超详解transformer(附图)
参考paper: Attention is all you need
发现一篇比较不错的讲transformer的文章,英文原版在这里。
现把它整理一下,有些词便于理解保留英文原单词。
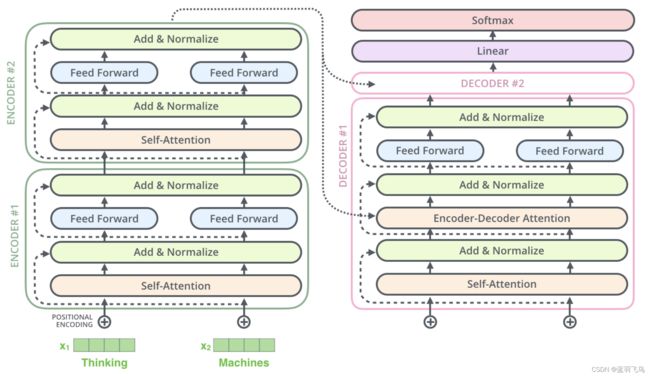
Transformer的high level look
需要翻译的句子(法语)进入transformer后,出来翻译后的句子(英语)。
 进入transformer, 看到它是由encoding部分和decoding部分构成
进入transformer, 看到它是由encoding部分和decoding部分构成
 进一步拆解,每个encoding部分由一系列的encoder构成(paper中是6个,当然这个数字也可以调整),decoding部分由相同数量的decoder构成。
进一步拆解,每个encoding部分由一系列的encoder构成(paper中是6个,当然这个数字也可以调整),decoding部分由相同数量的decoder构成。
 encoder们的结构是相同的(但是它们不共享参数),每个encoder又由两部分组成。
encoder们的结构是相同的(但是它们不共享参数),每个encoder又由两部分组成。
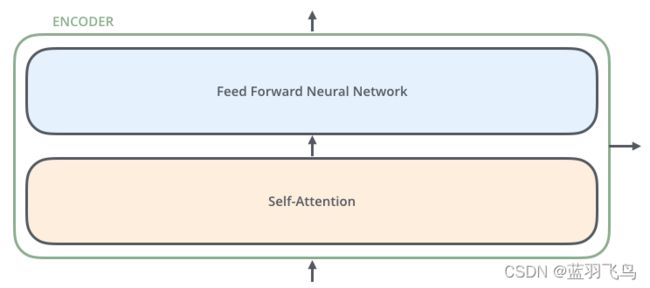 encoder的input先进入self attention层,在过一个单词时,这个self attention可以同时关注句子里的其他单词,该层的输出会进入到feed-forward网络,每个位置的单词都会有一个完全相同的feed-forward网络。
encoder的input先进入self attention层,在过一个单词时,这个self attention可以同时关注句子里的其他单词,该层的输出会进入到feed-forward网络,每个位置的单词都会有一个完全相同的feed-forward网络。
decorder也有encoder的两层,同时在两层之间还有一个attention层,帮助decoder聚焦在句子相关的部分上。
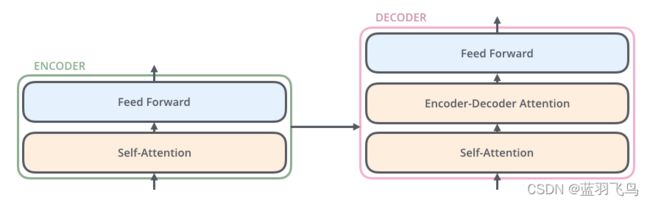
具体示例
下面来看一个input如何经过transformer而得到output。
假设输入一个句子,含有2个单词,首先把单词转为word embedding,是self attention层的输入,z是self attention的输出。
(训练的时候长度由训练集中最长的句子决定)
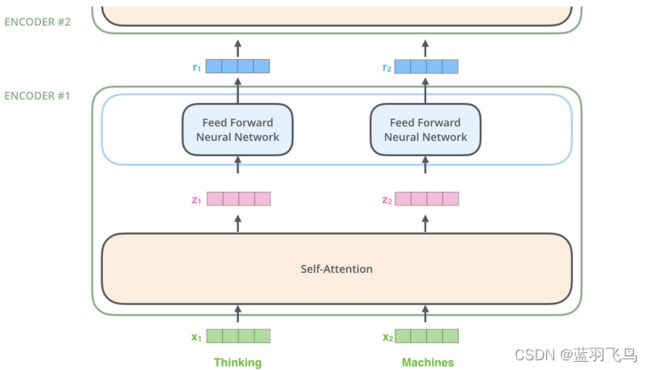
可以看到各单词是同时进入encoder的,它们在self attention层中有联系,但是在feed forward层是各自独立的(因为每个位置单独有一个feed forward层),在feed forward层可以并行处理。
Self Attention层
直观上理解,比如有这么个句子
”The animal didn’t cross the street because it was too tired”
那么其中的it指的是谁呢?是animal还是street?
当模型处理单词 it 时,self attention会把它和animal关联,如下图
处理每一个单词时,self attention都会把它和其他的单词关联,以更好地encoding
 下面开始说self attention的细节了
下面开始说self attention的细节了
第一步,从word embedding得到3个向量,即Query, Key, Value向量,简单解释下这3个的意义,
query是查询向量,在需要翻译的时候,word embedding转换成查询向量。query和不同单词的key进行matching,可以得到匹配度,也就是attention的score。不同单词的value向量和对应的score相乘求和,会得到输出向量。具体在后面会有解释。
Q,K,V这3个向量是由word embedding分别和3个矩阵相乘得到的,3个矩阵是在训练中得到。目前embedding和encoder input/output是512维,Q,K,V向量是64维(它们不是必须比embedding维度小)。

