;
- ANNUITY_INCOME_PERCENT: 贷款的每年还款金额/客户收入,猜测该比值越大,说明每年的还款金额大于用户的收入,用户违约的可能性就越大;
- CREDIT_TERM: 贷款的每年还款金额/贷款金额,即贷款的还款周期,猜测还款周期短的贷款,用户的短期压力可能会比较大,违约概率高;
- DAYS_EMPLOYED_PERCENT: 用户工作时间/用户年龄;
- INCOME_PER_CHILD:用户收入/孩子数量,即用户收入平均到每个孩子身上,同样的收入,猜测如果该用户的家庭人数较多,孩子很多,则负担可能比较重,违约的可能性可能更高;
- HAS_HOUSE_INFORMATION:根据客户是否有缺失房屋信息设计一个二分类特征,如果未缺失的话是1,缺失的是0;
app_train_domain = app_train.copy()
app_test_domain = app_test.copy()
app_train_domain['CREDIT_INCOME_PERCENT'] = app_train_domain['AMT_CREDIT'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['ANNUITY_INCOME_PERCENT'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_INCOME_TOTAL']
app_train_domain['CREDIT_TERM'] = app_train_domain['AMT_ANNUITY'] / app_train_domain['AMT_CREDIT']
app_train_domain['DAYS_EMPLOYED_PERCENT'] = app_train_domain['DAYS_EMPLOYED'] / app_train_domain['DAYS_BIRTH']
app_train_domain['INCOME_PER_CHILD'] = app_train_domain['AMT_INCOME_TOTAL'] / app_train_domain['CNT_CHILDREN']
app_train_domain['HAS_HOUSE_INFORMATION'] = app_train_domain['COMMONAREA_MEDI'].apply(lambda x:1 if x>0 else 0)
plt.figure(figsize = (12, 20))
for i, feature in enumerate(['CREDIT_INCOME_PERCENT', 'ANNUITY_INCOME_PERCENT', 'CREDIT_TERM', 'DAYS_EMPLOYED_PERCENT','INCOME_PER_CHILD']):
plt.subplot(5, 1, i + 1)
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 0, feature], label = 'target == 0')
sns.kdeplot(app_train_domain.loc[app_train_domain['TARGET'] == 1, feature], label = 'target == 1')
plt.title('Distribution of %s by Target Value' % feature)
plt.xlabel('%s' % feature); plt.ylabel('Density');
plt.tight_layout(h_pad = 2.5)
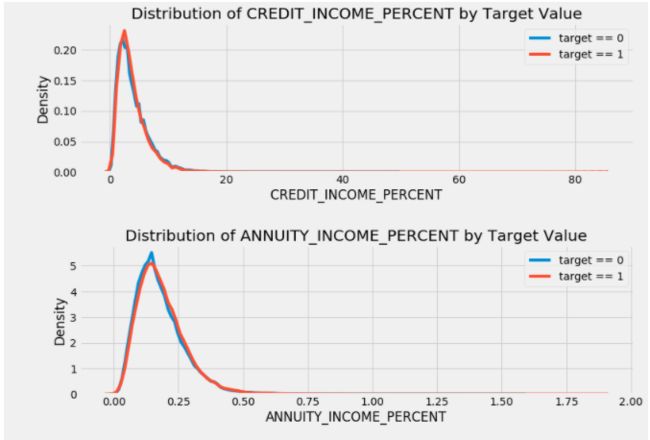
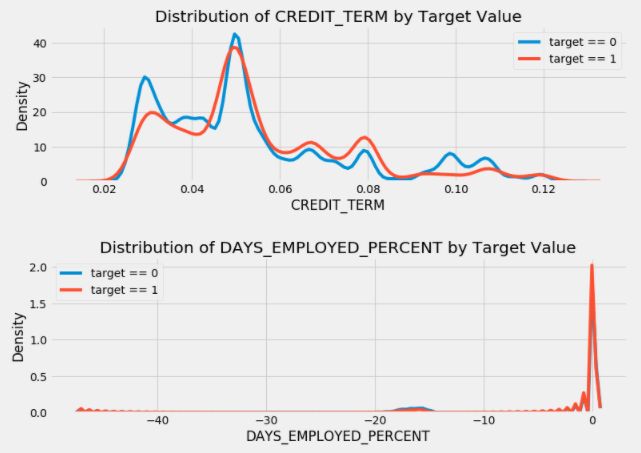
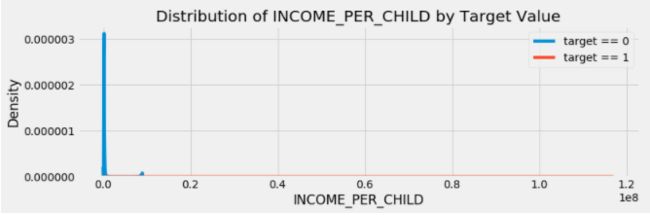 查看上述设计出来的前5个连续性特征在违约用户和非违约用户中的分布情况,可以发现除CREDIT_TERM这个特征外,其他的特征区分度似乎都不是很明显。
查看上述设计出来的前5个连续性特征在违约用户和非违约用户中的分布情况,可以发现除CREDIT_TERM这个特征外,其他的特征区分度似乎都不是很明显。
接下来自定义函数,验证房屋缺失值而设计的特征的效果。
def plot_stats(feature,label_rotation=False,horizontal_layout=True):
temp = app_train_domain[feature].value_counts()
df1 = pd.DataFrame({feature: temp.index,'Number of contracts': temp.values})
cat_perc = app_train_domain[[feature, 'TARGET']].groupby([feature],as_index=False).mean()
cat_perc.sort_values(by='TARGET', ascending=False, inplace=True)
if(horizontal_layout):
fig, (ax1, ax2) = plt.subplots(ncols=2, figsize=(12,6))
else:
fig, (ax1, ax2) = plt.subplots(nrows=2, figsize=(12,14))
sns.set_color_codes("pastel")
