前言
现在的数据库种类越来越多,数据库备份的格式也越来越复杂,所以数据格式化一直是一个老生常谈的问题。据库备份文件格式那么多,既有SQL的,也有BAK的,还有TXT的等。数据库种类也有很多,MySQL,Oracle,SQL server等,怎么对这些数据库进行管理?昨天泄露access格式的数据库,今天泄露了excel格式的数据库,明天又泄露了SQL格式的数据库。要格式化那么多种类的数据库,压力山大啊!搭建个本地的数据库怎么那么复杂?
这里就要说到kettle。首先得说说Pentaho这个企业。Pentaho主要致力于大数据的分析,整理和管理,并且这家公司开发出来的工具是开源的!没错,就是开源的。任何人都可以查看这个项目的源代码,并且对其进行更改和研究。这家公司开发了很多管理工具或者框架,最为出名的就是kettle了。Kettle是一款国外开源的ETL工具,纯java编写,可以在Window、Linux、Unix上运行,数据抽取高效稳定。ELT的全称为Extraction, Transformation Loading,其中文解释为提取,转换和加载。Kettle这个工具里面有SPOON,PAN,CHEF,Encr和KITCHEN这么五个基本组建。
SPOON 允许你通过图形界面来设计ETL转换过程(Transformation)。
PAN 允许你批量运行由Spoon设计的ETL转换 (例如使用一个时间调度器)。Pan是一个后台执行的程序,没有图形界面。