self attention是要给每个词计算一个score,score的大小表示对这个词付出的注意力的大小。
score的计算方法:
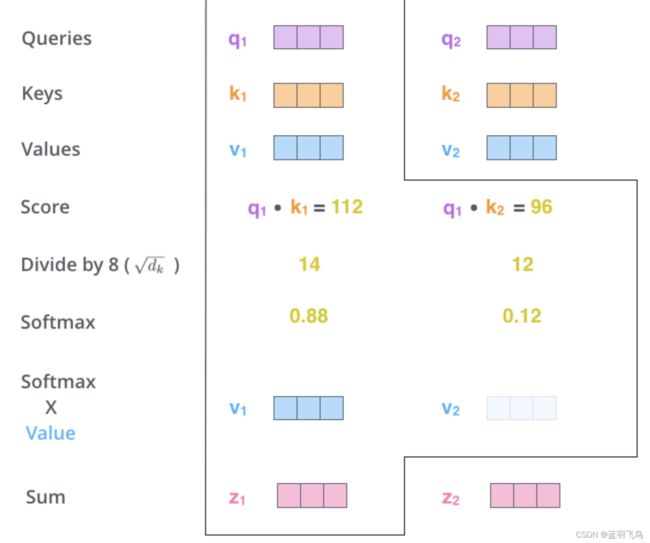
比如我们正在处理#1单词,想看#1对#1和#2分别关联有多大,也就是#1对#1的score,#1对#2的score.
这时用#1的query vector分别乘#1和#2的key vector,看matching程度,得到一个数字(这个数字再经过softmax才是score),见下图
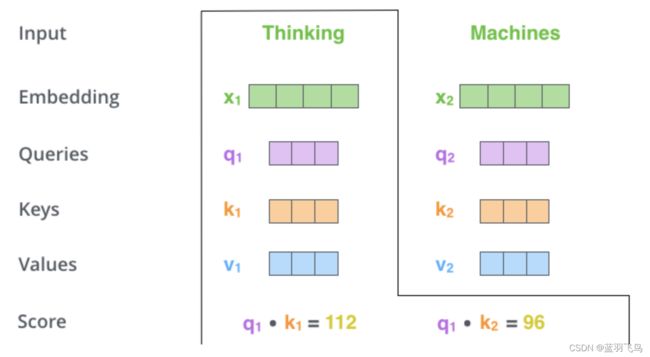
上面得到的数字要除以8(paper中key vector的维度是64,即64的开方),这样做可以得到更稳定的梯度(当然也可以换成其他除数)。将得到的数字进行softmax计算,得到score

