用实力给自己正名,YOLOv5:道路损伤检测我最强!GRDDC'2020大赛报告

作者:Deeksha Arya等
编译:CV君
报道:我爱计算机视觉公众号(id:aicvml)
向大家推荐一篇论文『Global Road Damage Detection: State-of-the-art Solutions』,它总结了在 IEEE International Conference on Big Data'2020 会议中举办的 “Global Road Damage Detection Challenge (GRDDC) ,全球道路损坏检测挑战赛”中前 12 名的解决方案。

其不仅给出了各参赛队的方案,而且这些代码也全部开源了,相信对于学术和工业界的朋友都会很有帮助。
本次挑战赛的任务是对几种道路损伤进行检测,不仅要分类出损伤类别,还要定位到损伤的位置,故该比赛实质是一个目标检测问题。
01
数据集
GRDDC'2020 数据集是从印度、日本和捷克收集的道路图像。包括三个部分:Train, Test1, Test2。训练集包括带有 PASCAL VOC 格式 XML 文件标注的道路图像。在给参赛者的数据Test1 和 Test2 中是没有标注。train则包含标注。
数据分布如下:

三个数据集和三个国家的图像分布统计
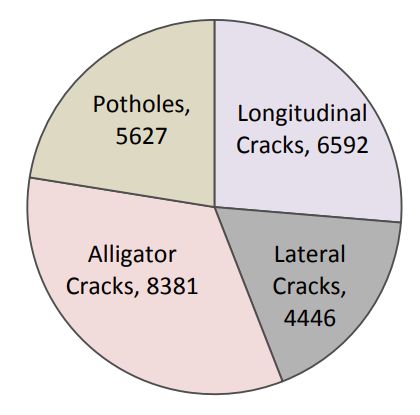
训练数据中每种损坏类型的实例数
02
评估方法
GRDD 挑战赛的评估标准是F1-Score。
对于参赛者提交的预测结果,如果预测满足以下两个标准,则认为它是正确的。
predicted bounding box 与 ground truth bounding box 之间的重叠区域超过 50%,即 IoU > 0.5。
预测的标签与实际的标签相匹配,如图像的标注文件中所指定的(ground truth)。
评估脚本比较两个输入文件以及计算所提交的 F1-Score。F1-Score 为精确率和召回率的调和平均数,精确度是真阳性与所有预测阳性的比率。召回率是真正的阳性结果与所有实际阳性结果的比率。
各参数的细节如下:
真阳性(TP):ground truth 中存在一个损害实例,并且该实例的标签和边界框被正确预测,IoU>0.5。
假阳性(FP):当模型预测了图像中某一特定位置的损害实例,但该实例并不存在于图像的 ground truth 中。也包括了预测标签与实际标签不匹配的情况。
假阴性(FN):当一个损害实例出现在 ground truth 中,但模型无法预测正确的标签或该实例的边界框。
召回率:

精确度:

F1-Score:

F1指标对召回和精度的权重相等。因此,参赛者需要在两者都有中等水平的表现,而不是在其中一个方面表现突出,在另一个方面表现不佳。对 test1 和test2 分别计算 F1。最后,用两个分数的平均值对各队进行排名。
03
结果和排名
本次挑战赛共有来自世界各地的 121 支队伍报名参加,有13 支队伍根据提出的解决方案和提交的源代码所达到的平均 F1-score 入围,其中有12 支队伍进入了决赛。
排名前三的团队平均 F1-score 超过60%,并提出了使用集成学习和多种数据增强技术的高效方法。
冠军团队是:IMSC团队(Hedge等,来自美国南加州大学和约旦德国约旦大学),提出方法基于 ultralytics-YOLO (u-YOLO) [YOLOv5, 2020],并应用了测试时数据增强(TTA),提高了模型的鲁棒性。TTA 通过对每张测试图像进行多次变换(如水平翻转、提高图像分辨率)并生成新的图像来进行数据增广。
新的图像与现有图像一起被输入到训练好的 u-YOLO 模型中。因此,对应于每一个测试图像,使用增强的图像生成多个预测。在此过程中产生的重复或重叠的预测使用非极大抑制(NMS)算法进行过滤。整个方法被称为集成预测(Ensemble Prediction,EP)。
除了 EP,该团队还提出了另一种方法,称为集成模型(EM)。顾名思义,EM是将 u-YOLO 模型的不同变体进行集成。鉴于训练一个 u-YOLO 模型涉及到调整不同的超参数,使用这些参数的不同组合会产生不同的训练模型。作者选择这些模型的一个子集,以使它们的整体精度最大化。每幅图像都会在所有选定的模型上测试,然后对每个模型的预测结果进行平均,最后应用非极大抑制。这种集成技术通过降低预测方差实现了更好的准确性。
团队的最终方案是将这两种方法结合起来,Ensemble Model with Ensemble Prediction(EM+EP)。可以想象每幅图像的测试时间肯定是很长的,但好在这只是比赛。
当然作者也比较了三种方法(EM、EP和EM+EP)在速度和精度方面的表现。统计结果显示,虽然在(EM+EP)的情况下,准确率得到了提高,达到了最高的 F1-score(测试1为0.67)(大力出奇迹啊!),而如果用每幅图像的检测时间来衡量,该方法在检测速度方面是最差的。
获胜团队的最后得分及代码如下:
Test1-Score:0.6748
Test2-Score:0.6662
(这个结果是远超第二名的!)
作者已经公开了代码:
https://github.com/USC-InfoLab/rddc2020