CHEF 允许你创建任务(Job)。 任务通过允许每个转换,任务,脚本等等,更有利于自动化更新数据仓库的复杂工作。任务通过允许每个转换,任务,脚本等等。任务将会被检查,看看是否正确地运行了。
KITCHEN 允许你批量使用由Chef设计的任务 (例如使用一个时间调度器)。KITCHEN也是一个后台运行的程序。
Encr 此脚本是用来加密连接数据库密码与集群时使用的密码
今天我们主要讲的是SPOON,这里会做一个基础的讲解,以便达到抛砖引玉的作用。
1.基本安装
由于Kettle是由JAVA代码所编写的,所以大家要运行Kettle首先是下载安装JDK并且设置好环境变量。Kettle的下载地址是“传送门”。
下载完成后,你会得到一个RAR压缩包,请对压缩包进行解压。
解压完成后在文件更目录内,你可以看到几个bat文件和sh文件,这里就是kettle工具的打开的方式。

这里做个常识普及。
windows系统的用户请用bat文件打开kettle
linux系统的用户请用sh文件打开kettle
这里主要说的是kettle spoon的一个基本讲解。运行spoon.bat或者spoon.sh后等待几秒钟就可以看到kettle spoon的基本界面了。
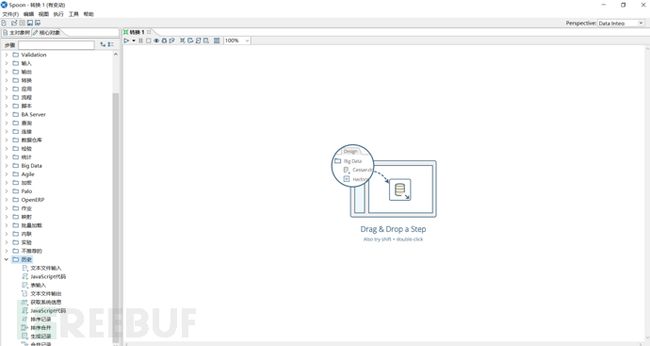
2.基本建模
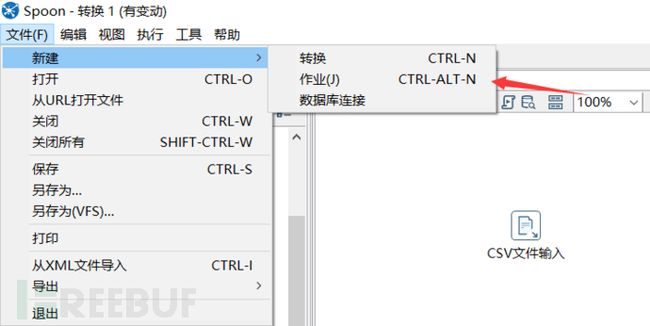
新建作业
在开始对数据管理之前,我们需要新建一个作业。点击文件,新建中的作业选项,产生出一个作业。
在核心对象这里,我们可以看到kettle spoon中非常主要的几个基本功能和模块。
