使用 Scikit-Learn 的人工数据集
使用 Python 生成合成数据

机器学习的一个问题,尤其是当您刚开始并想了解算法时,通常很难获得合适的测试数据。有些要花很多钱,有些则不能免费获得,因为它们受版权保护。因此,在某些情况下,人工生成的测试数据可以是一种解决方案。
出于这个原因,我们教程的这一章涉及人工生成数据。本章是关于创建人工数据。在我们教程的前几章中,我们了解到 Scikit-Learn (sklearn) 包含不同的数据集。一方面,有小的玩具数据集,但它也提供更大的数据集,这些数据集通常在机器学习社区中用于测试算法或作为基准。它为我们提供了来自“现实世界”的数据。
所有这些都很棒,但在许多情况下,这仍然不够。也许您找到了正确的数据类型,但您需要更多此类数据,或者数据并不完全是您要查找的数据类型,例如,您可能需要更复杂或更不复杂的数据。这是您应该考虑自己创建数据的地方。在这里,sklearn提供帮助。它包括各种随机样本生成器,可用于创建定制的人工数据集。满足您对大小和复杂性的想法的数据集。
以下 Python 代码是一个简单示例,我们在其中为一些德国城市创建了人工天气数据。我们使用 Pandas 和 Numpy 来创建数据:
import numpy as np
import pandas as pd
城市 = [ ‘柏林’ 、 ‘法兰克福’ 、 ‘汉堡’ 、
‘纽伦堡’ 、 ‘慕尼黑’ 、 ‘斯图加特’ 、
‘汉诺威’ 、 ‘萨尔布吕肯’ 、 ‘科隆’ 、
‘康斯坦茨’ 、 ‘弗莱堡’ 、 ‘卡尔鲁厄’
]
n = len (城市)
数据 = { '温度' : np 。随机的。正常( 24 , 3 , n ),
'湿度' : np 。随机的。正常( 78 , 2.5 , n ),
'Wind' : np 。随机的。正常( 15 , 4 , n )
}
df = pd. DataFrame (数据=数据, 索引=城市)
df
| 温度 | 湿度 | 风 | |
|---|---|---|---|
| 柏林 | 26.133572 | 80.328353 | 5.015542 |
| 法兰克福 | 23.161901 | 76.886831 | 14.021860 |
| 汉堡 | 24.145767 | 79.678764 | 10.897413 |
| 纽伦堡 | 27.114319 | 77.825100 | 21.273423 |
| 慕尼黑 | 24.573419 | 74.416920 | 21.734649 |
| 斯图加特 | 20.615747 | 81.827868 | 6.316270 |
| 汉诺威 | 26.513550 | 80.462603 | 9.568481 |
| 萨尔布吕肯 | 23.602173 | 83.181582 | 11.382041 |
| 科隆 | 27.769321 | 79.759665 | 11.433353 |
| 康斯坦斯 | 29.343985 | 78.814028 | 17.818053 |
| 弗莱堡 | 25.554123 | 77.339895 | 7.965502 |
| 卡尔斯鲁厄 | 19.780618 | 76.517790 | 6.304491 |
另一个例子
我们将为四种不存在的花卉创建人工数据。如果这些名字让你想起编程语言和披萨,那绝非巧合:
- Flos Pythonem
- 爪哇
- 弗洛斯玛格丽塔酒
- 人工花
RGB 平均颜色值相应地为:
- (255, 0, 0)
- (245, 107, 0)
- (206, 99, 1)
- (255, 254, 101)
花萼的平均直径为:
- 3.8
- 3.3
- 4.1
- 2.9
| Flos pythonem (254, 0, 0) |
Flos Java (245, 107, 0) |
|---|---|
| 弗洛斯玛格丽塔 (206, 99, 1) |
人工花链 (255, 254, 101) |
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
从 scipy.stats 导入 truncnorm
def truncated_normal ( mean = 0 , sd = 1 , low = 0 , upp = 10 , type = int ):
return truncnorm (
( low - mean ) / sd , ( upp - mean ) / sd , loc = mean , scale = sd )
def truncated_normal_floats ( mean = 0 , sd = 1 , low = 0 , upp = 10 , num = 100 ):
res = truncated_normal ( mean = mean , sd = sd , low = low , upp = upp )
返回 res 。RVS (NUM )
def truncated_normal_ints ( mean = 0 , sd = 1 , low = 0 , upp = 10 , num = 100 ):
res = truncated_normal ( mean = mean , sd = sd , low = low , upp = upp )
返回 res 。RVS (NUM )。类型( np .uint8 )
#项为每个花类的数目:
number_of_items_per_class = [ 190 , 205 , 230 , 170 ]
花 = {}
#FLOS Pythonem:
NUMBER_OF_ITEMS = number_of_items_per_class [ 0 ]
