2022_WSDM_Long Short-Term Temporal Meta-learning in Online Recommendation
[论文阅读笔记]2022_WSDM_Long Short-Term Temporal Meta-learning in Online Recommendation
论文下载地址: https://doi.org/10.1145/3488560.3498371
发表期刊:WSDM
Publish time: 2022
作者及单位:
- Ruobing Xie∗ WeChat, Tencent Beijing, China [email protected]
- Yalong Wang∗ WeChat, Tencent Beijing, China [email protected]
- Rui Wang WeChat, Tencent Beijing, China [email protected]
- Yuanfu Lu WeChat, Tencent Beijing, China [email protected]
- Yuanhang Zou WeChat, Tencent Beijing, China [email protected]
- Feng Xia WeChat, Tencent Beijing, China [email protected]
- Leyu Lin WeChat, Tencent Beijing, China [email protected]
数据集: 正文中的介绍
- NewsRec-21B dataset (extracted from a widely-used news recommendation system in WeChat)
代码:
其他:
其他人写的文章
简要概括创新点: internal Short-term + global Long-term + Temporal Meta-learning based on MAML + DeepFM + Multi-hop Neighbor-similarity Based loss
- The contributions of this work are concluded in four points as follows: (这项工作的贡献总结为以下四点:)
- We first systematically address the practical challenges of jointly considering users’ internal/external behaviors and short-/long-term preferences in recommendation via our new proposed LSTTM framework. LSTTM is effective and easy to deploy in practical systems. (我们首先通过新提出的LSTTM框架,系统地解决了在推荐中联合考虑用户的内部/外部行为和短期/长期偏好的实际挑战。LSTTM有效且易于在实际系统中部署。)
- We build two graphs focusing on different aspects to make full use of all internal/external behaviors. Moreover, we set customized GAT aggregators and training strategies to better learn user short-/long-term preferences. (我们构建了两个关注不同方面的图表,以充分利用所有内部/外部行为。此外,我们还设置了定制的GAT聚合器和培训策略,以更好地了解用户的短期/长期偏好。)
- We design a novel temporal meta-learning method based on MAML, which enables fast adaptations to users’ real-time preferences. To the best of our knowledge, we are the first to adopt temporal MAML in online recommendation. (我们设计了一种新的基于MAML的时态元学习方法,能够快速适应用户的实时偏好。据我们所知,我们是第一个在在线推荐中采用时态MAML的)
ABSTRACT
- (1) An effective online recommendation system should jointly capture users’ long-term and short-term preferences in both users’ internal behaviors (from the target recommendation task) and external behaviors (from other tasks). (一个有效的在线推荐系统应该联合捕获 用户在内部行为(来自目标推荐任务) 和 外部行为(来自其他任务) 中的 长期 和 短期偏好 。)
- (2) However, it is extremely challenging to conduct fast adaptations to real-time new trends while making full use of all historical behaviors in large-scale systems, due to the real-world limitations in real-time training efficiency and external behavior acquisition. (然而,由于实时训练效率和外部行为获取方面的现实限制,在充分利用大型系统中所有历史行为的同时,快速适应实时新趋势是极具挑战性的。)
- (3) To address these practical challenges, we propose a novel Long Short-Term Temporal Meta-learning framework (LSTTM) for online recommendation. (为了应对这些实际挑战,我们提出了一种新的用于在线推荐的长-短期时间元学习框架(LSTTM)。)
- It arranges user multi-source behaviors in a global long-term graph (它将 用户的多源行为 安排在一个 全局长期 图中)
- and an internal short-term graph, ( 内部短期图 ,)
- and conducts different GAT-based aggregators and training strategies to learn user short-term and long-term preferences separately. (执行不同的 基于GAT的聚合器 和训练策略,分别学习用户的 短期 和 长期 偏好。)
- To timely capture users’ real-time interests, we propose a temporal meta-learning method based on MAML under an asynchronous optimization strategy for fast adaptation, which regards recommendations at different time periods as different tasks. (为了及时捕捉 用户的实时兴趣 ,我们提出了一种 异步优化策略下的基于MAML的时态元学习方法 , 该方法将不同时间段的推荐视为不同的任务 。)
- It arranges user multi-source behaviors in a global long-term graph (它将 用户的多源行为 安排在一个 全局长期 图中)
- (4) In experiments, LSTTM achieves significant improvements on both offline and online evaluations. It has been deployed on a widely-used online recommendation system named WeChat Top Stories, affecting millions of users. (在实验中,LSTTM在离线和在线评估方面都取得了显著的改进。它已部署在一个广泛使用的在线推荐系统微信热门故事上,影响了数百万用户。)
CCS CONCEPTS
• Information systems → Recommender systems.
KEYWORDS
recommendation, temporal meta-learning, online recommendation
1 INTRODUCTION
-
(1) Real-world industry-level recommendation systems usually need to interact with complicated practical scenarios. (现实世界中的行业级推荐系统通常需要与复杂的实际场景交互。)
-
Large-scale on-line recommendation systems in super platforms such as Google and Amazon usually have the following two complexities: (谷歌和亚马逊等超级平台上的大规模在线推荐系统通常有以下两个复杂性:)
- (1) user behaviors are multi-source. Super platforms usually have multiple applications with shared user accounts (e.g., search, news, and video recommendation in Google), which can meet users’ diverse demands. (用户行为是多源的。超级平台通常有多个具有共享用户帐户的应用程序(例如,谷歌的搜索、新闻和视频推荐),可以满足用户的多样化需求。)
- Users’ various behaviors in multiple applications are related via shared accounts after user approvals, which can provide additional information from different aspects for the target recommendation task. (用户在多个应用程序中的各种行为在用户批准后通过共享帐户进行关联,这可以为目标推荐任务提供来自不同方面的附加信息。)
- In real-world scenarios, recommendation systems benefit from not only effective algorithms, but also informative data. (在现实场景中,推荐系统不仅受益于有效的算法,还受益于信息数据。)
- A good online recommendation should make full use of both user internal behaviors (i.e., user behaviors in the target recommendation task) and user external behaviors (i.e., user behaviors in other applications). (一个好的在线推荐应该充分利用 用户的内部行为(即目标推荐任务中的用户行为) 和 用户的外部行为(即其他应用中的用户行为)。)
- (2) User preferences are variable. In large-scale recommendation systems, millions of new items are daily generated and added to the candidate pool. (用户偏好是可变的。在大规模推荐系统中,每天都会生成数百万个新项目,并将其添加到候选池中。)
- Online systems (especially news and video recommendations) should capture users’ short-term preferences timely and accurately, since users’ concentrations are easily attracted by new trends and hot topics. (在线系统(尤其是新闻和视频推荐)应该及时准确地捕捉用户的短期偏好,因为用户的注意力很容易被新趋势和热门话题吸引。)
- In contrast, users’ long-term preferences could provide users’ aggregated stable interests as effective supplements to short-term interests. (相比之下,用户的 长期偏好 可以提供用户的聚合 稳定兴趣,作为短期兴趣的有效补充。因此,一个好的现实世界推荐应该很好地捕捉用户可变的短期偏好和用户稳定的长期偏好。)
- Hence, a good real-world recommendation should well capture both user variable short-term preferences and user stable long-term preferences. (因此,一个好的现实世界推荐应该很好地捕捉用户可变的短期偏好和用户稳定的长期偏好。)
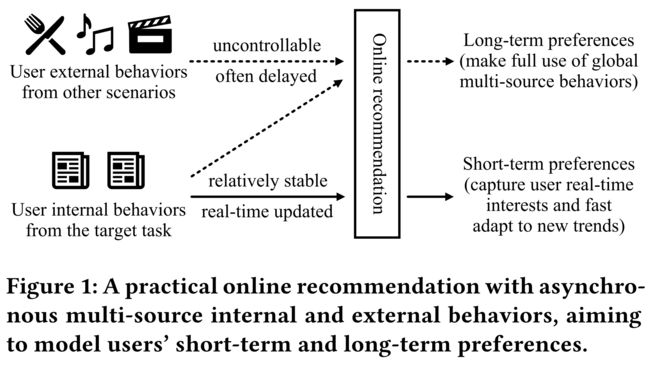
Figure 1: A practical online recommendation with asynchronous multi-source internal and external behaviors, aiming to model users’ short-term and long-term preferences. (图1:一个具有异步多源内部和外部行为的实用在线推荐,旨在模拟用户的短期和长期偏好。)
- (1) user behaviors are multi-source. Super platforms usually have multiple applications with shared user accounts (e.g., search, news, and video recommendation in Google), which can meet users’ diverse demands. (用户行为是多源的。超级平台通常有多个具有共享用户帐户的应用程序(例如,谷歌的搜索、新闻和视频推荐),可以满足用户的多样化需求。)
-
(2) In this work, we attempt to design an effective and efficient online recommendation framework, which jointly considers both users’ internal/external behaviorsandusers’ short-term/long-term preferences. (在这项工作中,我们试图设计一个有效且高效的在线推荐框架,该框架综合考虑了用户的内部/外部行为和用户的短期/长期偏好。)
-
This online recommendation mainly faces the following three challenges: (该在线推荐主要面临以下三个挑战:)
- (1) How to jointly consider internal and external behaviors? As in Fig. 1, users’ multi-source behaviors in various applications usually have different features. It is difficult to combine this heterogeneous information. Moreover, in real-world scenarios, users’ internal and external behaviors are often asynchronous (i.e., real-time internal feedbacks V.S. delayed and uncontrollable external behaviors), which makes it inconvenient to conduct a stable joint learning. (如何联合考虑内部行为和外部行为?如图1所示,用户在各种应用程序中的多源行为通常具有不同的特征。很难将这些异构信息组合起来。此外,在现实场景中,用户的内部和外部行为通常是异步的(即实时内部反馈,即延迟和不可控的外部行为),这使得不方便进行稳定的联合学习。)