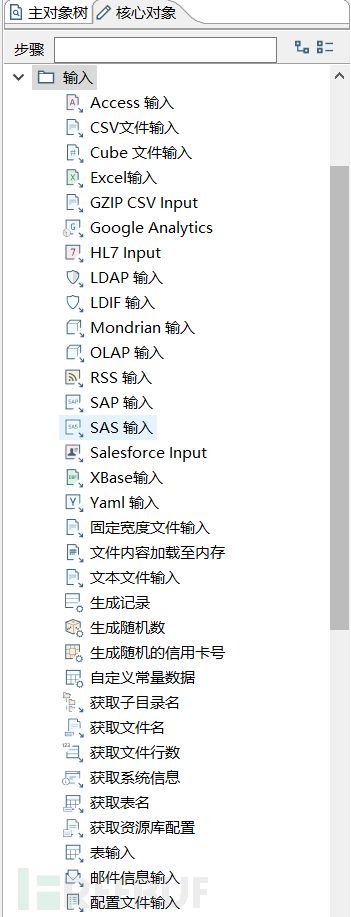
数据输入
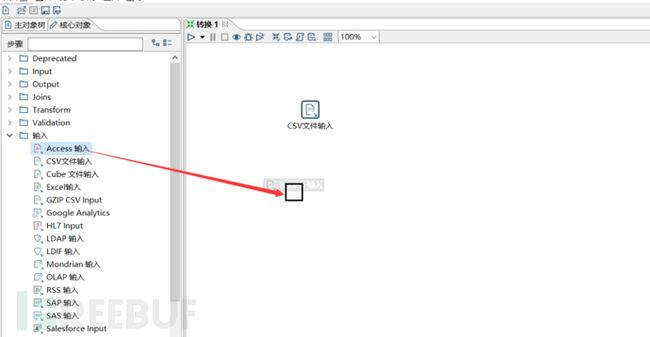
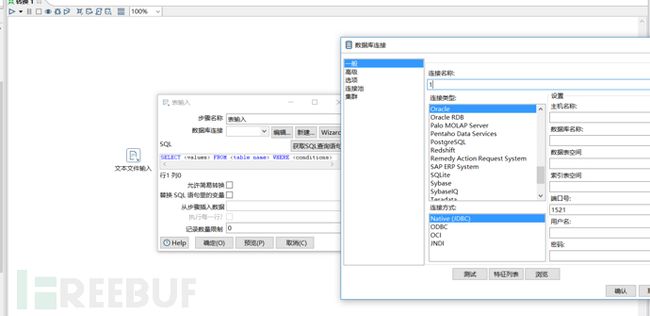
数据库的备份格式有很多,有bak,sql,txt,csv等等。这里需要对这些文件有一个基本的管理,这里就扯到了数据库输入模块,我们得先把自己的输入模块建立好。下面这张图是kettle spoon上几个输入的基本模块。
这里对输入模块做个基本的操作教程,我们先来看看对数据库备份文件怎么进行输入的。鼠标左键单击一个模块拖动到作业方框内就可以对这个模块进行编辑。
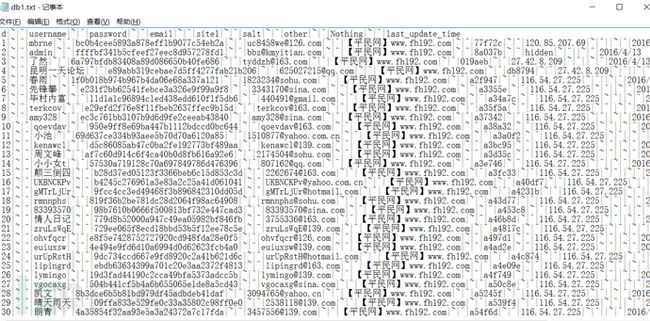
假设我要对一个txt格式的泄露数据库进行入库,那么首先应该查看的是字段的分隔符和限定符。
然后拖动一个文本文件输入模块到作业内。
双击这个模块对其进行设置。
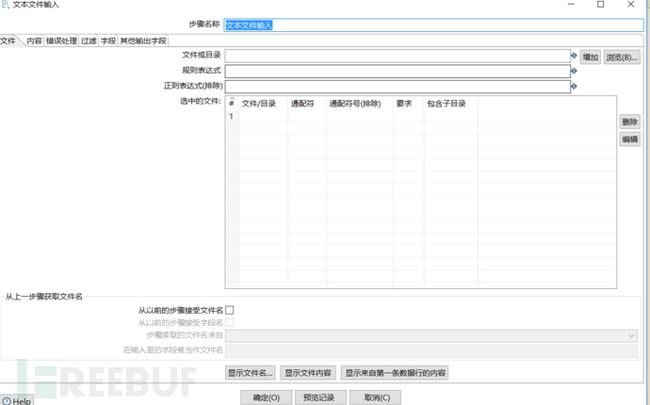
然后点击浏览,选择要导入的数据库文件,然后点击增加。
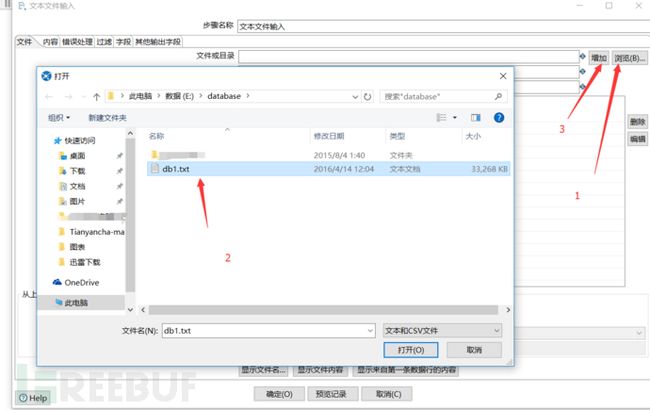
通过上图已经知道了数据库字段的分隔符,在内容处填写好分隔符。这里除了分隔符的设置还可以设置文本显示格式,限定符等等。
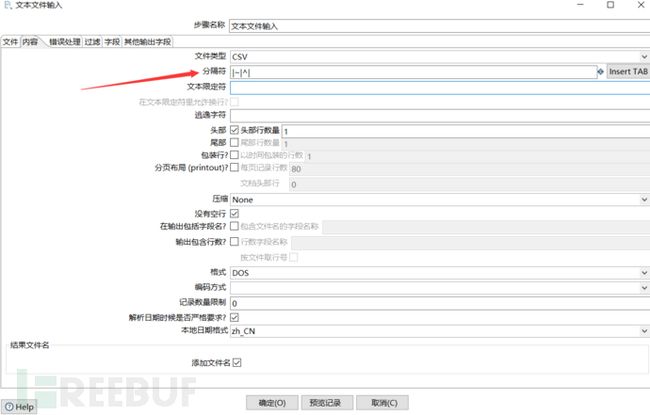