s = sns.barplot(ax=ax1, x = feature, y="Number of contracts",data=df1)
if(label_rotation):
s.set_xticklabels(s.get_xticklabels(),rotation=90)
s = sns.barplot(ax=ax2, x = feature, y='TARGET', order=cat_perc[feature], data=cat_perc)
if(label_rotation):
s.set_xticklabels(s.get_xticklabels(),rotation=90)
plt.ylabel('Percent of target with value 1 [%]', fontsize=10)
plt.tick_params(axis='both', which='major', labelsize=10)
plt.show();
plot_stats('HAS_HOUSE_INFORMATION',True)

通过上图,缺失房屋信息的用户违约概率要明显高于未缺失用户。
对主训练集的测试集也做同样构造新特征的处理。
app_test_domain['CREDIT_INCOME_PERCENT'] = app_test_domain['AMT_CREDIT'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['ANNUITY_INCOME_PERCENT'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_INCOME_TOTAL']
app_test_domain['CREDIT_TERM'] = app_test_domain['AMT_ANNUITY'] / app_test_domain['AMT_CREDIT']
app_test_domain['DAYS_EMPLOYED_PERCENT'] = app_test_domain['DAYS_EMPLOYED'] / app_test_domain['DAYS_BIRTH']
app_test_domain['INCOME_PER_CHILD'] = app_test_domain['AMT_INCOME_TOTAL'] / app_test_domain['CNT_CHILDREN']
app_test_domain['HAS_HOUSE_INFORMATION'] = app_test_domain['COMMONAREA_MEDI'].apply(lambda x:1 if x>0 else 0)
四、建模预测计算基准性能
Step8:在主训练集,利用LightGBM模型进行建模预测,得到模型基准性能。
- 导入相关库
from sklearn.model_selection import KFold
from sklearn.metrics import roc_auc_score
import lightgbm as lgb
import gc
- 自定义训练模型、预测模型函数。
其中,输入是训练集特征、测试集特征、编码方式以及交叉验证次数;输出为测试文件、重要特征以及性能指标。
def model(features, test_features, encoding = 'ohe', n_folds = 5):
train_ids = features['SK_ID_CURR']
test_ids = test_features['SK_ID_CURR']
labels = features['TARGET']
features = features.drop(columns = ['SK_ID_CURR', 'TARGET'])
test_features = test_features.drop(columns = ['SK_ID_CURR'])
if encoding == 'ohe':
features = pd.get_dummies(features)
test_features = pd.get_dummies(test_features)
features, test_features = features.align(test_features, join = 'inner', axis = 1)
cat_indices = 'auto'
elif encoding == 'le':
label_encoder = LabelEncoder()
cat_indices = []
for i, col in enumerate(features):
if features[col].dtype == 'object':
features[col] = label_encoder.fit_transform(np.array(features[col].astype(str)).reshape((-1,)))
test_features[col] = label_encoder.transform(np.array(test_features[col].astype(str)).reshape((-1,)))
cat_indices.append(i)
else:
raise ValueError("Encoding must be either 'ohe' or 'le'")
print('Training Data Shape: ', features.shape)