- (2) How to effectively model both short-term and long-term preferences? Both users’ short-term and long-term interests are essential in real-world recommendations, while there are biases between them. Models should capture both short-term and long-term preferences, and should be able to determine which interest is more essential in different scenarios. (如何有效地对短期和长期偏好进行建模?用户的短期和长期兴趣在现实世界的推荐中都是至关重要的,但两者之间存在偏见。模型应该同时捕捉短期和长期偏好,并且应该能够确定在不同的场景中哪个兴趣更重要。)
- (3) How to conduct a timely online update to capture short-term preferences? It is crucial to conduct an online update to capture user variable interests over time. However, it is extremely time-consuming (or even impractical) to conduct a complete model retraining or a complicated fine-tuning with million-level new behaviors. It is challenging to balance effectiveness and efficiency in online recommendation. These three challenges are important in real-world scenarios, while there are barely any works that jointly address them systematically. (如何及时进行在线更新以获取短期偏好?进行在线更新以捕获用户随时间变化的兴趣至关重要。然而,对百万级新行为进行完整的模型再培训或复杂的微调非常耗时(甚至不切实际)。在线推荐的有效性和效率之间的平衡是一个挑战。这三个挑战在现实场景中很重要,但几乎没有任何工作能够系统地共同应对它们。)
-
(3) To address these issues, we propose a novel Long Short-Term Temporal Meta-learning (LSTTM) framework for practical online recommendations. (为了解决这些问题,我们提出了一个新的长短期时间元学习(LSTTM)框架,用于实用的在线推荐。)
- Specifically, we build two heterogeneous graphs, namely the global long-term graph and the internal short-term graph, to capture different user preferences from multi-source behaviors. (具体来说,我们构建了两个异构图,即 全局长期图 和 内部短期图 ,以从 多源行为 中捕获不同的用户偏好。)
- The global long-term graph is a huge graph containing all users’ internal and external behaviors. It aims to build a global view of all multi-source interactions between users and items to better capture users’ long-term preferences. (全局长期图 是一个包含 所有用户 的内部和外部行为的巨大图。它的目标是建立用户和物品之间所有多源交互的全局视图,以便更好地捕捉用户的长期偏好。)
- In contrast, the internal short-term graph focuses on the short-term behaviors of the target recommendation task, which is specially optimized for real-time interest evolutions. (相比之下,内部短期图 侧重于目标推荐任务的 短期 行为,该任务专门针对 实时兴趣演变 进行了优化。)
- LSTTM adopts graph attention networks (GATs) with different neighbor sampling strategies to learn user long-term and short-term representations from these heterogeneous graphs, and then combines them via a gating fusion. (LSTTM采用 具有不同邻域抽样策略的图注意网络(GAT) 从这些异构图中学习用户的长期和短期表示,然后通过 选通融合 将它们结合起来。)
- To better capture long/short-term preferences and balance effectiveness and efficiency in online serving, we further design an asynchronous optimization method. (为了更好地捕捉长期/短期偏好,平衡在线服务的有效性和效率,我们进一步设计了一种异步优化方法。)
- We propose a temporal MAML training strategy, which regards recommendations at different time periods as different tasks, based on a classical meta-learning method named MAML [6]. This new temporal meta-learning enables fast adaptations to real-time variable user preferences. (我们提出了一种基于经典元学习方法MAML[6]的时态MAML训练策略,将不同时间段的建议视为不同的任务。这种新的时态元学习能够快速适应实时变化的用户偏好。)
- The advantages of LSTTM mainly locate in three aspects: (LSTTM的优势主要体现在三个方面:)
- (1) LSTTM makes full use of all internal and external behaviors via two huge graphs. (LSTTM通过两个巨大的图形充分利用所有内部和外部行为。)
- (2) We conduct different GAT aggregations and training strategies for two graphs to learn user short-term and long-term preferences separately, and combine them via gating. The differential designs enable more refined preference learning. (我们对两个图形进行不同的 GAT聚合 和 训练策略,分别学习用户的短期和长期偏好,并通过选通将它们结合起来。差异化设计可以实现更精细的偏好学习。)
- (3) The asynchronous optimization with temporal MAML facilitates fast adaptations to new trends under the practical (data and computation) limitations of real-world systems. (基于时间MAML的异步优化有助于在现实系统的实际(数据和计算)限制下快速适应新趋势。)
- Specifically, we build two heterogeneous graphs, namely the global long-term graph and the internal short-term graph, to capture different user preferences from multi-source behaviors. (具体来说,我们构建了两个异构图,即 全局长期图 和 内部短期图 ,以从 多源行为 中捕获不同的用户偏好。)
-
(4) In experiments, we conduct an offline temporal CTR prediction with competitive baselines on a real-world recommendation system, and also conduct an online A/B test. The significant offline and online improvements show the effectiveness of LSTTM. Moreover, we also conduct an ablation study to better understand the effectiveness of different components. (在实验中,我们在现实世界的推荐系统上进行了离线时间CTR预测,并进行了在线a/B测试。线下和线上的显著改进表明了LSTTM的有效性。此外,我们还进行了消融研究,以更好地了解不同成分的有效性。)
-
(5) The contributions of this work are concluded in four points as follows: (这项工作的贡献总结为以下四点:)
- We first systematically address the practical challenges of jointly considering users’ internal/external behaviors and short-/long-term preferences in recommendation via our new proposed LSTTM framework. LSTTM is effective and easy to deploy in practical systems. (我们首先通过新提出的LSTTM框架,系统地解决了在推荐中联合考虑用户的内部/外部行为和短期/长期偏好的实际挑战。LSTTM有效且易于在实际系统中部署。)
- We build two graphs focusing on different aspects to make full use of all internal/external behaviors. Moreover, we set customized GAT aggregators and training strategies to better learn user short-/long-term preferences. (我们构建了两个关注不同方面的图表,以充分利用所有内部/外部行为。此外,我们还设置了定制的GAT聚合器和培训策略,以更好地了解用户的短期/长期偏好。)
- We design a novel temporal meta-learning method based on MAML, which enables fast adaptations to users’ real-time preferences. To the best of our knowledge, we are the first to adopt temporal MAML in online recommendation. (我们设计了一种新的基于MAML的时态元学习方法,能够快速适应用户的实时偏好。据我们所知,我们是第一个在在线推荐中采用时态MAML的)
- We achieve significant improvements on offline and online evaluations. LSTTM has been deployed on a real-world system for millions of users. The idea of temporal MAML can also be easily transferred to other models and tasks. (我们在离线和在线评估方面取得了显著进步。LSTTM已经部署在一个真实的系统上,供数百万用户使用。时间MAML的思想也可以很容易地转移到其他模型和任务中。)
2 RELATED WORKS
2.1 Recommender System.
-
(1) In real-world recommendation, Factorization machine (FM) [19], NFM [8], DeepFM [7], AutoInt [20], DFN [29] are widely used to model feature interactions. User behaviors are one of the most essential features to learn user preferences. Lots of models [21, 28, 31, 34, 37] regard user behaviors as sequences to model user preferences via attention and transformer. Besides sequence-based models, graph-based models such as SR-GNN [26] and GCE-GNN [25] use graph neural networks (GNNs) on user behavior graphs built from sessions. (在实际推荐中,因子分解机(FM)[19]、NFM[8]、DeepFM[7]、AutoInt[20]、DFN[29]被广泛用于建模特征交互。用户行为是了解用户偏好的最基本特征之一。许多模型[21,28,31,34,37] 将用户行为视为序列 ,通过注意和变换来模拟用户偏好。除了基于序列的模型外,基于图形的模型(如SR-GNN[26]和GCE-GNN[25])在会话构建的用户行为图上使用图形神经网络(GNN)。)
- Inspired by these works, we also adopt GAT [23] to model user internal/external behaviors, and use DeepFM to model long-/short-term feature interactions. (受这些工作的启发,我们还采用GAT[23]对用户的内部/外部行为进行建模,并使用DeepFM对长期/短期的功能交互进行建模。)
-
(2) Both long- and short- term preferences are essential in recommendation. (长期和短期偏好在推荐中都是必不可少的。)
- Xiang et al. [27] proposes an injected preference fusion on a session-based temporal graph to model users’ long-term and short-term preferences simultaneously. (Xiang等人[27]在基于会话的时态图上提出了一种注入式偏好融合,以同时模拟用户的长期和短期偏好。)
- STAMP [12] highlights users’ current interests from the short-term memory of the last clicks. (STAMP[12]从上次点击的短期记忆中突出了用户当前的兴趣。)
- DIEN [36] explicitly models user’s interest evolutions. (DIEN[36]明确地为 用户的兴趣演变 建模。)
- Some works jointly consider short-term and long-term representations [1, 33]. (有些工作联合考虑短期和长期代表)
- Hu et al. [9] conducts LSTM for short-term interests and GNNs for long-term preferences. (Hu等人[9]为短期兴趣进行LSTM,为长期偏好进行GNN。)
- Intent preference decoupling [13] and online exploration [32] are used for online recommendation. (意向偏好分离[13]和在线探索[32]用于在线推荐。)
- However, these models cannot capture real-time global hot topics well, and do not make full use of multiple behaviors. (然而,这些模型不能很好地捕捉实时的全局热点话题,并且没有充分利用多种行为。)
- LSTTM builds two graphs focusing on long-term and short-term interests, and uses a temporal MAML to highlight short-term interests. (LSTTM构建了两个关注长期和短期兴趣的图表,并使用时间MAML突出短期兴趣。)