然后就是获取table表格。在这个设置内,你还可以对table表的表名进行编辑。
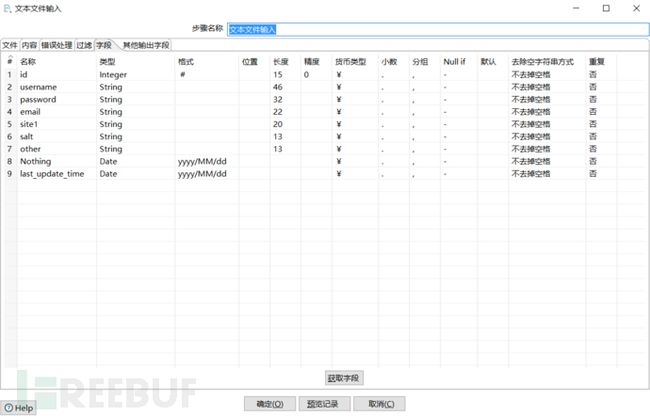
在设置完成后,我们需要预览一下整个table表,查看自己的设置是否正确。
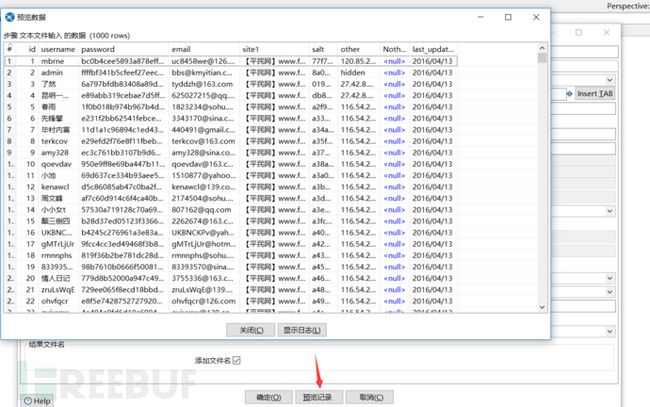
当然,这里只是一个非常简单的txt无加密备份的数据库,KettleSpoon还提供Accesss,SQL,CSV等数据输入格式,甚至还提供数据库对数据库输入。比如你要把oracle数据库中的数据输入到mysql的数据库中,你可能需要先把数据备份下来,整理好后在导入到mysql数据库中。但是在kettle spoon中,你可以直接在数据流中进行传输,直接省去了中间的这一步。在表输入模块中可以使用这个功能。
数据加工
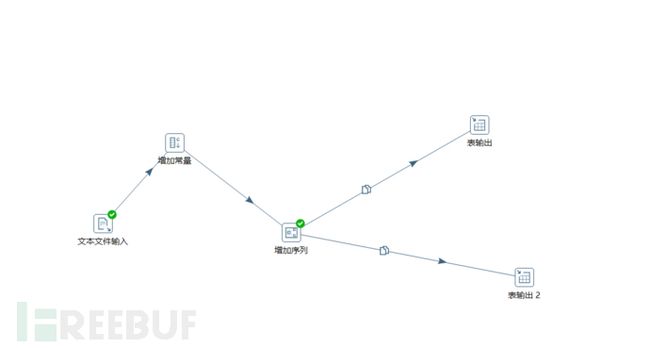
通过上面的步骤,已经成功的把数据输入进来,但是我们还需要对数据进行整理。比如增加序列,增加字段,数据加密等。这里再继续举个例子。因为本地数据库有海量的数据,所以就需要做数据索引。索引数据有个很关键的地方就是ID,每一条数据需要不同的ID进行索引,而且ID的值还不能是普通的int类型,必须是bigint类型。这里需要对海量的数据进行一个规范的整理和加工。
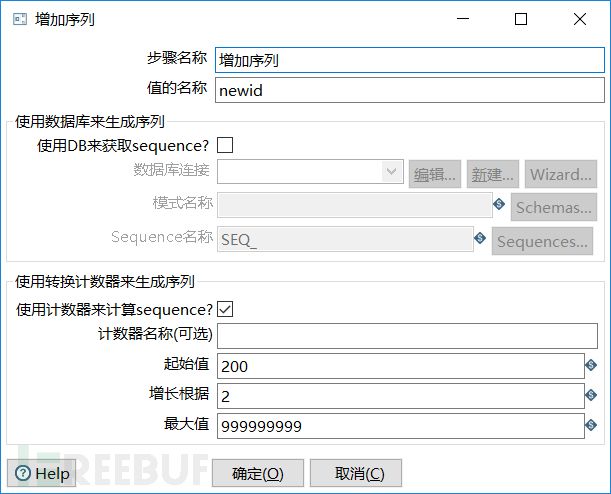
假设我的数据库中已经有199条数据了,我需要对新的每条数据重新做一个ID序列,ID起始值为200,每条数据之间的ID值增加两个数字。虽然感觉很复杂,但是kettle spoon却可以很轻易的解决这个问题。