print('Testing Data Shape: ', test_features.shape)
feature_names = list(features.columns)
features = np.array(features)
test_features = np.array(test_features)
k_fold = KFold(n_splits = n_folds, shuffle = True, random_state = 50)
feature_importance_values = np.zeros(len(feature_names))
test_predictions = np.zeros(test_features.shape[0])
out_of_fold = np.zeros(features.shape[0])
valid_scores = []
train_scores = []
for train_indices, valid_indices in k_fold.split(features):
train_features, train_labels = features[train_indices], labels[train_indices]
valid_features, valid_labels = features[valid_indices], labels[valid_indices]
model = lgb.LGBMClassifier(n_estimators=1000, objective = 'binary',
class_weight = 'balanced', learning_rate = 0.05,
reg_alpha = 0.1, reg_lambda = 0.1,
subsample = 0.8, n_jobs = -1, random_state = 50)
model.fit(train_features, train_labels, eval_metric = 'auc',
eval_set = [(valid_features, valid_labels), (train_features, train_labels)],
eval_names = ['valid', 'train'], categorical_feature = cat_indices,
early_stopping_rounds = 100, verbose = 200)
best_iteration = model.best_iteration_
feature_importance_values += model.feature_importances_ / k_fold.n_splits
test_predictions += model.predict_proba(test_features, num_iteration = best_iteration)[:, 1] / k_fold.n_splits
out_of_fold[valid_indices] = model.predict_proba(valid_features, num_iteration = best_iteration)[:, 1]
valid_score = model.best_score_['valid']['auc']
train_score = model.best_score_['train']['auc']
valid_scores.append(valid_score)
train_scores.append(train_score)
gc.enable()
del model, train_features, valid_features
gc.collect()
submission = pd.DataFrame({'SK_ID_CURR': test_ids, 'TARGET': test_predictions})
feature_importances = pd.DataFrame({'feature': feature_names, 'importance': feature_importance_values})
valid_auc = roc_auc_score(labels, out_of_fold)
valid_scores.append(valid_auc)
train_scores.append(np.mean(train_scores))
fold_names = list(range(n_folds))
fold_names.append('overall')
metrics = pd.DataFrame({'fold': fold_names,
'train': train_scores,
'valid': valid_scores})
return submission, feature_importances, metrics
- 利用自定义函数训练模型,并输出5折交叉验证的结果。
submission, fi, metrics = model(app_train_domain, app_test_domain)
print('Baseline metrics')
print(metrics)
submission.to_csv('my_submission1.csv',index=False)
del app_train_domain,app_test_domain
gc.collect

在主训练集,利用LightGBM模型进行建模预测,K折交叉验证得到模型在训练集上的AUC得分为 0.814328 ,在验证集上的AUC得分为0.766055。