2.2 Meta-learning in Recommendation.
-
(1) Meta-learning aims to transfer the meta knowledge so as to rapidly adapt to new tasks with a few examples, which is regarded as “learning to learn” [24]. (元学习旨在转移元知识,以快速适应新任务,只需几个例子,这被认为是“学会学习”[24]。)
- MAML [6] is a classical model-agnostic meta-learning method widely used in various fields, which provides a good weight initialization. Some works have also explored meta-learning on graphs [16, 41]. (MAML[6]是一种经典的模型不可知元学习方法,广泛应用于各个领域,提供了良好的权重初始化。一些研究还探索了图上的元学习[16,41]。)
-
(2) In recommendation, meta-learning has also been verified on various cold-start scenarios, including cold-start user [10, 40], item [22, 39], cross-domain recommendation [4, 38] and model selection [15]. (在推荐中,元学习也在各种冷启动场景中得到了验证,包括冷启动用户[10,40]、项目[22,39]、跨领域推荐[4,38]和模型选择[15]。)
- MeLU [10] brings in MAML to model cold-start users. (MeLU[10]引入了MAML来模拟冷启动用户。)
- Bharadhwaj [2] improves MAML with the dynamic meta-step for cold-start users. (Bharadhwaj[2]为冷启动用户提供了动态元步骤,从而改进了MAML。)
- Lu et al. [14] combines MAML with heterogeneous information networks, considering both semantic-wise and task-wise adaptations. (Lu等人[14]将MAML与异构信息网络相结合,同时考虑语义和任务方面的适应性。)
-
Besides MAML-based methods, Pan et al. [17] proposes meta-embeddings for warm-up scenarios. (除了基于MAML的方法外,Pan等人[17]还提出了热身场景的元嵌入。)
- MAMO [3] designs two task-specific and feature-specific memories. (MAMO[3]设计了两种特定于任务和功能的记忆。)
- SML [35] focuses on model retraining, which learns a transfer function from old to new parameters. (SML[35]专注于模型再训练,即学习从旧参数到新参数的传递函数。)
-
Different from these models, LSTTM designs a temporal MAML to accelerate model adaptation to users’ short-term preferences. (与这些模型不同,LSTTM设计了一个时间MAML,以加速模型适应用户的短期偏好。)
-
To the best of our knowledge, we are the first to conduct temporal MAML in recommendation. (据我们所知,我们是第一个进行时间MAML推荐的公司。)
3 METHODOLOGY
- (1) In this work, we attempt to jointly consider both user internal and external behaviors to capture users’ short-term/long-term preferences in online recommendation. (在这项工作中,我们试图共同考虑用户的内部和外部行为,以捕捉用户的短期/长期偏好在线推荐。)
- We first give brief definitions of the notions used in this work as follows: (我们首先对这项工作中使用的概念作如下简要定义:)
Definition 1: User internal behaviors. (用户内部行为)
- In LSTTM, the user behaviors of the target recommendation task are viewed as the user internal behaviors. (在LSTTM中,目标推荐任务的用户行为被视为用户内部行为。)
- These behaviors are the main sources of user preferences inside the target recommendation. (这些行为是目标推荐中用户偏好的主要来源。)
Definition 2: User external behaviors. (用户外部行为)
- All user behaviors from other applications are considered as the user external behaviors. (来自其他应用程序的所有用户行为都被视为用户外部行为。)
- These user external behaviors are related to their internal behaviors via the shared user accounts under user approvals. These behaviors are informative complements to the internal behaviors. (这些用户外部行为通过用户批准下的共享用户帐户与其内部行为相关。这些行为是对内部行为的有益补充。)
Definition 3: Temporal meta-learning.
- Meta-learning aims to fast adapt to new tasks [6]. (元学习旨在快速适应新任务[6]。)
- We define the temporal meta-learning, which regards recommendations in different time periods as different tasks, since user preferences can frequently change over time. (我们定义了时态元学习,它将不同时间段的建议视为不同的任务,因为用户的偏好会随着时间的推移而频繁变化。)
- The temporal meta-learning concentrates on fast adaptations between user behaviors at different times for short-term preferences. (时态元学习专注于用户在不同时间的行为之间快速适应短期偏好)
3.1 Overall Framework
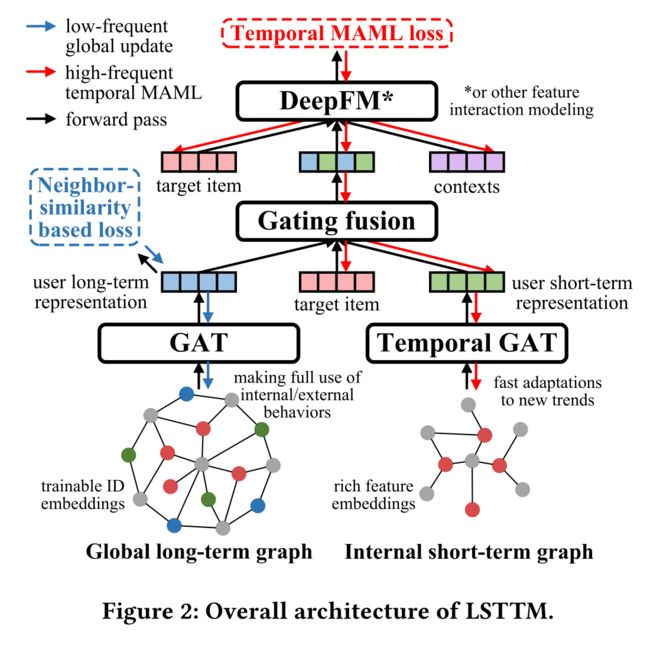
- (1) Fig. 2 displays the overall architecture of LSTTM. (图2显示了LSTTM的总体架构。)
- (2) The internal short-term graph regards all users and items in the target recommendation task as nodes, with all user internal behaviors utilized as edges. (内部短期图将目标推荐任务中的所有用户和项目视为节点,将所有用户内部行为视为边。)
- A heterogeneous GAT with temporal neighbor sampling is used for node aggregation to highlight user short-term preferences. (节点聚合采用了一种具有时间邻域采样的异构GAT来突出用户的短期偏好。)
- (3) In contrast, the global long-term graph is a much larger heterogeneous graph having all user internal and external behaviors, which focuses on the global view of user long-term preferences in multisource behaviors. (相比之下,全局长期图是一个更大的异构图,包含所有用户的内部和外部行为,它关注于多源行为中用户长期偏好的全局视图。)
- The long short-term graph fusion module then conducts a gating strategy to combine two short-/long-term representations, followed by a feature interaction module to generate the final recommendation. (长-短期图融合模块随后执行选通策略,将两个 短/长期表示 组合在一起,然后是特征交互模块,以生成最终建议。)
- We propose an asynchronous optimization to learn long-term and short-term preferences differently. (我们提出了一种异步优化方法,以不同的方式学习长期和短期偏好。)
- For the short-term graph and gating fusion modules, we propose a temporal MAML to highlight short-term interest modeling. (对于短期图和选通融合模块,我们提出了一种时间MAML来突出短期兴趣建模。)
- While for the long-term graph, we rely on a multi-hop neighbor-similarity based loss for efficient long-term preferencelearning. (而对于长期图,我们依靠基于多跳邻居相似性的损失来进行有效的长期偏好学习。)
- (4) In this case, LSTTM can make full use of both internal and external information to leverage user short-term and long-term preferences, finding an industrial balance between effectiveness and efficiency in practice. (在这种情况下,LSTTM可以充分利用内部和外部信息,利用用户的短期和长期偏好,在实践中找到有效性和效率之间的行业平衡。)
3.2 Internal Short-term Graph (内部短期图)
-
(1) The internal short-term graph module models user short-term internal behaviors. (内部短期图模块为用户的短期内部行为建模。)
- Specifically, it has two types of nodes indicating all users u ∈ U u \in U u∈U and all items d ∈ D I d \in D_I d∈DI in the target recommendation task, which are linked by user-item click behaviors as edges. (具体来说,它有两种类型的节点,指示在目标推荐任务中所有用户 u ∈ U u \in U u∈U和d所有项目 d ∈ D I d \in D_I d∈DI,这些任务由用户项点击行为作的边来链接。)
- U U U and D I D_I DI are the overall user set and internal item set respectively. (整体用户集和内部项目集。)
- We use u i 0 u^0_i ui0 and d i 0 d^0_i di0 to represent the i i i-th input feature embeddings of users and items, which are trainable embeddings built from different types of user attributes and item features (e.g., tag, topic). (表示用户和项目的第 i i i个输入特征嵌入,这是从不同类型的用户属性和项目特征(例如标签、主题)构建的可训练嵌入。)
- Specifically, it has two types of nodes indicating all users u ∈ U u \in U u∈U and all items d ∈ D I d \in D_I d∈DI in the target recommendation task, which are linked by user-item click behaviors as edges. (具体来说,它有两种类型的节点,指示在目标推荐任务中所有用户 u ∈ U u \in U u∈U和d所有项目 d ∈ D I d \in D_I d∈DI,这些任务由用户项点击行为作的边来链接。)
-
(2) Inspired by Veličković et al.[23], we build an enhanced GAT layer for short-term oriented node aggregation. (我们构建了一个增强的GAT层,用于面向短期的节点聚合。)
- For a user u i u_i ui and his/her click sequence s e q i = { d i , 1 , ⋅ ⋅ ⋅ , d i , m } seq_i = \{d_{i, 1}, · · · , d_{i, m} \} seqi={di,1,⋅⋅⋅,di,m} , different from conventional random-based neighbor sampling, we conduct a temporal neighbor sampling, which only selects the top-K most recent clicked items. The temporal neighbor sampling generates the neighbor set N u i N_{u_i} Nui as: (给定一个用户 u i u_i ui和他/她的点击序列 s e q i = { d i , 1 , ⋅ ⋅ ⋅ , d i , m } seq_i = \{d_{i, 1}, · · · , d_{i, m} \} seqi={di,1,⋅⋅⋅,di,m}, 与传统的基于随机的邻居抽样不同,我们进行了一次 时态邻居抽样,只选择前K个最近点击的项目。 时态邻域采样生成 邻域集)
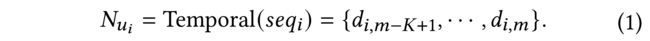
- For a user u i u_i ui and his/her click sequence s e q i = { d i , 1 , ⋅ ⋅ ⋅ , d i , m } seq_i = \{d_{i, 1}, · · · , d_{i, m} \} seqi={di,1,⋅⋅⋅,di,m} , different from conventional random-based neighbor sampling, we conduct a temporal neighbor sampling, which only selects the top-K most recent clicked items. The temporal neighbor sampling generates the neighbor set N u i N_{u_i} Nui as: (给定一个用户 u i u_i ui和他/她的点击序列 s e q i = { d i , 1 , ⋅ ⋅ ⋅ , d i , m } seq_i = \{d_{i, 1}, · · · , d_{i, m} \} seqi={di,1,⋅⋅⋅,di,m}, 与传统的基于随机的邻居抽样不同,我们进行了一次 时态邻居抽样,只选择前K个最近点击的项目。 时态邻域采样生成 邻域集)
-
(3) Similarly, we also generate the sampled neighbor set of items as N d i = { u i , m ′ − K + 1 , u i , m ′ } N_{d_i} = \{u_{i, m^{'} - K + 1}, u_{i, m^{'}} \} Ndi={ui,m′−K+1,ui,m′}. With the temporal neighbor set N u i N_{u_i} Nui, we build the user representation u i k u^k_i uik at the k k k-th layer via item embeddings in the k − 1 k−1 k−1 layer as follows: (类似地,我们还生成采样的相邻项集 N d i = { u i , m ′ − K + 1 , u i , m ′ } N_{d_i} = \{u_{i, m^{'} - K + 1}, u_{i, m^{'}} \} Ndi={ui,m′−K+1,ui,m′}. 伴同时态邻居集 N u i N_{u_i} Nui,我们构建了第 k k k层的用户表示,通过$k-1层的项目embedding。 )

-
(4) W d k W^k_d Wdk is the weighting matrix. α i j k \alpha^k_{ij} αijk represents the attention between u i u_i ui and d i , j d_{i,j} di,j in this layer, which is formalized as: ( W d k W^k_d Wdk是权重矩阵, α i j k \alpha^k_{ij} αijk表示该层中 u i u_i ui和 d i , j d_{i,j} di,j之间的注意力,其形式化为:)
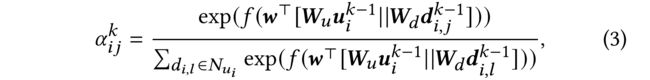
- where f ( ⋅ ) f(·) f(⋅) indicates a LeakyReLU activation and ∥ \parallel ∥ indicates the concatenation.