的红色 = truncated_normal_ints (平均值= 254 , SD = 18 , 低= 235 , upp = 256 ,
num = number_of_items )
果岭 = truncated_normal_ints (平均值= 107 , SD = 11 , 低= 88 , UPP = 127 ,
NUM = NUMBER_OF_ITEMS )
蓝调 = truncated_normal_ints (平均值= 0 , SD = 15 , 低= 0 , UPP = 20 ,
NUM = NUMBER_OF_ITEMS )
calyx_dia = truncated_normal_floats ( 3.8, 0.3 , 3.4 , 4.2 ,
num = number_of_items )
data = np . column_stack (( reds , greens , blues , calyx_dia ))
花[ "flos_pythonem" ] = 数据
#FLOS爪哇:
NUMBER_OF_ITEMS = number_of_items_per_class [ 1 ]
的红色 = truncated_normal_ints (平均值= 245 , SD = 17 , 低= 226 , UPP = 256 ,
NUM = NUMBER_OF_ITEMS )
果岭 = truncated_normal_ints (平均值= 107 , SD = 11 , 低= 88 , upp = 127 ,
NUM = NUMBER_OF_ITEMS )
蓝调 = truncated_normal_ints (平均值= 0 , SD = 10 , 低= 0 , UPP = 20 ,
NUM = NUMBER_OF_ITEMS )
calyx_dia = truncated_normal_floats (3.3 , 0.3 , 3.0 , 3.5 ,
NUM = NUMBER_OF_ITEMS )
数据 = NP 。column_stack ((红色, greens , blues , calyx_dia ))
花[ "flos_java" ] = 数据
#FLOS爪哇:
NUMBER_OF_ITEMS = number_of_items_per_class [ 2 ]
红色 = truncated_normal_ints (平均值= 206 , SD = 17 , 低= 175 , UPP = 238 ,
NUM = NUMBER_OF_ITEMS )
果岭 = truncated_normal_ints (平均= 99 , SD = 14 , 低= 80 , upp = 120 ,
NUM = NUMBER_OF_ITEMS )
蓝调 = truncated_normal_ints (平均值= 1 , SD = 5 , 低= 0 , UPP = 12 ,
NUM = NUMBER_OF_ITEMS )
calyx_dia = truncated_normal_floats (4.1 , 0.3 , 3.8 , 4.4 ,
NUM = NUMBER_OF_ITEMS )
数据 = NP 。column_stack ((红色, greens , blues , calyx_dia ))
花[ "flos_margarita" ] = 数据
#FLOS artificialis:
NUMBER_OF_ITEMS = number_of_items_per_class [ 3 ]
的红色 = truncated_normal_ints (平均值= 255 , SD = 8 , 低= 2245 , UPP = 2255 ,
NUM = NUMBER_OF_ITEMS )
果岭 = truncated_normal_ints (平均值= 254 , SD = 10 , 低= 240 , 向上= 255,
NUM = NUMBER_OF_ITEMS )
蓝调 = truncated_normal_ints (平均值= 101 , SD = 5 , 低= 90 , UPP = 112 ,
NUM = NUMBER_OF_ITEMS )
calyx_dia = truncated_normal_floats (2.9 , 0.4 , 2.4 , 3.5 ,
NUM = NUMBER_OF_ITEMS )
数据 = NP 。column_stack ((reds , greens , blues , calyx_dia ))
花[ "flos_artificialis" ] = 数据
数据 = np 。连接((花[ “flos_pythonem” ],
花[ “flos_java” ],
花[ “flos_margarita” ],
花[ “flos_artificialis” ]
), 轴= 0 )
# 分配标签
target = np . zeros ( sum ( number_of_items_per_class )) # 4 朵花
previous_end = 0
for i in range ( 1 , 5 ):
num = number_of_items_per_class [ i - 1 ]
beg = previous_end
target [ beg : beg + num ] += i
previous_end = beg + num
conc_data = np . 连接(( data , target . reshape ( target . shape [ 0 ], 1 )),
axis = 1 )
NP . savetxt ( "data/strange_flowers.txt" , conc_data , fmt = " %2.2f " ,)
导入 matplotlib.pyplot 作为 plt