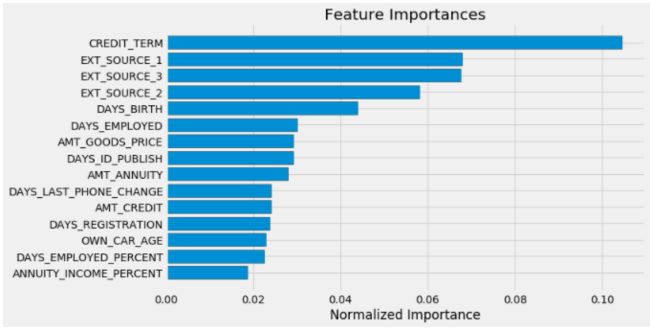
- 然后通过LightGBM自带的函数查看每个特征的重要性以及可视化每个特征的重要性。
def plot_feature_importances(df):
df = df.sort_values('importance', ascending = False).reset_index()
df['importance_normalized'] = df['importance'] / df['importance'].sum()
plt.figure(figsize = (10, 6))
ax = plt.subplot()
ax.barh(list(reversed(list(df.index[:15]))),
df['importance_normalized'].head(15),
align = 'center', edgecolor = 'k')
ax.set_yticks(list(reversed(list(df.index[:15]))))
ax.set_yticklabels(df['feature'].head(15))
plt.xlabel('Normalized Importance'); plt.title('Feature Importances')
plt.show()
return df
fi_sorted = plot_feature_importances(fi)
五、特征工程2:辅助信息集中引入新特征
Step9:在上述分析仅利用了主训练集和预测集来构建特征,接下来,把一些辅助训练集和主训练集通过对应的键进行关联,从辅助训练集中提取出一些有的价值信息,把将其作为新的特征加入主训练集中来构建新特征。
5.1 信息局数据集信息探索
- 信息局信息(bureau.csv)概述:该数据集中的每一行代表的是主训练集中的用户曾经在其他金融机构申请的贷款信息,该数据集与主训练集的连接键是“SK_ID_CURR’。一般辅助训练集和主训练集做left join即可。
bureau = pd.read_csv(' .../信用风险数据集/bureau.csv')
bureau.head()
-
但是,一个SK_ID_CURR可能会对应多个SK_ID_BUREAU,即一个用户如果在其他金融机构曾经有多条贷款信息的话,这里就会有多条记录(一对多),因为模型训练时每个用户在数据集中只能有一条记录,所以不能直接把辅助训练集去和主训练集join。
-
又根据常识,一个用户如果在其他金融机构曾经有多条贷款信息,数据集里就会有多条记录,则可以假设,一个用户在其他金融机构的历史贷款申请数越多,是不是可能说明这该用户的信用可能越好?因为其信用已经在其他金融机构那里被验证过,可信度会相对更高。
-
因此,接下来通过计算一些统计特征来即能避免“一对多”现象,又能构造新特征previous_loan_counts(之前贷款数量)。统计特征即统计上的一些常用计算,比如count、avg、min、max、median等。
previous_loan_counts = bureau.groupby('SK_ID_CURR', as_index=False)['SK_ID_BUREAU'].count().rename(columns = {'SK_ID_BUREAU': 'previous_loan_counts'})
previous_loan_counts.head()
- 然后将在bureau数据集上创建的新特征previous_loan_counts连接到主训练集上。
app_train = app_train.merge(previous_loan_counts, on = 'SK_ID_CURR', how = 'left')
app_train['previous_loan_counts'] = app_train['previous_loan_counts'].fillna(0)
app_train.head()
- 在做出新特征后,接下来需要检验新特征是否对预测有区分度,因为不是所有的新特征都是对预测起作用,并且一些没有用的特征加到数据集里反而会降低预测值。
print(app_train[app_train.TARGET==1]['previous_loan_counts'].describe())
print(app_train[app_train.TARGET==0]['previous_loan_counts'].describe())

由违约和非违约用户previous_loan_counts的统计属性发现,虽然非违约用户的平均贷款申请数量要略多于违约用户,但差异很小,所以其实很难判断这个特征对预测是否是有用的,因此可以尝试在做一些更多的特征。
- 自定义一个查看分布的函数,用于快速查看新的特征在违约用户和非违约用户中的分布情况。
def kde_target(var_name, df):
corr = df['TARGET'].corr(df[var_name])
avg_repaid = df.ix[df['TARGET'] == 0, var_name].median()
avg_not_repaid = df.ix[df['TARGET'] == 1, var_name].median()
plt.figure(figsize = (12, 6))
sns.kdeplot(df.ix[df['TARGET'] == 0, var_name], label = 'TARGET == 0')
