YOLOV3学习笔记
目录
- 一、YOLOV3论文阅读
-
- Abstract
- Introduction
- The Deal
-
- Bounding Box Prediction
- Class Prediction
- Prediction Across Scales(多尺度目标检测)
- Feature Extractor(特征提取网络的改进)&YOLOV3网络结构
- Training
- How We Do
- What This All Means&Rebuttal
- 二、YOLOV3损失函数(大概)
- 三、YOLOV3改进总结
YOLOV3的论文是一篇技术报告,所以不像YOLOV1和YOLOV2论文那样严谨正式,因此论文阅读部分仅仅选择一些我个人认为比较有意义的部分进行笔记。
论文链接:YOLOV3论文
参考视频:同济子豪兄:YOLOV3精讲
一、YOLOV3论文阅读
Abstract
在YOLOV2的基础上,作者又做了一些小设计使YOLO的算法性能更好。相比于YOLOV2,YOLOV3网络要大一些但是速度仍然很快,也更为准确。当输入为 320 ∗ 320 320*320 320∗320分辨率的图像时,YOLOV3检测一张图片需要22ms,map达到28.2,和SSD算法的精确度一样但是比SSD快三倍。当IOU阈值设为0.5时,YOLOV3的map是比较好的,在TitanX上运算一张图片需要51ms, A P 50 AP_{50} AP50达到57.9,相比于 A P 50 = 57.5 AP_{50}=57.5 AP50=57.5和检测一张图片198ms的RetinaNet,准确度相同但是YOLOV3要快三倍以上。
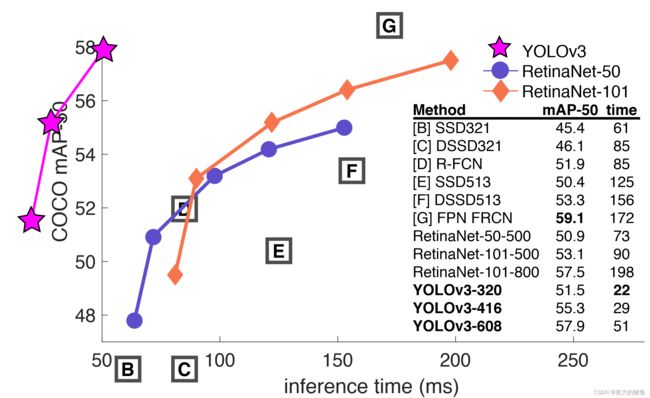 上图表明YOLOV3相比于其他算法,在准确度相同或者更高的情况下,速度要快得多,这展示了YOLOV3算法的优越性。
上图表明YOLOV3相比于其他算法,在准确度相同或者更高的情况下,速度要快得多,这展示了YOLOV3算法的优越性。
Introduction
作者写这篇技术报告是为了方便在另一篇文章中引用。
The Deal
Bounding Box Prediction
YOLOV3中对于每一个bbox使用逻辑回归预测置信度。
关于正负样本:YOLOV3有三个尺度的featuremap,因此gt的中心点在不同尺度的featuremap都会有一个对应的gridcell,那么在哪一个尺度上进行预测呢?YOLOV3的办法是:由3个尺度的anchor中与gt框IOU最大的那个anchor所在尺度的gridcell负责预测。
YOLOV3中把与gt的IOU最大的anchor的置信度设为1,也就是正样本。
在YOLOV1/V2中,置信度是IOU。这种机制的缺点在于:(参考同济子豪兄视频)
1、很多预测框与GT的IOU最高只有0.7,即标签最高只有0.7,这就导致训练的时候很难学习到0.7-1区间的置信度,比较难以训练;
2、coco中的小目标比较多,IOU对于像素偏移很敏感,无法有效学习。
而对于那些与gt的IOU不是最大的,但是却大于我们所设定的IOU阈值的anchor,忽略这些anchors。