- w ⊤ w^\top w⊤, W u W_u Wu and W d W_d Wd are the weighting vector and matrices. (是加权向量和矩阵。)
-
Note that the temporal neighbor set N u i N_{u_i} Nui changes over time, since the internal short-term graph is a dynamic graph that is updated via users’ new behaviors. (注意到,时态邻居集 N u i N_{u_i} Nui随着时间的推移会发生变化,因为内部短期图是一个动态图,通过用户的新行为进行更新。)
-
Finally, we conduct a two-layer temporal GAT to generate the user short-term representation u i s = u i 2 u^s_i = u^2_i uis=ui2, which is fed into the next gating fusion module. (最后,我们进行了两层时态GAT,以生成用户短期表示 u i s = u i 2 u^s_i = u^2_i uis=ui2 , 被送入下一个选通融合模块。)
-
The aggregation of items is similar to that of users. (项目的聚合与用户的聚合类似。)
-
We use GAT since it is effective, efficient, and easy to deploy on billion-level huge graphs. It is also convenient to conduct other enhanced GNN models in this module. (我们使用GAT,因为它有效、高效,并且易于在十亿级的大型图形上部署。在本模块中还可以方便地执行其他增强型GNN模型。)
-
(5) In internal short-term graph, the temporal neighbor sampling highlights the individual-level short-term preferences. We also propose a temporal meta-learning method to update this module, attempting to capture the short-term preferences at the global level, which will be introduced in Sec. 3.5. (在内部短期图中,时态邻域抽样突出了个体水平的短期偏好。我们还提出了一种时态元学习方法来更新这个模块,试图在全局层面捕捉短期偏好,这将在第二节中介绍。3.5.)
3.3 Global Long-term Graph (全局长期图)
-
(1) The global long-term graph module aims to take advantage of all user diverse preferences in multiple applications. (全局长期图模块旨在利用多个应用程序中所有用户的不同偏好。)
- It considers users u ∈ U u \in U u∈U and all internal and external items d ∈ D I ∪ D E d \in D_I \cup D_E d∈DI∪DE as nodes, where D I D_I DI and D E D_E DE represent the overall internal and external item sets.
- All heterogeneous user-item interactions in different applications as regarded as edges. (将不同应用程序中的所有异构用户项交互视为边。)
- The details of the external behaviors are in Sec. 4. Since heterogeneous items usually have different feature fields that are hard to align, we represent all users and items via trainable ID embeddings u ˉ i 0 \bar{u}^0_i uˉi0 and d ˉ i 0 \bar{d}^0_i dˉi0 in the same space. (有关外部行为的详细信息,请参阅第4节。由于异构项通常具有难以对齐的不同特征字段,我们通过可训练的ID嵌入 u ˉ i 0 \bar{u}^0_i uˉi0 and d ˉ i 0 \bar{d}^0_i dˉi0来表示所有用户和项目,在同一个空间。)
-
(2) We also conduct a two-layer GAT for neighbor aggregation similar as Eq. (2) to Eq. (3) , where the neighbor set N u i ˉ \bar{N_{u_i}} Nuiˉ are randomly sampled or selected via certain importances. (我们还为邻居聚合进行了两层GAT,类似于等式(2)到等式(3),其中邻居集 N u i ˉ \bar{N_{u_i}} Nuiˉ是通过某些确定的重要性随机抽样或选择的。)
-
The user long-term representation u ˉ i l = u ˉ i 2 \bar{u}^l_i = \bar{u}^2_i uˉil=uˉi2 is also utilized in the gating fusion module. Since the overall behaviors are too enormous to be fully retrained in online, and external behaviors are usually delayed and uncontrollable, we conduct an enhanced neighbor-similarity based loss to train this module asynchronously introduced in Sec. 3.5. (用户长期表示 u ˉ i l = u ˉ i 2 \bar{u}^l_i = \bar{u}^2_i uˉil=uˉi2也用于选通融合模块。由于整体行为过于庞大,无法在线完全重新训练,外部行为通常会延迟且无法控制,因此我们采用增强的基于邻居相似性的loss来异步训练Sec3.5中介绍的模块)
-
(3) Comparing the internal short-term graph modeling with the global long-term graph modeling, we can find three main differences: (比较内部短期图建模和全局长期图建模,我们可以发现三个主要区别:)
- (1) they adopt different data sources, and thus have different input feature forms (i.e., detailed user and item features V.S. trainable ID embeddings). (它们采用不同的数据源,因此具有不同的输入特征形式(即详细的用户和项目特征与可训练的ID嵌入)。)
- (2) They conduct different neighbor sampling strategies (i.e., temporal-based V.S. random or importance-based) due to their different long-/short- term concentrations. (由于长期/短期浓度不同,他们采用不同的相邻抽样策略(即,基于时间的VS随机或基于重要性)。)
- (3) They are updated under different strategies (i.e., temporal meta-learning V.S. neighbor-similarity based loss), considering the effectiveness of short-term preference modeling and the efficiency of global user behavior modeling in practice. (考虑到短期偏好建模的有效性和全局用户行为建模在实践中的效率,它们在不同策略下进行了更新(即,时态元学习与 基于邻居相似性的损失)
- We use GNN to capture heterogeneous node interactions, and conduct GAT in node aggregation for efficiency. It is also not difficult to conduct other complicated heterogeneous information networks in LSTTM. (我们使用GNN 捕获异构节点交互,并在节点聚合中执行GAT以提高效率。在LSTTM中进行其他复杂的异构信息网络也不难。)
3.4 Long- Short-term Preference Fusion (长短期偏好融合)
-
(1) This module attempts to combine both user short-term and long-term representations u i s u^s_i uis and u ˉ i l \bar{u}^l_i uˉil to generate the ranking score. We conduct a gating-based fusion to generate the final user representation u i u_i ui via u i s u^s_i uis and u ˉ i l \bar{u}^l_i uˉil as follows:
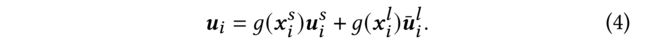
-
g ( ⋅ ) g(·) g(⋅) indicates the gating function, which is measured via the corresponding user embeddings and the target item d j s d^s_j djs as: (指示选通功能,通过相应的用户嵌入和目标项进行测量) (是一个随机初始化的可训练项目ID嵌入。)

- w g s w^s_g wgs and w g l w^l_g wgl are weighting vectors. (是加权向量。)
- d j s d^s_j djs is a trainable item ID embedding that is randomly initialized. (是一个随机初始化的可训练项目ID嵌入。)
-
(2) With this gating-based fusion, users can get personalized weights on long-/short- term preferences for different items, which helps to improve the performances. (通过这种基于选通的融合,用户可以根据不同项目的长期/短期偏好获得个性化权重,这有助于提高性能。)
-
(2) After gating fusion, the final user representation u i u_i ui is aggregated with the recommendation contexts c c c and target item embedding d j s d^s_j djs, and then fed into the downstream neural ranking models. (在门控融合之后,最终的用户表示 u i u_i ui与推荐上下文 c c c和嵌入 d j s d^s_j djs的目标项聚合,然后输入下游神经排序模型。)
-
We conduct a widely-used DeepFM [7] to model the feature field interactions between user, item and contexts as follows: (我们使用广泛使用的DeepFM[7]对用户、项目和上下文之间的功能字段交互进行建模,如下所示:)
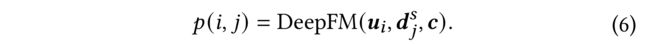
-
p ( i , j ) p(i, j) p(i,j) is the click probability for u i u_i ui and d j d_j dj. It is also easy to adopt other feature interaction models for feature interactions. ( p ( i , j ) p(i,j) p(i,j)是 u i u_i ui和 d j d_j dj的点击概率。采用其他特征交互模型进行特征交互也很容易。)
3.5 Optimization with Temporal MAML (用时态MAML优化)
The asynchronous optimization with temporal MAML is the key contribution of LSTTM. In practice, timely model updating is significant in online recommendation, while there are two challenges in real-world systems. (基于时间MAML的异步优化 是LSTTM的 关键贡献 。在实践中,及时更新模型对于在线推荐非常重要,而在现实系统中有两个挑战。)
- (1) It is extremely difficult to conduct a full model retraining or a complicated fine-tuning in real-time for GNN models with large-scale graphs, especially with the nearly billion-level interactions in the huge global graph. (对于具有大规模图的GNN模型,尤其是在巨大的全局图中有近十亿级交互的情况下,实时进行完整的模型再训练或复杂的微调是极其困难的。)
- (2) Moreover, multi-source behaviors are usually obtained asynchronously (e.g., external behaviors are often delayed) due to some practical system limitations. Hence, we decouple the training of internal short-term graph and global long-term graph into two asynchronous optimization objectives, including a temporal MAML based cross-entropy loss and a multi-hop neighbor-similarity based loss. It enables LSTTM to be smoothly and timely updated. (此外,由于一些实际的系统限制,多源行为通常是异步获得的(例如,外部行为通常是延迟的)。因此,我们将内部短期图和全局长期图的训练解耦为两个异步优化目标,包括基于时间MAML的交叉熵损失和基于多跳邻居相似性的损失。它使LSTTM能够顺利及时地更新。)
3.5.1 Temporal Meta-learning. (时态元学习)
-
(1) To enhance LSTTM with the capability of fast adaptation to user short-term interests, we propose a novel temporal MAML training strategy based on [6]. ([6] Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of ICML.) (为了增强LSTTM快速适应用户短期兴趣的能力,我们提出了一种 基于[6]的时态MAML训练策略 )