sns.kdeplot(df.ix[df['TARGET'] == 1, var_name], label = 'TARGET == 1')
plt.xlabel(var_name); plt.ylabel('Density'); plt.title('%s Distribution' % var_name)
plt.legend();
print(' %s 和Target之间的相关系数是 %0.4f' % (var_name, corr))
print('未偿还贷款的中位数 = %0.4f' % avg_not_repaid)
print('已偿还贷款的中位数= %0.4f' % avg_repaid)
kde_target('previous_loan_counts', app_train)
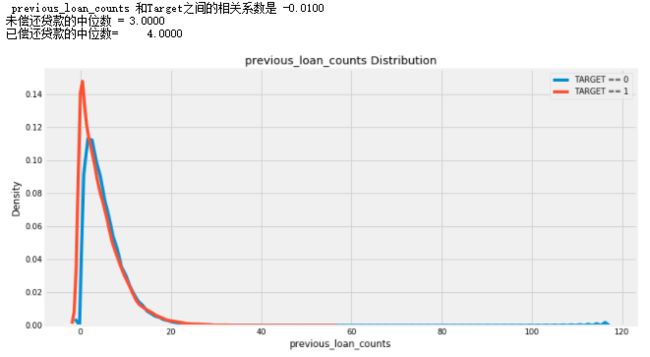
5.2 辅助数据集上自定义连续型和离散型变量特征提取函数
- 为了快速计算出辅助数据集上各类变量的特征,如以统计方法来描述连续型变量的特征以及计算其特征与Target的相关性;对于离散型变量先通过编码后再计算其统计特征。
5.2.1 自定义连续型变量特征提取函数
- 对于在辅助训练集上的连续型变量,首先计算其各属性统计值,其次重命名其属性列(表名+属性);其次与主训练集通过主键连接;再次,由于构造的特征数量较多,通过计算这些特征和目标值(Target)的相关性系数来做特征重要与否的快速判断;最后可视化未偿还贷款和已偿还贷款的新特征上的区分度。对于后两个步骤,可以在全部特征构建完后在特征选择时实现。
def agg_numeric(df, group_var, df_name):
for col in df:
if col != group_var and 'SK_ID' in col:
df = df.drop(columns = col)
group_ids = df[group_var]
numeric_df = df.select_dtypes('number')
numeric_df[group_var] = group_ids
agg = numeric_df.groupby(group_var).agg(['count', 'mean', 'max', 'min', 'sum']).reset_index()
columns = [group_var]
for var in agg.columns.levels[0]:
if var != group_var:
for stat in agg.columns.levels[1][:-1]:
columns.append('%s_%s_%s' % (df_name, var, stat))
agg.columns = columns
return agg
5.2.2 自定义离散型变量特征提取函数
- 对于在辅助训练集上的离散型变量,首先将定类、定序等定性变量编码,变成哑变量;其次计数后统计其属性中各类别的总量和占比;再次重命名其属性列(表名+属性);最后将构造的新特征连接到主训练集中,
自定义离散型变量特征提取函数
def count_categorical(df, group_var, df_name):
categorical = pd.get_dummies(df.select_dtypes('object'))
categorical[group_var] = df[group_var]
categorical = categorical.groupby(group_var).agg(['sum', 'mean'])
column_names = []
for var in categorical.columns.levels[0]:
for stat in ['count', 'count_norm']:
column_names.append('%s_%s_%s' % (df_name, var, stat))
categorical.columns = column_names
return categorical
5.3 整合所有数据集,创建新特征
通过以上定义的连续型变量特征提取和离散型变量特征提取的函数,下面把之前定义的函数应用到其他辅助数据集上。
- 重新读取数据集,把数据集还原到初始状态。
app_train=pd.read_csv('.../信用风险数据集/application_train.csv')
app_test = pd.read_csv('.../信用风险数据集/application_test.csv')
bureau = pd.read_csv('.../信用风险数据集/bureau.csv')
previous_application = pd.read_csv('./信用风险数据集/previous_application.csv')
POS_CASH_balance = pd.read_csv('.../信用风险数据集/POS_CASH_balance.csv')
credit_card_balance = pd.read_csv('.../信用风险数据集/credit_card_balance.csv')
- 把在主训练集上构造的新特征重新加入到数据集
app_train['CREDIT_INCOME_PERCENT'] = app_train['AMT_CREDIT'] / app_train['AMT_INCOME_TOTAL']
app_train['ANNUITY_INCOME_PERCENT'] = app_train['AMT_ANNUITY'] / app_train['AMT_INCOME_TOTAL']