上面经过softmax之后的score就表示pay多少attention了。
下一步是把每个Value vector乘以对应的score,然后求和,得到的就是self attention层对当前#1位置的输出。这步操作的目的是提高score高的单词的分数,滤掉score低的单词。输出向量z会是feed forward层的输入。
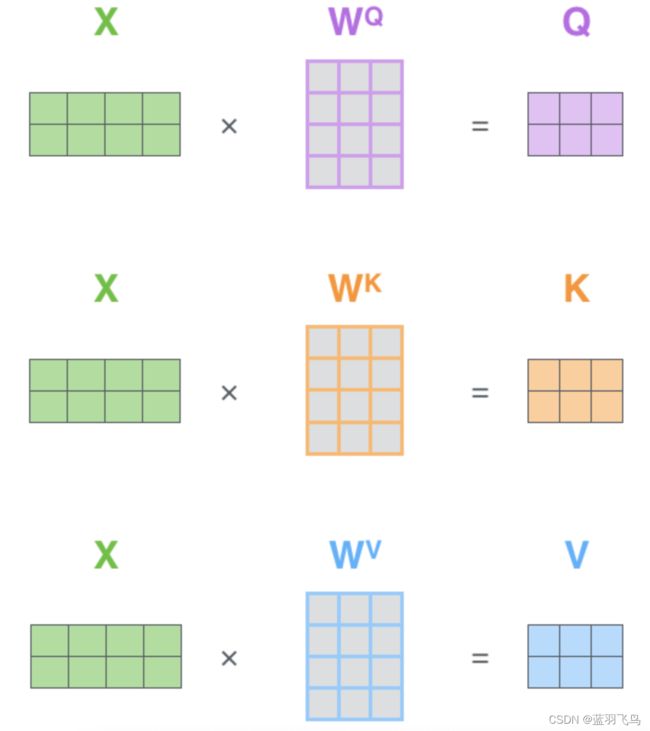
在实际中,上面的步骤是以矩阵形式实现的,如下:
把整个句子的单词的word embedding向量压缩到一个矩阵,分别乘以训练得到的3个矩阵WQ,WK,WV,得到Query,Key,Value矩阵。
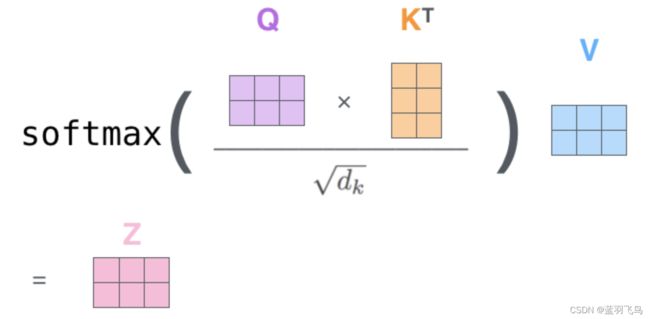
同样的,计算query和key分别匹配,用softmax得到score,再用value向量和对应的score相乘求和,得到self attention的输出Z向量。
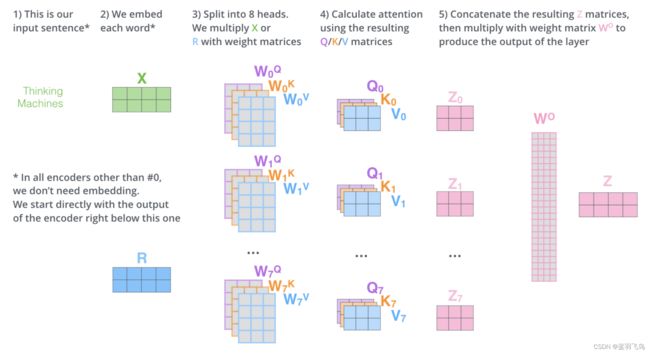
多头注意力机制
多头注意力机制相比于attention,有以下改进
- 上面的操作可以看到,在每一个位置处的单词,都计算它和其他单词的关联程度,但是不管怎么说,它肯定和它自己是最关联的。在“The animal didn’t cross the street because it was too tired”这个例子中,attention可以帮助我们判断it和哪个主语关联。多头注意力机制拓展了这种能力,可以判断不同位置的单词和其他词的关联。
- 可以给attention层提供多个表达空间,因为多头注意力机制会有多个Query,Key,Value矩阵,比如transformer有8个head,每个encoder,decoder就会有8套Query,Key,Value矩阵,每套都是随机初始化的。训练之后每套矩阵就会把输入的input embedding映射到不同的表达空间。

把input embedding经过不同的Query,Key,Value矩阵(self attention层),就会得到不同的输出Z矩阵

当我们把Z0~Z7压缩成一个Z矩阵时,问题又来了,feed-forward层对每个单词只需要一个Z矩阵,而不是8个head得到的8个Z的合体。
这时要把合体Z乘以一个权重矩阵WO,目的是把shape变成一个Z的shape

那么上面这些的整体流程如下:
请看多头注意力机制的效果(每列的颜色代表一个头)

positional encoding
每个input embedding要附上一个表示单词位置的positional encoding
postional encoding这篇文章讲的比较详细,
要表示位置信息,首先出现在脑海里的一个点子可能是,给句子中的每个词赋予一个相位,也就是[0, 1]中间的一个值,第一个词是0,最后一个词是1,中间的词在0到1之间取值。
这是个符合直觉的想法,但是这样会不会有什么问题呢?
其中一个问题在于,你并不知道每个句子中词语的个数是多少,这会导致每个词语之间的间隔变化是不一致的。而对于一个句子来说,每个词语之间的间隔都应该是具有相同含义的。
那,为了保证每个词语的间隔含义一致,我们是不是可以给每个词语添加一个线性增长的时间戳呢?比如说第一个词是0,第二词是1,以此类推,第N个词的位置编码是N。
这样其实也会有问题。同样,我们并不知道一个句子的长度,如果训练的句子很长的话,这样的编码是不合适的。 另外,这样训练出来的模型,在泛化性上是有一定问题的。
因此,理想状态下,编码方式应该要满足以下几个条件,
- 对于每个位置的词语,它都能提供一个独一无二的编码
- 词语之间的间隔对于不同长度的句子来说,含义应该是一致的
- 能够随意延伸到任意长度的句子



Residuals
有个细节就是encoder里面有residual connection,然后跟一个layer normalization

decoder里面的层也有类似这样的residual connection,比如2层的decoder,如下
decoder
最上层的encoder得到的输出转换为attention向量K和V,K和V会用在decoder的encoder-decoder attention层

前面位置的预测输出会作为decoder下一时刻的输入,decoder的步骤和encoder一样,也是先word embedding,加上positional encoding,再自下而上得到输出。

decoder中的self attention和encoder中的有一点区别,
在decoder中,要根据前面得到的单词去预测后面的,所以不同于encoder中所有单词同时进入self attention,decoder的self attention中softmax之前,要把未来的位置(还没得到单词的部分)给mask掉(设为-inf)。
Encoder Decoder Attention层跟多头注意力机制差不多,区别是它会在它底下一层计算Q矩阵,而利用encoder输出的K,V矩阵
Linear and Softmax层
如何通过decoder最后输出的一个向量得到单词呢?这就是Linear和softmax层要做的工作。
Linear层就是一个FC层,它要做的是把decoder得到的向量映射成一个更大的类似于one hot的向量。
one hot不用多说了,假设词库里有10000个单词,取长度为10000的向量,只有对应的单词处为1。
softmax层负责将Linear层的输出转换为score,还是假设长度为10000的向量,那么取分数最大的那个作为对应的单词。
如下图所示

Training过程
当我们比较encoder decoder全程的输出和真实标签时,要考虑到损失函数。
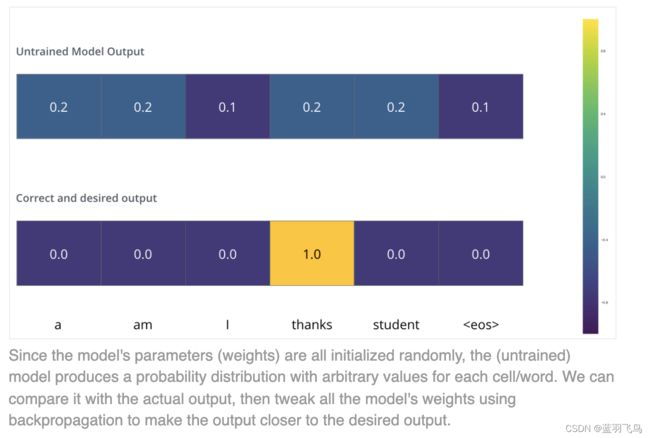
一般用到向量的损失函数,会考虑到cross entropy,但是现在的情况是这是一个句子,需要连续输出正确的单词
比如第一个位置我们需要I的概率最高,第二个位置需要am的概率最高。
训练完之后,我们希望输出是这个样子
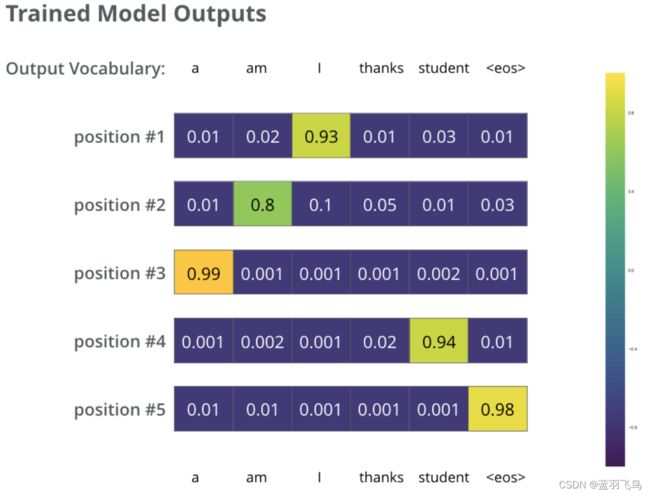
因为每次都是预测一个单词,我们每次取概率最高的单词作为本次输出(greedy decoding)。
还有一种方式,比如每次保留前两个概率最高的单词,然后预测下一个单词时,模型运行两遍,第一遍假设前一个单词是top1概率的,第二遍假设前一个单词时top2概率的,就这样每个位置都保留2个单词,这个是beam search。每次保留几个单词通过超参设定。