第二名
团队:SIS Lab
方案:以 YOLO-v4 为基础模型的集成模型,数据增广用到随机裁剪增强算法,每张训练图像输出三张图像。另外,其也探索用到过不同输入图像分辨率的 YOLO-v4检测。
Test1-Score:0.6275
Test2-Score:0.6358
代码:https://github.com/kevaldoshi17/IEEE-Big-Data-2020
第三名
团队:DD-VISION
方案:以Cascade R-CNN为基础模型的模型集合。数据增广用到:道路分割、混合、CLAHE、 RGB shift。该团队也探索使用过的其他算法:Faster-RCNN, ResNeXt101, HR-Net, CBNet, ResNet-50。
Test1-Score:0.629
Test2-Score:0.6219
代码:https://pan.baidu.com/share/init?surl=VjLuNBVJGS34mMMpDkDRGQ password: xzc6
Cascade R-CNN曾在多个目标检测比赛中博得头筹,这次的表现略逊一筹。
第四名
团队:titan_mu
方案:CSPDarknet53主干网上训练的YOLO模型。无数据增广。其还探索使用过 Hourglass104和 EfficientNet 主干网上训练的 CenterNet 和 EfficientDet 模型。
Test1-Score:0.5814
Test2-Score:0.5751
代码:https://github.com/titanmu/RoadCrackDetection
第五名
团队:Dongjuns
方案:主方法是:YOLOv5x。对于数据增广:图像HSV、图像转换、图像比例、水平翻转、马赛克。
Test1-Score:0.5683
Test2-Score:0.5710
代码:https://github.com/dongjuns/RoadDamageDetector
第六名
团队:SUTPC
方案:Ensemble(YOLO-v4 + Faster-RCNN)。
Test1-Score:0.5636
Test2-Score:0.5707
代码:https://github.com/ZhangXG001/RoadDamgeDetection
第七名
团队:RICS
方案:EfficientDet 。
Test1-Score:0.565
Test2-Score:0.547
论文An Efficient and scalable deep learning approach for road damage detection
代码:https://github.com/mahdi65/
roadDamageDetection2020


第八名
团队:AIRS-CSR
方案:主方法 YOLOv4,以及其它数据增广方法:通过调整亮度、对比度、色调、饱和度和噪声进行图像转换。随机缩放和 Mosaic 数据增强,条件GAN。
Test1-Score:0.554
Test2-Score:0.541
代码:https://github.com/ZhangXG001/RoadDamgeDetection
注:不知是否是原论文作者笔误,第八名与第六名的代码库是同一个
第九名
团队:CS17
方案:Faster RCNN+ Resnet-18/Resnet-50。使用过数据增广但没有改善精度。
Test1-Score:0.5413
Test2-Score:0.5430
代码:https://github.com/TristHas/road
第十名
团队:BDASL
方案:使用Resnet-50和Resnet-101主干网的多级 Faster R-CNN,以及以CSPNet 为主干网的 Yolov5。数据增广:对路面进行尺寸调整和语义分割(这样只检测路面部分)。
Test1-Score:0.5368
Test2-Score:0.5426
代码:https://github.com/vishwakarmarhl/rdd2020
第十一名
团队:IDVL
方案:Detectron2 和 Faster R-CNN。数据增广使用了水平镜像和缩放。
Test1-Score:0.51
Test2-Score:0.514
代码https://github.com/iDataVisualizationLab/
roaddamagedetector
第十二名
团队:E-LAB
方案:FR-CNN。
Test1-Score:0.4720
Test2-Score:0.4656
代码:https://github.com/MagischeMiesmuschel/E-LAB_IEEE_BDC_GRDD_2020_submission

前 12 支团队所取得的排名及得分情况


前 12 支队伍信息
05
结果讨论
YOLOv5、YOLOv4是比赛中常用的模型,u版YOLOv5很优秀;
几乎所有团队都使用了数据增广,其可以显著改善精度,但也有用了没效果的时候;
目标检测中的集成学习:
多图像输入+多模型测试+结果送入NMS。
在【我爱计算机视觉】公众号后台回复“GRDD”,即可下载该论文报告和前三名的参赛代码。

备注:目标检测

目标检测交流群
2D、3D目标检测等最新资讯,若已为CV君其他账号好友请直接私信。
我爱计算机视觉
微信号:aicvml
QQ群:805388940
微博知乎:@我爱计算机视觉
网站:www.52cv.net

在看,让更多人看到 