app_train['CREDIT_TERM'] = app_train['AMT_ANNUITY'] / app_train['AMT_CREDIT']
app_train['DAYS_EMPLOYED_PERCENT'] = app_train['DAYS_EMPLOYED'] / app_train['DAYS_BIRTH']
app_train['INCOME_PER_CHILD'] = app_train['AMT_INCOME_TOTAL'] / app_train['CNT_CHILDREN']
app_train['HAS_HOUSE_INFORMATION'] = app_train['COMMONAREA_MEDI'].apply(lambda x:1 if x>0 else 0)
app_test['CREDIT_INCOME_PERCENT'] = app_test['AMT_CREDIT'] / app_test['AMT_INCOME_TOTAL']
app_test['ANNUITY_INCOME_PERCENT'] = app_test['AMT_ANNUITY'] / app_test['AMT_INCOME_TOTAL']
app_test['CREDIT_TERM'] = app_test['AMT_ANNUITY'] / app_test['AMT_CREDIT']
app_test['DAYS_EMPLOYED_PERCENT'] = app_test['DAYS_EMPLOYED'] / app_test['DAYS_BIRTH']
app_test['INCOME_PER_CHILD'] = app_test['AMT_INCOME_TOTAL'] / app_test['CNT_CHILDREN']
app_test['HAS_HOUSE_INFORMATION'] = app_test['COMMONAREA_MEDI'].apply(lambda x:1 if x>0 else 0)
- 通过自定义函数agg_numeric、count_categorical对信用局数据中连续变量和离散变量的特征提取。
bureau_counts = count_categorical(bureau, group_var = 'SK_ID_CURR', df_name = 'bureau')
bureau_agg_new = agg_numeric(bureau, group_var = 'SK_ID_CURR', df_name = 'bureau')
bureau_agg_new.head()
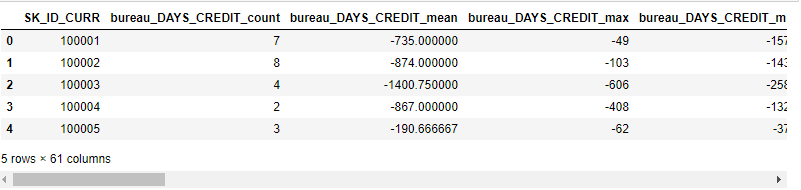
- 将信用局相关特征连接到主训练集和测试集上。
app_train = app_train.merge(bureau_counts, on = 'SK_ID_CURR', how = 'left')
app_train = app_train.merge(bureau_agg_new, on = 'SK_ID_CURR', how = 'left')
app_test = app_test.merge(bureau_counts, on = 'SK_ID_CURR', how = 'left')
app_test = app_test.merge(bureau_agg_new, on = 'SK_ID_CURR', how = 'left')
print(app_train.shape)
print(app_test.shape)
+ 此时,训练集特征数目已增加至234个。
- 通过自定义函数agg_numeric、count_categorical对历史贷款信息数据中连续变量和离散变量的特征提取。
previous_appication_counts = count_categorical(previous_application, group_var = 'SK_ID_CURR', df_name = 'previous_application')
previous_appication_agg_new = agg_numeric(previous_application, group_var = 'SK_ID_CURR', df_name = 'previous_application')
previous_appication_agg_new.head()

- 将历史贷款信息数据中相关特征连接到主训练集和测试集上。
app_train = app_train.merge(previous_appication_counts, on = 'SK_ID_CURR', how = 'left')
app_train = app_train.merge(previous_appication_agg_new, on = 'SK_ID_CURR', how = 'left')
app_test = app_test.merge(previous_appication_counts, on = 'SK_ID_CURR', how = 'left')
app_test = app_test.merge(previous_appication_agg_new, on = 'SK_ID_CURR', how = 'left')
print(app_train.shape)
print(app_test.shape)