-
Different from conventional meta-learning based recommendations that usually consider each user or domain as a task, our temporal MAML regards recommendation in each time period as a task. (不同于传统的基于元学习的建议,通常认为每个用户或域作为一个任务,我们的时态MAML考虑在每个时间段的建议作为一项任务。)
-
(2) Specifically, we first divide all training instances into different sets according to their time periods (e.g., we view each hour as a time period for the practical demands). (具体来说,我们首先根据时间段将所有训练实例划分为不同的集合(例如,我们将每个小时视为实际需求的时间段)。)
- In temporal MAML training, we regard instances in two adjacent hours as a task. (在时间性MAML训练中,我们将相邻两个小时内的实例视为一项任务)
- The support set contains instances of the former hour, while the query set contains instances of the latter hour. Note that an instance can belong to both a support set and a query set in two tasks. (支持集包含前一小时的实例,而查询集包含后一小时的实例。请注意,实例可以同时属于两个任务中的支持集和查询集。)
- We could further divide these temporal tasks into more fine-granularity tasks, where all instances in a task derive from the same user group (which is built via similar basic profiles or user interests) at the same time. Through these fine-granularity tasks, the instances in the support set and the query set will be more relevant. In this case, the temporal MAML will focus on the new trends in certain user communities instead of whole user groups. We can choose different temporal MAML settings according to the practical needs of systems. (我们可以进一步将这些时态任务划分为更细粒度的任务,其中任务中的所有实例同时来自相同的用户组(通过类似的基本配置文件或用户兴趣构建)。通过这些细粒度任务,支持集中的实例和查询集中的实例将更加相关。在这种情况下,时态MAML将关注特定用户社区中的新趋势,而不是整个用户组。我们可以根据系统的实际需要选择不同的时间MAML设置)
-
(3) In training, we sample different temporal tasks containing training instances in different time periods to form a batch. (在训练中,我们对包含不同时间段的训练实例的不同时间任务进行采样,形成一个batch。)
- To make sure our temporal MAML can learn a better initialization for fast adaptation on all time periods, we diversify the sampled temporal tasks to make them dissimilar to each other (e.g., selecting tasks in different hours and days). (为了确保我们的时态MAML能够学习更好的初始化,以便在所有时间段上快速适应,我们将采样的时态任务多样化,使它们彼此不同(例如,选择不同时间和天数的任务))
- The inner update (line 6) with support sets and the outer update (line 8) with query sets are similar to the original MAML. We conduct one gradient update in both inner and outer updates for efficiency. (带有支持集的内部更新(第6行)和带有查询集的外部更新(第8行)与原始MAML类似。为了提高效率,我们在内部和外部更新中进行了一次梯度更新)
- In online, we also conduct one gradient update for all new user feedbacks similar to MAML, which enables high-frequent (or even real-time) online model learning. Algorithm 1 gives the pseudo-code of temporal MAML with temporal tasks. (在在线模式下,我们也会对所有新用户反馈进行一次梯度更新,类似于MAML,这可以实现高频率(甚至实时)在线模式学习。算法1给出了带有时态任务的时态MAML的伪代码。)

-
(4) Under the temporal MAML training framework, we conduct a classical cross entropy loss L T L_T LT with the click probability p ( i , j ) p(i, j) p(i,j) of user u i u_i ui and item d j d_j dj on the positive set (clicked user-item instances) S p S_p Sp and negative set (unclicked user-item instances) S n S_n Sn as follows:
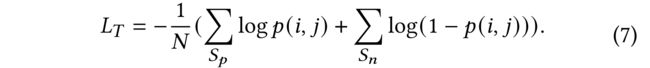
-
(5) Note that the L T L_T LT is only used for updating the internal short-term graph and the long- short-term preference fusion modules via the temporal MAML as in Fig. 2. (请注意, L T L_T LT仅用于通过时态MAML更新内部短期图和长短期偏好融合模块,如图2所示。)
- A gradient block is conducted to the global long-term graph module, since it is responsible for modeling users’ stable long-term preferences from multi-source behaviors, and thus should be fully trained on all behaviors. (对全局长期图模块进行梯度block,因为它负责从多源行为中建模用户稳定的长期偏好,因此应该对所有行为进行全面培训。)
-
(6) Motivations and advantages of temporal MAML. The motivations and advantages of the temporal MAML are concluded as follows: (时态MAML的动机和优势。时态MAML的动机和优势总结如下)
- (1) we attempt to capture new trends and hot topics timely in practical recency-sensitive recommendation systems. The temporal MAML highlights the model’s capability in capturing global user interest evolutions via temporal tasks, which enables fast adaptations to users’ variable short-term interests on the global new trends. (我们试图在实用的近因敏感推荐系统中及时捕捉新趋势和热点话题。时态MAML强调了该模型通过时态任务捕捉全局用户兴趣演变的能力,从而能够快速适应用户对全局新趋势的可变短期兴趣。)
- (2) MAML can fast adapt to new tasks [6], while classical MAML-based models mainly regard individual users as tasks, and thus cannot model the global temporal factors well. Hence, we propose the temporal MAML focusing on the temporal tasks. (MAML能够快速适应新任务[6], 而基于MAML的经典模型主要将单个用户视为任务,因此无法很好地建模全局时间因素。 因此,我们提出了以时间任务为中心的时间MAML。)
- (3) The internal short-term graph modeling can also provide short-term interests via the temporal neighbor sampling (see Eq. (1)). (内部短期图建模还可以通过时间邻域采样提供短期兴趣(参见等式(1))。)
- However, it merely concentrates on the individual user-related short-term behaviors, ignoring the global short-term behaviors generated by other users (which is essential especially when the user does not have recent behaviors). (然而,它只关注与单个用户相关的短期行为,而忽略了由其他用户生成的全局短期行为(尤其是当用户没有最近的行为时,这一点至关重要)。)
- The temporal MAML and the short-term graph modeling are strong supplements to each other in capturing user real-time preferences. (时态MAML和短期图建模是捕捉用户实时偏好的有力补充。)
- (4) The temporal MAML is also naturally suitable for the asynchronous online learning with large-scale instances, since it only needs a one-step update. (时态MAML自然也适用于大规模实例的异步在线学习,因为它只需要一步更新。)
3.5.2 Multi-hop Neighbor-similarity Based Loss. (基于多跳邻居相似性的loss。)
-
(1) Differing from the internal short-term graph, the global long-term graph (与内部短期图不同,全局长期图)
- (1) aims to model user long-term behaviors, (旨在模拟用户的长期行为,)
- (2) contains far more internal and external behaviors, and (包含更多的内部和外部行为)
- (3) might have uncontrollable and delayed behavior acquisitions. (可能有无法控制和延迟的行为。)
-
To make a compromise between efficiency, effectiveness, and robustness, we conduct a multi-hop neighbor- similarity based loss instead of the online temporal MAML. (为了在效率、有效性和鲁棒性之间做出折衷,我们采用了基于多跳邻居相似性的损失,而不是在线时态MAML。)
-
(2) We assume that both users’ and items’ long-term representations u ˉ i l \bar{u}^l_i uˉil and d ˉ j l \bar{d}^l_j dˉjl learned in Sec. 3.3 should be similar to their k-hop neighbors on the global long-term graph enhanced from [11] and [30]. (我们假设用户和项目的长期表示 u ˉ i l \bar{u}^l_i uˉil and d ˉ j l \bar{d}^l_j dˉjl,在Sec3.3学习到的。应该与[11]和[30]增强的全局长期图上的k-hop邻居相似。)
- The multi-hop neighbor-similarity based loss on the global user-item graph can be viewed as an extended matrix factorization (MF) model, which considers multi-hop user-item paths on the global graph as multi-source user/item correlations. (全局用户项图上 基于多跳邻居相似性的损失 可以看作是一个 扩展矩阵分解(MF)模型,该模型将全局图上的多跳用户项路径视为多源用户/项关联。)
- Precisely, we consider the 10-hop neighbors via DeepWalk based path sampling [18] to bring in more interactions via users’ multi-source behaviors. We formalize our k-hop neighbor-similarity based loss L N L_N LN as follows: (精确地,我们考虑10跳邻居通过基于DeepWalk的路径采样(18)通过用户的多源行为带来更多的交互。我们将基于k-hop邻居相似性的损失 L N L_N LN形式化,详情如下:)

- p p p is a k-length random path in the path set P P P generated by DeepWalk.
- q i , q j ∈ p q_i, q_j \in p qi,qj∈p are different nodes in the path p p p.
- We have q ˉ i l = u ˉ i l \bar{q}^l_i = \bar{u}^l_i qˉil=uˉil for user nodes and q ˉ j l = d ˉ j l \bar{q}^l_j = \bar{d}^l_j qˉjl=dˉjl for item nodes.
- σ \sigma σ is the sigmoid function.