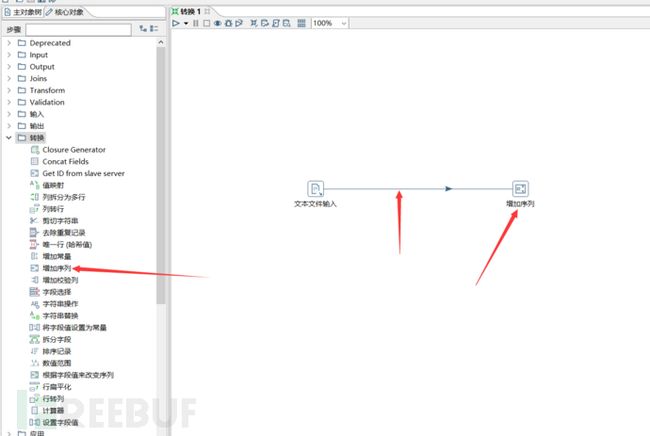
从转换处拖出一个增加序列模块到作业内,然后鼠标左键单击文本文件输入模块,并且按住shift键不放,同时往任意方向上拖动鼠标,这个时候你会看到一条线。把它链接到增加序列模块。
双击增加序列模块进入到设置界面,在值的名称那里设置字段名称为newid。因为ID的起始值是200,所以起始值设置成200。因为每条数据之间的ID增加两个数字,所以增长根据这里设置成2。最后点击确定。
这样一个增加序列的设置就完成了。当然这个例子只是一个非常简单的功能,里面有很多数据处理的功能等着大家一一尝试。
数据输出
数据输入也有了,加工步骤也有了,那么该对数据进行输出了。在数据输出的时候可能大家会对其有一些要求,比如我不想要某些字段,或者我想设置数据的格式等。这里kettle都可以帮助到你。Kettle甚至提供了多种数据输出的模块,大家可以查其输出菜单。
这里还是继续举一下刚才的例子。假设新的数据我只要刚才的新生成的ID,Usename和password字段,其它的我都不要,并且数据要输出到excel表格内,而且数据的字体是Arial,大小是10。
那么我们可以先建立一个excel输出模块,然后该模块需要与之前的增加序列模块进行连接。
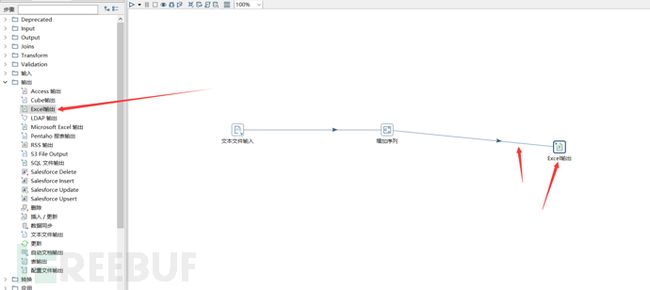
随后双击excel模块进行设置。在浏览那里选择excel的保存路径。