- 通过自定义函数agg_numeric、count_categorical对POS_CASH_balance数据连续变量和离散变量的特征提取。
POS_CASH_balance_counts = count_categorical(POS_CASH_balance, group_var = 'SK_ID_CURR', df_name = 'POS_CASH_balance')
POS_CASH_balance_agg_new = agg_numeric(POS_CASH_balance, group_var = 'SK_ID_CURR', df_name = 'POS_CASH_balance')
POS_CASH_balance_agg_new.head()
- 将POS_CASH_balance数据中相关特征连接到主训练集和测试集上。
app_train = app_train.merge(POS_CASH_balance_counts, on = 'SK_ID_CURR', how = 'left')
app_train = app_train.merge(POS_CASH_balance_agg_new, on = 'SK_ID_CURR', how = 'left')
app_test = app_test.merge(POS_CASH_balance_counts, on = 'SK_ID_CURR', how = 'left')
app_test = app_test.merge(POS_CASH_balance_agg_new, on = 'SK_ID_CURR', how = 'left')
print(app_train.shape)
print(app_test.shape)
此时,训练集特征数目已增加至764个,可能有过拟合的风险。因此,先利用主训练集/测试集application和3个辅助训练集bureau、previous_application以及POS_CASH_balance上所构建的新特征经过特征选择后,先建模预测,查看引入bureau、previous_application这两个辅助训练集上的新特征,AUC得分有无提高。
六、特征选择
Stpe10:特征筛选,在上述构造的所有特征中,通过计算变量与变量之间的相关系数,来移除具有共线性的特征以提高模型的效果,阈值是0.8,即移除每一对相关性大于0.8的变量中的其中一个变量。
corrs = app_train.corr()
threshold = 0.8
above_threshold_vars = {}
for col in corrs:
above_threshold_vars[col] = list(corrs.index[corrs[col] > threshold])
cols_to_remove = []
cols_seen = []
cols_to_remove_pair = []
for key, value in above_threshold_vars.items():
cols_seen.append(key)
for x in value:
if x == key:
next
else:
if x not in cols_seen:
cols_to_remove.append(x)
cols_to_remove_pair.append(key)
cols_to_remove = list(set(cols_to_remove))
print('被移除列的数量: ', len(cols_to_remove))
train_corrs_removed = app_train.drop(columns = cols_to_remove)
test_corrs_removed = app_test.drop(columns = cols_to_remove)
print('去除高相关性特征后的训练集特征数: ', train_corrs_removed.shape)
print('去除高相关性特征后的测试集特征数: ', test_corrs_removed.shape)
七、建模预测
step11:利用在主训练集和辅助训练集上构造的特征,再使用之前建立好的模型model函数进行建模预测。
submission, fi, metrics = model(train_corrs_removed, test_corrs_removed)
print('metrics')
print(metrics)

fi_sorted = plot_feature_importances(fi)
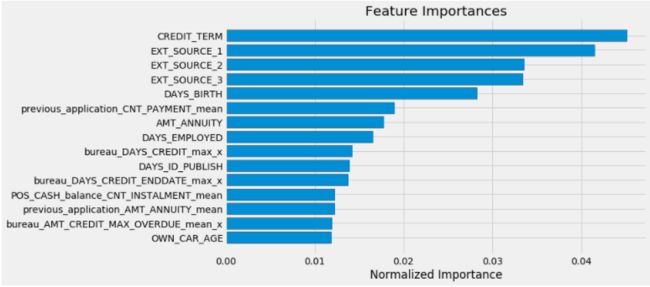
与仅在主训练集上构建特征后训练预测的AUC得分相比,加入三个辅助训练集bureau、previous_application、POS_CASH_balance上构造的新特征后,训练特征数为448个,其ROC得分也有一定的提高。
具体的,在训练集上ROC提高了4%,在测试集上ROC提高了1.9%。
对比两次训练时前15个重要性特征,CREDIT_TERM依然是最重要的特征,其中在加入bureau\previous_application辅助训练集后,新增了如previous_application_CNT_PAYMENT_mean、bureau_AMT_CREEDT_MAX_OVERDUE_mean等次重要特征,说明加入辅助训练集能够提高一点的模型预测能力。
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,因此,需要创建更好的特征工程进一步探索分析。