-
(3) The multi-hop neighbor-similarity based loss focuses more on the global view of user and item representations learned from all long-term internal/external behaviors. (基于多跳邻居相似性的损失更关注从所有长期的内部/外部行为中学习到的用户和项目表示的全局视图。)
- Generally, the global long-term graph trains far less frequently than the short-term graph considering its motivation and training efficiency. (一般来说,考虑到动机和训练效率,全局长期图的训练频率远低于短期图。)
-
(4) The advantages of using the multi-hop neighbor-similarity based loss for the global long-term graph are as follows: (对全局长期图使用基于多跳邻居相似性的损失的优点如下:)
- (1) the L N L_N LN loss is simple, efficient, and effective, which can directly optimize the cross-source interactions via the multi-hop connections. (简单、高效、高效,可以通过多跳连接直接优化跨源交互。)
- (2) Based on the neighbor-similarity based loss, it is more convenient to introduce other heterogeneous nodes (e.g., content or tag in [30]) and their interactions in this work. Other node representation learning methods are also easy to be adopted in our framework. (基于基于邻居相似性的损失,在本工作中引入其他异构节点(如[30]中的内容或标签)及其交互更为方便。在我们的框架中,其他节点表示学习方法也很容易被采用。)
3.5.3 Overall loss.
-
(1) The overall loss L L L is the weighted aggregation of these two losses L T L_T LT and L N L_N LN as follows:
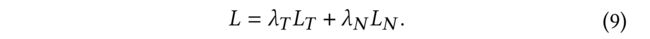
- We empirically set λ T = λ N = 1 \lambda_T = \lambda_N = 1 λT=λN=1.
- In LSTTM, the neighbor-similarity based loss L N L_N LN works as an auxiliary task for the temporal MAML loss L T L_T LT, since L T L_T LT is directly related to the ranking objectives. (在LSTTM中,基于邻域相似性的损失 L N L_N LN作为辅助任务用于时态MAML损失 L T L_T LT,因为 L T L_T LT与排名目标直接相关。)
-
(2)The advantages of our asynchronous optimization are listed as follows: (我们的异步优化的优点如下:)
- (1) it decouples the short-term and long-term preference modeling, making both modules more flexible, specialized, and robust to capture different user preferences. (它将短期和长期偏好建模分离,使这两个模块更加灵活、专业化和健壮,以捕获不同的用户偏好。)
- (2) It proposes an industrial solution to jointly consider large-scale external and internal behaviors, improving the robustness against the high disturbances and uncontrollability in practical systems (e.g., the delay and noises of external behaviors have little influence on the internal short-term preference modeling). (提出了一种联合考虑大规模外部和内部行为的工业解决方案,提高了实际系统中对高干扰和不可控性的鲁棒性(例如,外部行为的延迟和噪声对内部短期偏好建模的影响很小)。)
- (3) The asynchronous optimization is flexible and easy to deploy. It is also convenient to use other representation learning models in this asynchronous framework. (异步优化灵活且易于部署。在这个异步框架中使用其他表示学习模型也很方便。)
4 ONLINE DEPLOYMENT
Online System.
- We have deployed LSTTM on a real-world recommendation system of WeChat. This online recommendation system is a feed stream that has nearly million-level users and daily views. It contains heterogeneous domains, including news and videos. User behaviors of the target recommendation task are viewed as the internal behaviors. After user approvals, other behaviors (e.g., clicks in other recommendation domains) linked by the same user account in the platform are regarded as the external behaviors, which also provide additional information to reflect user preferences. (我们已经在微信的真实推荐系统上部署了LSTTM。这个在线推荐系统是一个拥有近百万级用户和每日浏览量的提要流。它包含不同的领域,包括新闻和视频。目标推荐任务的用户行为被视为内部行为。用户审批后,平台中同一用户账号链接的其他行为(如其他推荐域中的点击)被视为外部行为,也提供了反映用户偏好的附加信息。)
Online Serving.
- We conduct an asynchronous optimization and online updating for different modules. In offline training, we conduct a daily complete training to update all modules via the asynchronous optimization of temporal MAML and neighbor-similarity based losses on all ehaviors. It constructs an industrial balance between effectiveness and efficiency, since the access to user external behaviors is usually delayed, and the full training on billion-level global graphs cannot be conducted in real-time. In online serving, the global graph module is fixed within a day for modeling long-term preferences, while the internal graph and fusion modules are frequently updated (according to the online computing capability) to capture user short-term preferences. When recommending at the t t t-th time period, we consider all previous t − 1 t − 1 t−1 time periods in this day as the support set, simulating the offline temporal MAML training. Hence, we just need to conduct the general one-step gradient updates on new user behaviors, regarding them as the support set of the current recommendation. It enables a fast online learning since the online time complexity of temporal MAML is equivalent to the classical one-step fine-tuning. (我们对不同的模块进行异步优化和在线更新。在离线训练中,我们每天进行一次完整的训练,通过异步优化时间MAML和基于邻域相似性的所有eHavior损失来更新所有模块。它在有效性和效率之间构建了一个行业平衡,因为用户外部行为的访问通常会延迟,并且无法实时对十亿级全局图进行全面培训。在在线服务中,全局图模块在一天内固定,用于建模长期偏好,而内部图和融合模块则经常更新(根据在线计算能力)以捕获用户短期偏好。在 t t t时间段推荐时,我们考虑所有以前的T。 t − 1 t−1 t−1个时间段作为支持集,模拟离线时态MAML训练。因此,我们只需要对新用户行为进行一般的一步梯度更新,将其视为当前推荐的支持集。由于时态MAML的在线时间复杂度相当于经典的一步微调,因此它可以实现快速在线学习。)
Online Efficiency.
- We train our model once over all training instances in online updating considering the efficiency. The online computation does not involve the global long-term graph modeling. The online time complexity of LSTTM is O ( k ( T i + T f ) ) O(k(T_i + T_f)) O(k(Ti+Tf)), where k k k is the number of candidates (e.g., top 200 items retrieved by the previous matching module). T i T_i Ti and T f T_f Tf represent the computation costs of the internal short-term graph (2-layer GAT with the dynamic temporal neighbors) and the fusion. For the online memory cost, the model should store the temporal MAML model and the fixed user long-term representations. Specifically, we implement LSTTM on a self-developed distributed deep learning framework. We have 30 parameter servers and 20 workers for training. Each server has 10G memory with 3 CPUs, and each worker has 10G memory with 5 CPUs. We spend nearly 4 hours for daily complete retraining. (考虑到效率问题,我们对模型进行了一次又一次的在线更新训练。在线计算不涉及全局长期图建模。LSTTM的在线时间复杂度为 O ( k ( T i + T f ) ) O(k(T_i + T_f)) O(k(Ti+Tf)), 哪里푘 是候选项的数量(例如,前一个匹配模块检索到的前200项)。 T i T_i Ti 和 T f T_f Tf表示内部短期图(具有动态时间邻域的两层GAT)和融合的计算成本。对于在线存储成本,模型应存储时态MAML模型和固定的用户长期表示。具体来说,我们在自主开发的分布式深度学习框架上实现了LSTTM。我们有30台参数服务器和20名培训工人。每台服务器有3个CPU的10G内存,每个工人有5个CPU的10G内存。我们每天花将近4个小时完成再培训。)
5 EXPERIMENTS
In this section, we conduct experiments to answer the following research questions: (在本节中,我们通过实验来回答以下研究问题:)
- (RQ1): How does LSTTM perform in offline temporal CTR prediction that simulates practical scenarios (Sec. 5.4)? ((RQ1):LSTTM在模拟实际场景的离线时间CTR预测中如何执行(第5.4节)?)
- (RQ2): How does LSTTM perform in online A/B tests (Sec. 5.5)? ((RQ2):LSTTM在在线A/B测试中表现如何(第5.5节)?)
- (RQ3): What are the effects of different components (Sec. 5.6)? ((RQ3):不同成分的影响是什么(第5.6节)?)