target_names = 列表(花朵。键())
feature_names = [ '红' , '绿色' , '蓝' , '花萼' ]
ñ = 4
无花果, 斧 = PLT 。子图( n , n , figsize = ( 16 , 16 ))
颜色 = [ '蓝色' 、 '红色' 、 '绿色' 、 '黄色' ]
for x in range ( n ):
for y in range ( n ):
xname = feature_names [ x ]
yname = feature_names [ y ]
for color_ind in range ( len ( target_names )):
ax [ x , y ] 。分散(数据[目标== color_ind , x ],
数据[ target == color_ind , y ],
label = target_names [ color_ind ],
c = colors [ color_ind ])
轴[ x , y ] 。set_xlabel ( xname )
ax [ x , y ] 。set_ylabel ( yname )
ax [ x , y ] 。图例(loc = '左上' )
PLT 。显示()

使用 Scikit-Learn 生成合成数据
使用 Scikit-Learn 的可能性来创建合成数据要容易得多。
sklearn 中可用的功能可以分为
- 用于分类和聚类的生成器
- 用于创建回归数据的生成器
- 流形学习生成器
- 分解生成器
分类和聚类生成器
我们先从功能make_blobs的sklearn.datasets打造“斑点”状数据分布。通过将 的值设置centers为n_classes,我们确定了 blob 的数量,即集群。n_samples对应于在集群中平均分配的点总数。如果random_state没有设置,我们每次调用函数都会有随机结果。我们将一个 int 传递给这个参数,以便在多个函数调用中重现输出。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
n_classes = 4
数据, 标签 = make_blobs (n_samples = 1000 ,
中心= n_classes ,
random_state = 100 )
标签[: 7 ]
输出:
数组([1, 3, 1, 3, 1, 3, 2])
我们将使用 matplotlib 可视化先前创建的 blob custers:
图, ax = plt 。子图()
颜色 = ('绿色' , '橙色' , '蓝' , “粉红色” )
为 标签 在 范围(n_classes ):
斧。分散( x =数据[标签==标签, 0 ],
y =数据[标签==标签, 1 ],
c =颜色[标签],
s = 40 ,
标签=标签)
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = 'Blob 示例' )
斧头。图例(loc = '右上角' )
输出:

在前面的例子中,blob 的中心是随机选择的。在以下示例中,我们明确设置了 blob 的中心。我们创建一个包含中心点的列表并将其传递给参数centers:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
中心 = [[ 2 , 3 ], [ 4 , 5 ], [ 7 , 9 ]]
数据, 标签 = make_blobs (N_SAMPLES次= 1000 ,
中心= NP 。阵列(中心),
random_state = 1 )
标签[: 7 ]
输出:
数组([0, 1, 1, 0, 2, 2, 2])
让我们看看之前创建的 blob 集群:
图, ax = plt 。子图()
颜色 = ('绿' , '橙' , '蓝' )
为 标签 的 范围(len个(中心)):
斧。分散( x =数据[标签==标签, 0 ],
y =数据[标签==标签, 1 ],
c =颜色[标签],
s = 40 ,
标签=标签)
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = 'Blob 示例' )
斧头。图例(loc = '右上角' )
输出:

通常,您希望将人工创建的数据集保存在文件中。为此,我们可以使用savetxtnumpy 中的函数。在我们这样做之前,我们必须重新排列我们的数据。每行都应包含数据和标签:
将 numpy 导入为 np
标签 = 标签。重塑((标签。形状[ 0 ],1 ))
all_data = NP 。连接((数据, 标签), 轴= 1 )
all_data [:7 ]
输出:
数组([[ 1.72415394, 4.22895559, 0. ],
[ 4.16466507, 5.77817418, 1. ],
[ 4.51441156, 4.98274913, 1. ],
[ 1.49102772, 2.83351405, 0. ],
[ 6.0386362 , 7.57298437, 2. ],
[ 5.61044976, 9.83428321, 2. ],
[ 5.69202866, 10.47239631, 2. ]])
对于某些人来说,理解 reshape 和 concatenate 的组合可能很复杂。因此,您可以在以下代码中看到一个极其简单的示例:
将 numpy 导入为 np
a = np 。数组( [[ 1 , 2 ], [ 3 , 4 ]])
b = np 。数组( [ 5 , 6 ])
b = b 。reshape (( b . shape [ 0 ], 1 ))
打印( b )
x = np 。连接( ( a , b ), 轴= 1 )
x
输出:
[[5]