在YOLOV2中,对于每一个gt只有一个anchor负责预测,那就是与IOU最大的anchor负责预测。这个anchor就是正样本,而剩余的anchor则为负样本。在YOLOV2的损失函数中,正样本会在定位、置信度、分类等损失函数上产生贡献;而负样本只会对置信度损失函数产生贡献。
因为负样本不负责预测物体,因此其置信度应该为0;不对分类损失产生贡献的原因是:分类概率=置信度×类条件概率,而置信度为0,那么最后的分类概率也为0,因此不用考虑类条件概率的损失;至于定位,个人理解是:因为负责预测物体的是与GT的IOU最大的anchor,因此只需关注该anchor产生的预测框的定位误差,经过不断训练,最后预测阶段,不负责预测物体的anchors所产生的预测框,由于其置信度为0,经过非极大值抑制,就会被剔除掉。(关于非极大值抑制后续会出笔记~已经挖了好多笔记坑了o(╥﹏╥)o一个一个慢慢填叭))
Class Prediction
每一个bbox都可能包含多个目标,也就是有几个类的标签值和预测值都为1,。而softmax最终的预测概率求和为1,因此softmax对于提高模型的性能来说益处不大。
在YOLOV3中,对于每一个类别,单独使用二分类,从而对于每一个类别都输出一个0-1之间的数。在训练过程中,对于类别预测使用二分类交叉熵损失函数。
这种方法的好处在于:当涉及到更加复杂的数据集,如有许多重复标签的谷歌数据集Open Images Dataset,这就意味着一个bbox可能会负责预测很多个目标,有多个标签,比如一个框可能标签既是人也是女人。这时候使用softmax强行假设每一个bbox都只有一个类别,而这与数据集有许多重叠标签的情况不符合,而多标签的方法更适合此数据集。
Prediction Across Scales(多尺度目标检测)
YOLOV3在3个不同的尺度预测bbox,模型受FPN的启发,从不同的尺度提取特征。在基础特征提取器之后,对于每一个尺度添加不同的卷积层,最后每一个尺度都会输出一个包含bbox偏移信息、置信度和分类预测的三维张量。在作者的实验中,使用COCO数据集,在每一个尺度上每一个gridcell都预测三个bbox(对应3个anchor),因此最后输出的张量大小为: N × N × [ 3 ∗ ( 4 + 1 + 80 ) ] N\times N\times [3*(4+1+80)] N×N×[3∗(4+1+80)]。
YOLOV3中添加了通道融合部分,比如现将 19 ∗ 19 19*19 19∗19尺度的featuremap经过上采样,尺度变为原来的两倍成为 38 ∗ 38 38*38 38∗38,然后与backbone部分相同尺度的featuremap进行通道融合,得到一个新尺度 38 ∗ 38 38*38 38∗38的featuremap。
这一操作能够得到更有意义的深层抽象特化语义信息和浅层细粒度像素结构信息。之后添加卷积层去处理融合的特征图,最后预测得到新尺度下的张量。
在经过相同的操作得到 76 ∗ 76 76*76 76∗76的featuremap。
在YOLOV3中作者仍然使用Kmeans聚类得到anchorboxes。最后选择九个聚类中心,然后将这九个anchor根据尺度平均分配到3个尺度的featuremap上,也就是每个尺度有3个anchor。
Feature Extractor(特征提取网络的改进)&YOLOV3网络结构