5.1 Dataset
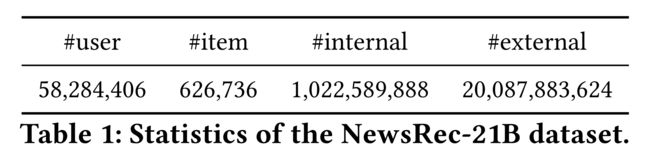
- Since there is no large-scale real-world dataset that contains both hourly-updated hot spots and user external behaviors, we build a new dataset NewsRec-21B extracted from a widely-used news recommendation system in WeChat. (由于没有包含每小时更新热点和用户外部行为的大规模真实数据集,我们从微信上广泛使用的新闻推荐系统中提取了一个新的数据集NewsRec-21B。)
- Precisely, we randomly select 58million users and get nearly1billion user internal behaviors with timestamps in the target news domain. (准确地说,我们随机选择了5.8亿用户,在目标新闻领域中获得了近10亿个带有时间戳的用户内部行为。)
- We also use these users’ 20 billion external click behaviors from other recommendation domains in the same platform after user approval to build the global long-term graph. (我们还使用这些用户在获得用户批准后在同一平台上其他推荐域的200亿次外部点击行为来构建全局长期图。)
- These internal and external behaviors are in the same platform, which are linked via the shared user accounts. (这些内部和外部行为在同一个平台上,通过共享用户帐户进行链接。)
- All data are preprocessed via data masking to protect user privacy. The instances in the former eight days are regarded as the train set, and the last day’s internal behaviors are considered as the test set. We follow Sec. 3.2 and Sec. 3.3 to build two huge graphs with the train set. Table 1 shows the detailed statistics of NewsRec-21B. (所有数据都经过预处理以保护用户隐私。前八天的实例被视为列车集,最后一天的内部行为被视为测试集。我们关注Sec。3.2和第。3.3用列车组建立两个巨大的图形。表1显示了NewsRec-21B的详细统计数据。)
5.2 Competitors
-
(1) We implement several competitive baselines for evaluation. First, we conduct four widely-used ranking models as follows: (我们实施了几个竞争性评估基准。首先,我们进行了四种广泛使用的排名模型,如下所示:)
- FM [19]. FM is a simple and effective model that captures second-order feature interactions via latent vectors. (FM是一种简单有效的模型,通过潜在向量捕捉二阶特征交互。)
- NFM [8]. NFM combines the neural FM layer with the DNN layer sequentially to model high-order feature interactions. (NFM将神经FM层与DNN层顺序组合,以模拟高阶特征交互。)
- DeepFM [7]. DeepFM follows the Wide&Deep framework and improves the Wide part with a neural FM layer. It is also used in the long-/short- term gating fusion of LSTTM. (DeepFM遵循广度和深度框架,并通过神经FM层改进广度部分。它还用于LSTTM的长/短选通融合。)
- AutoInt [20]. AutoInt is a strong feature interaction modeling method, which adopts self-attention layers. (AutoInt是一种强大的特征交互建模方法,它采用自关注层。)
-
(2) These baselines use the same features of the users, internal behaviors and contexts that are also used in LSTTM, and are optimized via the same training set with the cross-entropy loss. (这些基线使用与LSTTM中同样使用的用户特征、内部行为和上下文,并通过具有交叉熵损失的相同训练集进行优化。)
-
(3) For fair comparisons, we also implement two enhanced DeepFM models armed with external behaviors and sequence modeling. (为了进行公平的比较,我们还实现了两个增强的DeepFM模型,其中包含外部行为和序列建模。)
- DeepFM (+external). We add the features of user external behaviors to DeepFM, noted as DeepFM (+external). It has the same input features as the LSTTM model. (我们将用户外部行为的特性添加到DeepFM中,称为DeepFM(+external)。它与LSTTM模型具有相同的输入特性。)
- DIN+DeepFM (+external). Based on DeepFM (+external), we further bring in the ability of sequence-based modeling on user’s internal and external behaviors to better model the short-term and long-term preferences. Inspired by [29], we conduct two DIN encoders [37] to model internal and external behaviors respectively. These behavior features are considered as the input feature fields of DeepFM (+external) (在DeepFM(+external)的基础上,我们进一步引入了基于序列的用户内外行为建模能力,更好地建模短期和长期偏好。受[29]的启发,我们使用两个DIN编码器[37]分别模拟内部和外部行为。这些行为特征被视为DeepFM(+external)的输入特征字段)
-
(4) Finally, since we conduct the temporal MAML for online updating, we also implement two SOTA meta-learning methods based on SML [35] in online news recommendation as follows: (最后,由于我们进行了在线更新的时态MAML,我们还在在线新闻推荐中基于SML[35]实现了两种SOTA元学习方法,如下所示:)
- SML [35]. SML is the SOTA meta-learning based recommendation model designed for model retraining verified in online new recommendation [35]. It is the most related baseline of our task. SML attempts to learn a transfer function from old to new parameters via a sequential training over time. Following the original SML’s implementation, we also build SML based on an MF model. (SML是基于SOTA元学习的推荐模型,设计用于在线新推荐[35]中验证的模型再训练。这是我们任务中最相关的基线。SML试图通过一段时间内的顺序训练来学习从旧参数到新参数的传递函数。在最初的SML实现之后,我们还基于MF模型构建了SML。)
- SML+DeepFM. We further improve the original SML by replacing the MF model with the best performing DeepFM model, noted as SML+DeepFM. This model also utilizes the same features as LSTTM for fair comparisons. (我们进一步改进了原有的SML,用性能最好的DeepFM型号替换MF型号,称为SML+DeepFM。该模型还利用与LSTTM相同的功能进行公平比较。)
-
(5) Note that we do not compare with other meta-learning recommendation methods such as MeLU [10], since they focus on different tasks (e.g., cold-start users or domains) and are not suitable for our temporal setting. To further verify the effectiveness of different components and features in LSTTM, we implement four ablation versions of LSTTM, whose results are discussed in Sec. 5.6. (请注意,我们不会与其他元学习推荐方法(如MeLU[10])进行比较,因为它们专注于不同的任务(例如,冷启动用户或域),不适合我们的时间设置。为了进一步验证LSTTM中不同组件和功能的有效性,我们实现了LSTTM的四个消融版本,其结果将在第。5.6.)
5.3 Experimental Settings
- We randomly select up to 30 neighbors in global graph and 30 most recent behaviors in internal graph for aggregation. (我们在全局图中随机选择30个邻居,在内部图中随机选择30个最近的行为进行聚合。)
- The dimensions of the output embeddings in both graphs are 16. (两个图中的输出嵌入的维数都是16。)
- We use 6 fields for users (e.g., user profiles such as age and gender) and items (e.g., item features such as tag and provider), and the dimension of each trainable feature field embedding is 16. (我们为用户(例如,年龄和性别等用户侧像)和项目(例如,标签和提供者等项目特征)使用6个字段,每个可培训特征字段嵌入的维度为16。)
- In temporal MAML, the task number of each batch, batch size, and learning rate are essential parameters. (在时态MAML中,每个批次的任务数、批次大小和学习率是基本参数)
- We have tested the task number among {4,8,16},
- the support and query set size among {32,64,128,256},
- and the learning rate among {0.001,0.01,0.02}.
- Finally, we let each batch size contain 8 temporal tasks of different days and hours, (最后,我们让每个批量包含8个不同日期和时间的临时任务,)
- where each support set and query set contain 128 items. (其中每个支持集和查询集包含128项。)
- We use Adagrad [5] and empirically set the same learning rate as 0.01 for inner and outer updates. (我们使用Adagrad[5],并根据经验将内部和外部更新的学习率设置为0.01。)
- Note that all instances could belong to a certain query set used in Line 8, Algorithm 1, which directly updates model parameters. (请注意,所有实例都可能属于第8行算法1中使用的特定查询集,该查询集直接更新模型参数。)
- We only conduct a one-step gradient in temporal MAML for online efficiency. (为了提高在线效率,我们只在时间MAML中进行一步梯度。)
- We conduct a grid search for parameter selection. All models share the same experimental settings. (我们对参数选择进行网格搜索。所有模型共享相同的实验设置。)
5.4 Temporal CTR Prediction (RQ1)
We first simulate the real-world online recommendation and conduct the temporal CTR prediction task for offline evaluation. (我们首先模拟现实世界中的在线推荐,并执行用于离线评估的时态CTR预测任务)
5.4.1 Evaluation Protocol.
- We evaluate models on our real-world dataset NewsRec-21B. (我们在真实数据集NewsRec-21B上评估模型。)
- To simulate the online recommendation, we first train all models with the train set (the former few days), and divide the test set (the last day) into 24 hours. (为了模拟在线推荐,我们首先使用训练集(前几天)训练所有模型,并将测试集(最后一天)划分为24小时。)
- Each hour is regarded as a temporal task for evaluation, with all instances of former hours in the test set used as the support set. (每个小时都被视为评估的临时任务,测试集中以前时间的所有实例都被用作支持集。)
- Considering both accuracy and online efficiency, all models including LSTTM and baselines are fine-tuned via one gradient update for fair comparisons (SML is updated via its transfer method [35]). (考虑到准确性和在线效率,包括LSTTM和基线在内的所有模型都通过一次梯度更新进行微调,以进行公平比较(SML通过其传递方法进行更新[35])。)
- We use AUC as our metric, which is widely utilized as the main metric in real-world systems [7, 20, 37]. (我们使用AUC作为度量,它在现实系统中被广泛用作主要度量)
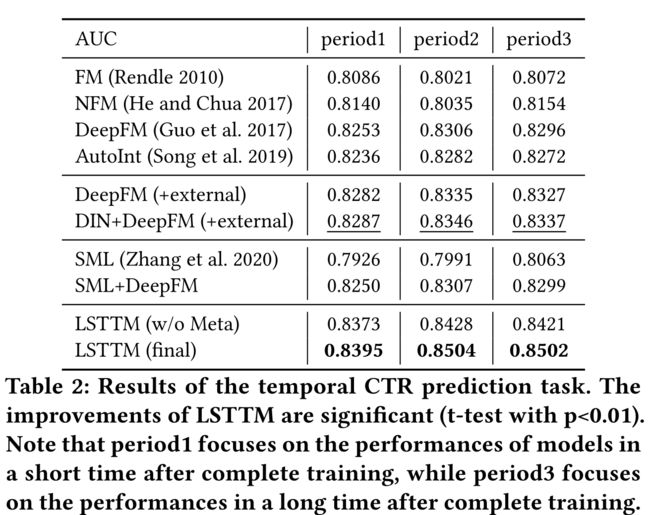
- For a better display, we group 24 hours into 3 periods (0:00-8:00, 8:00-16:00, 16:00-0:00+1), and report the average AUC in each period in Table 2. (为了更好地显示,我们将24小时分为3个时段(0:00-8:00、8:00-16:00、16:00-0:00+1),并在表2中报告每个时段的平均AUC。)
- We conduct 3 runs for each model. (我们为每个模型进行3次运行)