[6]]
数组([[1, 2, 5],
[3, 4, 6]])
我们使用numpy函数savetxt来保存数据。不要担心这个奇怪的名字,它只是为了好玩,原因很快就会清楚:
NP . savetxt ( "squirrels.txt" ,
all_data ,
fmt = [ ' %.3f ' , ' %.3f ' , ' %1d ' ])
all_data [: 10 ]
输出:
数组([[ 1.72415394, 4.22895559, 0. ],
[ 4.16466507, 5.77817418, 1. ],
[ 4.51441156, 4.98274913, 1. ],
[ 1.49102772, 2.83351405, 0. ],
[ 6.0386362 , 7.57298437, 2. ],
[ 5.61044976, 9.83428321, 2. ],
[ 5.69202866, 10.47239631, 2. ],
[ 6.14017298, 8.56209179, 2. ],
[ 2.97620068, 5.56776474, 1. ],
[ 8.27980017, 8.54824406, 2. ]])
读取数据并将其转换回“数据”和“标签”
我们将展示现在,如何在数据再次读取以及如何将其拆分成data和labels再次:
文件数据 = np 。loadtxt ( "squirrels.txt" )
数据 = file_data [:,:- 1 ]
标签 = file_data [:,2 :]
标签 = 标签。重塑((标签。形状[ 0 ]))
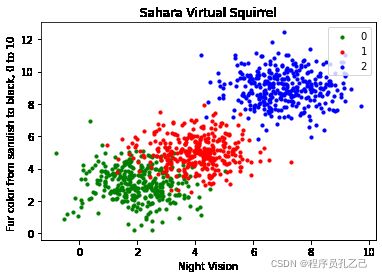
我们将数据文件称为squirrels.txt,因为我们想象了一种生活在撒哈拉沙漠中的奇怪动物。x 值代表动物的夜视能力,y 值对应毛皮的颜色,从浅褐色变为黑色。我们有3种松鼠,0、1和2。(注意我们的松鼠是想象中的松鼠,与真正的撒哈拉松鼠没有任何关系!)
导入 matplotlib.pyplot 作为 plt
颜色 = (“绿色” 、 “红色” 、 “蓝色” 、 “洋红色” 、 “黄色” 、 “青色” )
n_classes = 3
图, ax = plt 。副区()
为 n_class 在 范围(0 , n_classes ):
斧。分散(数据[标签== n_class , 0 ], 数据[标签== n_class , 1 ],
c =颜色[ n_class ], s = 10 , 标签= str (n_class ))
斧头。set ( xlabel = 'Night Vision' ,
ylabel = '毛色从浅褐色到黑色, 0 到 10 ' ,
title = 'Sahara Virtual Squirrel' )
斧头。图例(loc = '右上角' )
输出:
我们将在以下代码中训练我们的人工数据:
从 sklearn.model_selection 导入 train_test_split
data_sets = train_test_split ( data ,
labels ,
train_size = 0.8 ,
test_size = 0.2 ,
random_state = 42 #保证每次运行的输出相同
)
train_data , test_data , train_labels , test_labels = data_sets
#
从 sklearn.neighbors 导入 模型import KNeighborsClassifier
# 创建分类器
knn = KNeighborsClassifier ( n_neighbors = 8 )
# 训练
knn 。适合(train_data , train_labels )
# 对测试数据进行测试:
calculated_labels = knn . 预测(测试数据)
计算标签
输出:
数组([2., 0., 1., 1., 0., 1., 2., 2., 2., 2., 0., 1., 0., 0., 1., 0. , 1.,
2., 0., 0., 1., 2., 1., 2., 2., 1., 2., 0., 0., 2., 0., 2., 2., 0. ,
0., 2., 0., 0., 0., 1., 0., 1., 1., 2., 0., 2., 1., 2., 1., 0., 2. ,
1., 1., 0., 1., 2., 1., 0., 0., 2., 1., 0., 1., 1., 0., 0., 0., 0. ,
0., 0., 0., 1., 1., 0., 1., 1., 1., 0., 1., 2., 1., 2., 0., 2., 1. ,
1., 0., 2., 2., 2., 0., 1., 1., 1., 2., 2., 0., 2., 2., 2., 2., 0. ,
0., 1., 1., 1., 2., 1., 1., 1., 0., 2., 1., 2., 0., 0., 1., 0., 1. ,
0., 2., 2., 2., 1., 1., 1., 0., 2., 1., 2., 2., 1., 2., 0., 2., 0. ,
0., 1., 0., 2., 2., 0., 0., 1., 2., 1., 2., 0., 0., 2., 2., 0., 0. ,
1., 2., 1., 2., 0., 0., 1., 2., 1., 0., 2., 2., 0., 2., 0., 0., 2. ,
1., 0., 0., 0., 0., 2., 2., 1., 0., 2., 2., 1., 2., 0., 1., 1., 1. ,
0., 1., 0., 1., 1., 2., 0., 2., 2., 1., 1., 1., 2.])