在YOLOV3中,作者使用了一个新的骨干网络提取特征。该网络混合了YOLOV2的Darknet19和残差网络,并且使用了连续的 3 × 3 3\times 3 3×3和 1 × 1 1\times 1 1×1卷积层,再加上了shortcut短路连接,因此新的网络明显更大了。由于该网络有53个卷积层,因此该网络称为Darknet53.
网络结构:
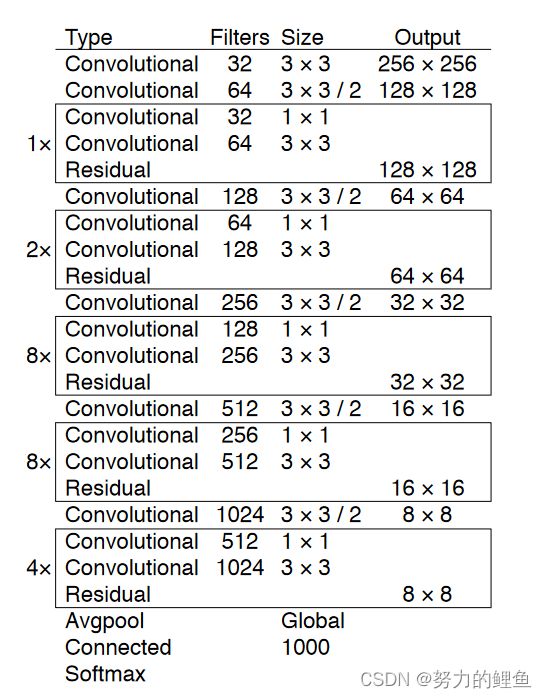
上述为分类网络,目标检测网络结构如下:(图源知乎Algernon:YOLO三部曲解读——YOLOV3)
图源知乎江大白:深入浅出YOLO系列
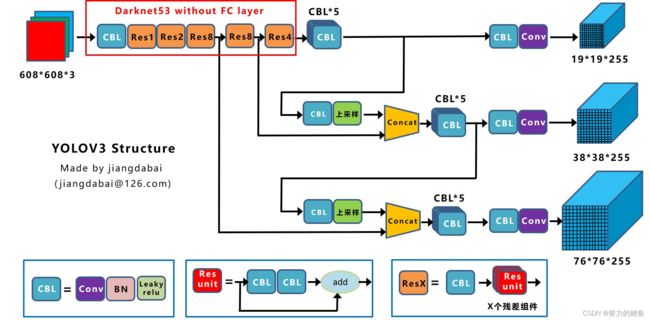 根据上述YOLOV3网络结构的两个不同表示,结合自己的理解,我绘制了下图的YOLOV3结构:(审美有待提高(灬ꈍ ꈍ灬))
根据上述YOLOV3网络结构的两个不同表示,结合自己的理解,我绘制了下图的YOLOV3结构:(审美有待提高(灬ꈍ ꈍ灬))
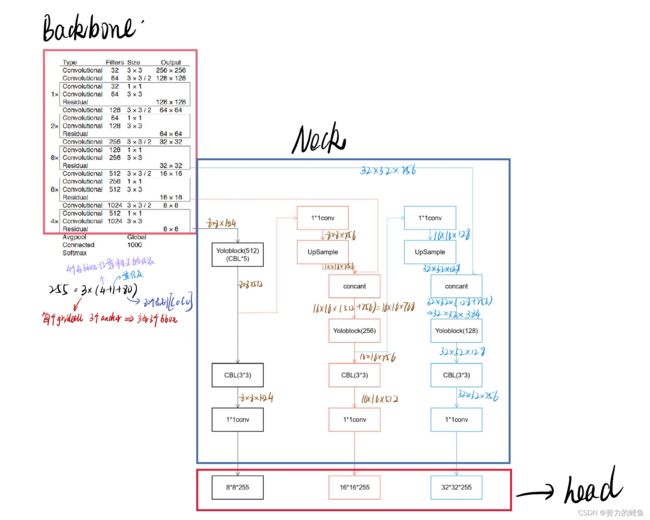
关于卷积操作最后输出为小数的处理——向下取整去余:
当步长为2时,卷积核移动两个为1步,因此可以设一个为0.5步。上图中卷积核移动3步就已经把全图走完,再往后走多为零填充层,因此取3步。
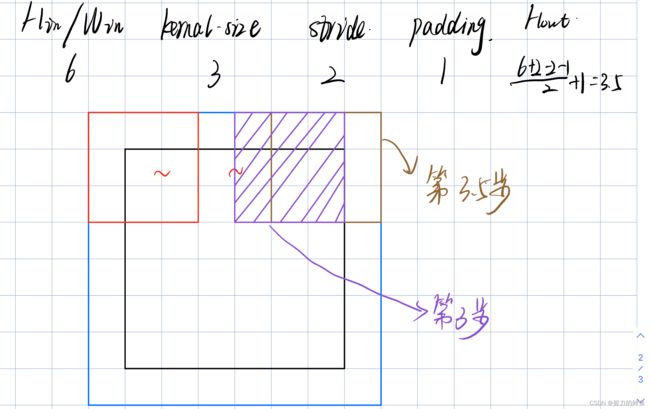
YOLOV3网络中的backbone——darknet53骨干网络是一个FClayer,因此可以兼容不同尺度。
关于Draknet53的性能:检测性能和如今先进的分类器平分秋色,但是速度更快并且具有更少的浮点运算。Darknet53比Resnet101更好并且快1.5倍。同时 Darknet53每秒可以实现最大次数的浮点运算相比于其他先进的目标检测算法。这意味着Darknet53的网络结构对GPU可以更好的进行利用。
Training
YOLOV3的训练过程依然使用端到端的训练,没有使用难例挖掘的方法。采用了多尺度训练,许多的数据扩增办法,BN层等。
How We Do
YOLOV3在 m a p @ . 5 map@.5 map@.5指标上表现非常好,这表明YOLOV3在粗略的目标检测上具有比较好的性能。但是当IOU阈值增加时,性能大幅下降,,这表明YOLOV3的精准定位性能还是比较差的,也就是其预测出的bbox无法与gt完美重合。
YOLOV1和YOLOV2是在小目标的检测上性能比较差,然而YOLOV3在小目标的检测性能比较好,在大目标和中等目标上的检测性能比较差。
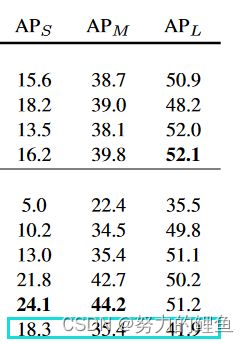 可以看到上表中YOLOV3在小目标检测上的AP指标相对比较好,但是中大目标上的AP指标相对来说比较低。在YOLOV3中小目标检测性能好的原因主要有以下几点:
可以看到上表中YOLOV3在小目标检测上的AP指标相对比较好,但是中大目标上的AP指标相对来说比较低。在YOLOV3中小目标检测性能好的原因主要有以下几点:
- gridcell个数增加。在YOLOV1中,将每幅图像划分为 7 ∗ 7 7*7 7∗7的网格,每个网格产生2个bbox,因此最终有 7 ∗ 7 ∗ 2 = 98 7*7*2=98 7∗7∗2=98个bbox;在YOLOV2中,将每幅图像划分为 13 ∗ 13 13*13 13∗13个gridcell,每个gridcell对应5个anchor,每个anchor对应一个预测框;因此有 13 ∗ 13 ∗ 5 = 845 13*13*5=845 13∗13∗5=845个bbox;在YOLOV3中,每幅图像对应3个不同尺度的featuremap,每个尺度的每个gridcell对应3个anchor,因此每个尺度最后产生 N ∗ N ∗ 3 N*N*3 N∗N∗3个bbox,以输入图像为 256 ∗ 256 256*256 256∗256为例,3个尺度分别为 8 ∗ 8 、 16 ∗ 16 、 32 ∗ 32 8*8、16*16、32*32 8∗8、16∗16、32∗32,最后总共有 ( 8 ∗ 8 + 16 ∗ 16 + 32 ∗ 32 ) ∗ 3 = 4032 (8*8+16*16+32*32)*3=4032 (8∗8+16∗16+32∗32)∗3=4032个bbox。相比于之前的yolo算法,YOLOV3算法产生的预测框更多,可以将图像中的目标尽可能多的预测出来,因此小目标密集目标的检测性能增加;
- 添加了anchor。anchor是根据数据集中目标的gt框聚类得到的,因此对于小目标有专门长宽的anchor框去负责预测,这样大大增加了小目标被检测到的可能性;
- 特征融合。在YOLOV3中将深层特征与浅层细粒度特征进行融合,有利于提高检测精度;
- 多尺度检测FPN。在YOLOV3中有3个尺度的featuremap,分别对应着大、中、小三个尺度的目标,因此对于小目标来说,有专门尺度的featuremap去进行检测,提高了小目标检测的精度。
- backbone骨干网络的改进——Darknet53。有一个好的特征提取网络能够提取到好的特征,而好的特征对于目标检测任务来说至关重要。因此骨干网络的改进使得更好的特征被提取,从而整体上提高了模型检测的性能。
What This All Means&Rebuttal
人类很难区分IOU的微小差异,也就是对于面积的微小差异是不敏感的。对于定位误差而言,既然人类都很难区分,那么目标检测任务为什么要苛刻地追求完美定位呢?
COCO片面地强调了定位性能,但是忽略了分类性能。对于人类来说,分类错误是更明显的,对于定位只要大致定位到,那么就可以接受。因此作者认为map评价指标比较落后。
二、YOLOV3损失函数(大概)
关于YOLOV3的损失函数分为两部分,分别为正样本的损失与负样本的损失。关于正负样本的设置在Bounding Box Prediction 部分有提到,同时参考知乎Algernon:YOLO三部曲解读——YOLOV3)。设置一个IOU阈值,对于每一个 gt框,计算所有预测框与gt的IOU,选择IOU最大的作为该gt的正样本,大于阈值但不是最大的预测框忽略,小于阈值的预测框作为负样本。
由于每一个预测框只负责预测一个gt,因此当对下一个gt框进行预测时,要去掉之前gt框的正例预测框,计算剩下的预测框与此gt的IOU。
YOLOV3的损失函数源于同济子豪兄:YOLOV3算法精讲:

三、YOLOV3改进总结
- 骨干网络——Darknet53
- 特征融合:neck
- 多尺度检测:head
- anchor:每个gridcell3个anchor
- 正负样本的设置
- 损失函数