5.4.2 Experimental Results.
From Table 2 we can observe that: (从表2可以看出:)
-
(1) LSTTM achieves significant improvements on all baselines in three periods, with the significance level α = 0.01 \alpha = 0.01 α=0.01 . It consistently outperforms strong baselines in all 24 hours (see Fig. 3). The deviation is less than ±0.002. Considering the large size of our test set, the 1.1% − 1.7% AUC improvements over the best baseline are impressive and solid. It verifies the effectiveness and robustness of LSTTM in modeling both short-term and long-term preferences from users’ internal and external behaviors. (LSTTM在三个时期内实现了所有基线的显著改善,显著性水平α=0.01。在所有24小时内,其表现始终优于强基线(见图3)。偏差小于±0.002。考虑到我们的测试集很大,1.1%− 与最佳基线相比,1.7%的AUC改善令人印象深刻且稳定。它验证了LSTTM在从用户的内部和外部行为建模短期和长期偏好方面的有效性和鲁棒性。)
-
(2) LSTTM (final) consistently outperforms LSTTM (w/o Meta) and SML on all tasks. It confirms the advantages of temporal MAML in Sec. 3.5.1. Thanks to the MAML-based training, LSTTM is more sensitive to global new trends in communities. Hence, it can better capture users’ short-term preferences via good model initialization, and thus can fast adapt to hot topics over time in online recommendation. Nevertheless, LSTTM (w/o Meta) still performs better than baselines, which reflects the effectiveness of our global long-term and internal short-term graphs as well as the gating fusion. Sec. 5.6 gives more details of different ablation versions. (LSTTM(最终版)在所有任务上都始终优于LSTTM(不含Meta)和SML。它证实了时态MAML在Sec中的优势。3.5.1. 由于基于MAML的培训,LSTTM对社区的全球新趋势更加敏感。因此,通过良好的模型初始化,它可以更好地捕捉用户的短期偏好,从而能够快速适应在线推荐中的热门话题。尽管如此,LSTTM(w/o Meta)的性能仍优于基线,这反映了我们的全球长期和内部短期图以及选通融合的有效性。5.6节给出了不同消融版本的更多细节。)
-
(3) We also find that models armed with external behaviors consistently outperform the same models without external behaviors (e.g., see LSTTM in Sec. 5.6 and DeepFM in Table 2). It verifies the importance of external behaviors in real-world scenarios, which works as a strong supplement to the internal behaviors. The external behaviors will be more significant in few-shot scenarios. (我们还发现,具有外部行为的模型始终优于没有外部行为的相同模型(例如,见第5.6节中的LSTTM和表2中的DeepFM)。它验证了外部行为在现实场景中的重要性,是对内部行为的有力补充。在少数镜头场景中,外部行为将更加显著。)
-
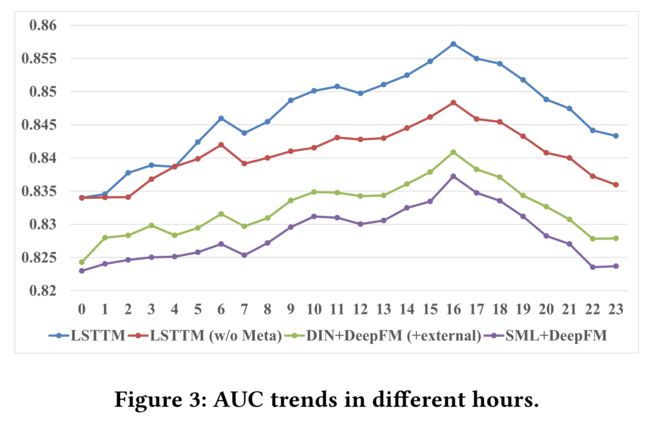
(4) Comparing models in different periods, we know that LSTTM achieves larger improvements in period 2 and 3 compared to LSTTM (w/o Meta). It is because that (a) humans and hot spots are often more active in period 2 and 3, where temporal MAML is superior to baselines in capturing user real-time preferences. (b) In period3, all models have not been fully trained for at least 16 hours. LSTTM
has a better online fine-tuning to catch up with new global interest evolutions. The cumulative effects of temporal MAML will gradually
show up over time with growing hot topics. Fig. 3 shows the hour-level AUC trends of four representative models. (比较不同时期的模型,我们知道,与LSTTM(w/o Meta)相比,LSTTM在第2和第3时期取得了更大的改进。这是因为(a)人类和热点通常在第2和第3阶段更活跃,在这两个阶段中,时间MAML在捕捉用户实时偏好方面优于基线。(b) 在第三阶段,所有模型至少有16小时没有接受过全面培训。LSTTM有更好的在线微调功能,以跟上新的全球利益变化。时间MAML的累积效应将随着时间的推移逐渐显现,并伴随着越来越多的热点话题。图3显示了四个代表性模型的小时级AUC趋势。)
5.5 Online A/B Tests (RQ2)
5.5.1 Evaluation Protocol.
- (1) To evaluate LSTTM in real-world systems, we conduct an online A/B test on WeChat Top Stories. Following Sec. 4, we deploy our LSTTM in the ranking module of the news domain with other modules unchanged. (为了评估现实系统中的LSTTM,我们在微信热门故事上进行了在线A/B测试。以下是Sec。4.我们在新闻领域的排名模块中部署我们的LSTTM,其他模块不变。)
- The online base model is DeepFM with the same online update frequency of LSTTM. (在线基础模型为DeepFM,其在线更新频率与LSTTM相同。)
- In online evaluation, we focus on four representative metrics, including Click-through-rate (CTR), average click number per capita (ACN), user has-click rate (HCR), and average dwell time per capita (DT) to measure recommendation accuracy and user satisfaction, which are formalized as follows: (在在线评估中,我们关注四个有代表性的指标,包括点击率(CTR)、人均点击次数(ACN)、用户点击率(HCR)和人均平均停留时间(DT),以衡量推荐准确性和用户满意度,其形式化如下:)

- (2) We conduct the A/B test for 5 days. (我们进行了为期5天的A/B测试。)
5.5.2 Experimental Results.
Table 3 shows the improvement percentages over the base model. We can observe that: (表3显示了与基础模型相比的改进百分比。我们可以观察到:)
-
(1) LSTTM achieves significant improvements on all metrics with the significance level α = 0.01 \alpha = 0.01 α=0.01. It reconfirms the effectiveness of LSTTM in online. Through the asynchronous online updating with the temporal MAML, LSTTM can (LSTTM在显著性水平α=0.01的所有指标上都取得了显著改善。它再次确认了LSTTM在在线测试中的有效性。通过时态MAML的异步在线更新,LSTTM可以)
- (a) fast adapt to new topics and hot spots, and (快速适应新话题和热点)
- (b) successfully combine both external and internal behaviors in online ranking without many computation costs. (成功地结合了在线排名中的外部和内部行为,而无需大量计算成本。)
-
(2) The improvement on CTR indicates that more appropriate items have been impressed to users (reflecting item-aspect accuracy), while the improvement on ACN represents that users are more willing to click items (reflecting user-aspect accuracy and activeness). HCR models the coverage of users that have clicked news, which implies the impacts of our recommendation function. LSTTM also outperforms the online baseline on dwell time of items, which reflects the real user satisfaction on the item contents. In conclusion, LSTTM achieves comprehensive improvements on all online metrics, which confirms the robustness of our model. (CTR的改进表明用户对更合适的项目印象深刻(反映项目方面的准确性),而ACN的改进表明用户更愿意点击项目(反映用户方面的准确性和积极性)。HCR对点击新闻的用户的覆盖率进行建模,这意味着我们的推荐功能的影响。LSTTM在商品停留时间方面也优于在线基线,这反映了用户对商品内容的真实满意度。总之,LSTTM实现了所有在线指标的全面改进,这证实了我们模型的稳健性。)

5.6 Ablation Tests (RQ3)
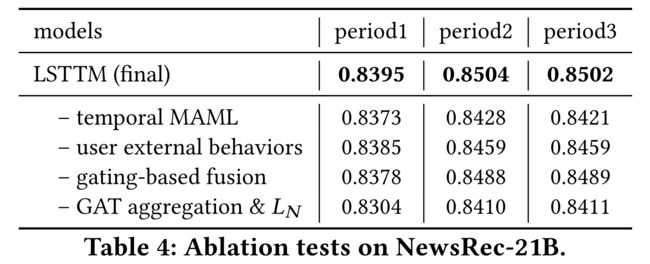
We further conduct an ablation test to verify the effectiveness of different components in LSTTM. Table 4 shows the results of different ablation settings. We observe that all components significantly benefit the recommendation. Precisely, we find that: (我们进一步进行了消融试验,以验证LSTTM中不同组件的有效性。表4显示了不同消融设置的结果。我们观察到,所有组件都显著受益于该建议。确切地说,我们发现:)
- (1) the temporal MAML can precisely capture user’s variable short-term interests without additional online computation costs. The improvements are larger when more new trends are involved as time passes by, such as in period 2 and 3. (时态MAML可以精确地捕捉用户的可变短期兴趣,而无需额外的在线计算成本。随着时间的推移,如在第2和第3阶段,涉及到更多新趋势时,改进会更大。)
- (2) The second ablation version only considers internal behaviors by removing the global long-term graph. It verifies the effectiveness
of the user external behaviors as well as the global long-term graph modeling in Sec. 3.3. The advantages of external behaviors will be more significant if we deploy LSTTM on cold-start scenarios. (第二种消融方案仅通过去除全局长期图来考虑内部行为。验证了Sec中用户外部行为和全局长期图建模的有效性。3.3. 如果我们在冷启动场景中部署LSTTM,外部行为的优势将更加显著。) - (3) The gating-based fusion is also effective compared to concatenation, which provides personalized strategies in combining internal short-term and global long-term representations. (与级联相比,基于选通的融合也很有效,提供了结合内部短期和全局长期表示的个性化策略。)
- (4) The fourth ablation version removes the GAT-based aggregation in Eq. (2) and the multi-hop neighbor-similarity based loss in Eq. (8) (only use the raw features of internal and external behaviors as inputs). The GAT-based aggregation and the multi-hop neighbor-similarity based loss enable more sufficient multi-domain user-item interactions, which are beneficial in capturing user variable and diverse preferences in practice.(第四个版本删除了式(2)中基于GAT的聚集和式(8)中基于多跳邻居相似性的损失(仅使用内部和外部行为的原始特征作为输入)。基于GAT的聚合和基于多跳邻居相似性的丢失能够实现更充分的多域用户项交互,这有助于在实践中捕获用户变量和不同的偏好。)
6 CONCLUSION AND FUTURE WORK
-
(1) In this work, we propose an LSTTM for online recommendation, (在这项工作中,我们提出了一个用于在线推荐的LSTTM,)
- which captures user long-term and short-term preferences from internal/external behaviors. (它从内部/外部行为中捕捉用户的长期和短期偏好。)
- The temporal MAML enables fast adaptations to new topics in recommendation. (时态MAML能够快速适应推荐中的新主题。)
- The effectiveness of LSTTM is verified in offline and online real-world evaluations. (LSTTM的有效性在离线和在线真实评估中得到验证。)
-
(2) In the future, we will polish the temporal MAML to build a more robust adaptation, and transfer the idea of temporal MAML to other
temporal tasks. We will also explore some enhanced combinations with other online learning and meta-learning methods. (在未来,我们将完善时态MAML以构建更强大的适应性,并将时态MAML的思想转移到其他时态任务中。我们还将探索与其他在线学习和元学习方法的一些增强组合。)