从 sklearn 导入 指标
打印(“精度:” , 度量。accuracy_score (test_labels , calculated_labels ))
输出:
准确度:0.97
其他有趣的分布
将 numpy 导入为 np
将 sklearn.datasets 导入为 ds
数据, 标签 = ds 。make_moons ( n_samples = 150 ,
shuffle = True ,
噪音= 0.19 ,
random_state = None )
数据 += np 。阵列(- NP 。ndarray 。分钟(数据[:,0 ]),
- NP 。ndarray 。分钟(数据[:,1 ))
NP . 数组。min ( data [:, 0 ]), np . 数组。分钟(数据[:, 1 ])
输出:
(0.0, 0.43385925898113253)
导入 matplotlib.pyplot 作为 plt
fig , ax = plt 。子图()
斧头。分散(数据[标签== 0 , 0 ], 数据[标签== 0 , 1 ],
c = 'orange' , s = 40 , label = 'oranges' )
ax . 散射(数据[标签== 1 , 0 ], 数据[标签== 1 , 1 ],
c ^ = '蓝', s = 40 , 标签= 'blues' )
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = 'Moons' )
#ax.legend(loc='右上角');
输出:

我们想要缩放范围内范围内[min, max]的值[a, b]。
F(X)=(乙-一个)⋅(X-米一世n)米一个X-米一世n+一个
我们现在使用此公式将 的 X 和 Y 坐标data转换为其他范围:
min_x_new , max_x_new = 33 , 88
min_y_new , max_y_new = 12 , 20
数据, 标签 = ds 。make_moons ( n_samples = 100 ,
shuffle = True ,
噪音= 0.05 ,
random_state = None )
min_x , min_y = np 。数组。min ( data [:, 0 ]), np . 数组。min ( data [:, 1 ])
max_x , max_y = np 。数组。最大(数据[:,0 ]), np 。数组。最大值(数据[:, 1 ])
#data -= np.array([min_x, 0])
#data *= np.array([(max_x_new - min_x_new) / (max_x - min_x), 1])
#data += np.array([min_x_new, 0 ])
#data -= np.array([0, min_y])
#data *= np.array([1, (max_y_new - min_y_new) / (max_y - min_y)])
#data += np.array([0, min_y_new ])
数据 -= np 。数组([ min_x , min_y ])
数据 *= np 。数组([( max_x_new - min_x_new ) / ( max_x - min_x ), ( max_y_new - min_y_new ) / ( max_y - min_y )])
数据 += np 。数组([ min_x_new , min_y_new ])
#np.ndarray.min(data[:,0]), np.ndarray.max(data[:,0])
数据[: 6 ]
输出:
数组([[88., 15.90901932],
[60.360365, 18.79100903],
[49.63581889, 17.39619093],
[87.04094705, 17.48341055],
[54.70782513, 19.39948339],
[45.93282226, 19.58274387]])
DEF scale_data (数据, new_limits , 就地=假 ):
如果 不 就地:
数据 = 数据。copy ()
min_x , min_y = np . 数组。min ( data [:, 0 ]), np . 数组。min ( data [:, 1 ])
max_x , max_y = np 。数组。最大(数据[:,0 ]), np 。数组。max ( data [:, 1 ])
min_x_new , max_x_new = new_limits [ 0 ]
min_y_new , max_y_new = new_limits [ 1 ]
data -= np 。数组([ min_x , min_y ])
数据 *= np 。数组([( max_x_new - min_x_new ) / ( max_x - min_x ), ( max_y_new - min_y_new ) / ( max_y - min_y )])
数据 += np 。阵列([ min_x_new , min_y_new ])