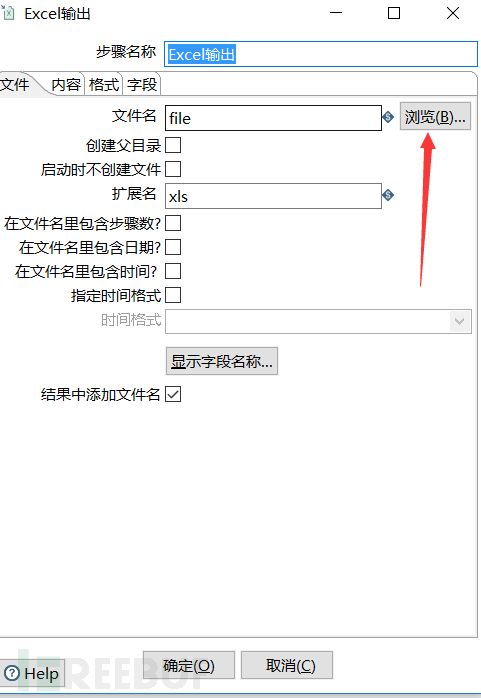
然后在格式这里设置excel的字体格式等。
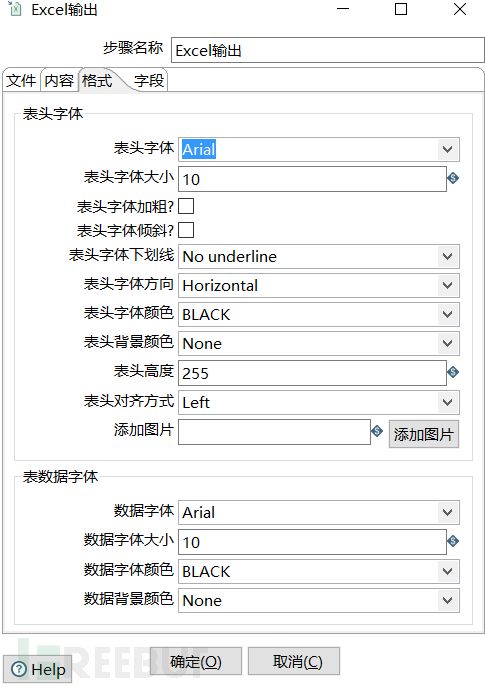
然后在字段这里先选择获取字段,然后删除不想要的字段,并且对字段进行排序。
然后点击左上角的开始即可开始对数据的输出
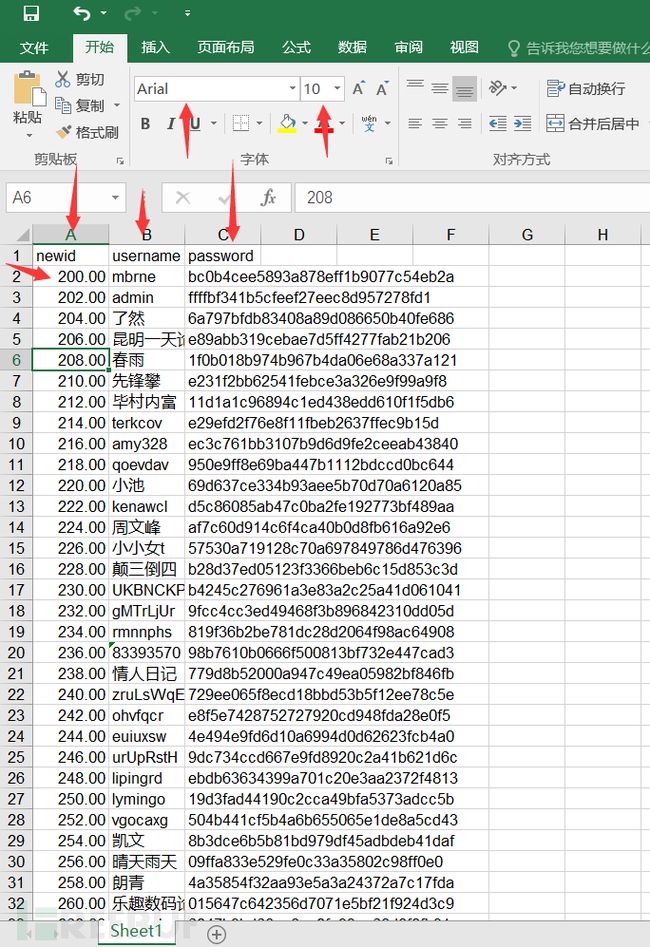
下图是整理后的数据。可以看到数据的ID从200开始,并且每条数据增加两个数字。同时字段要求和字体格式要求都已经达到。因为我自己的excel的设置问题,所有的数字后面都会有两个小数据点,这个不影响。
总结
实际上刚才展示的只是一个非常基础的kettle数据建模,还有更加复杂的,我给大家展示一下
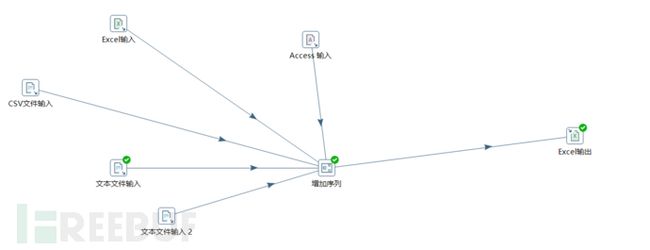
多备份数据库输入到单一excel文件内
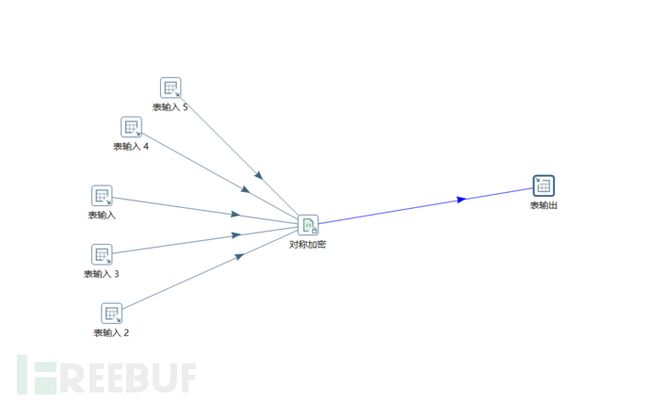
多数据在线同步并且加密到异地服务器内
单一文件增加常量和序列并且同时同步到多个数据库内
Kettle非常的强大,而这篇文章所说到的只是kettle spoon,还有pen,chef等。这篇文章主要是做一个抛砖引玉的作用,让大家能够了解并且初步使用kettle这个工具。kettle不只是可以做到基本的数据入库和整理,你甚至还可以写自己的数据管理模块,脚本,并且运用在kittle内,比如数据匹配模块,数据分发模块等。