MLP-Mixer的Pytorch实现和分析(二)
model = MLPMixer(in_channels=3, dim=512, num_classes=1000, patch_size=16, image_size=224, depth=1, token_dim=256,
channel_dim=2048).to(device)
summary(model,(3,224,224))首先参数意义如下(输入图片为3*224*224):
- in_channels:输入图片的通道数,3。
- dim:卷积操作的输出通道数即out_channels,512。
- num_classes:输出类别的种类数量,最后输出类别,1000。
- patch_size:每一个patch的大小,16。
- image_size:输入图片的大小,224。
- depth:深度,1,理解为token-mixing MLPs(MLP1)和channel-mixing MLPs(MLP2)各一层,若 depth>1则是不断叠加这两个层。
- token_dim:256,理解为mlp1里的神经元数量。
- channel_dim:2048, 理解为mlp2里的神经元数量,两个mlp层区别只是神经元数量。
- num_patches:一张图片的一个channel可以分割成多少个patch
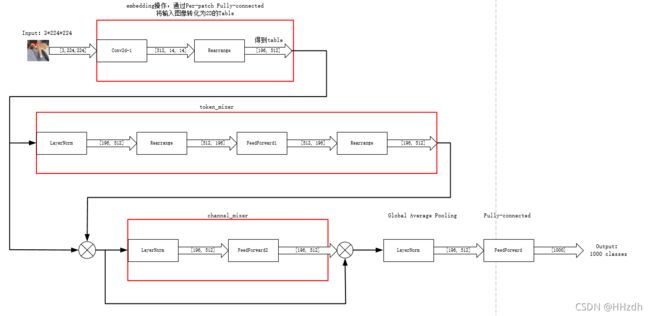
故计算得到每一个channel可以分割得到的patch数量为:(224*224)/(16*16)=196个patch。
self.to_embedding=nn.Sequential(Conv2d(in_channels=in_channels,out_channels=dim,kernel_size=patch_size,stride=patch_size),
Rearrange('b c h w -> b (h w) c')
)这里的卷积操作:
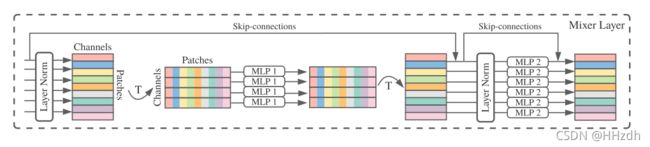
Conv2d(in_channels=3,out_channels=512,kernel_size=16,stride=16)可以看出图片变换为:从[-1,3,224,224]变成[-1,512,14,14],经过Rearrange转换为[-1,196,512],可以理解为196个patch在512长度的向量中映射出其在三个通道的信息,那么这个[196,512]的变换前面所说的table([patch数,通道数])。同时明确token-mixing MLPs(MLP1)对table的列进行映射,对不同空间位置在同一通道上的信息进行操作,实现空间域的信息融合。channel-mixing MLPs(MLP2)对table的行进行映射,对同一空间位置在不同通道上的信息进行映射,实现通道域的信息融合。
接着搭建MLP1和MLP2模块
self.mixer_blocks=nn.ModuleList([])
for _ in range(depth):
self.mixer_blocks.append(MixerBlock(dim,self.num_patches,token_dim,channel_dim,dropout))
即可表示为:
self.mixer_blocks.append(MixerBlock(512,196,token_dim=256,channel_dim=2048,dropout))- token_dim:256,理解为mlp1里的神经元数量。
- channel_dim:2048, 理解为mlp2里的神经元数量,两个mlp层区别只是神经元数量。
回到前面定义的MixerBlock模块,对于token_mixer和channel-mixing模块,主要理解这个FeedForward里的操作,即MLP层。token_mixer对table的列进行映射,针对196进行操作;channel-mixing对table的行进行映射,针对512操作。


MLP的结构如下所示:

一个简单的MLP层定义如下:
class TwoLayerNet(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(TwoLayerNet, self).__init__()
self.twolayernet = nn.Sequential(
nn.Linear(input_size, hidden_size),
nn.ReLU(),
nn.Linear(hidden_size, output_size),
)
def forward(self, x):
y_pred = self.twolayernet(x)
return y_pred
与MLP_Mixer的MLP定义对比:
class FeedForward(nn.Module):
def __init__(self,in_channels,mlp_dim,dropout=0.):
# in_channels, mlp_dim
super().__init__()
self.net=nn.Sequential(
#由此可以看出 FeedForward 的输入和输出维度是一致的
nn.Linear(in_channels,mlp_dim),
#激活函数
nn.GELU(),
#防止过拟合
nn.Dropout(dropout),
#重复上述过程
nn.Linear(mlp_dim,in_channels),
nn.Dropout(dropout)
)
def forward(self,x):
x=self.net(x)
return x这个网络可以画成:

总的来说,MLP-Mixer的核心思想是对行列分别进行映射,注意里面还有skip-connections。