如果 就地:
返回 无
其他:
返回 数据
数据, 标签 = ds 。make_moons ( n_samples = 100 ,
shuffle = True ,
噪音= 0.05 ,
random_state = None )
scale_data ( data , [( 1 , 4 ), ( 3 , 8 )], inplace = True )
data [: 10 ]
输出:
数组([[4. , 6.15406088],
[3.39866042, 3.67397656],
[2.48929457, 3.53253909],
[1.91445947, 8. ],
[2.91169101, 5.66862954],
[1.945163, 7.73094901],
[1.77272979, 7.98946409],
[1.74802092, 7.53443605],
[2.13143418, 5.0679138],
[2.96740593, 4.69559235]])
图, ax = plt 。子图()
斧头。分散(数据[标签== 0 , 0 ], 数据[标签== 0 , 1 ],
c = 'orange' , s = 40 , label = 'oranges' )
ax . 散射(数据[标签== 1 , 0 ], 数据[标签== 1 , 1 ],
c ^ = '蓝', s = 40 , 标签= 'blues' )
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = 'moons' )
斧头。图例( loc = '右上角' );

将 sklearn.datasets 导入为 ds
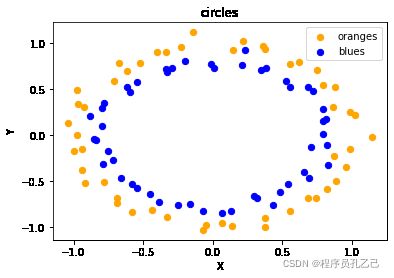
数据, 标签 = ds 。make_circles ( n_samples = 100 ,
shuffle = True ,
噪声= 0.05 ,
random_state = None )
图, ax = plt 。子图()
斧头。分散(数据[标签== 0 , 0 ], 数据[标签== 0 , 1 ],
c = 'orange' , s = 40 , label = 'oranges' )
ax . 散射(数据[标签== 1 , 0 ], 数据[标签== 1 , 1 ],
c ^ = '蓝', s = 40 , 标签= 'blues' )
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = 'circles' )
斧头。图例(loc = '右上角' )
输出:
打印(__doc__ )
导入 matplotlib.pyplot 作为 plt
从 sklearn.datasets 导入 make_classification
从 sklearn.datasets 导入 make_blobs
从 sklearn.datasets 导入 make_gaussian_quantiles
PLT 。图( figsize = ( 8 , 8 ))
plt . subplots_adjust (底部=. 05 , 顶部=. 9 , 左=. 05 , 右=. 95 )
PLT 。子图( 321 )
plt 。标题(“一个信息特征,每个类一个集群” , 字体大小= 'small' )
X1 , Y1 = make_classification (n_features = 2 , n_redundant = 0 , n_informative = 1 ,
n_clusters_per_class = 1 )
plt 。分散( X1 [:, 0 ], X1 [:, 1], 标记= 'o' , c = Y1 ,
s = 25 , edgecolor = 'k' )
PLT 。子图( 322 )
plt 。标题(“两个信息特征,每个类一个集群” , 字体大小= 'small' )
X1 , Y1 = make_classification (n_features = 2 , n_redundant = 0 , n_informative = 2 ,
n_clusters_per_class = 1 )
plt 。分散( X1 [:, 0 ], X1 [:, 1], 标记= 'o' , c = Y1 ,
s = 25 , edgecolor = 'k' )
PLT 。子图( 323 )
plt 。标题(“两个信息特征,每类两个集群” ,
字体大小= 'small' )
X2 , Y2 = make_classification (n_features = 2 ,
n_redundant = 0 ,
n_informative = 2 )
plt 。分散( X2 [:, 0 ], X2 [:, 1 ], 标记= 'o' , c = Y2 ,
s = 25 , edgecolor = 'k' )
PLT 。子图( 324 )
plt 。标题(“多类,两个信息特征,一个集群” ,
fontsize = 'small' )
X1 , Y1 = make_classification (n_features = 2 ,
n_redundant = 0 ,
n_informative = 2 ,
n_clusters_per_class = 1 ,
n_classes = 3 )
plt 。分散( X1 [:, 0], X1 [:, 1 ], 标记= 'o' , c = Y1 ,
s = 25 , edgecolor = 'k' )
PLT 。子图( 325 )
plt 。title ( "Gaussian 分为三个分位数" , fontsize = 'small' )
X1 , Y1 = make_gaussian_quantiles ( n_features = 2 , n_classes = 3 )
plt . 分散( X1 [:, 0 ], X1 [:, 1 ], 标记= 'o' , c = Y1 ,
s =25 , 边缘颜色= 'k' )
PLT 。显示()
输出:

练习
练习 1
创建两个与此类似的集群:

两个测试集可以用没有偏置节点的感知器分离。
练习 2
创建两个类似于下图的集群:

练习 3
创建一个包含五个类“Tiger”、“Lion”、“Penguin”、“Dolphin”和“Python”的数据集。这些集合应该类似于下图:

解决方案
练习 1 的解决方案
数据, 标签 = make_blobs ( n_samples = 100 ,
cluster_std = 0.5 ,
中心= [[ 1 , 4 ] ,[ 4 , 1 ]],
random_state = 1 )
图, ax = plt 。子图()
颜色 = [ “橙” , “绿” ]
LABEL_NAME = [ “虎” , “狮子” ]
为 标签 在 范围(0 , 2 ):
斧。分散(数据[标签==标签, 0 ], 数据[标签==标签, 1 ],
c =颜色[标签], s = 40 , 标签= label_name [标签])
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = '数据集' )
斧头。图例(loc = '右上角' )
输出:

练习 2 的解决方案
数据, 标签 = make_blobs ( n_samples = 100 ,
cluster_std = 0.5 ,
中心= [[ 2 , 2 ] ,[ 4 , 4 ]],
random_state = 1 )
图, ax = plt 。子图()
颜色 = [ “橙” , “绿” ]
LABEL_NAME = [ “火腿” , “垃圾邮件” ]
为 标签 在 范围(0 , 2 ):
斧。分散(数据[标签==标签, 0 ], 数据[标签==标签, 1 ],
c =颜色[标签], s = 40 , 标签= label_name [标签])
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = '数据集' )
斧头。图例(loc = '右上角' )
输出:

练习 3 的解答
将 sklearn.datasets 导入为 ds
数据, 标签 = ds 。make_circles ( n_samples = 100 ,
shuffle = True ,
噪声= 0.05 ,
random_state = 42 )
中心 = [[ 3 , 4 ], [ 5 , 3 ], [ 4.5 , 6 ]]
DATA2 , 标签2 = make_blobs (N_SAMPLES次= 100 ,
cluster_std = 0.5 ,
中心=中心,
random_state = 1 )
对于 我 在 范围(len个(中心)- 1 , - 1 , - 1 ):
标签2 [标签2 == 0 +我] = 我+ 2
打印(标签2 )
标签 = np 。连接([ labels , labels2 ])
data = data * [ 1.2 , 1.8 ] + [ 3 , 4 ]
数据 = np 。串连([数据, DATA2 ], 轴= 0 )
输出:
[2 4 4 3 4 4 3 3 2 4 4 2 4 3 4 2 4 4 4 4 2 2 4 4 3 2 2 3 2 2 3 2 3 3 3 3
3 4 3 3 2 3 3 3 2 2 2 2 3 4 4 4 2 4 3 3 2 2 3 4 4 3 3 4 2 4 2 4 3 3 4 2 2
3 4 4 2 3 2 3 3 4 2 2 2 2 3 2 4 2 2 3 3 4 4 2 2 4 3]
图, ax = plt 。子图()
颜色 = [ “橙” , “蓝” , “品红色” , “黄色” , “绿色” ]
LABEL_NAME = [ “老虎” , “狮子” , “企鹅” , “海豚” , “的Python” ]
为 标签 在 范围( 0 , len (中心) + 2 ):
ax 。分散(数据[标签==标签, 数据[标签==标签, 1 ],
c =颜色[标签], s = 40 , 标签= label_name [标签])
斧头。设置(xlabel = 'X' ,
ylabel = 'Y' ,
title = '数据集' )
斧头。图例(loc = '右上角' )
输出:
